清华大学严蔚敏数据结构题集完整答案(c语言版)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清华大学严蔚敏数据结构题集完整答案(c语言版)相关的知识,希望对你有一定的参考价值。
参考技术A 第一章 绪论1.16
void print_descending(int x,int y,int z)//按从大到小顺序输出三个数
scanf("%d,%d,%d",&x,&y,&z);
if(x<y) x<->y; //<->为表示交换的双目运算符,以下同
if(y<z) y<->z;
if(x<y) x<->y; //冒泡排序
printf("%d %d %d",x,y,z);
//print_descending
1.17
Status fib(int k,int m,int &f)//求k阶斐波那契序列的第m项的值f
int tempd;
if(k<2||m<0) return ERROR;
if(m<k-1) f=0;
else if (m==k-1) f=1;
else
for(i=0;i<=k-2;i++) temp[i]=0;
temp[k-1]=1; //初始化
for(i=k;i<=m;i++) //求出序列第k至第m个元素的值
sum=0;
for(j=i-k;j<i;j++) sum+=temp[j];
temp[i]=sum;
f=temp[m];
return OK;
//fib
分析:通过保存已经计算出来的结果,此方法的时间复杂度仅为O(m^2).如果采用递归编程(大多数人都会首先想到递归方法),则时间复杂度将高达O(k^m).
1.18
typedef struct
char *sport;
enummale,female gender;
char schoolname; //校名为'A','B','C','D'或'E'
char *result;
int score;
resulttype;
typedef struct
int malescore;
int femalescore;
int totalscore;
scoretype;
void summary(resulttype result[ ])//求各校的男女总分和团体总分,假设结果已经储存在result[ ]数组中
scoretype score ;
i=0;
while(result[i].sport!=NULL)
switch(result[i].schoolname)
case 'A':
score[ 0 ].totalscore+=result[i].score;
if(result[i].gender==0) score[ 0 ].malescore+=result[i].score;
else score[ 0 ].femalescore+=result[i].score;
break;
case 'B':
score .totalscore+=result[i].score;
if(result[i].gender==0) score .malescore+=result[i].score;
else score .femalescore+=result[i].score;
break;
…… …… ……
i++;
for(i=0;i<5;i++)
printf("School %d:\n",i);
printf("Total score of male:%d\n",score[i].malescore);
printf("Total score of female:%d\n",score[i].femalescore);
printf("Total score of all:%d\n\n",score[i].totalscore);
//summary
1.19
Status algo119(int a[ARRSIZE])//求i!*2^i序列的值且不超过maxint
last=1;
for(i=1;i<=ARRSIZE;i++)
a[i-1]=last*2*i;
if((a[i-1]/last)!=(2*i)) reurn OVERFLOW;
last=a[i-1];
return OK;
//algo119
分析:当某一项的结果超过了maxint时,它除以前面一项的商会发生异常.
1.20
void polyvalue()
float ad;
float *p=a;
printf("Input number of terms:");
scanf("%d",&n);
printf("Input the %d coefficients from a0 to a%d:\n",n,n);
for(i=0;i<=n;i++) scanf("%f",p++);
printf("Input value of x:");
scanf("%f",&x);
p=a;xp=1;sum=0; //xp用于存放x的i次方
for(i=0;i<=n;i++)
sum+=xp*(*p++);
xp*=x;
printf("Value is:%f",sum);
//polyvalue
第二章 线性表
2.10
Status DeleteK(SqList &a,int i,int k)//删除线性表a中第i个元素起的k个元素
if(i<1||k<0||i+k-1>a.length) return INFEASIBLE;
for(count=1;i+count-1<=a.length-k;count++) //注意循环结束的条件
a.elem[i+count-1]=a.elem[i+count+k-1];
a.length-=k;
return OK;
//DeleteK
2.11
Status Insert_SqList(SqList &va,int x)//把x插入递增有序表va中
if(va.length+1>va.listsize) return ERROR;
va.length++;
for(i=va.length-1;va.elem[i]>x&&i>=0;i--)
va.elem[i+1]=va.elem[i];
va.elem[i+1]=x;
return OK;
//Insert_SqList
2.12
int ListComp(SqList A,SqList B)//比较字符表A和B,并用返回值表示结果,值为正,表示A>B;值为负,表示A<B;值为零,表示A=B
for(i=1;A.elem[i]||B.elem[i];i++)
if(A.elem[i]!=B.elem[i]) return A.elem[i]-B.elem[i];
return 0;
//ListComp
2.13
LNode* Locate(LinkList L,int x)//链表上的元素查找,返回指针
for(p=l->next;p&&p->data!=x;p=p->next);
return p;
//Locate
2.14
int Length(LinkList L)//求链表的长度
for(k=0,p=L;p->next;p=p->next,k++);
return k;
//Length
2.15
void ListConcat(LinkList ha,LinkList hb,LinkList &hc)//把链表hb接在ha后面形成链表hc
hc=ha;p=ha;
while(p->next) p=p->next;
p->next=hb;
//ListConcat
2.16
见书后答案.
2.17
Status Insert(LinkList &L,int i,int b)//在无头结点链表L的第i个元素之前插入元素b
p=L;q=(LinkList*)malloc(sizeof(LNode));
q.data=b;
if(i==1)
q.next=p;L=q; //插入在链表头部
else
while(--i>1) p=p->next;
q->next=p->next;p->next=q; //插入在第i个元素的位置
//Insert
2.18
Status Delete(LinkList &L,int i)//在无头结点链表L中删除第i个元素
if(i==1) L=L->next; //删除第一个元素
else
p=L;
while(--i>1) p=p->next;
p->next=p->next->next; //删除第i个元素
//Delete
2.19
Status Delete_Between(Linklist &L,int mink,int maxk)//删除元素递增排列的链表L中值大于mink且小于maxk的所有元素
p=L;
while(p->next->data<=mink) p=p->next; //p是最后一个不大于mink的元素
if(p->next) //如果还有比mink更大的元素
q=p->next;
while(q->data<maxk) q=q->next; //q是第一个不小于maxk的元素
p->next=q;
//Delete_Between
2.20
Status Delete_Equal(Linklist &L)//删除元素递增排列的链表L中所有值相同的元素
p=L->next;q=p->next; //p,q指向相邻两元素
while(p->next)
if(p->data!=q->data)
p=p->next;q=p->next; //当相邻两元素不相等时,p,q都向后推一步
else
while(q->data==p->data)
free(q);
q=q->next;
p->next=q;p=q;q=p->next; //当相邻元素相等时删除多余元素
//else
//while
//Delete_Equal
2.21
void reverse(SqList &A)//顺序表的就地逆置
for(i=1,j=A.length;i<j;i++,j--)
A.elem[i]<->A.elem[j];
//reverse
2.22
void LinkList_reverse(Linklist &L)//链表的就地逆置;为简化算法,假设表长大于2
p=L->next;q=p->next;s=q->next;p->next=NULL;
while(s->next)
q->next=p;p=q;
q=s;s=s->next; //把L的元素逐个插入新表表头
q->next=p;s->next=q;L->next=s;
//LinkList_reverse
分析:本算法的思想是,逐个地把L的当前元素q插入新的链表头部,p为新表表头.
2.23
void merge1(LinkList &A,LinkList &B,LinkList &C)//把链表A和B合并为C,A和B的元素间隔排列,且使用原存储空间
p=A->next;q=B->next;C=A;
while(p&&q)
s=p->next;p->next=q; //将B的元素插入
if(s)
t=q->next;q->next=s; //如A非空,将A的元素插入
p=s;q=t;
//while
//merge1
2.24
void reverse_merge(LinkList &A,LinkList &B,LinkList &C)//把元素递增排列的链表A和B合并为C,且C中元素递减排列,使用原空间
pa=A->next;pb=B->next;pre=NULL; //pa和pb分别指向A,B的当前元素
while(pa||pb)
if(pa->data<pb->data||!pb)
pc=pa;q=pa->next;pa->next=pre;pa=q; //将A的元素插入新表
else
pc=pb;q=pb->next;pb->next=pre;pb=q; //将B的元素插入新表
pre=pc;
C=A;A->next=pc; //构造新表头
//reverse_merge
分析:本算法的思想是,按从小到大的顺序依次把A和B的元素插入新表的头部pc处,最后处理A或B的剩余元素.
2.25
void SqList_Intersect(SqList A,SqList B,SqList &C)//求元素递增排列的线性表A和B的元素的交集并存入C中
i=1;j=1;k=0;
while(A.elem[i]&&B.elem[j])
if(A.elem[i]<B.elem[j]) i++;
if(A.elem[i]>B.elem[j]) j++;
if(A.elem[i]==B.elem[j])
C.elem[++k]=A.elem[i]; //当发现了一个在A,B中都存在的元素,
i++;j++; //就添加到C中
//while
//SqList_Intersect
2.26
void LinkList_Intersect(LinkList A,LinkList B,LinkList &C)//在链表结构上重做上题
p=A->next;q=B->next;
pc=(LNode*)malloc(sizeof(LNode));
while(p&&q)
if(p->data<q->data) p=p->next;
else if(p->data>q->data) q=q->next;
else
s=(LNode*)malloc(sizeof(LNode));
s->data=p->data;
pc->next=s;pc=s;
p=p->next;q=q->next;
//while
C=pc;
//LinkList_Intersect
2.27
void SqList_Intersect_True(SqList &A,SqList B)//求元素递增排列的线性表A和B的元素的交集并存回A中
i=1;j=1;k=0;
while(A.elem[i]&&B.elem[j])
if(A.elem[i]<B.elem[j]) i++;
else if(A.elem[i]>B.elem[j]) j++;
else if(A.elem[i]!=A.elem[k])
A.elem[++k]=A.elem[i]; //当发现了一个在A,B中都存在的元素
i++;j++; //且C中没有,就添加到C中
//while
while(A.elem[k]) A.elem[k++]=0;
//SqList_Intersect_True
2.28
void LinkList_Intersect_True(LinkList &A,LinkList B)//在链表结构上重做上题
p=A->next;q=B->next;pc=A;
while(p&&q)
if(p->data<q->data) p=p->next;
else if(p->data>q->data) q=q->next;
else if(p->data!=pc->data)
pc=pc->next;
pc->data=p->data;
p=p->next;q=q->next;
//while
//LinkList_Intersect_True
2.29
void SqList_Intersect_Delete(SqList &A,SqList B,SqList C)
i=0;j=0;k=0;m=0; //i指示A中元素原来的位置,m为移动后的位置
while(i<A.length&&j<B.length&& k<C.length)
if(B.elem[j]<C.elem[k]) j++;
else if(B.elem[j]>C.elem[k]) k++;
else
same=B.elem[j]; //找到了相同元素same
while(B.elem[j]==same) j++;
while(C.elem[k]==same) k++; //j,k后移到新的元素
while(i<A.length&&A.elem[i]<same)
A.elem[m++]=A.elem[i++]; //需保留的元素移动到新位置
while(i<A.length&&A.elem[i]==same) i++; //跳过相同的元素
//while
while(i<A.length)
A.elem[m++]=A.elem[i++]; //A的剩余元素重新存储。
A.length=m;
// SqList_Intersect_Delete
分析:先从B和C中找出共有元素,记为same,再在A中从当前位置开始, 凡小于same的
元素均保留(存到新的位置),等于same的就跳过,到大于same时就再找下一个same.
2.30
void LinkList_Intersect_Delete(LinkList &A,LinkList B,LinkList C)//在链表结构上重做上题
p=B->next;q=C->next;r=A-next;
while(p&&q&&r)
if(p->data<q->data) p=p->next;
else if(p->data>q->data) q=q->next;
else
u=p->data; //确定待删除元素u
while(r->next->data<u) r=r->next; //确定最后一个小于u的元素指针r
if(r->next->data==u)
s=r->next;
while(s->data==u)
t=s;s=s->next;free(t); //确定第一个大于u的元素指针s
//while
r->next=s; //删除r和s之间的元素
//if
while(p->data=u) p=p->next;
while(q->data=u) q=q->next;
//else
//while
//LinkList_Intersect_Delete
2.31
Status Delete_Pre(CiLNode *s)//删除单循环链表中结点s的直接前驱
p=s;
while(p->next->next!=s) p=p->next; //找到s的前驱的前驱p
p->next=s;
return OK;
//Delete_Pre
2.32
Status DuLNode_Pre(DuLinkList &L)//完成双向循环链表结点的pre域
for(p=L;!p->next->pre;p=p->next) p->next->pre=p;
return OK;
//DuLNode_Pre
2.33
Status LinkList_Divide(LinkList &L,CiList &A,CiList &B,CiList &C)//把单链表L的元素按类型分为三个循环链表.CiList为带头结点的单循环链表类型.
s=L->next;
A=(CiList*)malloc(sizeof(CiLNode));p=A;
B=(CiList*)malloc(sizeof(CiLNode));q=B;
C=(CiList*)malloc(sizeof(CiLNode));r=C; //建立头结点
while(s)
if(isalphabet(s->data))
p->next=s;p=s;
else if(isdigit(s->data))
q->next=s;q=s;
else
r->next=s;r=s;
//while
p->next=A;q->next=B;r->next=C; //完成循环链表
//LinkList_Divide
2.34
void Print_XorLinkedList(XorLinkedList L)//从左向右输出异或链表的元素值
p=L.left;pre=NULL;
while(p)
printf("%d",p->data);
q=XorP(p->LRPtr,pre);
pre=p;p=q; //任何一个结点的LRPtr域值与其左结点指针进行异或运算即得到其右结点指针
//Print_XorLinkedList
2.35
Status Insert_XorLinkedList(XorLinkedList &L,int x,int i)//在异或链表L的第i个元素前插入元素x
p=L.left;pre=NULL;
r=(XorNode*)malloc(sizeof(XorNode));
r->data=x;
if(i==1) //当插入点在最左边的情况
p->LRPtr=XorP(p.LRPtr,r);
r->LRPtr=p;
L.left=r;
return OK;
j=1;q=p->LRPtr; //当插入点在中间的情况
while(++j<i&&q)
q=XorP(p->LRPtr,pre);
pre=p;p=q;
//while //在p,q两结点之间插入
if(!q) return INFEASIBLE; //i不可以超过表长
p->LRPtr=XorP(XorP(p->LRPtr,q),r);
q->LRPtr=XorP(XorP(q->LRPtr,p),r);
r->LRPtr=XorP(p,q); //修改指针
return OK;
//Insert_XorLinkedList
2.36
Status Delete_XorLinkedList(XorlinkedList &L,int i)//删除异或链表L的第i个元素
p=L.left;pre=NULL;
if(i==1) //删除最左结点的情况
q=p->LRPtr;
q->LRPtr=XorP(q->LRPtr,p);
L.left=q;free(p);
return OK;
j=1;q=p->LRPtr;
while(++j<i&&q)
q=XorP(p->LRPtr,pre);
pre=p;p=q;
//while //找到待删结点q
if(!q) return INFEASIBLE; //i不可以超过表长
if(L.right==q) //q为最右结点的情况
p->LRPtr=XorP(p->LRPtr,q);
L.right=p;free(q);
return OK;
r=XorP(q->LRPtr,p); //q为中间结点的情况,此时p,r分别为其左右结点
p->LRPtr=XorP(XorP(p->LRPtr,q),r);
r->LRPtr=XorP(XorP(r->LRPtr,q),p); //修改指针
free(q);
return OK;
//Delete_XorLinkedList
2.37
void OEReform(DuLinkedList &L)//按1,3,5,...4,2的顺序重排双向循环链表L中的所有结点
p=L.next;
while(p->next!=L&&p->next->next!=L)
p->next=p->next->next;
p=p->next;
//此时p指向最后一个奇数结点
if(p->next==L) p->next=L->pre->pre;
else p->next=l->pre;
p=p->next; //此时p指向最后一个偶数结点
while(p->pre->pre!=L)
p->next=p->pre->pre;
p=p->next;
p->next=L; //按题目要求调整了next链的结构,此时pre链仍为原状
for(p=L;p->next!=L;p=p->next) p->next->pre=p;
L->pre=p; //调整pre链的结构,同2.32方法
//OEReform
分析:next链和pre链的调整只能分开进行.如同时进行调整的话,必须使用堆栈保存偶数结点的指针,否则将会破坏链表结构,造成结点丢失.
2.38
DuLNode * Locate_DuList(DuLinkedList &L,int x)//带freq域的双向循环链表上的查找
p=L.next;
while(p.data!=x&&p!=L) p=p->next;
if(p==L) return NULL; //没找到
p->freq++;q=p->pre;
while(q->freq<=p->freq) q=q->pre; //查找插入位置
if(q!=p->pre)
p->pre->next=p->next;p->next->pre=p->pre;
q->next->pre=p;p->next=q->next;
q->next=p;p->pre=q; //调整位置
return p;
//Locate_DuList
2.39
float GetValue_SqPoly(SqPoly P,int x0)//求升幂顺序存储的稀疏多项式的值
PolyTerm *q;
xp=1;q=P.data;
sum=0;ex=0;
while(q->coef)
while(ex<q->exp) xp*=x0;
sum+=q->coef*xp;
q++;
return sum;
//GetValue_SqPoly
2.40
void Subtract_SqPoly(SqPoly P1,SqPoly P2,SqPoly &P3)//求稀疏多项式P1减P2的差式P3
PolyTerm *p,*q,*r;
Create_SqPoly(P3); //建立空多项式P3
p=P1.data;q=P2.data;r=P3.data;
while(p->coef&&q->coef)
if(p->exp<q->exp)
r->coef=p->coef;
r->exp=p->exp;
p++;r++;
else if(p->exp<q->exp)
r->coef=-q->coef;
r->exp=q->exp;
q++;r++;
else
if((p->coef-q->coef)!=0) //只有同次项相减不为零时才需要存入P3中
r->coef=p->coef-q->coef;
r->exp=p->exp;r++;
//if
p++;q++;
//else
//while
while(p->coef) //处理P1或P2的剩余项
r->coef=p->coef;
r->exp=p->exp;
p++;r++;
while(q->coef)
r->coef=-q->coef;
r->exp=q->exp;
q++;r++;
//Subtract_SqPoly
2.41
void QiuDao_LinkedPoly(LinkedPoly &L)//对有头结点循环链表结构存储的稀疏多项式L求导
p=L->next;
if(!p->data.exp)
L->next=p->next;p=p->next; //跳过常数项
while(p!=L)
p->data.coef*=p->data.exp--;//对每一项求导
p=p->next;
//QiuDao_LinkedPoly
2.42
void Divide_LinkedPoly(LinkedPoly &L,&A,&B)//把循环链表存储的稀疏多项式L拆成只含奇次项的A和只含偶次项的B
p=L->next;
A=(PolyNode*)malloc(sizeof(PolyNode));
B=(PolyNode*)malloc(sizeof(PolyNode));
pa=A;pb=B;
while(p!=L)
if(p->data.exp!=2*(p->data.exp/2))
pa->next=p;pa=p;
else
pb->next=p;pb=p;
p=p->next;
//while
pa->next=A;pb->next=B;
//Divide_LinkedPoly 参考技术B 可以传我一份不啊 302851130@qq.com 谢谢 参考技术C 考研用的?
有光盘的21元,没光盘的18
二手的便宜点,很实惠 参考技术D 你这叫别人怎么给你 第5个回答 2009-05-13 邮箱传你要不本回答被提问者采纳
-《数据结构题集》习题解析-严蔚敏吴伟民版
习题集解析部分
第12章 文件
——《数据结构题集》-严蔚敏.吴伟民版
源码使用说明 链接☛☛☛ 《数据结构-C语言版》(严蔚敏,吴伟民版)课本源码+习题集解析使用说明
课本源码合辑 链接☛☛☛ 《数据结构》课本源码合辑
习题集全解析 链接☛☛☛ 《数据结构题集》习题解析合辑
相关测试数据下载 链接☛ 数据包
本习题文档的存放目录:数据结构\\▼配套习题解析\\▼12 文件
文档中源码的存放目录:数据结构\\▼配套习题解析\\▼12 文件\\▼习题测试文档-12
源码测试数据存放目录:数据结构\\▼配套习题解析\\▼12 文件\\▼习题测试文档-12\\Data
一、基础知识题
12.1❶ 试比较顺序文件、索引文件和索引顺序文件各有什么特点。

12.2❶ 已知下列ISAM文件:

试叙述在文件中查找记录R(xan)和R(xzi)的过程。

12.3❶ 试画出在下图所示文件的状态下,插入R89,R91,删除R99,R92之后的文件状态。
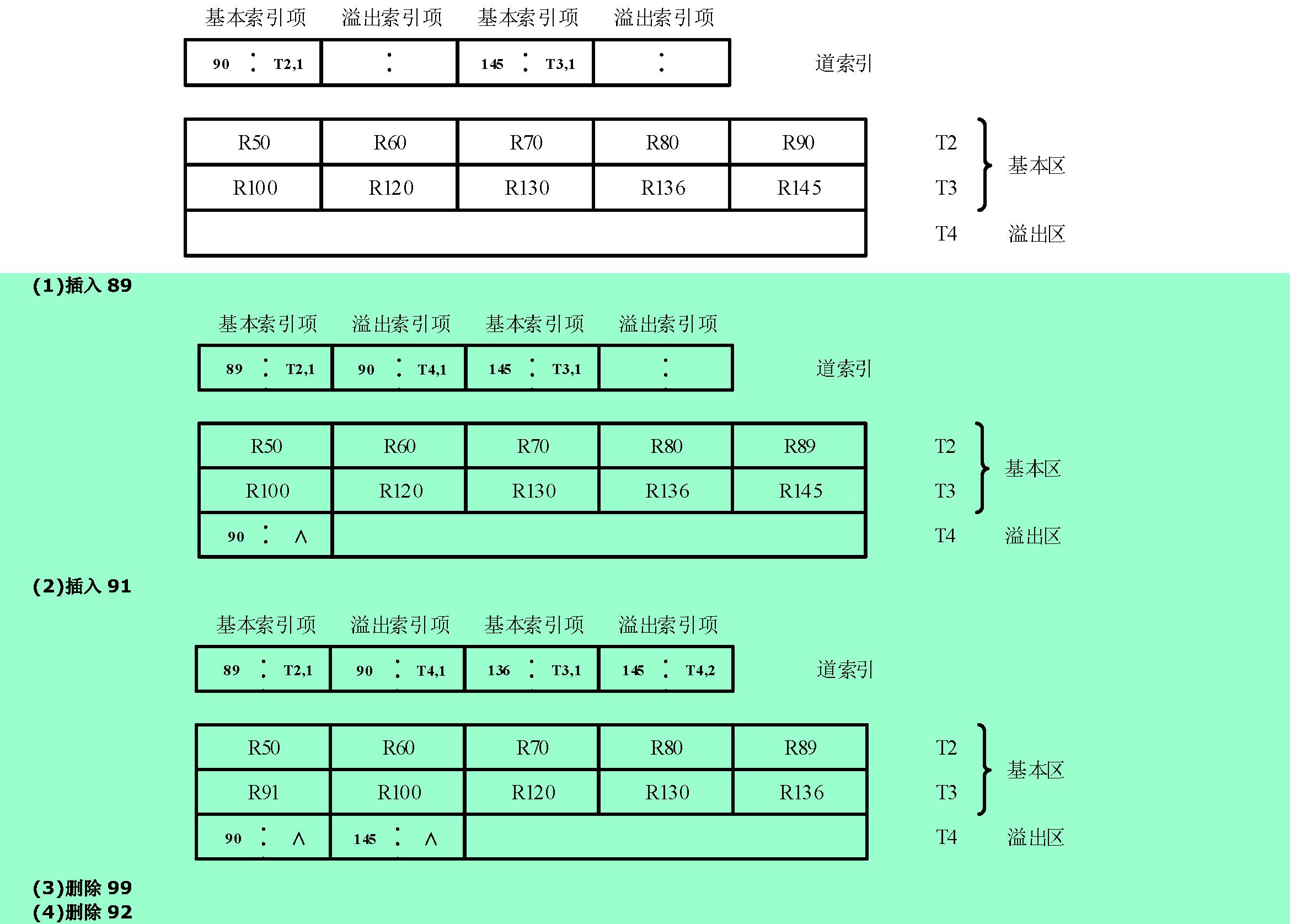
12.4❷ 直接存取文件为什么不用教科书9.3.3节中给出的链地址法存储结构而要按桶散列?桶的大小m是如何确定的?

12.5❷ 假设物理块(桶)大小为100,若要求对含有30000个记录的直接存取文件进行一次按关键字查询时,读外存次数的平均值不超过2,则问该直接存取文件应设多大?

12.6❶ 试叙述在下图所示文件中查找“计算机”专业选修“丙”课程的学生名单的过程。一般来说,查询条件为两个关键字条件的“与”时,按哪个次关键字的链查找较好?
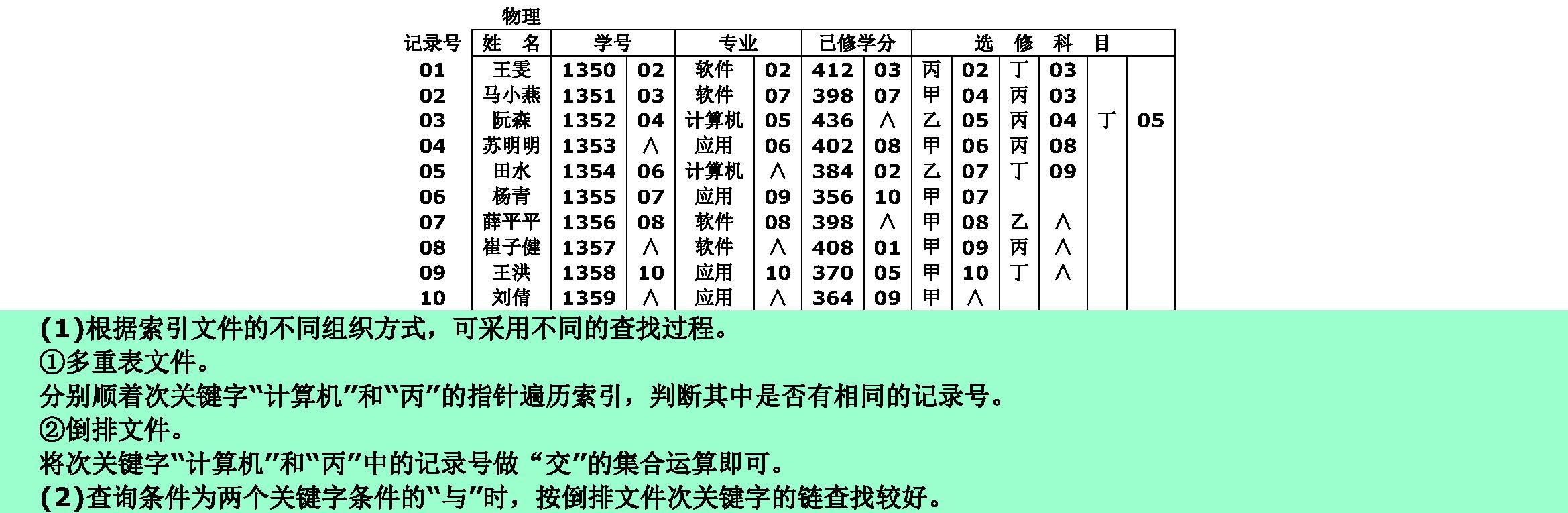
12.7❶ 简单比较文件的多重表和倒排表组织方式各有什么优缺点。

12.8❸ 请为图书馆中如下所示的部分目录建立一个倒排文件。要求该文件允许用户按书名查找或按作者查找或按分类查找。现有的外存为磁盘,主文件按索引顺序组织,每个柱面有6道,设柱面溢出区,溢出区占2道。

若相继插入下列记录,文件将发生什么变化?

12.9❶ 试综述文件有哪几种常用的组织方式?它们各有什么特点?

12.10❸ 假设某个有3000张床位的旅店需为投宿的旅客建立一个便于管理的文件,每个记录是一名旅客的身份和投宿情况,其中旅客的身份证号码(15位十进制数字)可作为主关键字。为了来访客人查询方便,还需建立姓名、投宿日期、从哪儿来等次关键字项索引。请为此文件确定一种组织方式(如:主文件如何组织、各次关键字项索引如何建立等)。

转载注明出处:原文链接
二、算法设计题
12.11❸ 设主文件中每个记录含有账号和余额两个域,事务文件含有账号、存取标记和数额三个域。试写一个批量处理算法,产生更新后的新主文件,如下图所示。各文件均按账号由小到大的顺序排序;你的算法中必须包括检查输入数据错误的能力:将错误记录输出而又不影响后面其他记录的处理。

以上是关于清华大学严蔚敏数据结构题集完整答案(c语言版)的主要内容,如果未能解决你的问题,请参考以下文章