Python获取公众号(pc客户端)数据,使用Fiddler抓包工具
Posted 魔王不会哭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python获取公众号(pc客户端)数据,使用Fiddler抓包工具相关的知识,希望对你有一定的参考价值。
前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

今天来教大家如何使用Fiddler抓包工具,获取公众号(PC客户端)的数据。
Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件)。
Fiddler是位于客户端和服务器端的HTTP代理,是目前最常用的http抓包工具之一。

目录
开发环境
-
python 3.8 运行代码
-
pycharm 2021.2 辅助敲代码
-
requests 第三方模块
-
Fiddler 汉化版 抓包的工具
-
微信PC端

本文所有模块\\环境\\源码\\教程皆可点击文章下方名片获取此处跳转
如何抓包
配置Fiddler环境
先打开Fiddler,选择工具,再选选项
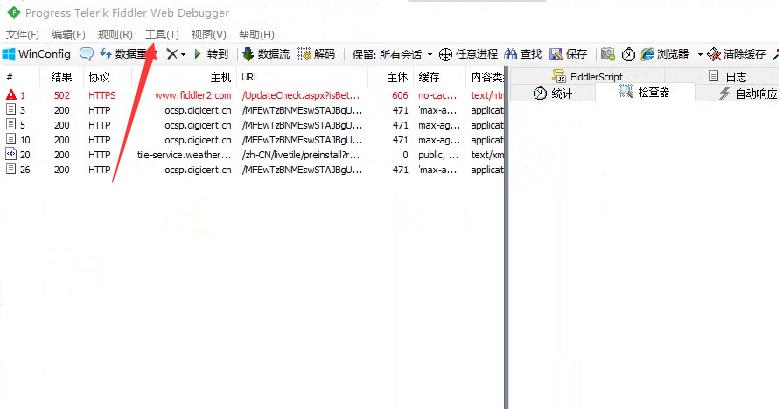
在选项窗口里点击HTTPS,把勾选框都勾选上
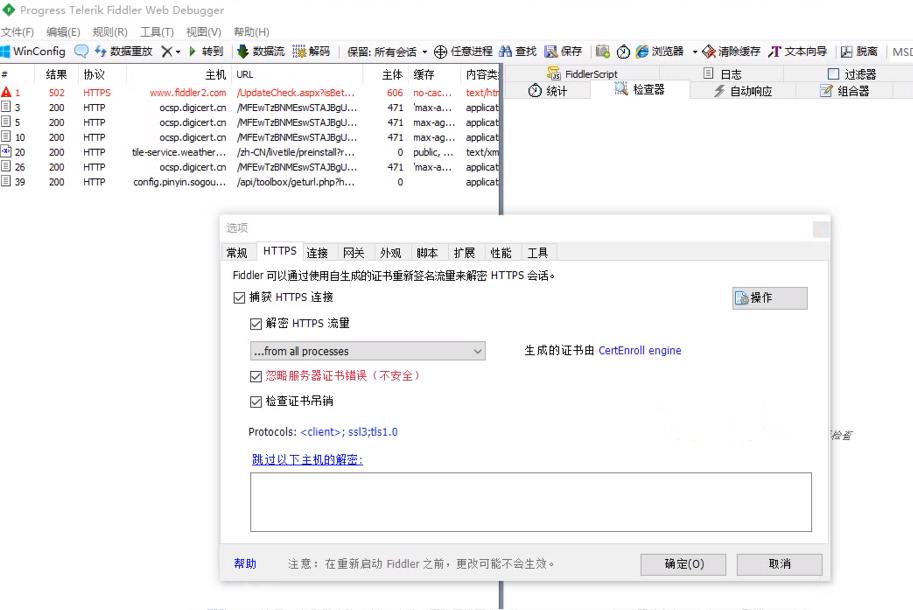
在选项窗口里点击链接,把勾选框都勾选上,然后点击确定即可
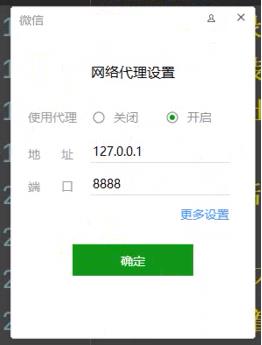
我们还需要在客户端把网络代理开启
地址:127.0.0.1
端口:8888
抓包
先登录,然后清空Fiddler里的数据,在选到你想要的公众号内容
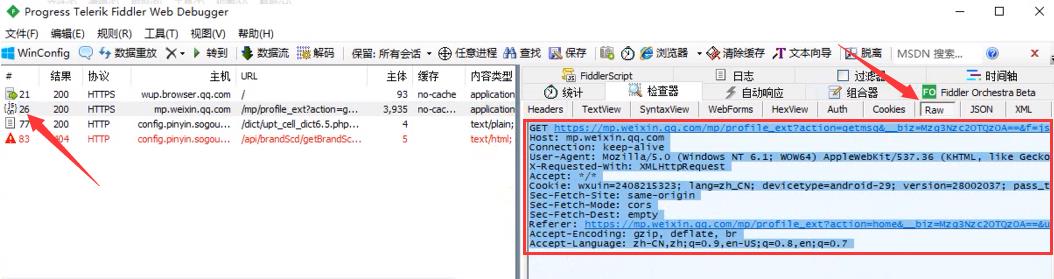
出现数据包后,点开,再选择Raw,里面的就是请求的具体信息

代码展示
本文所有模块\\环境\\源码\\教程皆可点击文章下方名片获取此处跳转
先访问到列表页,获取所有的详情页链接
请求头
headers =
'Host': 'mp.weixin.qq.com',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x63090016)',
'X-Requested-With': 'XMLHttpRequest',
'Accept': '*/*',
'Cookie': 'wxuin=2408215323; lang=zh_CN; devicetype=android-29; version=28002037; pass_ticket=f85UL5Wi11mqpsvuWgLUECYkDoL2apJ045mJw9lzhCjUteAxd4jM8PtaJCM0nBXrQEGU9D7ulLGrXpSummoA==; wap_sid2=CJvmqfwIEooBeV9IR29XUTB2eERtakNSbzVvSkhaRHdMak9UMS1MRmg4TGlaMjhjbTkwcks1Q2E2bWZ1cndhUmdITUZUZ0pwU2VJcU51ZWRDLWpZbml2VkF5WkhaU0NNaDQyQ1RDVS1GZ05mellFR0R5UVY2X215bXZhUUV0NVlJMVRPbXFfZGQ1ZnVvMFNBQUF+MPz0/50GOA1AlU4=',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=Mzg3Nzc2OTQzOA==&uin=MjQwODIxNTMyMw%3D%3D&key=2ed1dc903dceac3d9a380beec8d46a84995a555d7c7eb7b793a3cc4c0d32bc588e1b6df9da9fa1a258cb0db4251dd36eda6029ad4831c4d57f6033928bb9c64c12b8e759cf0649f65e4ef30753ff3092a2a4146a008df311c110d0b6f867ab173792368baa9aaf28a514230946431480cc6b171071a9f9a1cd52f7c07a751925&devicetype=Windows+10+x64&version=63090016&lang=zh_CN&a8scene=7&session_us=gh_676b5a39fe6e&acctmode=0&pass_ticket=f85UL5Wi11%2BmqpsvuW%2BgLUECYkDoL2apJ045mJw9lzhCjUteAxd4jM8PtaJCM0nBXrQEGU9D7ulLGrXpSummoA%3D%3D&wx_header=1&fontgear=2',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
发送请求
url = f'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=Mzg3Nzc2OTQzOA==&f=json&offset=10&count=10&is_ok=1&scene=&uin=MjQwODIxNTMyMw%3D%3D&key=3e8646dd303f109219f39517773e368d92e1975e6972ccf5d1479758d37ecec3e55bc3cb1bb5606d79ec76073ab58e4019ee720c31c2b36fafa9fe891e7afb1e22809e5db3cd8890ab35a570ffb680d16617ac3049d6627e61ffdf3305e4575666e30ad80a57b14555aa6c5a3a0fb0001a6d5d2cd76fd8af116a086ce9ef2c8e&pass_ticket=f85UL5Wi11%2BmqpsvuW%2BgLUECYkDoL2apJ045mJw9lzjmzvDbqI6V6Y%2FkXeYCZ7WsuMSqko7EWesSKLrDKnJ96A%3D%3D&wxtoken=&appmsg_token=1200_VUCOfHI2jYSEziPbaYFlHoaB7977BJYsAb5cvQ~~&x5=0&f=json'
response = requests.get(url=url, headers=headers, verify=False)
解析
general_msg = response.json()['general_msg_list']
general_msg_list = json.loads(general_msg)
for general in general_msg_list['list']:
content_url = general['app_msg_ext_info']['content_url']
print(content_url)
再访问所有详情页链接,获取需要的图片内容
发送请求
html_data = requests.get(url=content_url, headers=headers, verify=False).text
解析数据
img_list = re.findall('<img class=".*?data-src="(.*?)"', html_data)
print(img_list)
保存数据
for img in img_list:
img_data = requests.get(url=img, verify=False).content
open(f'img/index.jpg', mode='wb').write(img_data)
index += 1
尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝

python爬搜狗微信获取指定微信公众号的文章
前言:
之前收藏了一个叫微信公众号的文章爬取,里面用到的模块不错。然而
偏偏报错= =。果断自己写了一个
正文:
第一步爬取搜狗微信搜到的公众号:
http://weixin.sogou.com/weixin?type=1&query=FreeBuf&ie=utf8&s_from=input&_sug_=n&_sug_type_=1&w=01015002&oq=&ri=11&sourceid=sugg&sut=0&sst0=1529673558816&lkt=0%2C0%2C0&p=40040108
将FreeBuf改为自己要搜的公众号
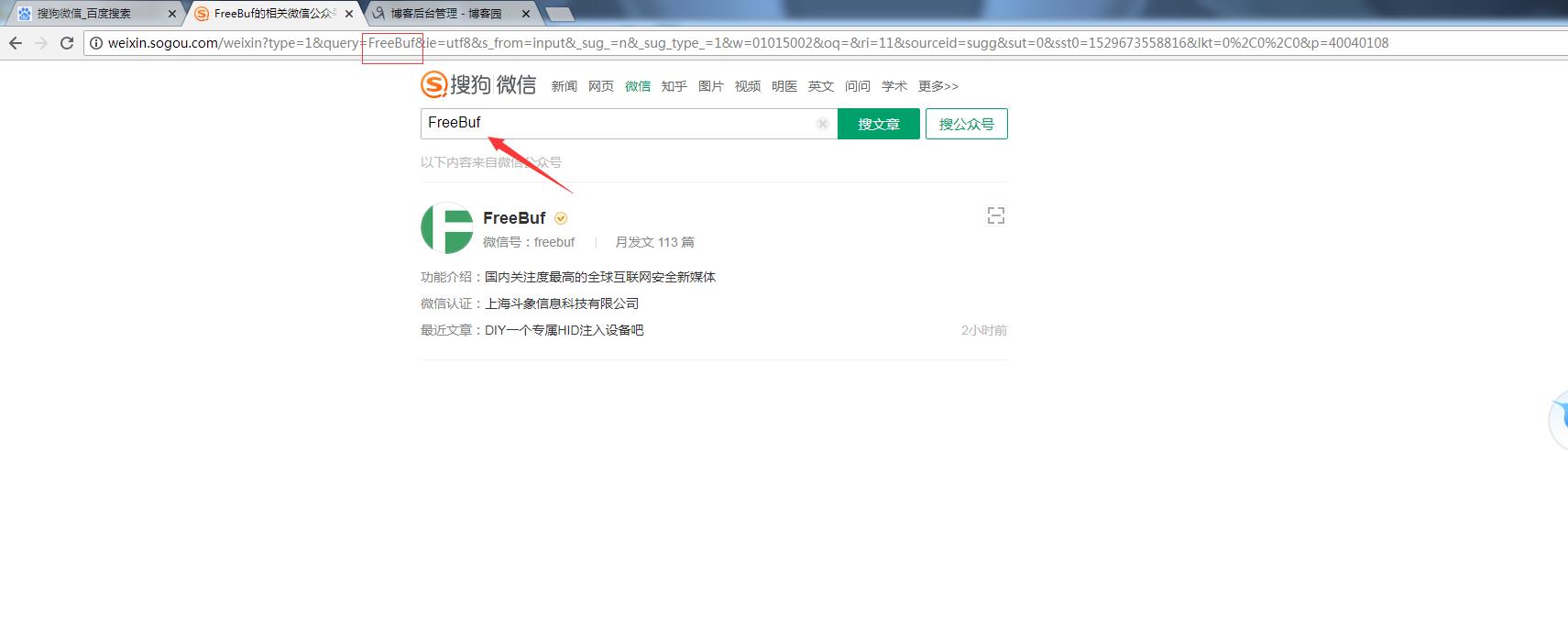
查看网页源代码:
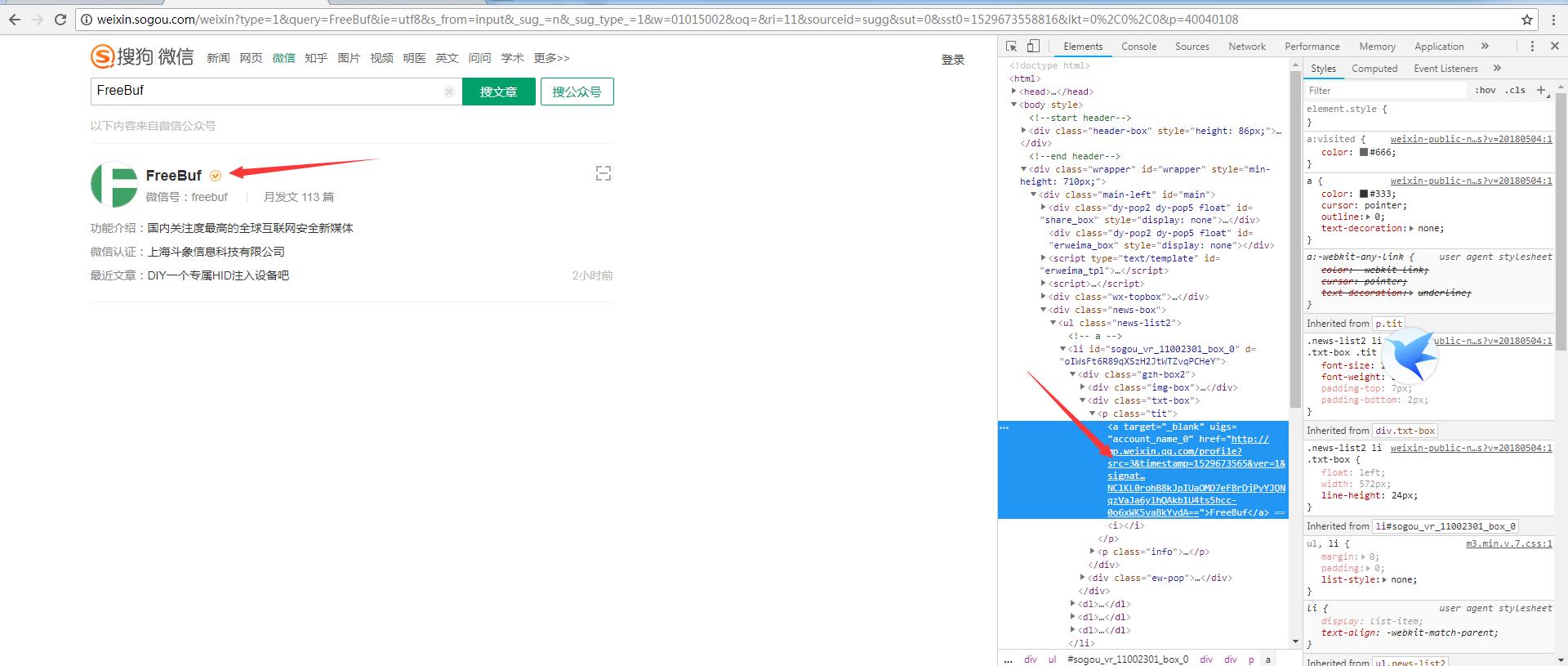
正则匹配:
第一个正则:匹配指定的URL 正则: src=.*&timestamp=.*&ver=.*&signature=.*
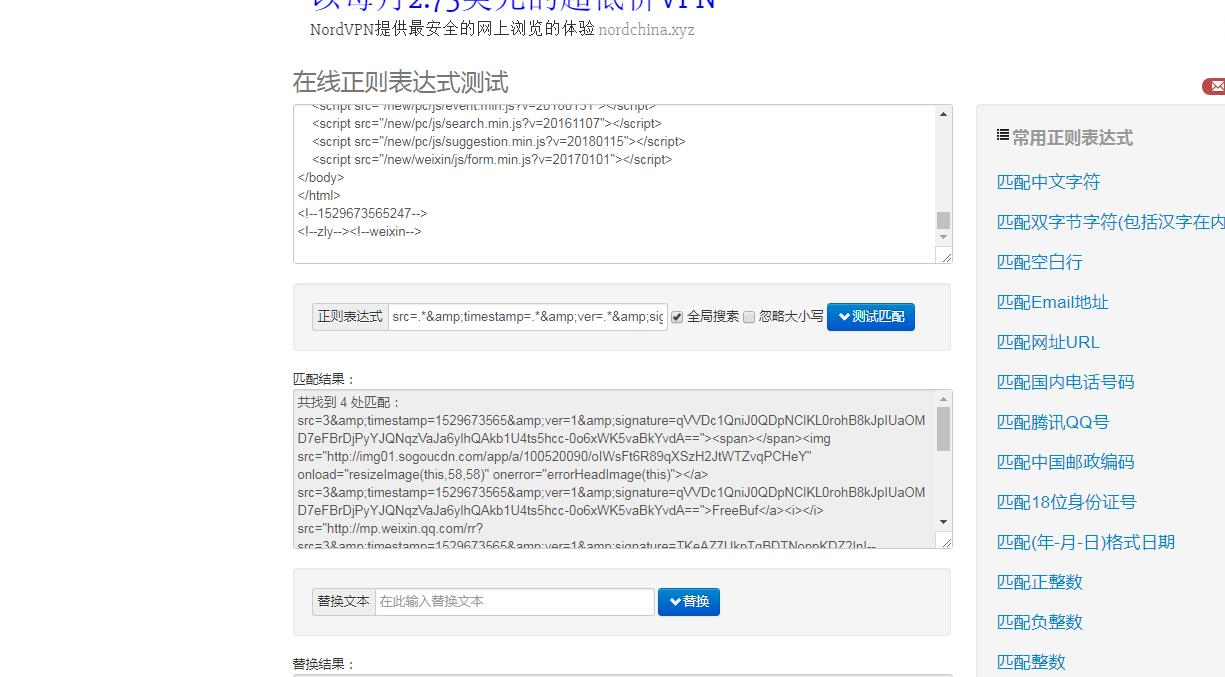
蓝色标出来的是我们要的,注意多请求URL可以注意到URL,signature也就是签名是随机变化的。所以可得到正则:.*== ,取第一个,然后打开此链接爬取文章链接即可(更多细节会在代码看到)
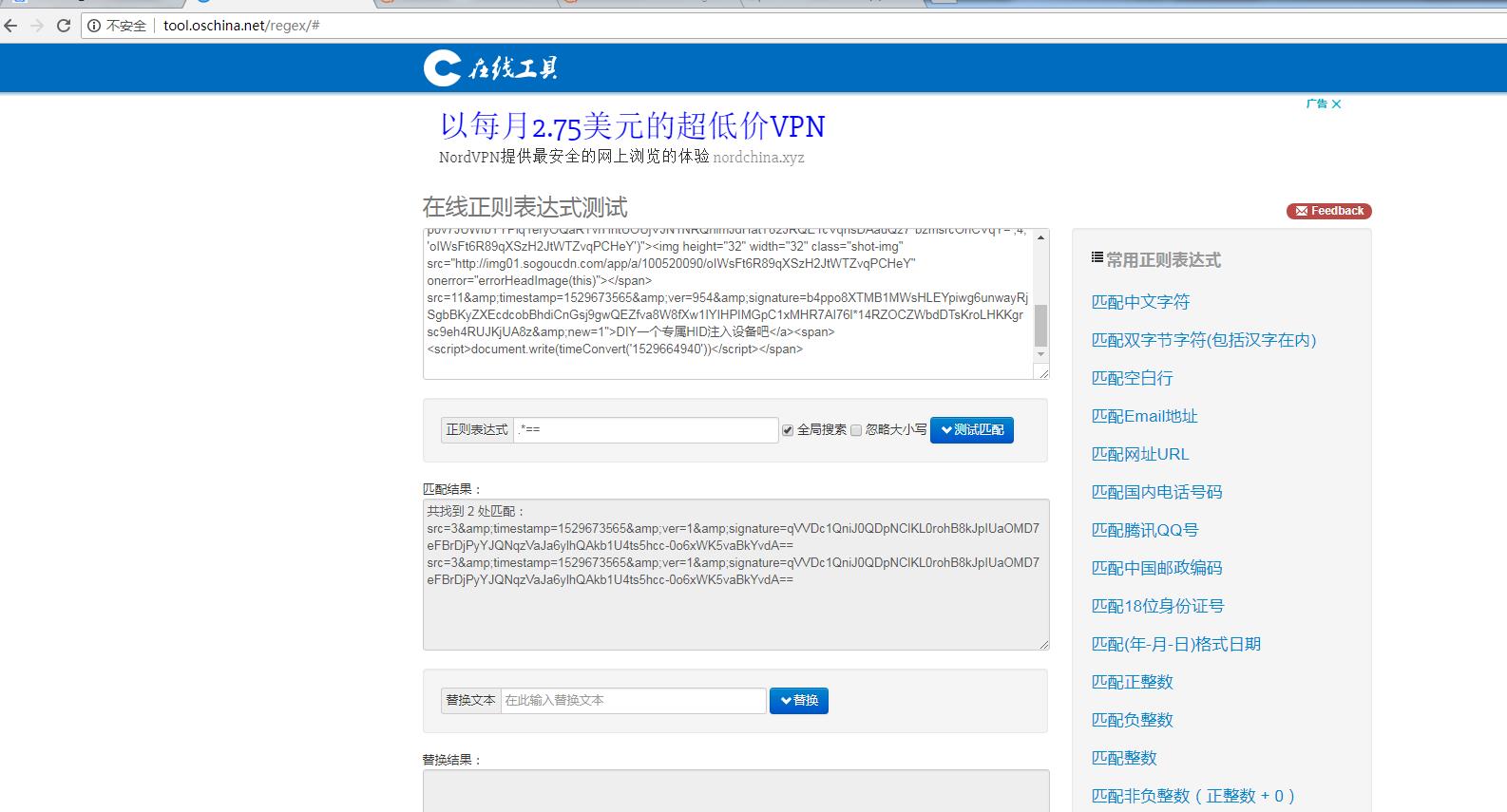
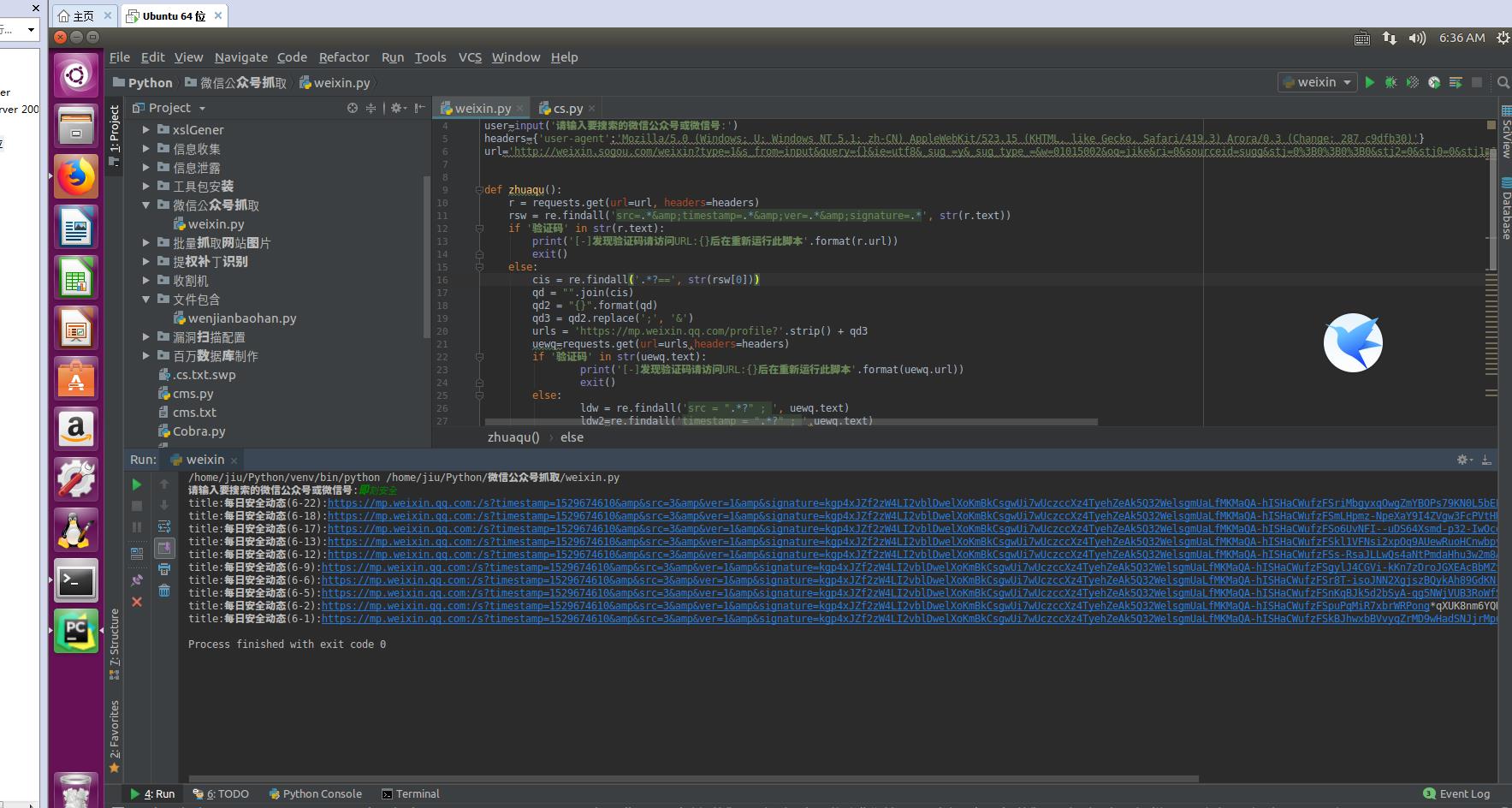
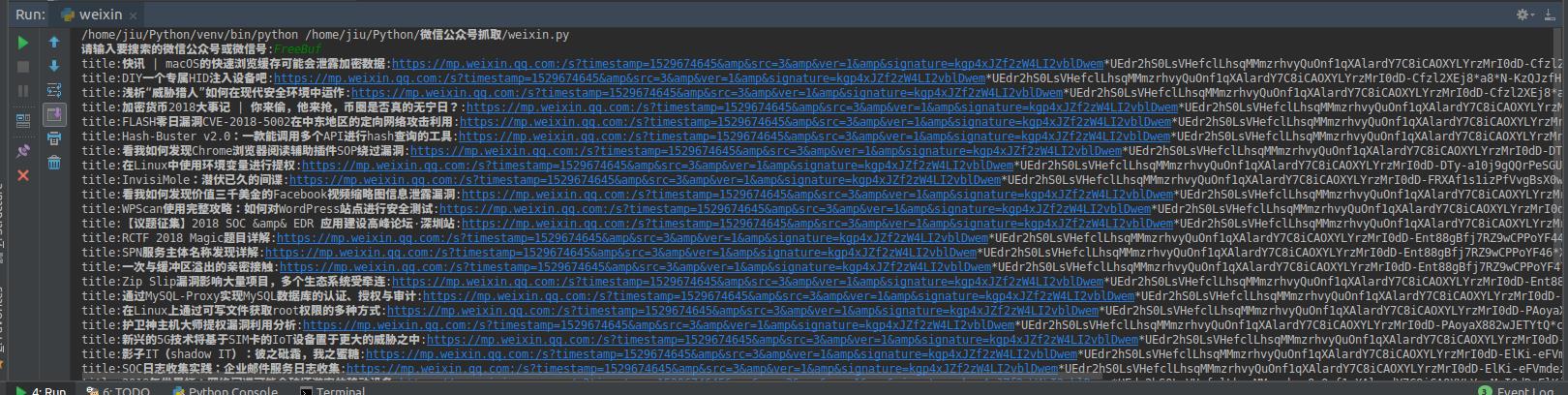
代码:
import requests import re import threading user=input(\'请输入要搜索的微信公众号或微信号:\') headers={\'user-agent\':\'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)\'} url=\'http://weixin.sogou.com/weixin?type=1&s_from=input&query={}&ie=utf8&_sug_=y&_sug_type_=&w=01015002&oq=jike&ri=0&sourceid=sugg&stj=0%3B0%3B0%3B0&stj2=0&stj0=0&stj1=0&hp=36&hp1=&sut=4432&sst0=1529305369937&lkt=5%2C1529305367635%2C1529305369835\'.format(user.rstrip()) def zhuaqu(): r = requests.get(url=url, headers=headers) rsw = re.findall(\'src=.*&timestamp=.*&ver=.*&signature=.*\', str(r.text)) if \'验证码\' in str(r.text): print(\'[-]发现验证码请访问URL:{}后在重新运行此脚本\'.format(r.url)) exit() else: cis = re.findall(\'.*?==\', str(rsw[0])) qd = "".join(cis) qd2 = "{}".format(qd) qd3 = qd2.replace(\';\', \'&\') urls = \'https://mp.weixin.qq.com/profile?\'.strip() + qd3 uewq=requests.get(url=urls,headers=headers) if \'验证码\' in str(uewq.text): print(\'[-]发现验证码请访问URL:{}后在重新运行此脚本\'.format(uewq.url)) exit() else: ldw = re.findall(\'src = ".*?" ; \', uewq.text) ldw2=re.findall(\'timestamp = ".*?" ; \',uewq.text) ldw3=re.findall(\'ver = ".*?" ; \',uewq.text) ldw4=re.findall(\'signature = ".*?"\',uewq.text) ldws="".join(ldw) ldw2s="".join(ldw2) ldw3s="".join(ldw3) ldw4s="".join(ldw4) ldwsjihe=ldws+ldw2s+ldw3s+ldw4s fk=ldwsjihe.split() fkchuli="".join(fk) gs=fkchuli.replace(\'"\',\'\') hew=gs.replace(\';\',\'&\') wanc="http://mp.weixin.qq.com/profile?"+hew xiau=requests.get(url=wanc,headers=headers) houxu=re.findall(\'{.*?}\',xiau.content.decode(\'utf-8\')) title=re.findall(\'"title":".*?"\',str(houxu)) purl=re.findall(\'"content_url":".*?"\',str(houxu)) for i in range(0,len(title)): jc=\'{}:{}\'.format(title[i],\'https://mp.weixin.qq.com\'+purl[i]).replace(\'"\',\'\') jc2=jc.replace(\'content_url\',\'\') jc3=jc2.replace(\';\',\'&\') print(jc3) t=threading.Thread(target=zhuaqu,args=()) t.start()
测试结果:
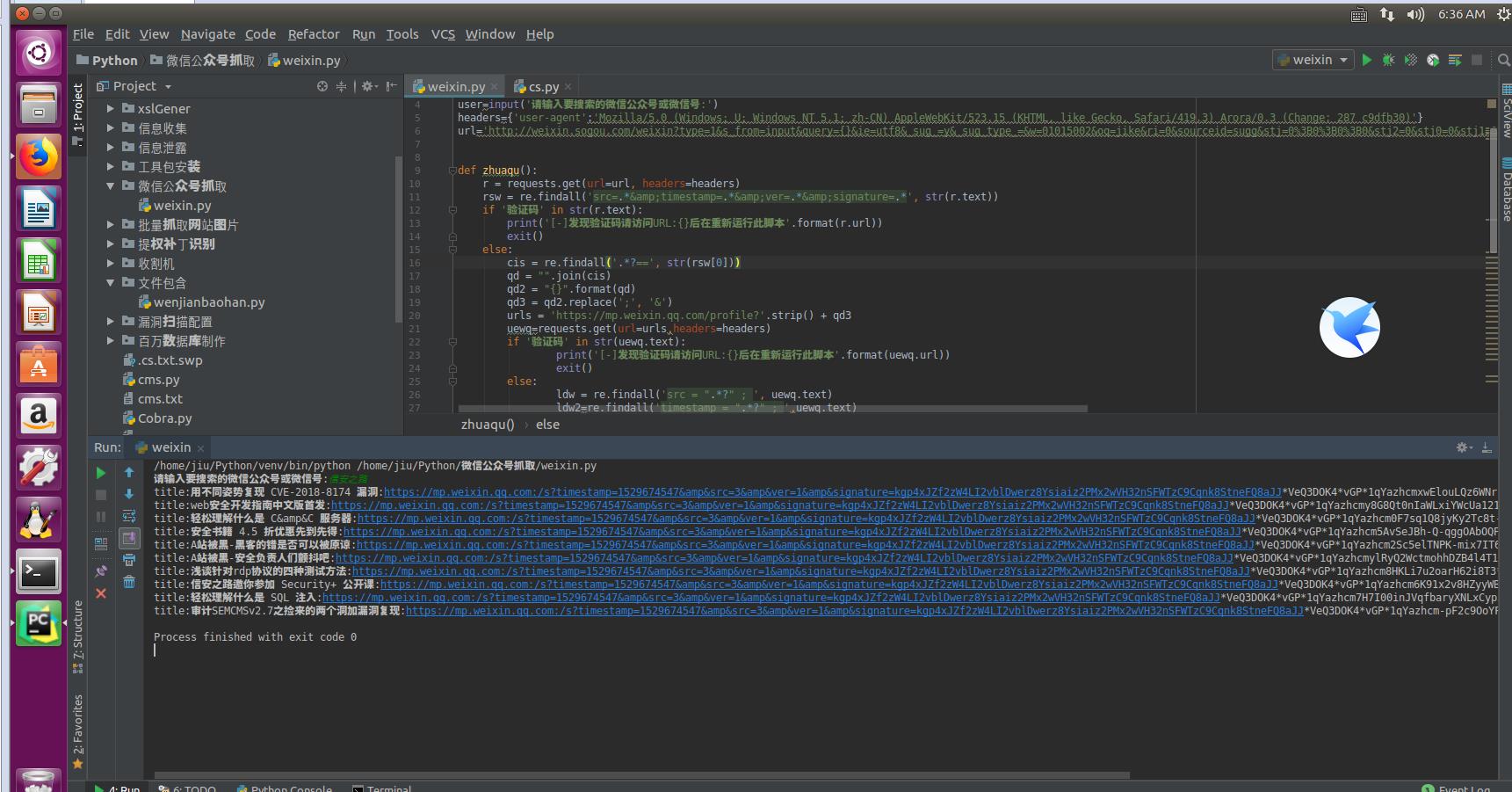
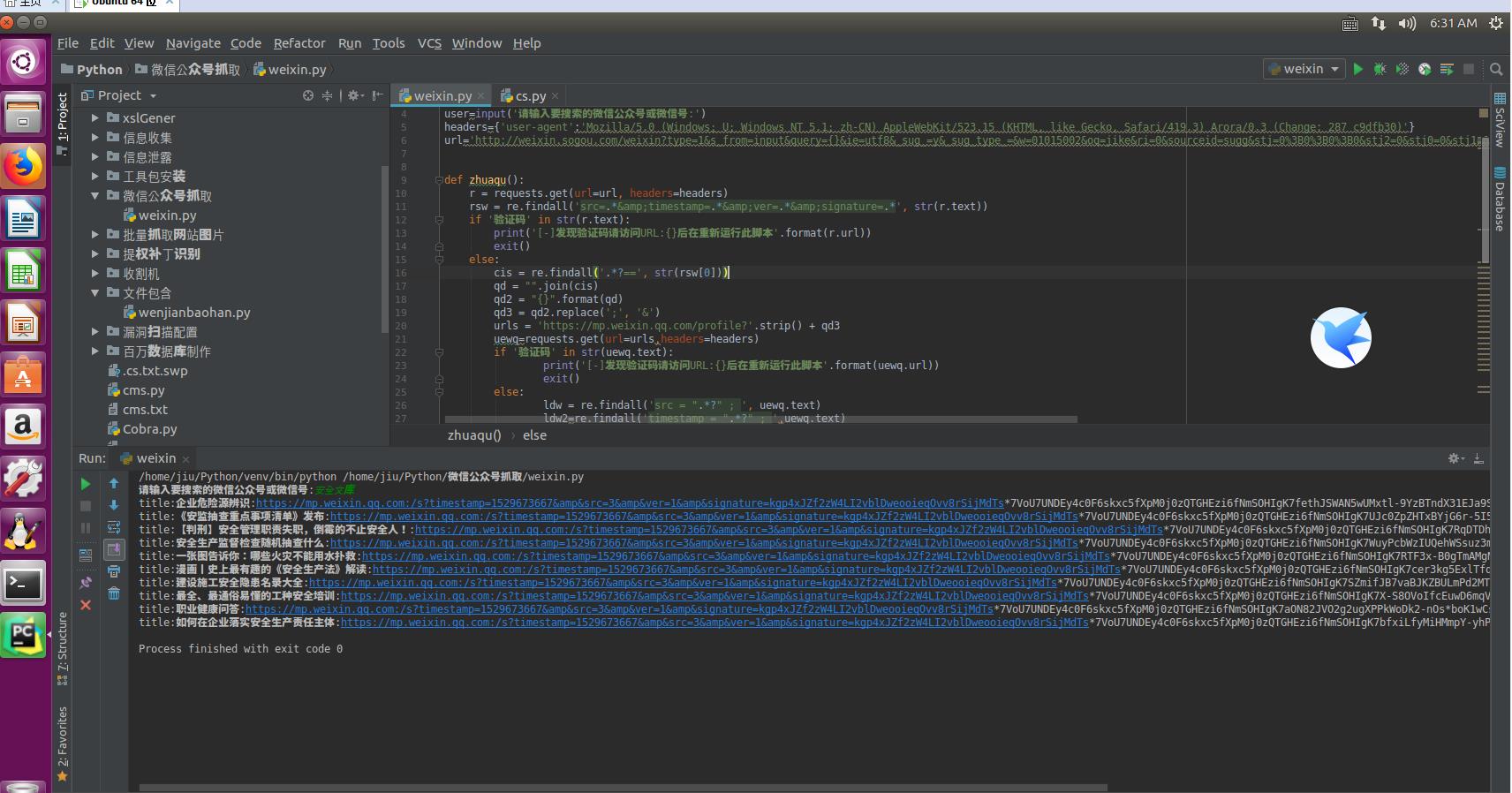
BGM:
以上是关于Python获取公众号(pc客户端)数据,使用Fiddler抓包工具的主要内容,如果未能解决你的问题,请参考以下文章