Java中Steam流的用法及使用备忘
Posted 划]破
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java中Steam流的用法及使用备忘相关的知识,希望对你有一定的参考价值。
文章目录
- Java中Steam流的用法及使用备忘
Java中Steam流的用法及使用备忘
一. 流的常用创建方法
1-1 使用Collection下的 stream() 和 parallelStream() 方法
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream(); //获取一个顺序流
Stream<String> parallelStream = list.parallelStream(); //获取一个并行流
1-2 使用Arrays 中的 stream() 方法,将数组转成流
Integer[] nums = new Integer[10];
Stream<Integer> stream = Arrays.stream(nums);
1-3 使用Stream中的静态方法:of()、iterate()、generate()
// 1. of()
Stream<Integer> stream = Stream.of(1,2,3,4,5,6);
// 2. iterate()
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);
stream2.forEach(System.out::println); // 0 2 4 6 8 10
// 3. generate()
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);
stream3.forEach(System.out::println);
1-4 使用 BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("F:\\\\test_stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);
1-5 使用 Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("a,b,c,d");
stringStream.forEach(System.out::println);
二、流的中间操作
// 1. 筛选与切片
filter:过滤流中的某些元素
limit skip distinct sorted 都是有状态操作,这些操作只有拿到前面处理后的所有元素之后才能继续下去。
limit(n):获取前n个元素
skip(n):跳过前n元素,配合limit(n)可实现分页
distinct:通过流中元素的 hashCode() 和 equals() 去除重复元素
// 2. 映射
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
// 3. 消费 peek , 类似map,
// map接收的是一个Function表达式,有返回值;
// 而peek接收的是Consumer表达式,没有返回值。
// 4. 排序
sorted():自然排序,流中元素需实现Comparable接口
sorted(Comparator com):定制排序,自定义Comparator排序器
// 5.
2-1 筛选、去重与切片:filter、distinct、skip、limit
// 实例:集合内元素>5,去重,跳过前两位,取剩下元素的两个返回为新集合
Stream<Integer> stream = Stream.of(6, 4, 6, 7, 3, 9, 8, 10, 12, 14, 14);
Stream<Integer> newStream = stream.filter(s -> s > 5) //6 6 7 9 8 10 12 14 14
.distinct() //6 7 9 8 10 12 14
.skip(2) //9 8 10 12 14
.limit(2); //9 8
newStream.forEach(System.out::println);
2-2 映射:map、flatMap
// 1. Map可以看成一个转换器,传入一个对象,返回新的对象
// map的使用实例 stream.map(x->x.getId());
List<String> list = Arrays.asList("a,b,c", "1,2,3");
// 去掉字符串中所有的,
List<String> collect = list.stream().map(s -> s.replaceAll(",", "")).collect(Collectors.toList());
// collect集合内容为:abc,123
System.out.println(collect);
// 2. flatMap 效果:结果展平 ,即把嵌套集合,按照子集合的形式,统一放入到新的一个集合中
// 接收一个函数作为参数,将流中的每个值都换成另一个流,
// 然后把所有流连接成一个流。
Stream<String> stringStream = list.stream().flatMap(s ->
// 将字符串以,分割后得到一个字符串数组
String[] split = s.split(",");
// 然后将每个字符串数组对应流返回,flatMap会自动把返回的所有流连接成一个流
Stream<String> stream = Arrays.stream(split);
return stream;
);
// stringStream.collect(Collectors.toList())的集合内容为:a,b,c,1,2,3
System.out.println(stringStream.collect(Collectors.toList()));
2-3 归约:统计-计算-逻辑处理:reduce
// 说明:reduce看似效果和map相似,
// 但reduce返回的是函数经过执行运算后的结果,
// 而map返回的是处理后新的集合
List<String> memberNames = new ArrayList<>();
memberNames.add("Amitabh");
memberNames.add("Shekhar");
memberNames.add("Aman");
memberNames.add("Rahul");
memberNames.add("Shahrukh");
memberNames.add("Salman");
memberNames.add("Yana");
memberNames.add("Lokesh");
// 将集合中的元素按照#连接成字符串,并返回放置在Optional<String>中
Optional<String> reduced = memberNames.stream()
.reduce((s1,s2) -> s1 + "#" + s2);
// 有值则取出打印显示
reduced.ifPresent(System.out::println);
// 输出内容: Amitabh#Shekhar#Aman#Rahul#Shahrukh#Salman#Yana#Lokesh
// 计算统计实例:
/**
* T reduce(T identity, BinaryOperator<T> accumulator);
* identity:它允许用户提供一个循环计算的初始值。
* accumulator:计算的累加器,
*/
private static void testReduce()
//T reduce(T identity, BinaryOperator<T> accumulator);
System.out.println("给定个初始值,求和");
System.out.println(Stream.of(1, 2, 3, 4).reduce(100, (sum, item) -> sum + item));
System.out.println(Stream.of(1, 2, 3, 4).reduce(100, Integer::sum));
// 输出:110
System.out.println("给定个初始值,求min");
System.out.println(Stream.of(1, 2, 3, 4).reduce(100, (min, item) -> Math.min(min, item)));
System.out.println(Stream.of(1, 2, 3, 4).reduce(100, Integer::min));
// 输出:1
System.out.println("给定个初始值,求max");
System.out.println(Stream.of(1, 2, 3, 4).reduce(100, (max, item) -> Math.max(max, item)));
System.out.println(Stream.of(1, 2, 3, 4).reduce(100, Integer::max));
// 输出:100
//Optional<T> reduce(BinaryOperator<T> accumulator);
// 注意返回值,上面的返回是T,泛型,传进去啥类型,返回就是啥类型。
// 下面的返回的则是Optional类型
System.out.println("无初始值,求和");
System.out.println(Stream.of(1, 2, 3, 4).reduce(Integer::sum).orElse(0));
// 输出:10
Integer sum=Stream.of(1, 2, 3, 4).reduce((x,y)->x+y).get();
System.out.println(sum); // 输出:10
System.out.println("无初始值,求max");
System.out.println(Stream.of(1, 2, 3, 4).reduce(Integer::max).orElse(0));
// 输出:4
System.out.println("无初始值,求min");
System.out.println(Stream.of(1, 2, 3, 4).reduce(Integer::min).orElse(0));
// 输出:1
2-4 排序:sorted
// 按照默认字典顺序排序
stream.sorted();
// 按照sortNo排序
stream.sorted((x,y)->Integer.compare(x.getSortNo(),y.getSortNo()));
2-4-1 函数式接口排序
// 正向排序(默认)
pendingPeriod.stream().sorted(Comparator.comparingInt(ReservoirPeriodResult::getId));
// 逆向排序
pendingPeriod.stream().sorted(Comparator.comparingInt(ReservoirPeriodResult::getId).reversed());
2-4-2 LocalDate 和 LocalDateTime 排序
// 准备测试数据
Stream<DateModel> stream = Stream.of(new DateModel(LocalDate.of(2020, 1, 1))
, new DateModel(LocalDate.of(2021, 1, 1)), new DateModel(LocalDate.of(2022, 1, 1)));
// 正向排序(默认)
stream.sorted(Comparator.comparing(DateModel::getLocalDate))
.forEach(System.out::println);
// 逆向排序
stream.sorted(Comparator.comparing(DateModel::getLocalDate).reversed())
.forEach(System.out::println);
三. 流的终止操作 allMatch,noneMatch,anyMatch,findFirst,findAny,count,max,min
// 匹配和聚合
allmatch,noneMatch,anyMatch用于对集合中对象的某一个属性值是否存在判断。
allMatch全部符合该条件返回true,
noneMatch全部不符合该断言返回true
anyMatch 任意一个元素符合该断言返回true
// 实例:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
boolean allMatch = list.stream().allMatch(e -> e > 10); //false
boolean noneMatch = list.stream().noneMatch(e -> e > 10); //true
boolean anyMatch = list.stream().anyMatch(e -> e > 4); //true
// 其他一些方法
findFirst:返回流中第一个元素
String firstMatchedName = memberNames.stream()
.filter((s) -> s.startsWith("L"))
.findFirst().get();
findAny:返回流中的任意元素
count:返回流中元素的总个数
long totalMatched = memberNames.stream()
.filter((s) -> s.startsWith("A"))
.count();
max:返回流中元素最大值
min:返回流中元素最小值
3-1 普通收集 – 收集为List
// 默认返回的类型为ArrayList,可通过Collectors.toCollection(LinkedList::new)
// 显示指明使用其它数据结构作为返回值容器。
List<String> collect = stream.collect(Collectors.toList());
// 由集合创建流的收集需注意:仅仅修改流字段中的内容,没有返回新类型,
// 如下操作直接修改原始集合,无需处理返回值。
userVos.stream().map(e -> e.setDeptName(hashMap.get(e.getDeptId())))
.collect(Collectors.toList());
// 收集偶数集合的实例:
List<Integer> list = new ArrayList<Integer>();
for(int i = 1; i< 10; i++)
list.add(i);
Stream<Integer> stream = list.stream();
List<Integer> evenNumbersList = stream.filter(i -> i%2 == 0)
.collect(Collectors.toList());
System.out.print(evenNumbersList);
3-2 普通收集 – 收集流为数组(Array)
// list 为 1,2,3,.....100
Stream<Integer> stream = list.stream();
Integer[] evenNumbersArr = stream.[Java] 各种流的分类及区别
https://www.cnblogs.com/lca1826/p/6427177.html
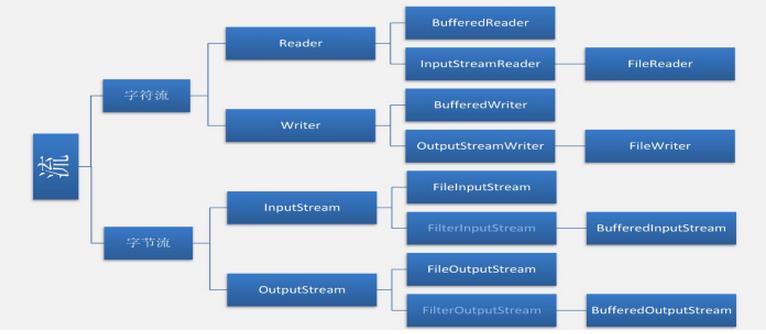
流在Java中是指计算中流动的缓冲区。
从外部设备流向中央处理器的数据流成为“输入流”,反之成为“输出流”。
字符流和字节流的主要区别:
1.字节流读取的时候,读到一个字节就返回一个字节;字符流使用了字节流读到一个或多个字节(中文对应的字节数是两个,在UTF-8码表中是3个字节)时。先去查指定的编码表,将查到的字符返回。
2.字节流可以处理所有类型数据,如:图片,MP3,AVI视频文件,而字符流只能处理字符数据。只要是处理纯文本数据,就要优先考虑使用字符流,除此之外都用字节流。
1.字节流:
字节输入流类:FileInputStream、BufferedInputStream和DataInputStream
FileInputStream:此类用于从本地文件系统中读取文件内容。
构造方法:
·FileInputStream(File file):打开一个到实际文件的连接来创建一个FileInputStream,该文件通过文件系统中的File对象file指定。
·FileInputStream(String name):打开一个到实际文件的连接来创建一个FileInputStream,该文件通过文件系统中的路径名name指定。
常用方法:
·int available():返回下一次对此输入流调用的方法不受阻塞地从此输入流读取(或跳过)的估计剩余字节数。
·void close():关闭此文件输入流并释放与该流关联的所有系统资源。
BufferedInputStream:此类本身带有一个缓冲区,在读取数据时,先放到缓冲区中,可以减少对数据源的访问,提高运行的效率。
构造方法:
·BufferedInputStream(InputStream in):创建一个BufferedInputStream并保存其参数,即输入流in,以便将来使用。
·BufferedInputStream(InputStream in,int size):创建一个具有指定缓冲区大小的BufferedInputStream并保存其参数,即输入流in,以便将来使用。
常用方法:
·int available():返回下一次对此输入流调用的方法不受阻塞地从此输入流读取(或跳过)的估计剩余字节数。
·void close():关闭此输入流并释放与该流关联的所有系统资源。
·int read():从输入流中读取数据的下一个字节。
·int read(byte[] b,int off,int len):从此字节输入流中给定偏移量处开始将各字节读取到指定的byte数组中。
DataInputStream:该类提供一些基于多字节读取方法,从而可以读取基本数据类型的数据。
构造方法:
·DataInputStream(InputStream in):使用指定的底层InputStream创建一个DataInputStream。
常用方法:
·int read(byte[] b):从包含的输入流中读取一定数量的字节,并将它们存储到缓冲区数组b中。
·int read(byte[] b,int off,int len):从包含的输入流中将最多len个字节读入一个byte数组中。
字节输出流类:FileOutputStream、BufferedOutputStream和DataOutputStream
FileOutputStream:此类用于从本地文件系统的文件中写入数据。
构造方法:
·FileOutputStream(File file):创建一个向指定File对象表示的文件中写入数据的文件输出流。
·FileOutputStream(String name):创建一个向具有指定名称的文件中写入数据的输出文件流。
常用方法:
·void close():关闭此文件输出流并释放与此流有关的所有系统资源。
·FileDescriptor getFD():返回与此流有关的文件描述符。
·void write(byte[] b):将b.length个字节从指定byte数组写入此文件输出流中。
·void write(byte[] b,int off,int len):将指定byte数组中从偏移量off开始的len个字节写入此文件输出流。
·void write(int b):将指定字节写入此文件输出流。
BufferedOutputStream:此类本身带有一个缓冲区,在写入数据时,先放到缓冲区中,实现缓冲的数据流。
构造方法:
·BufferedOutputStream(OutputStream out):创建一个新的缓冲输出流,来将数据写入指定的底层输入流。
·BufferedOutputStream(OutputStream out,int size):创建一个新的缓冲输出流,来将具有指定缓冲区大小的数据写入指定的底层输出流。
常用方法:
·void flush():刷新此缓冲的输出流。
·void write(byte[] b,int off,int len):将指定byte数组中从偏移量off开始的len个字节写入此缓冲的输出流。
·void write(int b):将指定的字节写入此缓冲的输出流。
DataOutputStream(OutputStream out):创建一个新的数据输出流,将数据写入指定基础输出流。
常用方法:
·void flush():清空此数据输出流。
·int size():返回计数器written的当前值,即到目前为止写入此数据输出流的字节数。
·void write(byte[] b,int off,int len):将指定byte数组中从偏移量off开始的len个字节写入基础输出流。
·void write(int b):将指定字节(参数b的八个低位)写入基础输出流。
2.字符流:
FileReader:用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。
构造方法:
·FileReader(File file):在给定从中读取数据的File的情况下创建一个新的FileReader。
·FileReader(String fileName):在给定从中读取数据的文件名的情况下创建一个新的FileReader。
BufferedReader类是Reader类的子类,为Reader对象添加字符缓冲器,为数据输入分配内存存储空间,存取数据更为有效。
构造方法:
·BufferedReader(Reader in):创建一个使用默认大小输入缓冲区的缓冲字符输入流。
·BufferedReader(Reader in,int sz):创建一个使用指定大小输入缓冲区的缓冲字符输入流。
操作方法:
·void close():关闭该流并释放与之关联的所有资源。
·void mark(int readAheadLimit):标记流中的当前为止。
·boolean markSupported();判断此流是否支持mark()操作。
·int read():读取单个字符。
·int read(char[] cbuf,int off,int len):将字符读入数组的某一部分。
·String readLine():读取一个文本行。
·boolean ready():判断此流是否已准备好被读取。
·void reset():将流重置到最新的标记。
·long skip(long n):跳过字符。
FileWriter:用来写入字符文件的便捷类,可用于写入字符流。
构造方法:
·FileWriter(File file):根据给定的File对象构造一个FileWriter对象。
·FileWriter(String filename):根据给定的文件名构造一个FileWriter对象。
BufferedWriter:将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
以上是关于Java中Steam流的用法及使用备忘的主要内容,如果未能解决你的问题,请参考以下文章