Ceph是一个可靠地、自动重均衡、自动恢复的分布式存储系统,根据场景划分可以将Ceph分为三大块,分别是对象存储、块设备存储和文件系统服务。在虚拟化领域里,比较常用到的是Ceph的块设备存储,比如在OpenStack项目里,Ceph的块设备存储可以对接OpenStack的cinder后端存储、Glance的镜像存储和虚拟机的数据存储,比较直观的是Ceph集群可以提供一个raw格式的块存储来作为虚拟机实例的硬盘。
Ceph相比其它存储的优势点在于它不单单是存储,同时还充分利用了存储节点上的计算能力,在存储每一个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡,同时由于Ceph的良好设计,采用了CRUSH算法、HASH环等方法,使得它不存在传统的单点故障的问题,且随着规模的扩大性能并不会受到影响。
2 Ceph的核心组件
Ceph的核心组件包括Ceph OSD、Ceph Monitor和Ceph MDS。
Ceph OSD:OSD的英文全称是Object Storage Device,它的主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进行心跳检查等,并将一些变化情况上报给Ceph Monitor。一般情况下一块硬盘对应一个OSD,由OSD来对硬盘存储进行管理,当然一个分区也可以成为一个OSD。
Ceph OSD的架构实现由物理磁盘驱动器、Linux文件系统和Ceph OSD服务组成,对于Ceph OSD Deamon而言,Linux文件系统显性的支持了其拓展性,一般Linux文件系统有好几种,比如有BTRFS、XFS、Ext4等,BTRFS虽然有很多优点特性,但现在还没达到生产环境所需的稳定性,一般比较推荐使用XFS。
伴随OSD的还有一个概念叫做Journal盘,一般写数据到Ceph集群时,都是先将数据写入到Journal盘中,然后每隔一段时间比如5秒再将Journal盘中的数据刷新到文件系统中。一般为了使读写时延更小,Journal盘都是采用SSD,一般分配10G以上,当然分配多点那是更好,Ceph中引入Journal盘的概念是因为Journal允许Ceph OSD功能很快做小的写操作;一个随机写入首先写入在上一个连续类型的journal,然后刷新到文件系统,这给了文件系统足够的时间来合并写入磁盘,一般情况下使用SSD作为OSD的journal可以有效缓冲突发负载。
Ceph Monitor:由该英文名字我们可以知道它是一个监视器,负责监视Ceph集群,维护Ceph集群的健康状态,同时维护着Ceph集群中的各种Map图,比如OSD Map、Monitor Map、PG Map和CRUSH Map,这些Map统称为Cluster Map,Cluster Map是RADOS的关键数据结构,管理集群中的所有成员、关系、属性等信息以及数据的分发,比如当用户需要存储数据到Ceph集群时,OSD需要先通过Monitor获取最新的Map图,然后根据Map图和object id等计算出数据最终存储的位置。
Ceph MDS:全称是Ceph MetaData Server,主要保存的文件系统服务的元数据,但对象存储和块存储设备是不需要使用该服务的。
查看各种Map的信息可以通过如下命令:ceph osd(mon、pg) dump
3 Ceph基础架构组件
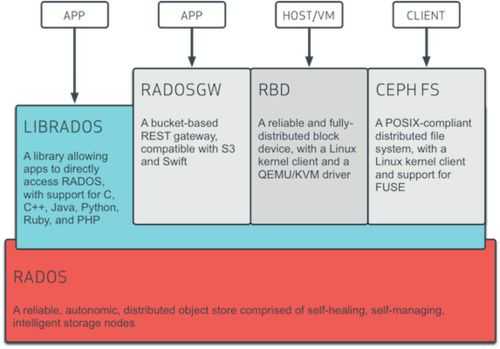
从架构图中可以看到最底层的是RADOS,RADOS自身是一个完整的分布式对象存储系统,它具有可靠、智能、分布式等特性,Ceph的高可靠、高可拓展、高性能、高自动化都是由这一层来提供的,用户数据的存储最终也都是通过这一层来进行存储的,RADOS可以说就是Ceph的核心。
RADOS系统主要由两部分组成,分别是OSD和Monitor。
基于RADOS层的上一层是LIBRADOS,LIBRADOS是一个库,它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言,比如C、C++、Python等。
基于LIBRADOS层开发的又可以看到有三层,分别是RADOSGW、RBD和CEPH FS。
RADOSGW:RADOSGW是一套基于当前流行的RESTFUL协议的网关,并且兼容S3和Swift。
RBD:RBD通过Linux内核客户端和QEMU/KVM驱动来提供一个分布式的块设备。
CEPH FS:CEPH FS通过Linux内核客户端和FUSE来提供一个兼容POSIX的文件系统。
4 Ceph数据分布算法
在分布式存储系统中比较关注的一点是如何使得数据能够分布得更加均衡,常见的数据分布算法有一致性Hash和Ceph的Crush算法。Crush是一种伪随机的控制数据分布、复制的算法,Ceph是为大规模分布式存储而设计的,数据分布算法必须能够满足在大规模的集群下数据依然能够快速的准确的计算存放位置,同时能够在硬件故障或扩展硬件设备时做到尽可能小的数据迁移,Ceph的CRUSH算法就是精心为这些特性设计的,可以说CRUSH算法也是Ceph的核心之一。
在说明CRUSH算法的基本原理之前,先介绍几个概念和它们之间的关系。
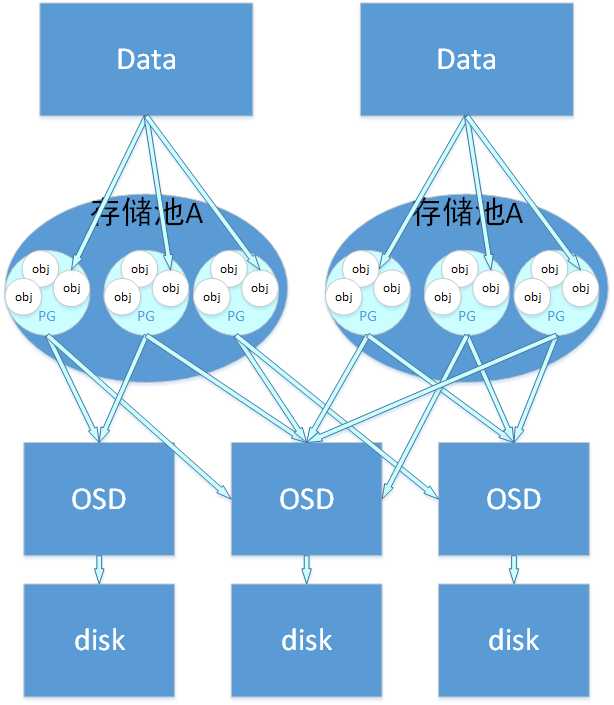
存储数据与object的关系:当用户要将数据存储到Ceph集群时,存储数据都会被分割成多个object,每个object都有一个object id,每个object的大小是可以设置的,默认是4MB,object可以看成是Ceph存储的最小存储单元。
object与pg的关系:由于object的数量很多,所以Ceph引入了pg的概念用于管理object,每个object最后都会通过CRUSH计算映射到某个pg中,一个pg可以包含多个object。
pg与osd的关系:pg也需要通过CRUSH计算映射到osd中去存储,如果是二副本的,则每个pg都会映射到二个osd,比如[osd.1,osd.2],那么osd.1是存放该pg的主副本,osd.2是存放该pg的从副本,保证了数据的冗余。
pg和pgp的关系:pg是用来存放object的,pgp相当于是pg存放osd的一种排列组合,我举个例子,比如有3个osd,osd.1、osd.2和osd.3,副本数是2,如果pgp的数目为1,那么pg存放的osd组合就只有一种,可能是[osd.1,osd.2],那么所有的pg主从副本分别存放到osd.1和osd.2,如果pgp设为2,那么其osd组合可以两种,可能是[osd.1,osd.2]和[osd.1,osd.3],是不是很像我们高中数学学过的排列组合,pgp就是代表这个意思。一般来说应该将pg和pgp的数量设置为相等。这样说可能不够明显,我们通过一组实验来体会下:
先创建一个名为testpool包含6个PG和6个PGP的存储池
ceph osd pool create testpool 6 6
通过写数据后我们查看下pg的分布情况,使用以下命令:
ceph pg dump pgs | grep ^1 | awk ‘{print $1,$2,$15}‘
dumped pgs in format plain
1.1 75 [3,6,0]
1.0 83 [7,0,6]
1.3 144 [4,1,2]
1.2 146 [7,4,1]
1.5 86 [4,6,3]
1.4 80 [3,0,4]
第1列为pg的id,第2列为该pg所存储的对象数目,第3列为该pg所在的osd
我们扩大PG再看看
ceph osd pool set testpool pg_num 12
再次用上面的命令查询分布情况:
1.1 37 [3,6,0]
1.9 38 [3,6,0]
1.0 41 [7,0,6]
1.8 42 [7,0,6]
1.3 48 [4,1,2]
1.b 48 [4,1,2]
1.7 48 [4,1,2]
1.2 48 [7,4,1]
1.6 49 [7,4,1]
1.a 49 [7,4,1]
1.5 86 [4,6,3]
1.4 80 [3,0,4]
我们可以看到pg的数量增加到12个了,pg1.1的对象数量本来是75的,现在是37个,可以看到它把对象数分给新增的pg1.9了,刚好是38,加起来是75,而且可以看到pg1.1和pg1.9的osd盘是一样的。
而且可以看到osd盘的组合还是那6种。
我们增加pgp的数量来看下,使用命令:
ceph osd pool set testpool pgp_num 12
再看下
1.a 49 [1,2,6]
1.b 48 [1,6,2]
1.1 37 [3,6,0]
1.0 41 [7,0,6]
1.3 48 [4,1,2]
1.2 48 [7,4,1]
1.5 86 [4,6,3]
1.4 80 [3,0,4]
1.7 48 [1,6,0]
1.6 49 [3,6,7]
1.9 38 [1,4,2]
1.8 42 [1,2,3]
再看pg1.1和pg1.9,可以看到pg1.9不在[3,6,0]上,而在[1,4,2]上了,该组合是新加的,可以知道增加pgp_num其实是增加了osd盘的组合。
通过实验总结:
(1)PG是指定存储池存储对象的目录有多少个,PGP是存储池PG的OSD分布组合个数
(2)PG的增加会引起PG内的数据进行分裂,分裂相同的OSD上新生成的PG当中
(3)PGP的增加会引起部分PG的分布进行变化,但是不会引起PG内对象的变动
pg和pool的关系:pool也是一个逻辑存储概念,我们创建存储池pool的时候,都需要指定pg和pgp的数量,逻辑上来说pg是属于某个存储池的,就有点像object是属于某个pg的。
以下这个图表明了存储数据,object、pg、pool、osd、存储磁盘的关系
本质上CRUSH算法是根据存储设备的权重来计算数据对象的分布的,权重的设计可以根据该磁盘的容量和读写速度来设置,比如根据容量大小可以将1T的硬盘设备权重设为1,2T的就设为2,在计算过程中,CRUSH是根据Cluster Map、数据分布策略和一个随机数共同决定数组最终的存储位置的。
Cluster Map里的内容信息包括存储集群中可用的存储资源及其相互之间的空间层次关系,比如集群中有多少个支架,每个支架中有多少个服务器,每个服务器有多少块磁盘用以OSD等。
数据分布策略是指可以通过Ceph管理者通过配置信息指定数据分布的一些特点,比如管理者配置的故障域是Host,也就意味着当有一台Host起不来时,数据能够不丢失,CRUSH可以通过将每个pg的主从副本分别存放在不同Host的OSD上即可达到,不单单可以指定Host,还可以指定机架等故障域,除了故障域,还有选择数据冗余的方式,比如副本数或纠删码。
下面这个式子简单的表明CRUSH的计算表达式:
CRUSH(X) -> (osd.1,osd.2.....osd.n)
式子中的X就是一个随机数。
下面通过一个计算PG ID的示例来看CRUSH的一个计算过程:
(1)Client输入Pool ID和对象ID;
(2)CRUSH获得对象ID并对其进行Hash运算;
(3)CRUSH计算OSD的个数,Hash取模获得PG的ID,比如0x48;
(4)CRUSH取得该Pool的ID,比如是1;
(5)CRUSH预先考虑到Pool ID相同的PG ID,比如1.48。