pytorch1.0 搭建LSTM网络
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch1.0 搭建LSTM网络相关的知识,希望对你有一定的参考价值。
参考技术A torch.nn包下实现了LSTM函数,实现LSTM层。多个LSTMcell组合起来是LSTM。LSTM自动实现了前向传播,不需要自己对序列进行迭代。
LSTM的用到的参数如下:创建LSTM指定如下参数,至少指定前三个参数
其中,指定batch_first=True后,input就是(batch_size,seq_len,input_size)
(h0,c0)是初始的隐藏层,因为每个LSTM单元其实需要两个隐藏层的。记hidden=(h0,c0)
其中,h0的维度是(num_layers*num_directions, batch_size, hidden_size)
c0维度同h0。注意,即使batch_first=True,这里h0的维度依然是batch_size在第二维度
其中,out是每一个时间步的最后一个隐藏层h的输出,假如有5个时间步(即seq_len=5),则有5个对应的输出,out的维度是:(batch_size,seq_len,hidden_size)
而hidden=(hn,cn),他自己实现了时间步的迭代,每次迭代需要使用上一步的输出和hidden层,最后一步hidden=(hn,cn)记录了最后一各时间步的隐藏层输出,有几层对应几个输出,如果这个是RNN-encoder,则hn,cn就是中间的编码向量。hn的维度是(num_layers*num_directions,batch_size,hidden_size),cn同。
基于pytorch搭建多特征LSTM时间序列预测代码详细解读(附完整代码)
文章目录
LSTM时间序列预测
对于LSTM神经网络的概念想必大家也是熟练掌握了,所以本文章不涉及对LSTM概念的解读,仅解释如何使用pytorch使用LSTM进行时间序列预测,复原使用代码实现的全流程。
数据获取与预处理
首先预览一下本次实验使用的数据集,该数据集共有三个特征,将最后一列的压气机出口温度作为标签预测(该数据集是我在git上收集到的)

定义一个xls文件读取的函数,其中data.iloc()函数是将dataframe中的数据进行切片,返回数据和标签
# 文件读取
def get_Data(data_path):
data=pd.read_excel(data_path)
data=data.iloc[:,:3] # 以三个特征作为数据
label=data.iloc[:,2:] # 取最后一个特征作为标签
print(data.head())
print(label.head())
return data,label
使用sklearn中的preprocessing模块中的归一化函数对数据进行归一化处理,其中data=data.values函数是将dataframe中的数据从pd格式转换np数组,删除轴标签,fit_transform函数是fit()和transform()的组合,是将fit和transform合并,一步到位的结果,最后返回data,label和归一化的标签值
# 数据预处理
def normalization(data,label):
mm_x=MinMaxScaler() # 导入sklearn的预处理容器
mm_y=MinMaxScaler()
data=data.values # 将pd的系列格式转换为np的数组格式
label=label.values
data=mm_x.fit_transform(data) # 对数据和标签进行归一化等处理
label=mm_y.fit_transform(label)
return data,label,mm_y
我们将数据进行归一化之后,数据是np数组格式,我们需要将其转换成向量的格式存储在列表当中,因此,先创建两个空列表,建立一个for循环将预处理过的数据最后按x.size(0),seq_length,features)的纬度输出至列表当中。其中seq_length代表的是时间步长,x.size(0)则表示的是数据的第一维度,features代表的是数据的特征数。打印x,y的维度并返回x,y。
# 时间向量转换
def split_windows(data,seq_length):
x=[]
y=[]
for i in range(len(data)-seq_length-1): # range的范围需要减去时间步长和1
_x=data[i:(i+seq_length),:]
_y=data[i+seq_length,-1]
x.append(_x)
y.append(_y)
x,y=np.array(x),np.array(y)
print('x.shape,y.shape=\\n',x.shape,y.shape)
return x,y
将数据和标签都准备好之后即可分离数据,将数据分离成训练集和测试集。定义split_data()函数,其中split_ratio是设定的测试集比例,本次实验设置的训练集与测试集之比为9:1,即split_ratio=0.1。将分离好的数据分别装入Variable中封装好,并且将array转换成tensor格式,得到测试集和训练集。注意,一定要使用Variable函数对数据集进行封装,否则不支持后面torch的迭代。
# 数据分离
def split_data(x,y,split_ratio):
train_size=int(len(y)*split_ratio)
test_size=len(y)-train_size
x_data=Variable(torch.Tensor(np.array(x)))
y_data=Variable(torch.Tensor(np.array(y)))
x_train=Variable(torch.Tensor(np.array(x[0:train_size])))
y_train=Variable(torch.Tensor(np.array(y[0:train_size])))
y_test=Variable(torch.Tensor(np.array(y[train_size:len(y)])))
x_test=Variable(torch.Tensor(np.array(x[train_size:len(x)])))
print('x_data.shape,y_data.shape,x_train.shape,y_train.shape,x_test.shape,y_test.shape:\\n'
.format(x_data.shape,y_data.shape,x_train.shape,y_train.shape,x_test.shape,y_test.shape))
return x_data,y_data,x_train,y_train,x_test,y_test
将封装好的训练集和测试集装入torch支持的可迭代对象torch.utils.data.DataLoader中,num_epochs是计算得到的迭代次数,返回train_loader,test_loader,num_epochs,这样,数据集就预处理好了,可以进行模型的搭建了。
# 数据装入
def data_generator(x_train,y_train,x_test,y_test,n_iters,batch_size):
num_epochs=n_iters/(len(x_train)/batch_size) # n_iters代表一次迭代
num_epochs=int(num_epochs)
train_dataset=Data.TensorDataset(x_train,y_train)
test_dataset=Data.TensorDataset(x_test,y_test)
train_loader=torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=False,drop_last=True) # 加载数据集,使数据集可迭代
test_loader=torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False,drop_last=True)
return train_loader,test_loader,num_epochs
模型构建
使用torch构建模型无非就是定义一个类,在这个类中定义一个模型实例和前向传播函数,就这么简单,接下来让我们来看看。
# 定义一个类
class Net(nn.Module):
def __init__(self,input_size,hidden_size,num_layers,output_size,batch_size,seq_length) -> None:
super(Net,self).__init__()
self.input_size=input_size
self.hidden_size=hidden_size
self.num_layers=num_layers
self.output_size=output_size
self.batch_size=batch_size
self.seq_length=seq_length
self.num_directions=1 # 单向LSTM
self.lstm=nn.LSTM(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers,batch_first=True) # LSTM层
self.fc=nn.Linear(hidden_size,output_size) # 全连接层
def forward(self,x):
# e.g. x(10,3,100) 三个句子,十个单词,一百维的向量,nn.LSTM(input_size=100,hidden_size=20,num_layers=4)
# out.shape=(10,3,20) h/c.shape=(4,b,20)
batch_size, seq_len = x.size()[0], x.size()[1] # x.shape=(604,3,3)
h_0 = torch.randn(self.num_directions * self.num_layers, x.size(0), self.hidden_size)
c_0 = torch.randn(self.num_directions * self.num_layers, x.size(0), self.hidden_size)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(x, (h_0, c_0)) # output(5, 30, 64)
pred = self.fc(output) # (5, 30, 1)
pred = pred[:, -1, :] # (5, 1)
return pred
首先定义一个实例,其中包括必须参数input_size,hidden_size,num_layers,output_size,batch_size,seq_length。将self.num_directions设置为1代表这是一个单项的LSTM,然后再添加一个lstm层和一个全连接层fc,lstm层输入维度为(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers),设置了,batch_first=True则代表shape=(batch_size,seq_size,hidden_size),fc层的参数为(hidden_size,output_size),返回pred
训练与测试
训练模型,初始化i,(batch_x, batch_y),将train_loader设置为枚举类型,optimizer.zero_grad() 代表将每次传播时的梯度累积清除,torch中如果不声明optimizer.zero_grad()则会一直累积计算梯度,设置每100次输入打印一次损失
# train
iter=0
for epochs in range(num_epochs):
for i,(batch_x, batch_y) in enumerate (train_loader):
outputs = moudle(batch_x)
optimizer.zero_grad() # 将每次传播时的梯度累积清除
# print(outputs.shape, batch_y.shape)
loss = criterion(outputs,batch_y) # 计算损失
loss.backward() # 反向传播
optimizer.step()
iter+=1
if iter % 100 == 0:
print("iter: %d, loss: %1.5f" % (iter, loss.item()))
最后几次损失如下
iter: 2400, loss: 0.00331
iter: 2500, loss: 0.00039
...
iter: 4400, loss: 0.00332
iter: 4500, loss: 0.00022
iter: 4600, loss: 0.00380
iter: 4700, loss: 0.00032
将最后训练集和测试集的MAE/RMSE画出,得到最终结果。
def result(x_data, y_data):
moudle.eval()
train_predict = moudle(x_data)
data_predict = train_predict.data.numpy()
y_data_plot = y_data.data.numpy()
y_data_plot = np.reshape(y_data_plot, (-1,1))
data_predict = mm_y.inverse_transform(data_predict)
y_data_plot = mm_y.inverse_transform(y_data_plot)
plt.plot(y_data_plot)
plt.plot(data_predict)
plt.legend(('real', 'predict'),fontsize='15')
plt.show()
print('MAE/RMSE')
print(mean_absolute_error(y_data_plot, data_predict))
print(np.sqrt(mean_squared_error(y_data_plot, data_predict) ))
result(x_data, y_data)
result(x_test,y_test)
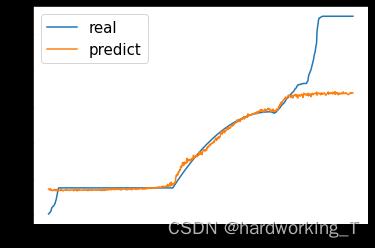

最终结果:训练集:MAE/RMSE:35.114613\\75.8706
测试集:MAE/RMSE:213.30313\\213.31061
本文仅作示范pytorch构建lstm的用法,预测结果不是很准确,像dropout等都没加,仅供参考。
完整代码见我的github:https://github.com/Tuniverj/Pytorch-lstm-forecast
以上是关于pytorch1.0 搭建LSTM网络的主要内容,如果未能解决你的问题,请参考以下文章