PHP MYSQL求一个获取主键的简单方法吧!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PHP MYSQL求一个获取主键的简单方法吧!相关的知识,希望对你有一定的参考价值。
我需要获取自增主键的值来做判断,求个方法呀。
参考技术A 自增主键不都是创建数据表的时候规定好的吗?`id` int(10) NOT NULL AUTO_INCREMENT,
你是想获得这个id的值来判断吗? 参考技术B 每次insert一条数据后再执行一条sql就行了,SELECT LAST_INSERT_ID() AS lastinsertid 参考技术C 查询出最大的一个。我只能想到这种
MySQL基础学习二
MySQL数据库基础知识
一,数据库的安装,连接
官网下载:https://www.mysql.com/downloads/ 下载最新版本和其他所需插件
数据库安装有两种方式
1,在windows下使用安装包直接安装,在安装过程中,软件会自动配置好环境变量,图形界面。软件自动检测系统环境是否完整,在发现不完整后会自动安装所需组件,只要傻瓜式的点击下一步就可以安装完成。
2,使用zip压缩包进行安装: 1):官网下载zip包,解压到自定义文件。
2):打开解压后的文件,进入bin目录下,在文件下有 mysqld ,mysql两个文件
(mysql数据这类软件都是基于socket C/S模式进行操作的,所以在安装之前我们要分清客户端与服务端软件,先安装服务端(mysqld),再打开客户端使用(mysql))
3):复制bin文件路径,打开命令行窗口,粘贴路径,进入bin目录下。
4):使用命令 mysqld --initialize-insecure命令,初始化数据库,安装服务端(如果数据库安装不成功,到安装文件目录下确认是否有data这个文件夹,有些安装不成都是因为在解压后就已经存在data目录,数据库在初始化时不成功,导致无法启动,需要删除重新使用命令 mysqld --initialize 进行初始化操作)
5):在初始化安装后,配置环境变量,将bin目录文件路径添加到windows环境变量中。
6):安装windows启动服务,使用命令 mysqld --install(此处没有添加成功,可以把bin文件路径添加后再安装服务)
7):使用命令 net start MySQL 启动服务(启动不成功的,需要重启一下系统)
8):启动命令行窗口,使用命令mysql -u root -p 连接服务端。(mysql初始化有一个root用户,密码为空)
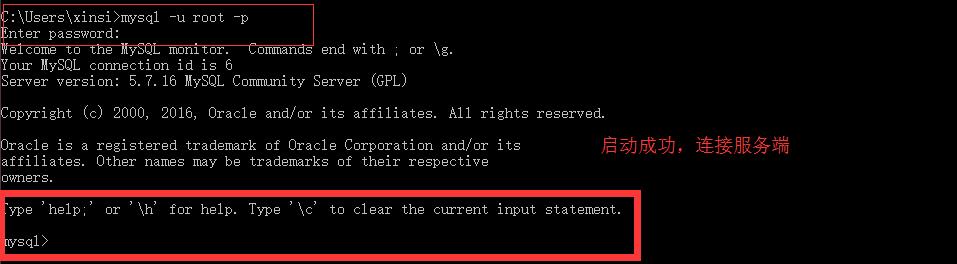
二,MySQL数据库基本操作
使用数据库我们需要连接登录,在数据库初始化时会自动创建一个root用户,我们也可以自己创建用户,方便数据的使用,维护。
创建用户:
create user "username/用户名"@“指定的ip主机” identified by \'123123\';
(在指定ip地址主机的时候可以使用 % 匹配任何主机)
设置用户权限:
grant select,insert,update on db1.t1 to \'alex\'@\'%\';(设置该用户权限为增,查,改)
grant all privileges on db1.t1 to \'alex\'@\'%\'; (设置该用户超级用户,用户完整的表操作权限)
revoke all privileges on db1.t1 from \'alex\'@\'%\';(去除该用户的用户权限)
数据库的基本操作
1,显示数据库信息,显示数据表名 show命令
show databases :显示数据库名称
show tables :显示数据表名
2,数据库的创建,使用,操作
使用:
use 数据库名 :进入该数据库
创建:
create database 数据库名 :创建数据库
在创建数据库的时候需要指定字节编码,default charset="编码格式",推荐使用utf8
删除:
drop database 数据库名 :删除数据库
3,数据表操作
创建:
create table 表名 (
列名1 int auto_increment primary key not null ,
列名2 char(10)
)engine=innodb default charset="utf8" :创建数据表
auto_increment 自增键,该列数值会随着行数的增加而进行加操作,一般都设置为行ID
primary key 设置该列为主键,主键就是一种索引,可以加速数据的查找
在创建数据表的时候也需要指定字节编码,default charset="编码格式",推荐使用utf8,同时需要创建事务 engine=innodb 操作回滚
innodb:数据库引擎,事务操作,对关键数据的改增,在发生意外后,有回滚操作
default charset :指定字节编码
清除:
delete from tablename :清空数据表数据
truncate table tablename :清空数据表及自增量数值归零
在设置自增列,清空数据表后,自增量不会改变,插入数据会根据已增加量为起始值进行自增,所以需要truncate清空自增量
删除:
drop table 表名 :删除表
4,数据行操作
查看:
select * from tablename :查看数据表所有行内容
select * from tablename where 列名 表达式 :带条件查看符合的行数据
select 列名 from tablename :只显示该指定列数据
select 列1,列2 from tablename :查询该表的多列数据
增加:
insert into tablename (列名1,列名2) value(数值1,数值2)
insert into tablename (列名1,列名2) values(数值1,数值2),(数值3,数值4) 这句与上一句的区别在于可以一次插入多行数据。
修改:
updata tablename set 列名=更新的数值
updata tablename set 列名=更新的数值 where 列名+条件表达式
删除:
delete from tablename where 列名+条件表达式
5,数据表的关系操作
主键:
主键是索引的一种,并且是唯一性索引,且必须定义为primary key。一个表只有一个主键,主键可以由多列组成。
声明主键的关键字为:primary key
简单的一个声明主键的示例:
create table score(sid int auto_increment primary key)engine=innodb default charset=utf8 primary key为声明的关键字。
外键
如果一个实体的某个字段指向另一个实体的主键,就称为外键。
被指向的实体,称之为主实体(主表),也叫父实体(父表)。
负责指向的实体,称之为从实体(从表),也叫子实体(子表)。
作用:用于约束处于关系内的实体。增加子表记录的时候,是否有与之对应的父表记录,如果主表没有相关的记录,从表不能插入。
外键示例代码:
#创建被关联的子表 create table class(cid int auto_increment primary key,clname char(20))engine=innodb default charset=utf8; #插入数据 insert into class(clname) values("三年级"),("一年级"),("四年级"),("二年级"); #创建主表(父表) create table student(sid int auto_increment primary key,sname char(12), class_id int,constraint fk_id_class foreign key(class_id) references class(cid)) engine=innodb default charset=utf8; #constraint fk_id_class foreign key(class_id) references class(cid)关键词,foreign key后跟父表列名,reference后加子表列名。 insert into student(sname,class_id) values("stu1"),("stu2"),("stu3");
外键变种:
外键与主键都有唯一索引,且都不能重复。区别就是主键不能为空,外键的唯一索引可以为空。
外键变种分为以下几种关系:
一对多,一对一,多对多
1,一对一关系:
create table userinfo1( id int auto_increment primary key, name char(10), gender char(10), email varchar(64) )engine=innodb default charset=utf8; create table admin( id int not null auto_increment primary key, username varchar(64) not null, password VARCHAR(64) not null, user_id int not null, unique uq_u1 (user_id),#关键字,指定外键的一对一关系 CONSTRAINT fk_admin_u1 FOREIGN key (user_id) REFERENCES userinfo1(id) )engine=innodb default charset=utf8;
2,一对多关系
3,多对多关系
create table userinfo2( id int auto_increment primary key, name char(10), gender char(10), email varchar(64) )engine=innodb default charset=utf8; create table host( id int auto_increment primary key, hostname char(64) )engine=innodb default charset=utf8; create table user2host( id int auto_increment primary key, userid int not null, hostid int not null, unique uq_user_host (userid,hostid),#关键字,指定为多对多的关系语句 CONSTRAINT fk_u2h_user FOREIGN key (userid) REFERENCES userinfo2(id), CONSTRAINT fk_u2h_host FOREIGN key (hostid) REFERENCES host(id) )engine=innodb default charset=utf8;
数据表的操作:
插入,修改,选择,删除数据:
#一次插入多条数据的方式: insert into student(sname,class_id) values("stu1"),("stu2"),("stu3"); #修改表内数据 update student set sname="stu10" #操作显示表数据 select sid,sname from student;#显示学生表的id与学生名字 select sid,sname from student where sid>3;显示表中sid大于3,的学生id与姓名 #删除表数据 delete from student where id=1;#删除表中id为1的数据
where条件语句
where:条件限制语句,在数据操作中需要对数据进行按条件筛选,就需要用到where语句。在使用时徐注意:
where函数条件后不允许加聚合函数条件
语法: where 条件表达式
条件表达式的运算符
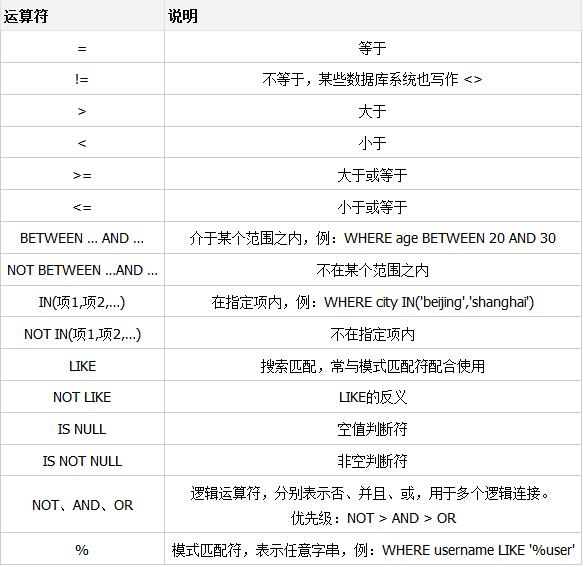
模糊匹配的关键字 like
模糊匹配补充 _下划线 指的是该字符之后的一个任意数值,示例:where username like"a_"
自增数据操作
在数据表的会经常设置自增数据,自增数据是可以对其进行修改查看等操作的。由于mysql的步长是基于会话操作的,每次修改针对的是每一个会话而不是全局,如果需要对全局进行修改要是global
查看:
show session variables like \'auto_inc%\'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set, 1 warning (0.00 sec)
修改自增步长:
set session auto_increment_increment=2; Query OK, 0 rows affected (0.00 sec) show session variables like \'auto_inc%\'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 2 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set, 1 warning (0.00 sec)
全局查看:
全局查看是基于关键字global。
设置全局步长值:set global auto_increment_increment=2;
show global variables like \'auto_inc%\'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set, 1 warning (0.00 sec)
索引:
作用:约束,和加速查找
索引有以下几种:
主键索引:加速查找,主键不能为空且不能重复
普通索引:加速查找
唯一索引:加速查找,且键值不能为空
联合索引(多列组合)
联合主键索引
联合唯一索引
联合普通索引
全文索引:对文本的内容进行分词,进行搜素。
数据表无索引的时候,数据行从前到后一次查找,速度相对较慢
当数据表有索引时,查找速读快,但是对于表的增删改会减慢速度,因为在建立索引的时候会建立一张索引表,在对表进行增删改的操作时,需要对索引文件进行操作。
索引的种类:
hash:哈希索引,特点时速度快,但是对于范围文件的查找,速度较慢
btree:二叉树,索引文件的建立查找会以二分形式树形结构向下发展
索引的建立可以加速数据的查找,1,使用额外的文件保存特殊的数据结构
2,查询快,插入更新删除慢(因为额外的文件需要操作)
3,命中索引
索引建立:
主键索引: primary key
普通索引:create index 索引名称 on 表名(列名)
删除索引:
drop index 索引名称 on 表名
唯一索引: create unique index 索引名称 on 表名(列名)
删除索引:
drop unique index 索引名称 on 表名
组合索引(遵循最左前缀匹配):
create unique index 索引名称 on表名(列名1,列名2)
删除索引:
drop unique index 索引名称 on 表名(列名1,列名2)
最左前缀匹配的概念实操:
建立一个组合索引:
create index 索引名称 on 表名 (name,email)
例子1 select * from 表名 where name=“alex”(符合最左前缀匹配,在查找时可以加速查找)
例子2 select * from 表名 where name=“alex” and email="1234@qq.com"(符合最左前缀匹配)
例子3 select * from 表名 where email=\'1234@qq.com\';(这种查询方式不符合最左前缀匹配的规则,无法加速查找)
索引合并:
索引合并中的索引列,每一个都可以单独使用,没有规则限制,但是索引合并的效率要小于组合索引
名词:
覆盖索引:
在索引文件中直接获取数据:
create index 索引名 on 表名 (id)
select id from 表名 (直接使用索引名称,获取索引值的方式就叫覆盖索引)
索引合并:
把多个单列索引合并使用
建立索引的原则,就是根据我们的工作需求,去对某列建立索引,频繁使用操作的列应该建立索引
我们建立了索引,索引会加快我们对数据的查找速度,但是有时候即使我们建立了索引,也会出现速度很慢的情况,这就牵扯了一个索引命中的问题,在什么情况下,我们建立的索引会失效
1,like "%ss" 语句中含有模糊匹配
2,函数,内置函数还有自定义函数
3,or 条件语句
select * from tb1 where nid = 1 or name = \'seven@live.com\';
例外:当or条件中有未建立索引的列才失效
select * from tb1 where nid = 1 or name = \'seven\';
select * from tb1 where nid = 1 or name = \'seven@live.com\' and email = \'alex\'
4,类型不一致
列与传入查找的列的数值类型应该相同,不同的话,索引将失效
5,!= 在查找语句中,where 条件表达式有不等于操作,索引将失效
例外:如果该列为主键,查找将走索引
6,> select * from tb1 where email > \'alex\'
例外:如果是主键或索引是整数类型,则还是会走索引
select * from tb1 where nid > 123
select * from tb1 where num > 123
7,order by
select name from tb1 order by email desc;
当根据索引排序时候,选择的映射如果不是索引,则不走索引
特别的:如果对主键排序,则还是走索引:
select * from tb1 order by nid desc;
8,组合索引最左前缀
组合索引为(name,email)
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
索引的目的是为了加快数据库的搜索,所以我们要避免以下操作出现
1,避免使用select * 尽量不要对全表进行搜索,这样会只会拖慢整体速度,做到按需操作
2,count(1)或count(列)代替count(*)
3,创建表时能用char就不要用varchar,对于定长的char,数据库可以很快的对字符进行筛选
4,表的字段顺序固定长度的字段优先
5,组合索引代替多个单列索引(在经常使用多个条件查询时)
6,尽量使用短索引
7,使用连接来代替子查询
8,连表时注意条件类型需一致
9,索引的散列值不适合建立索引
limit分页操作
select * from tb1 where nid < (select nid from (select nid from tb1 where nid < 当前页最小值 order by nid desc limit 每页数据 *【页码-当前页】) A order by A.nid asc limit 1) order by nid desc limit 10; select * from tb1 where nid < (select nid from (select nid from tb1 where nid < 970 order by nid desc limit 40) A order by A.nid asc limit 1) order by nid desc limit 10; 下一页: select * from tb1 where nid < (select nid from (select nid from tb1 where nid > 当前页最大值 order by nid asc limit 每页数据 *【当前页-页码】) A order by A.nid asc limit 1) order by nid desc limit 10; select * from tb1 where nid < (select nid from (select nid from tb1 where nid > 980 order by nid asc limit 20) A order by A.nid desc limit 1) order by nid desc limit 10;
执行计划
explain +查询sql 可以显示sql执行信息参数,根据参考信息可以进行sql优化

图中内容显示该表查询类型为all,全表逐条查询。没有设置主键,没有索引,这张表的速度将会很慢
select_type 查询类型 SIMPLE 简单查询 PRIMARY 最外层查询 SUBQUERY 映射为子查询 DERIVED 子查询 UNION 联合 UNION RESULT 使用联合的结果 ... table 正在访问的表名 type 查询时的访问方式,性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const ALL 全表扫描,对于数据表从头到尾找一遍 select * from tb1; 特别的:如果有limit限制,则找到之后就不在继续向下扫描 select * from tb1 where email = \'seven@live.com\' select * from tb1 where email = \'seven@live.com\' limit 1; 虽然上述两个语句都会进行全表扫描,第二句使用了limit,则找到一个后就不再继续扫描。 INDEX 全索引扫描,对索引从头到尾找一遍 select nid from tb1; RANGE 对索引列进行范围查找 select * from tb1 where name < \'alex\'; PS: between and in > >= < <= 操作 注意:!= 和 > 符号 INDEX_MERGE 合并索引,使用多个单列索引搜索 select * from tb1 where name = \'alex\' or nid in (11,22,33); REF 根据索引查找一个或多个值 select * from tb1 where name = \'seven\'; EQ_REF 连接时使用primary key 或 unique类型 select tb2.nid,tb1.name from tb2 left join tb1 on tb2.nid = tb1.nid; CONST 常量 表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快,因为它们只读取一次。 select nid from tb1 where nid = 2 ; SYSTEM 系统 表仅有一行(=系统表)。这是const联接类型的一个特例。 select * from (select nid from tb1 where nid = 1) as A; possible_keys 可能使用的索引 key 真实使用的 key_len MySQL中使用索引字节长度 rows mysql估计为了找到所需的行而要读取的行数 ------ 只是预估值 extra 该列包含MySQL解决查询的详细信息 “Using index” 此值表示mysql将使用覆盖索引,以避免访问表。不要把覆盖索引和index访问类型弄混了。 “Using where” 这意味着mysql服务器将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,
因此不是所有带where子句的查询都会显示“Using where”。有时“Using where”的出现就是一个暗示:查询可受益于不同的索引。 “Using temporary” 这意味着mysql在对查询结果排序时会使用一个临时表。 “Using filesort” 这意味着mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,
explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成。 “Range checked for each record(index map: N)” 这个意味着没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的。
以上是关于PHP MYSQL求一个获取主键的简单方法吧!的主要内容,如果未能解决你的问题,请参考以下文章