[kubernetes] 已经被废弃的 tcp_tw_recycle, 运维的小伙伴看过来
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[kubernetes] 已经被废弃的 tcp_tw_recycle, 运维的小伙伴看过来相关的知识,希望对你有一定的参考价值。
参考技术A 最近准备自己动手部署测试kubernetes集群,注备写一个 hands on 的手册。突发奇想将 centos 原有的内核从3.10更新到了4.14版本,并执行一些常规的优化操作。没有想到在修改了 sysctl.conf 里面的一些参数,希望能对新的 kubernetes 性能有所帮助。sysctl: cannot stat /proc/sys/net/ipv4/tcp_tw_recycle: No such file or directory
纳尼,没有tcp_tw_recycle这个参数了? 怎么回事。。。
net.ipv4.tcp_tw_reuse = 0 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
net.ipv4.tcp_tw_recycle = 0 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
net.ipv4.tcp_fin_timeout = 60 表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间(可改为30,一般来说FIN-WAIT-2的连接也极少)
好像上面3个内核调整参数,都是很多 Linux 运维工程师的标配了,怎么我一升级内核就不行了? 自己狠下心来好好去的看了 kernel 的文档,Linux 从4.12内核版本开始移除了 tcp_tw_recycle 这个参数。 好嘛,小弟我手贱贱,升级到了4.14现在没有这个参数,只能硬着头皮去掉。
但是这个参数对 linux 系统回收大量 tcp timeout wait 有帮助, tcp_tw_recycle通常会和tcp_tw_reuse参数一起使用,用于解决服务器TIME_WAIT状态连接过多的问题 。 但是 kernel 为什么又要取消掉呢?
简单来说就是,Linux会丢弃所有来自远端的timestramp时间戳小于上次记录的时间戳(由同一个远端发送的)的任何数据包。也就是说要使用该选项,则必须保证数据包的时间戳是单调递增的。同时从4.10内核开始,官方修改了时间戳的生成机制,所以导致 tcp_tw_recycle 和新时间戳机制工作在一起不那么友好,同时 tcp_tw_recycle 帮助也不那么的大。
此处的时间戳并不是我们通常意义上面的绝对时间,而是一个相对时间。很多情况下,我们是没法保证时间戳单调递增的,比如业务服务器之前部署了NAT,LVS等情况。相信很多小伙伴上班的公司大概率实用实用各种公有云,而各种公有云的 LVS 网关都是 FullNAT 。所以可能导致在高并发的情况下,莫名其妙的 TCP 建联不是那么顺畅或者丢连接。
而这也是很多优化文章中并没有提及的一点,大部分文章都是简单的推荐将net.ipv4.tcp_tw_recycle设置为1,却忽略了该选项的局限性,最终造成严重的后果(比如我们之前就遇到过部署在nat后端的业务网站有的用户访问没有问题,但有的用户就是打不开网页)。
这次我们要关注的不是上半部分的 TCP 新建连接,而是下半部分的 TCP 断开连接。 别人老谈 TCP 3次握手,我就来谈 TCP 4次“挥手告别”。
在说 TCP 断开连接之前,我想先插入点内容。 就是 为什么要在 TCP 传输种引入 TIMEWAIT 这个概念。
第一个作用就是避免新连接接收到重复的数据包,由于使用了时间戳,重复的数据包会因为时间戳过期被丢弃。
第二个作用是确保远端不是处于LAST-ACK状态,如果ACK包丢失,远端没有成功获取到最后一个ACK包,则会重发FIN包。直到:
1.放弃(连接断开)
2.收到ACK包
3.收到RST包
如果FIN包被及时接收到,并且本地端仍然是TIME-WAIT状态,那ACK包会被发送,此时就是正常的四次挥手流程。
如果TIME-WAIT的条目已经被新连接所复用,则新连接的SYN包会被忽略掉,并且会收到FIN包的重传,本地会回复一个RST包(因为此时本地连接为SYN-SENT状态),这会让远程端跳出LAST-ACK状态,最初的SYN包也会在1秒后重新发送,然后完成连接的建立,整个过程不会中断,只是有轻微的延迟。流程如下:
TIME_WAIT永远是出现在主动发送断开连接请求的一方(下文中我们称之为客户), 划重点:这一点面试的时候经常会被问到。 嘿嘿,这个可以做为面试官的杀手锏,上图逻辑保证好多人不知道。(我咋这么坏呢。。。)
客户在收到服务器端发送的FIN(表示"我们也要断开连接了")后发送ACK报文,并且进入TIME_WAIT状态,等待2MSL(MaximumSegmentLifetime 最大报文生存时间)。对于Linux,字段为TCP_TIMEWAIT_LEN硬编码为30秒,对于Windows为2分钟(可自行调整)。
说到 TCP_TIMEWAIT_LEN 这个我就多啰嗦几句,很多资深运维小伙伴,在早起为了加快 tcp timeout 的回收时间,经常会修改这个内核头文件中定义的宏数据,然后重编译内核。 说实话确实有一些用处,至少早起阿里很多基础平台的运维就是这么干的,至于其他大厂不得而知,这个仁者见仁吧。
确保 TCP 连接在各种情况下,都能正常的关闭。我们的网络 IP 协议本身就是尽力而为的传输,所有传输的可靠性都是靠 TCP 协议栈来完成的。假如当 TCP 自身传输信令的过程中也出现了一些异常呢? 是不是我们 TCP 传输协议本身需要一定的容错机制。
又回到了上面说到的 IP 网络本身尽力而为的传输机制,并不保证数据包在底层传输的时候,接收方收到的数据包的数据顺序不一定是按照发送方的顺序,再加上数据传输延迟,就让上图的问题发生的情况成为了大概率事件。
TIME_WAIT占用的1分钟时间内,相同四元组(源地址,源端口,目标地址,目标端口)的连接无法创建,通常一个ip可以开启的端口为net.ipv4.ip_local_port_range指定的32768-61000,如果TIME_WAIT状态过多,会导致无法创建新连接。
这个占用资源并不是很多,可以不用担心。 (现在服务器内存真心多,不怕。 如果你实用的虚拟机,而且还是短链接巨多,内存分配不那么充足的情况下,还要节省成本, 那就要当心咯)
1.修改为长连接,代价较大,长连接对服务器性能有影响。
2.增加可用端口范围(修改net.ipv4.ip_local_port_range); 增加服务端口,比如采用80,81等多个端口提供服务; 增加客户端ip(适用于负载均衡,比如nginx,采用多个ip连接后端服务器); 增加服务端ip; 这些方式治标不治本,只能缓解问题。
3.将net.ipv4.tcp_max_tw_buckets设置为很小的值(默认是18000). 当TIME_WAIT连接数量达到给定的值时,所有的TIME_WAIT连接会被立刻清除,并打印警告信息。但这种粗暴的清理掉所有的连接,意味着有些连接并没有成功等待2MSL,就会造成通讯异常。
4.修改TCP_TIMEWAIT_LEN值,减少等待时间,但这个需要修改内核并重新编译。(这个之前提过,有某个大厂的小伙伴之前这么做的,有效果,但是有其他负面情况,我没有做完整的评估,自己斟酌实用)
5.打开tcp_tw_recycle和tcp_timestamps选项。
6.打开tcp_tw_reuse和tcp_timestamps选项。
注意,注意,注意,重要的事情说三遍。 5和6之间只能选择一个,不能同时打开。
tcp_tw_recycle 选项在4.10内核之前还只是不适用于NAT/LB的情况(其他情况下,我们也非常不推荐开启该选项),但4.10内核后彻底没有了用武之地,并且在4.12内核中被移除.
tcp_tw_reuse 选项仍然可用。在服务器上面,启用该选项对于连入的TCP连接来说不起作用,但是对于客户端(比如服务器上面某个服务以客户端形式运行,比如nginx反向代理)等是一个可以考虑的方案。
修改TCP_TIMEWAIT_LEN是非常不建议的行为。
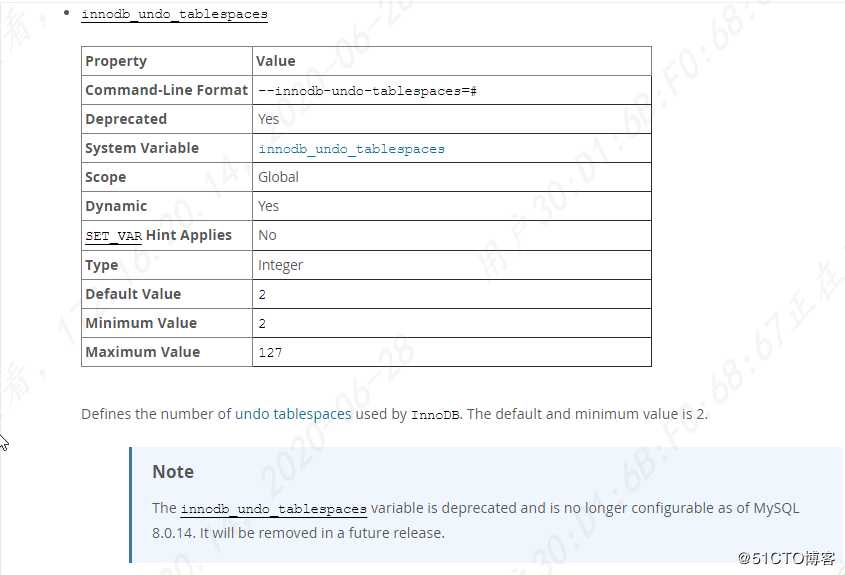
MySQL 8.0 innodb_undo_tablespace废弃掉
MySQL 8.0.19版本已经上线,innodb_undo_tablespace参数已经被废弃掉,后续只能手动添加undo表空降,操作越来越像Oracle了。
以上是关于[kubernetes] 已经被废弃的 tcp_tw_recycle, 运维的小伙伴看过来的主要内容,如果未能解决你的问题,请参考以下文章
K8S 生态周报| Kubernetes v1.22.0 正式发布,新特性一览!