Arduino STM32如何让pa11输出高低电平?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Arduino STM32如何让pa11输出高低电平?相关的知识,希望对你有一定的参考价值。
STM32系列的供电电压都是3.3V或者更低,输出5V比输入更高是不可能。比较简单的办法是加一个三极管开关电路进行电平转换。如果用到的引脚很多,可以直接使用一个电平转换芯片。或者用光耦做开关,似乎也挺好用,并能起到隔离作用。
另外 stm32 虽然输出能力不错,F1记得好像是25mA,直接带数码管什么的问题不大,但诸如电机什么就不要想了,不要像年轻的我一样天真。。 参考技术A 库函数有
GPIO-SetBits(GPIOC,GPIO-Pin-3)
或者GPIO-Reset(……)命令,也比较简单
开漏输出就是不输出电压,低电平时接地,高电平时不接地。如果外接上拉电阻,则在输出高电平时电压会拉到上拉电阻的电源电压。这种方式适合在连接的外设电压比单片机电压低的时候。 推挽输出就是单片机引脚可以直接输出高电平电压。
STM32是基于ARM® Cortex® M 处理器内核的 32位闪存微控制器,为MCU用户开辟了一个全新的自由开发空间,并提供了各种易于上手的软硬 参考技术B 关于您所询问的让pa11输出高低电平这个问题,可以通过相应的参数设置来进行调整,不同的测试的范围,输出的电压高低不同 参考技术C 可以让输出高低啊,电瓶的这个主播是在输出的时候可以去购买一个他们的专门的变压器就可以了。 参考技术D 输入法有很多可以把电流店里电留条高出高电平的办法有很多,可以把电流调高或者电压调或者电影
字符编码
字符编码
1、什么是字符编码?
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电平(高低平即二进制数1,低电平即二进制数0),也就是说计算机只认识数字。
很明显,我们平时在使用计算机时,用的都是人类能读懂的字符(用高级语言编程的结果也无非是在文件内写了一堆字符),如何能让计算机读懂人类的字符?
必须经过一个过程:
字符--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码。
以下两个场景下涉及到字符编码的问题:
1. 一个python文件中的内容是由一堆字符组成的(python文件未执行时)
2. python中的数据类型字符串是由一串字符组成的(python文件执行时)
2、字符编码的发展史
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)
后来为了将拉丁文也编码进了ASCII表,将最高位也占用了
阶段二: 为了满足中文,中国人定制了GBK
GBK:2Bytes代表一个字符
为了满足其他国家,各个国家纷纷定制了自己的编码
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言
但对于通篇都是英文的文本来说,这种编码方式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的)
于是产生了UTF-8,对英文字符只用1Bytes表示,对中文字符用3Bytes
总结:
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Shift-JIS 日本字符
- ks_c_5601-1987 韩国编码
- TIS-620 泰国编码
- Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中... 也叫万国码
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符;
UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
bit 位,计算机中最小的表示单位 8bit = 1bytes 字节,最小的存储单位,1bytes缩写为1B 1KB=1024B 1MB=1024KB 1GB=1024MB 1TB=1024GB 1PB=1024TB 1EB=1024PB 1ZB=1024EB 1YB=1024ZB 1BB=1024YB
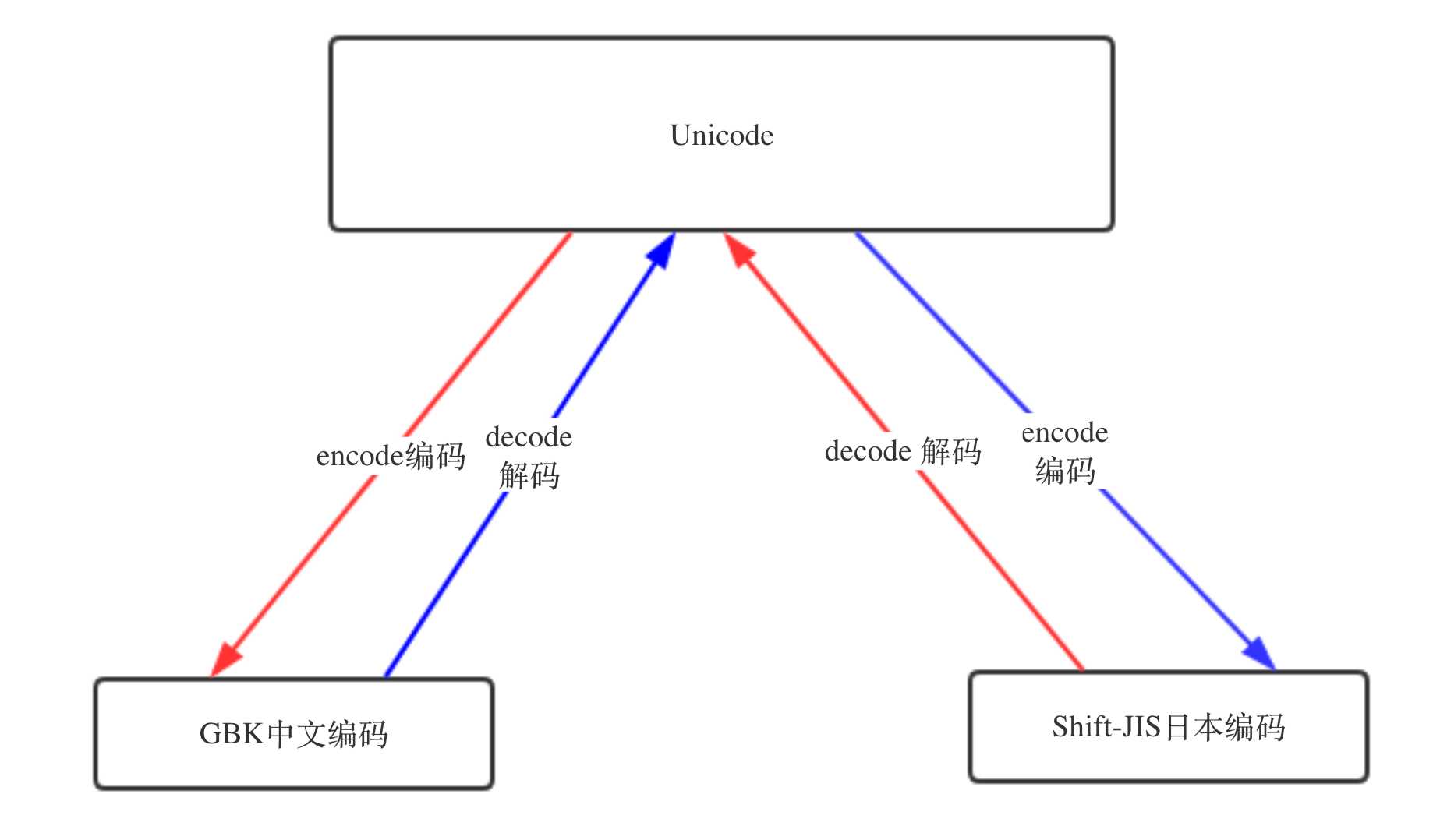
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
文件存取编码转换图
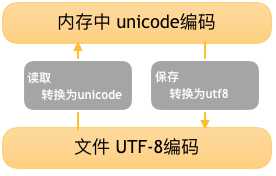
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode
为了方便记忆,常用编码介绍一览表如下:

3、编码的转换(重点):
虽然国际语言是英语 ,但大家在自己的国家依然说自已的语言,不过出了国, 你就得会英语
编码也一样,虽然有了unicode and utf-8 , 但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的windows,默认编码依然是gbk,而不是utf-8
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。
若想让中国的软件可以正常的在 美国人的电脑上显示,只有以下2条路可走:
- 让美国人的电脑上都装上gbk编码
- 把你的软件编码以utf-8编码
第1种方法几乎不可能实现,第2种方法比较简单。 但是也只能是针对新开发的软件。 如果你之前开发的软件就是以gbk编码的,上百万行代码可能已经写出去了,重新编码成utf-8格式也会费很大力气。
so , 针对已经用gbk开发完毕的项目,以上2种方案都不能轻松的让项目在美国人电脑上正常显示,难道没有别的办法了么?
有, 还记得我们讲unicode其中一个功能是其包含了跟全球所有国家编码的映射关系,意思就是,你写的是gbk的“路飞学城”,但是unicode能自动知道它在unicode中的“路飞学城”的编码是什么,如果这样的话,那是不是意味着,无论你以什么编码存储的数据 ,只要你的软件在把数据从硬盘读到内存里,转成unicode来显示,就可以了。
由于所有的系统、编程语言都默认支持unicode,那你的gbk软件放到美国电脑 上,加载到内存里,变成了unicode,中文就可以正常展示啦。
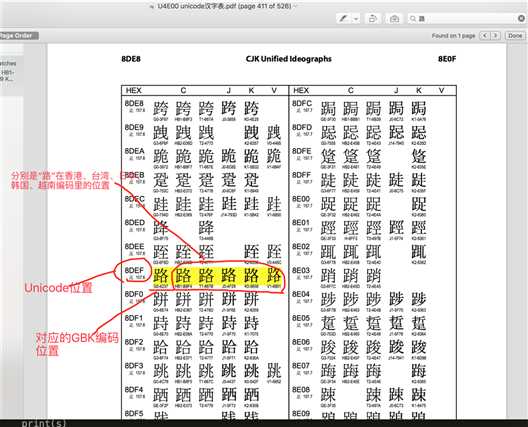
这个表你自己也可以下载下来
unicode与gbk的映射表 http://www.unicode.org/charts/
Python3的执行过程
在看实际代码的例子前,我们来聊聊,python3 执行代码的过程
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明
编码转换过程
实际代码演示,在py3上 把你的代码以utf-8编写, 保存,然后在windows上执行,
s = ‘路飞学城‘ print(s)
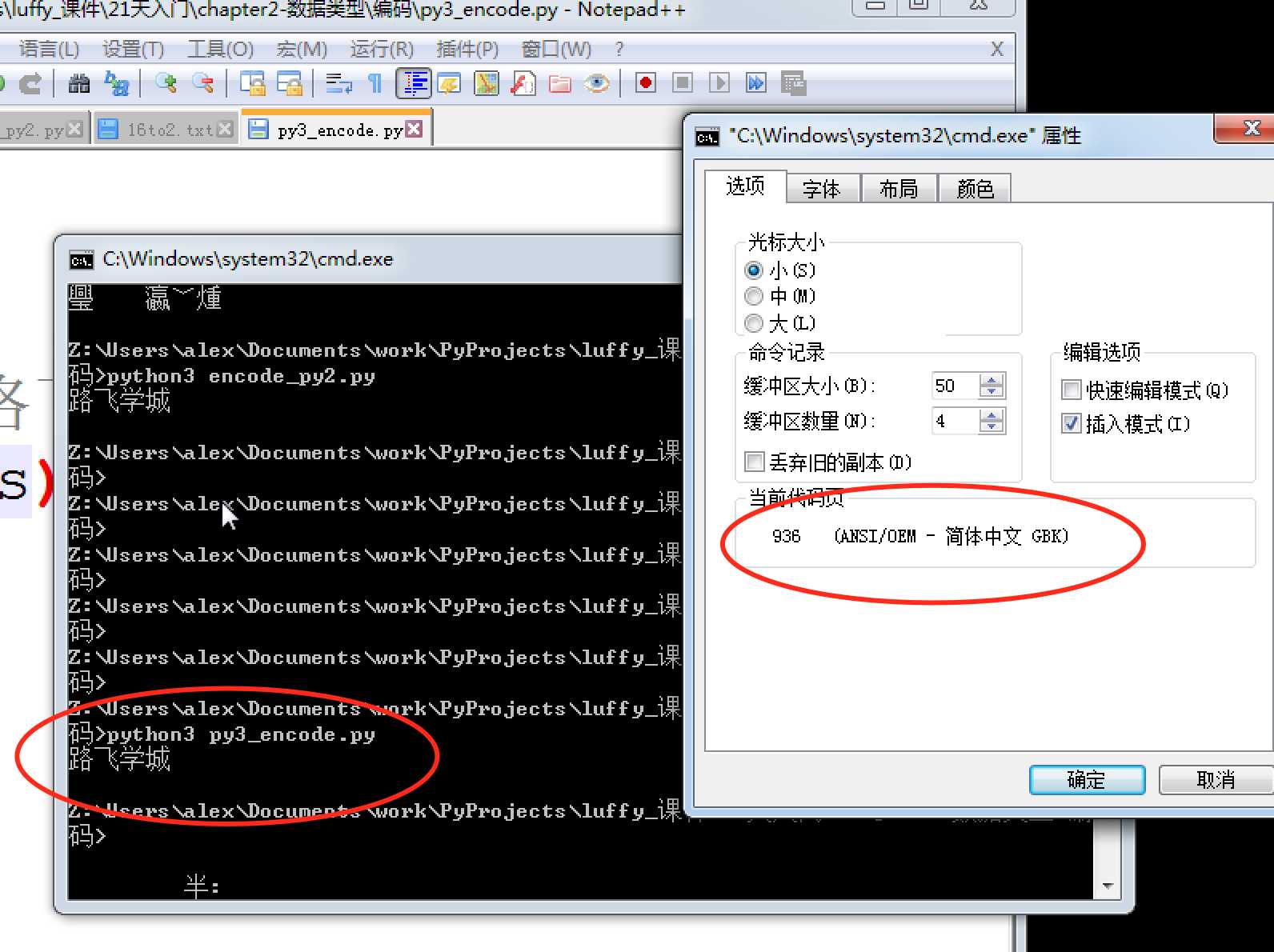
so ,一切都很美好,到这里,我们关于编码的学习按说就可以结束了。
但是,如生活一样,美好的表面下,总是隐藏着不尽如人意,上面的utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode , 但是这只是python3, 并不是所有的编程语言在内存里默认编码都是unicode,比如 万恶的python2 就不是, 它的默认编码是ASCII,想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变量字符串就也是utf-8, 这意味着什么你知道么?。。。意味着,你以utf-8编码的文件,在windows是乱码。
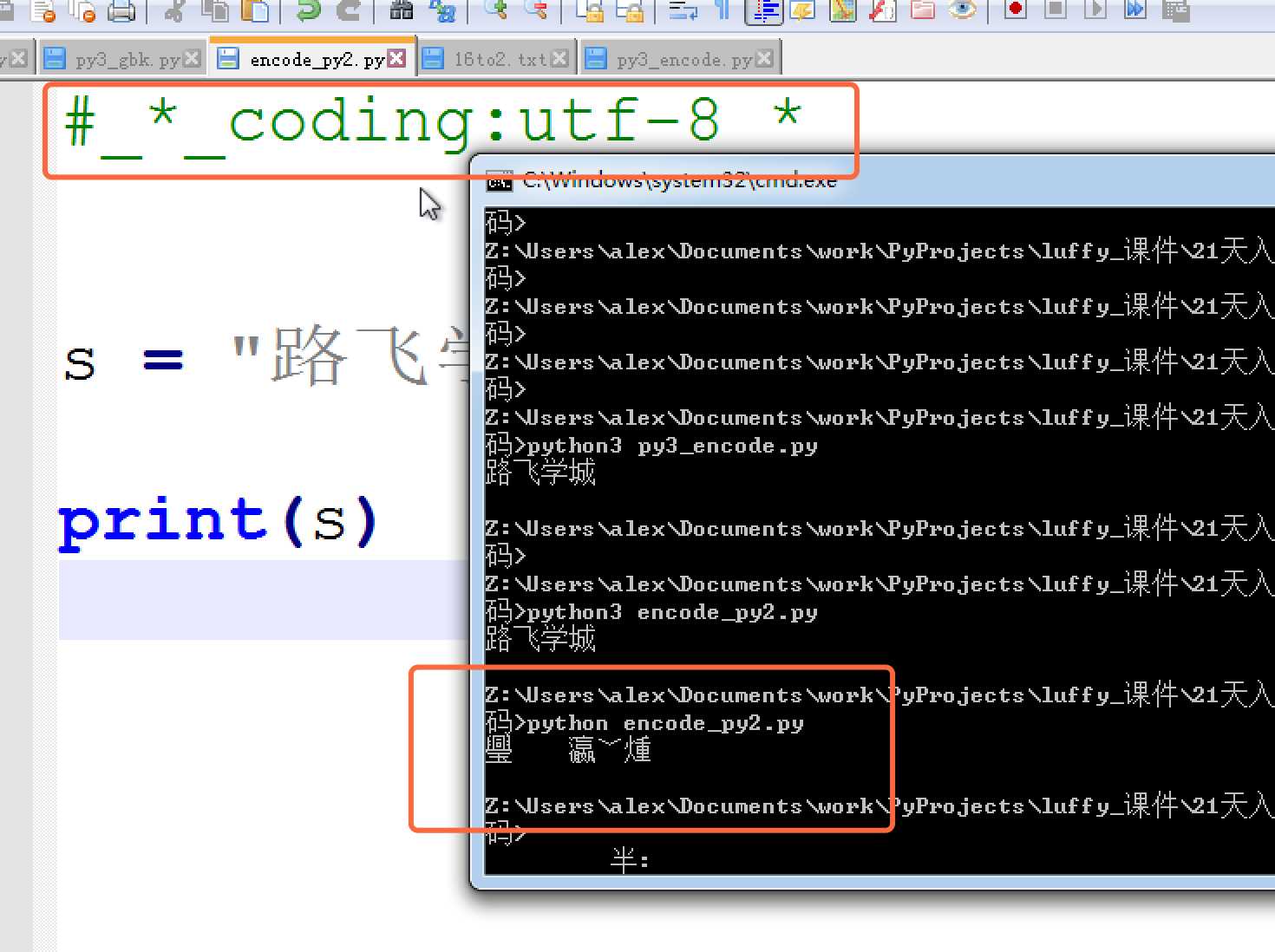
乱是正常的,不乱才不正常,因为只有2种情况 ,你的windows上显示才不会乱
- 字符串以GBK格式显示
- 字符串是unicode编码
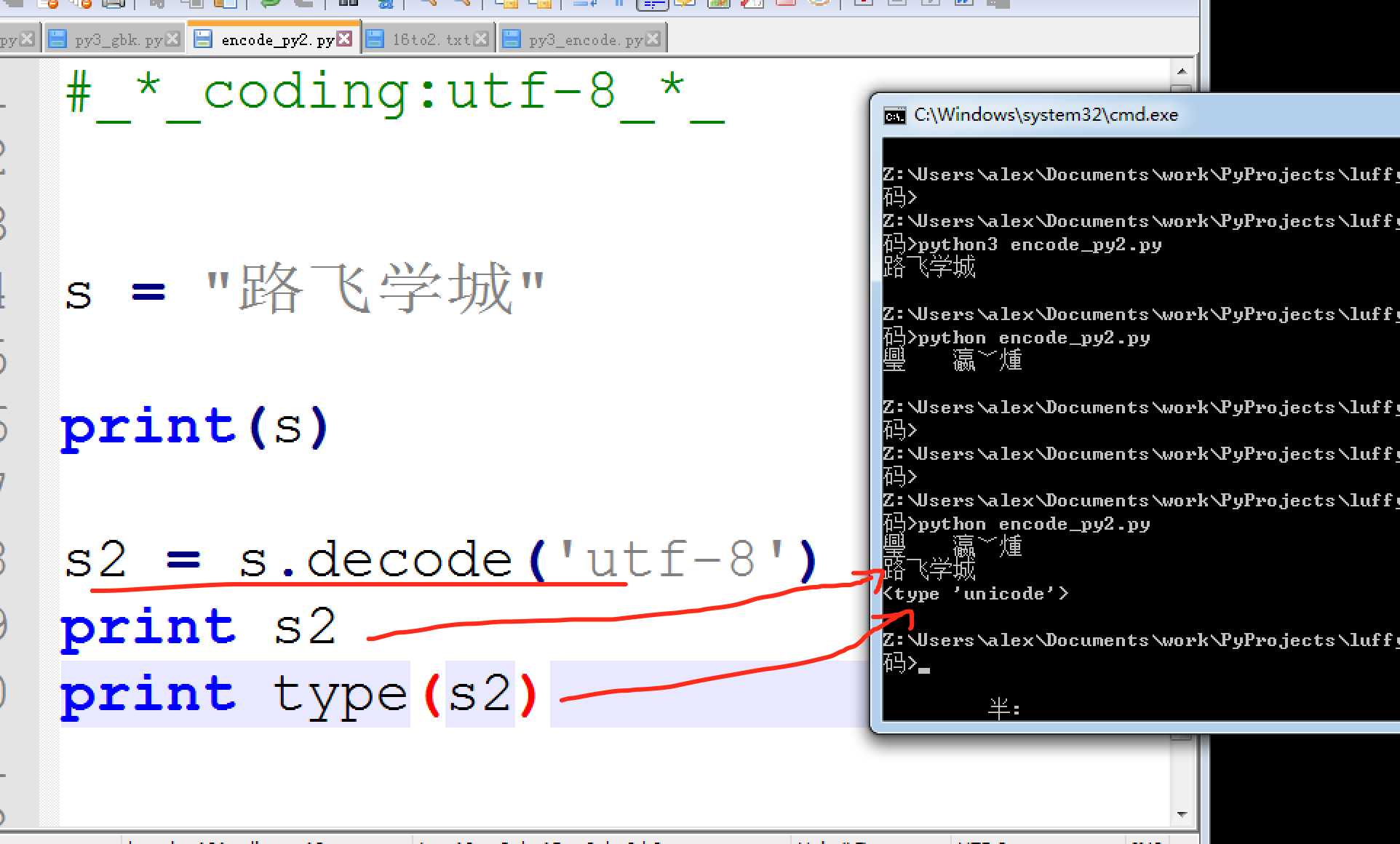
既然Python2并不会自动的把文件编码转为unicode存在内存里, 那就只能使出最后一招了,你自己人肉转。Py3 自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode(编码)
UTF-8 --> decode 解码 --> Unicode
Unicode --> encode 编码 --> GBK / UTF-8
decode示例
encode 示例
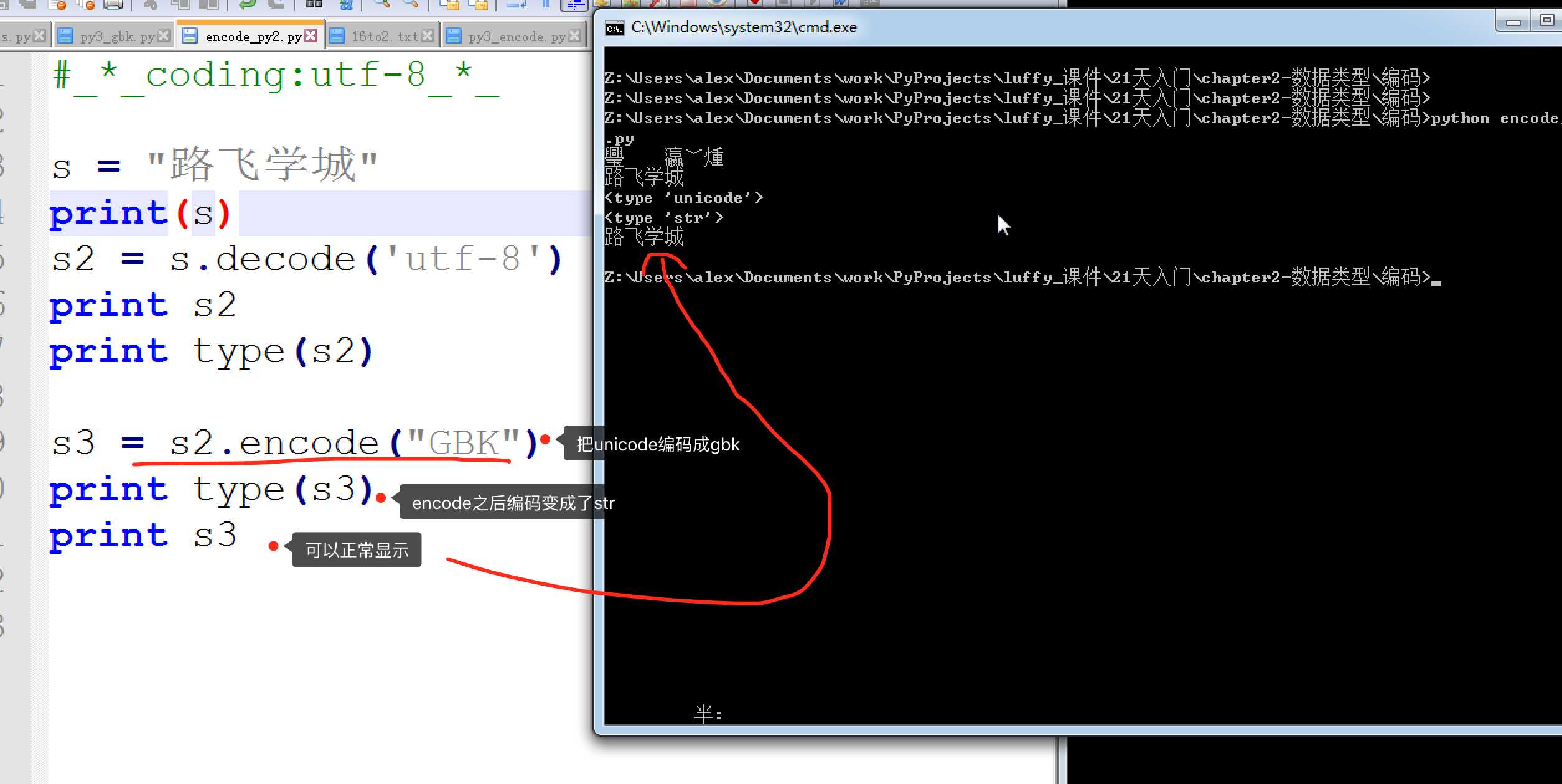
记住下图规则
如何验证编码转对了呢?
1. 查看数据类型,python 2 里有专门的unicode 类型
2. 查看unicode编码映射表
unicode字符是有专门的unicode类型来判断的,但是utf-8,gbk编码的字符都是str,你如果分辨出来的当前的字符串数据是何种编码的呢? 有人说可以通过字节长度判断,因为utf-8一个中文占3字节,gbk一个占2字节

靠上面字节个数,虽然也能大体判断是什么类型,但总觉得不是很专业。
怎么才能精确的验证一个字符的编码呢,就是拿这些16进制的数跟编码表里去匹配。
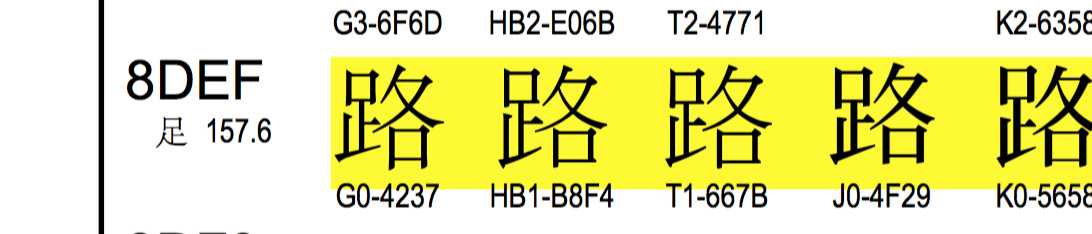
“路飞学城”的unicode编码的映射位置是 u‘u8defu98deu5b66u57ce‘ ,‘u8def’ 就是‘路’,到表里搜一下。
“路飞学城”对应的GBK编码是‘xc2xb7xb7xc9xd1xa7xb3xc7‘ ,2个字节一个中文,"路" 的二进制 "xc2xb7"是4个16进制,正好2字节,拿它到unicode映射表里对一下, 发现是G0-4237,并不是xc2xb7呀。。。擦。演砸了吧。。
再查下“飞” u98de ,对应的是G0-3749, 跟xb7xc9也对不上。
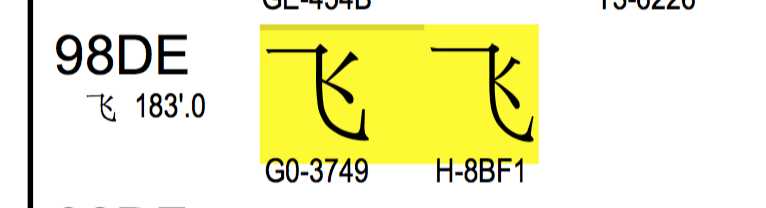
虽然对不上, 但好xc2xb7 和G0-4237中的第2位的2和第4位的7对上了,“飞”字也是一样,莫非巧合?
把他们都转成2进制显示试试
路 C 2 8 4 2 1 8 4 2 1 <strong>1 1 0 0 0 0 1 0</strong> B 7 8 4 2 1 8 4 2 1 <strong>1 0 1 1 0 1 1 1</strong> 飞 B 7 8 4 2 1 8 4 2 1 1 0 1 1 0 1 1 1 C 9 8 4 2 1 8 4 2 1 1 1 0 0 1 0 0 1
这个“路”还是跟G0-4237对不上呀,没错, 但如果你把路xc2xb7的每个二进制字节的左边第一个bit变成0试试呢, 我擦,加起来就真的是4237了呀。。难道又是巧合???
必然不是,是因为,GBK的编码表示形式决定的。。因为GBK编码在设计初期就考虑到了要兼容ASCII,即如果是英文,就用一个字节表示,2个字节就是中文,但如何区别连在一起的2个字节是代表2个英文字母,还是一个中文汉字呢? 中国人如此聪明,决定,2个字节连在一起,如果每个字节的第1位(也就是相当于128的那个2进制位)如果是1,就代表这是个中文,这个首位是128的字节被称为高字节。 也就是2个高字节连在一起,必然就是一个中文。 你怎么如此笃定?因为0-127已经表示了英文的绝大部分字符,128-255是ASCII的扩展表,表示的都是极特殊的字符,一般没什么用。所以中国人就直接拿来用了。
问:那为什么上面 "xc2xb7"的2进制要把128所在的位去掉才能与unicode编码表里的G0-4237匹配上呢?
这只能说是unicode在映射表的表达上直接忽略了高字节,但真正映射的时候 ,肯定还是需要用高字节的哈。
Python bytes类型
在python 2 上写字符串
>>> s = "路飞" >>> print s 路飞 >>> s ‘xe8xb7xafxe9xa3x9e‘
虽说打印的是路飞,但直接调用变量s,看到的却是一个个的16进制表示的二进制字节,我们怎么称呼这样的数据呢?直接叫二进制么?也可以, 但相比于010101,这个数据串在表示形式上又把2进制转成了16进制来表示,这是为什么呢? 哈,为的就是让人们看起来更可读。我们称之为bytes类型,即字节类型, 它把8个二进制一组称为一个byte,用16进制来表示。
说这个有什么意思呢?
想告诉你一个事实, 就是,python2的字符串其实更应该称为字节串。 通过存储方式就能看出来, 但python2里还有一个类型是bytes呀,难道又叫bytes又叫字符串? 嗯 ,是的,在python2里,bytes == str , 其实就是一回事
除此之外呢, python2里还有个单独的类型是unicode , 把字符串解码后,就会变成unicode
>>> s ‘xe8xb7xafxe9xa3x9e‘ #utf-8 >>> s.decode(‘utf-8‘) u‘u8defu98de‘ #unicode 在unicode编码表里对应的位置 >>> print(s.decode(‘utf-8‘)) 路飞 #unicode 格式的字符
由于Python创始人在开发初期认知的局限性,其并未预料到python能发展成一个全球流行的语言,导致其开发初期并没有把支持全球各国语言当做重要的事情来做,所以就轻佻的把ASCII当做了默认编码。 当后来大家对支持汉字、日文、法语等语言的呼声越来越高时,Python于是准备引入unicode,但若直接把默认编码改成unicode的话是不现实的, 因为很多软件就是基于之前的默认编码ASCII开发的,编码一换,那些软件的编码就都乱了。所以Python 2 就直接 搞了一个新的字符类型,就叫unicode类型,比如你想让你的中文在全球所有电脑上正常显示,在内存里就得把字符串存成unicode类型
>>> s = "路飞" >>> s ‘xe8xb7xafxe9xa3x9e‘ >>> s2 = s.decode("utf-8") >>> s2 u‘u8defu98de‘ >>> type(s2) <type ‘unicode‘>
时间来到2008年,python发展已近20年,创始人龟叔越来越觉得python里的好多东西已发展的不像他的初衷那样,开始变得臃肿、不简洁、且有些设计让人摸不到头脑,比如unicode 与str类型,str 与bytes类型的关系,这给很多python程序员造成了困扰。
龟叔再也忍不了,像之前一样的修修补补已不能让Python变的更好,于是来了个大变革,Python3横空出世,不兼容python2,python3比python2做了非常多的改进,其中一个就是终于把字符串变成了unicode,文件默认编码变成了utf-8,这意味着,只要用python3,无论你的程序是以哪种编码开发的,都可以在全球各国电脑上正常显示,真是太棒啦!
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。
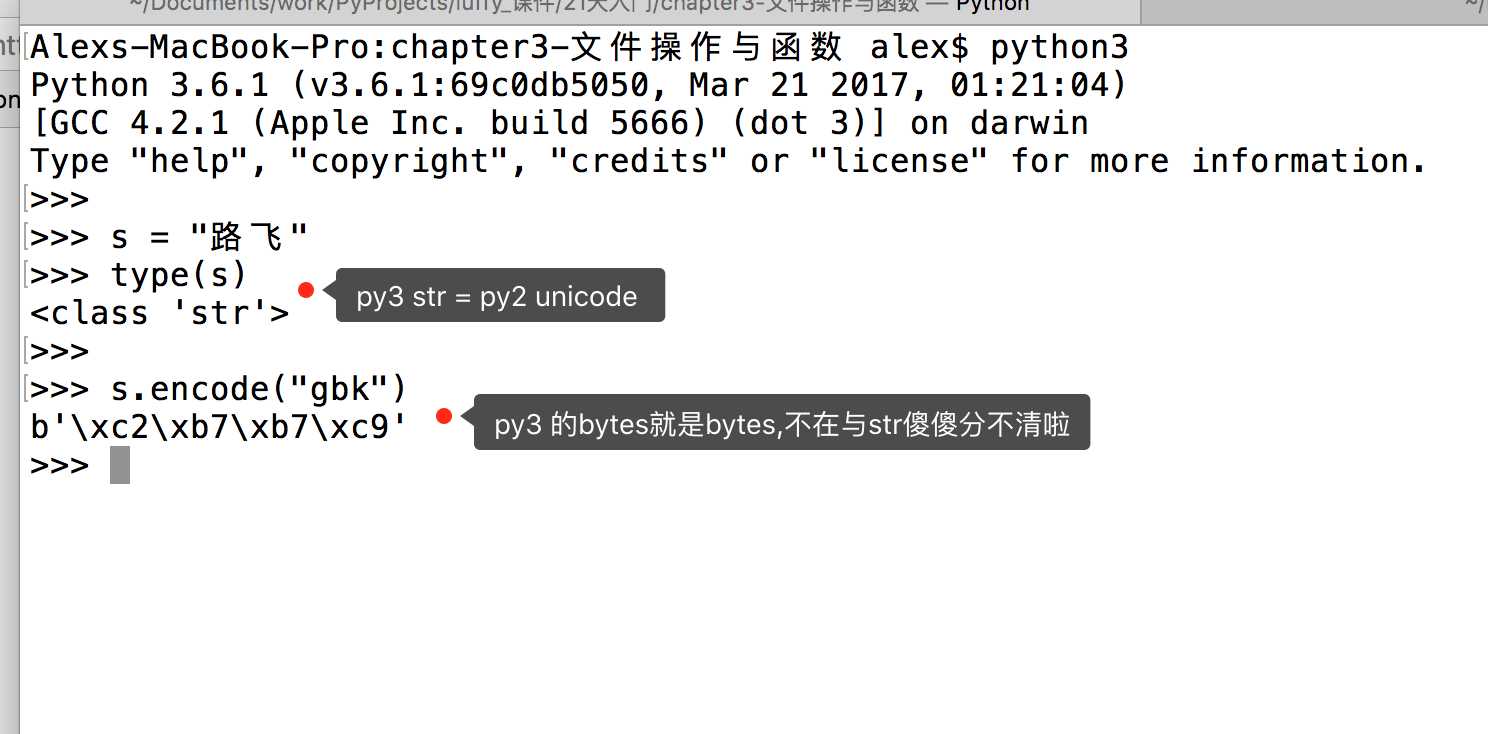
最后一个问题,为什么在py3里,把unicode编码后,字符串就变成了bytes格式? 你直接给我直接打印成gbk的字符展示不好么?我想其实py3的设计真是煞费苦心,就是想通过这样的方式明确的告诉你,想在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示。
常见编码错误的原因有:
- Python解释器的默认编码
- Python源文件文件编码
- Terminal使用的编码
- 操作系统的语言设置 掌握了编码之前的关系后,挨个排错就好
以上是关于Arduino STM32如何让pa11输出高低电平?的主要内容,如果未能解决你的问题,请参考以下文章