web框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了web框架相关的知识,希望对你有一定的参考价值。
第一篇web框架
http协议
web应用和web框架
主 文
http协议
HTTP简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP是一个基于TCP/IP通信协议来传递数据(html 文件, 图片文件, 查询结果等)。
HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。目前在WWW中使用的是HTTP/1.0的第六版,HTTP/1.1的规范化工作正在进行之中,而且HTTP-NG(Next Generation of HTTP)的建议已经提出。
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。

HTTP特点
1、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。
由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。
缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
HTTP请求协议
请求协议遵照以下格式:
请求首行; // 协议和版本 请求路径 请求方式,例如:Http1.1/index.html /GET 请求头信息; // 请求头名称:请求头内容,即为key:value格式,例如:Host:localhost 空行; // 用来与请求体分隔开 请求体。 // GET没有请求体,只有POST有请求体。
浏览器发送给服务器的内容就这个格式的,如果不是这个格式服务器将无法解读!在HTTP协议中,请求有很多请求方法,其中最为常用的就是GET和POST。
get请求
HTTP/1.1/562f25980001b1b106000338.jpg/GET Host img.mukewang.com User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36 Accept image/webp,image/*,*/*;q=0.8 Referer http://www.imooc.com/ Accept-Encoding gzip, deflate, sdch Accept-Language zh-CN,zh;q=0.8
HTTP默认的请求方法就是GET
* 没有请求体
* 数据量有限制!
* GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
1、Host
请求的web服务器域名地址
2、User-Agent
HTTP客户端运行的浏览器类型的详细信息。通过该头部信息,web服务器可以判断出http请求的客户端的浏览器的类型。
3、Accept
指定客户端能够接收的内容类型,内容类型的先后次序表示客户都接收的先后次序
4、Accept-Lanuage
指定HTTP客户端浏览器用来展示返回信息优先选择的语言
5、Accept-Encoding
指定客户端浏览器可以支持的web服务器返回内容压缩编码类型。表示允许服务器在将输出内容发送到客户端以前进行压缩,以节约带宽。
而这里设置的就是客户端浏览器所能够支持的返回压缩格式。
6、Accept-Charset
HTTP客户端浏览器可以接受的字符编码集
7、Content-Type
显示此HTTP请求提交的内容类型。一般只有post提交时才需要设置该属性
有关Content-Type属性值有如下两种编码类型:
(1)“application/x-www-form-urlencoded”: 表单数据向服务器提交时所采用的编码类型,默认的缺省值就是“application/x-www-form-urlencoded”。
然而,在向服务器发送大量的文本、包含非ASCII字符的文本或二进制数据时这种编码方式效率很低。
(2)“multipart/form-data”: 在文件上载时,所使用的编码类型应当是“multipart/form-data”,它既可以发送文本数据,也支持二进制数据上载。
当提交为表单数据时,可以使用“application/x-www-form-urlencoded”;当提交的是文件时,就需要使用“multipart/form-data”编码类型。
post请求
POST / HTTP1.1 Host:www.wrox.com User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022) Content-Type:application/x-www-form-urlencoded Content-Length:40 Connection: Keep-Alive name=Professional%20Ajax&publisher=Wiley
HTTP响应协议
响应格式
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文
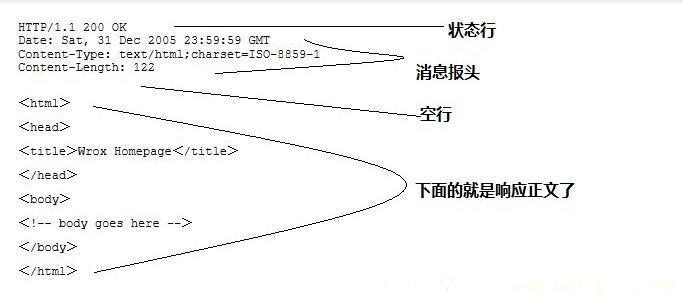
http响应消息格式.jpg
例子:
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
<html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息
第二行和第三行为消息报头,
Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
第三部分:空行,消息报头后面的空行是必须的
第四部分:响应正文,服务器返回给客户端的文本信息。
空行后面的html部分为响应正文
响应状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别: 1xx:指示信息--表示请求已接收,继续处理 2xx:成功--表示请求已被成功接收、理解、接受 3xx:重定向--要完成请求必须进行更进一步的操作 4xx:客户端错误--请求有语法错误或请求无法实现 5xx:服务器端错误--服务器未能实现合法的请求 常见状态码: 200 OK //客户端请求成功 400 Bad Request //客户端请求有语法错误,不能被服务器所理解 401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 403 Forbidden //服务器收到请求,但是拒绝提供服务 404 Not Found //请求资源不存在,eg:输入了错误的URL 500 Internal Server Error //服务器发生不可预期的错误 503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
GET和POST请求的区别
GET请求 GET /books/?sex=man&name=Professional HTTP/1.1 Host: www.wrox.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6) Gecko/20050225 Firefox/1.0.1 Connection: Keep-Alive 注意最后一行是空行 POST请求 POST / HTTP/1.1 Host: www.wrox.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6) Gecko/20050225 Firefox/1.0.1 Content-Type: application/x-www-form-urlencoded Content-Length: 40 Connection: Keep-Alive name=Professional%20Ajax&publisher=Wiley
1、GET提交,请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,多个参数用&连接;例 如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如: %E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:把提交的数据放置在是HTTP包的包体中。上文示例中红色字体标明的就是实际的传输数据
因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变。
2、传输数据的大小:首先声明:HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。
而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如 IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系 统的支持。
因此对于GET提交时,传输数据就会受到URL长度的 限制。
POST:由于不是通过URL传值,理论上数据不受 限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
GET和POST的区别
-
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
-
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
-
GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
-
GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码
web应用和web框架
1.对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端
import socket
sk = socket.socket()
sk.bind((\'127.0.0.1\', 8888))
sk.listen()
while True:
conn, addr = sk.accept()
data = conn.recv(8192)
conn.send(b\'OK\')
conn.close()
这种情况下,用浏览器是不能连接socket服务端的,引出第2点
2、增加HTTP协议响应头
import socket
sk = socket.socket()
sk.bind((\'127.0.0.1\', 8888))
sk.listen()
while True:
conn, addr = sk.accept()
data = conn.recv(8192)
conn.send(b\'HTTP/1.1 200 OK\\r\\n\\r\\n\')
conn.send(b\'OK\')
conn.close()
3、根据用户请求不同的URL返回不同的内容
import socket sk = socket.socket() sk.bind((\'127.0.0.1\', 8888)) sk.listen() # 将不同的页面封装成不同的函数 def index(url): page = "这是 {} 页面!".format(url) return bytes(page, encoding="utf8") def home(url): page = "这是 {} 页面!".format(url) return bytes(page, encoding="utf8") while True: conn, addr = sk.accept() data = conn.recv(8192) # 根据接收用户的信息获取url路径 data = str(data, encoding=\'utf-8\') data1 = data.split("\\r\\n")[0] url = data1.split()[1] # 根据不同的路径返回不同内容 if url == "/index/": response = index(url) elif url == "/home/": response = home(url) else: response = b"404 NOT FOUND"
4、用反射优化请求不同URL返回不同内容
import socket
sk = socket.socket()
sk.bind((\'127.0.0.1\', 8888))
sk.listen()
# 将不同的页面封装成不同的函数
def index(url):
page = "这是 {} 页面!".format(url)
return bytes(page, encoding="utf8")
def home(url):
page = "这是 {} 页面!".format(url)
return bytes(page, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
url_list = [
("/index/", index),
("/home/", home),
]
while True:
conn, addr = sk.accept()
data = conn.recv(8192)
# 根据接收用户的信息获取url路径
data = str(data, encoding="utf-8")
data1 = data.split("\\r\\n")[0]
url = data1.split()[1]
# 根据不同的路径返回不同内容
func = None
for i in url_list:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 NOT FOUND"
# 给客户端发送数据
conn.send(b\'HTTP/1.1 200 OK\\r\\nContent-Type: text/html; charset=utf-8\\r\\n\\r\\n\')
conn.send(response)
conn.close()
5、返回完整的静态HTML
import socket
sk = socket.socket()
sk.bind((\'127.0.0.1\', 8888))
sk.listen()
# 将不同的页面封装成不同的函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
url_list = [
("/index/", index),
("/home/", home),
]
while True:
conn, addr = sk.accept()
data = conn.recv(8192)
# 根据接收用户的信息获取url路径
data = str(data, encoding="utf-8")
data1 = data.split("\\r\\n")[0]
url = data1.split()[1]
# 根据不同的路径返回不同内容
func = None
for i in url_list:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 NOT FOUND"
# 给客户端发送数据
conn.send(b\'HTTP/1.1 200 OK\\r\\nContent-Type: text/html; charset=utf-8\\r\\n\\r\\n\')
conn.send(response)
conn.close()
6、返回动态的HTML,本质上就是HTML内容中利用一些特殊的符号来替换要展示的数据;
import time
import socket
sk = socket.socket()
sk.bind((\'127.0.0.1\', 8888))
sk.listen()
# 将不同的页面封装成不同的函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.asctime(time.localtime(time.time())))
s = s.replace("@@oo@@", now)
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
url_list = [
("/index/", index),
("/home/", home),
]
while True:
conn, addr = sk.accept()
data = conn.recv(8192)
# 根据接收用户的信息获取url路径
data = str(data, encoding="utf-8")
data1 = data.split("\\r\\n")[0]
url = data1.split()[1]
# 根据不同的路径返回不同内容
func = None
for i in url_list:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 NOT FOUND"
# 给客户端发送数据
conn.send(b\'HTTP/1.1 200 OK\\r\\nContent-Type: text/html; charset=utf-8\\r\\n\\r\\n\')
conn.send(response)
conn.close()
模板渲染有个现成的工具:jinja2
7、返回动态的HTML,wsgiref版
import time
from wsgiref.simple_server import make_server
# 将不同的页面封装成不同的函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.asctime(time.localtime(time.time())))
s = s.replace("@@oo@@", now)
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
url_list = [
("/index/", index),
("/home/", home),
]
def run_server(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html;charset=utf8\'), ]) # 设置HTTP响应的状态码和头信息
url = environ[\'PATH_INFO\'] # 取到用户输入的url
# 根据不同的路径返回不同内容
func = None
for i in url_list:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 NOT FOUND"
return [response, ]
if __name__ == \'__main__\':
httpd = make_server(\'127.0.0.1\', 8888, run_server)
print("Serving HTTP on port 8888...")
httpd.serve_forever()
8、返回动态的HTML,wsgiref + jinja2 版
import time
import jinja2
from wsgiref.simple_server import make_server
# 将不同的页面封装成不同的函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.asctime(time.localtime(time.time())))
s = s.replace("@@oo@@", now)
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
def person(url):
with open("person.html", "r", encoding="utf8") as f:
s = f.read()
# 生成一个jinja2的Template(模板)对象
template = jinja2.Template(s)
data = {"name": "Yang", "hobby_list": ["爱好1", "爱好2", "爱好3"]}
# 本质上是完成了字符串的替换
response = template.render(data)
return bytes(response, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
url_list = [
("/index/", index),
("/home/", home),
("/person/", person),
]
def run_server(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html;charset=utf8\'), ]) # 设置HTTP响应的状态码和头信息
url = environ[\'PATH_INFO\'] # 取到用户输入的url
# 根据不同的路径返回不同内容
func = None
for i in url_list:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 NOT FOUND"
return [response, ]
if __name__ == \'__main__\':
httpd = make_server(\'127.0.0.1\', 8888, run_server)
print("Serving HTTP on port 8888...")
httpd.serve_forever()
9、使用pymysql连接数据库
import time
import jinja2
import pymysql
from wsgiref.simple_server import make_server
# 将不同的页面封装成不同的函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.asctime(time.localtime(time.time())))
s = s.replace("@@oo@@", now)
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
def person(url):
with open("person.html", "r", encoding="utf8") as f:
s = f.read()
# 生成一个jinja2的Template(模板)对象
template = jinja2.Template(s)
conn = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
passwd="",
db="userinfo",
charset="utf8"
)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("SELECT name, hobby FROM user")
user = cursor.fetchone()
cursor.close()
conn.close()
hobby_list = user["hobby"].split()
user["hobby_list"] = hobby_list
# 本质上是完成了字符串的替换
response = template.render(user)
return bytes(response, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
url_list = [
("/index/", index),
("/home/", home),
("/person/", person),
]
def run_server(environ, start_response):
start_response(\'200 OK\', [(\'Content-Type\', \'text/html;charset=utf8\'), ]) # 设置HTTP响应的状态码和头信息
url = environ[\'PATH_INFO\'] # 取到用户输入的url
# 根据不同的路径返回不同内容
func = None
for i in url_list:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 NOT FOUND"
return [response, ]
if __name__ == \'__main__\':
httpd = make_server(\'127.0.0.1\', 8888, run_server)
print("Serving HTTP on port 8888...")
httpd.serve_forever()
以上是关于web框架的主要内容,如果未能解决你的问题,请参考以下文章