hadoop2.2的nodemanager无法启动
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop2.2的nodemanager无法启动相关的知识,希望对你有一定的参考价值。
配置完成之后,
在master上 格式化namenode:./bin/hdfs namenode –format
然后
启动hdfs: ./sbin/start-dfs.sh
此时在001上面运行的进程有:namenode secondarynamenode
002和003上面运行的进程有:datanode
启动yarn: ./sbin/start-yarn.sh
此时在001上面运行的进程有:namenode secondarynamenode resourcemanager
002和003上面运行的进程有:
只有datanode
没有nodemanager
这是什么原因?
谢谢。
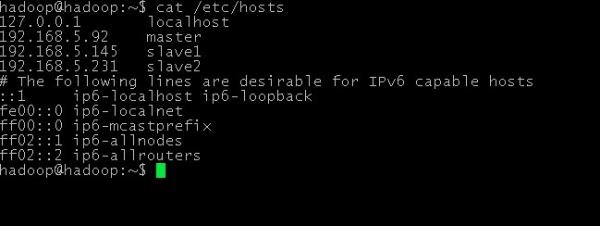
修改 /etc/hosts 文件
把里面的 127.0.0.1 hadoop 去掉
我的节点日志是有错误的。
追答那就把日志贴出来看看
记一次nodemanager无法启动的情况
早上看CDH发现有一个nodemanager挂掉
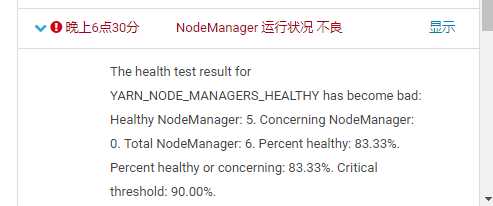
然后查看对应的日志。 发现在日志里面并没有错误。,然然后发现服务器的磁盘满了,赶紧清理磁盘空间
发现在日志里面并没有错误。,然然后发现服务器的磁盘满了,赶紧清理磁盘空间
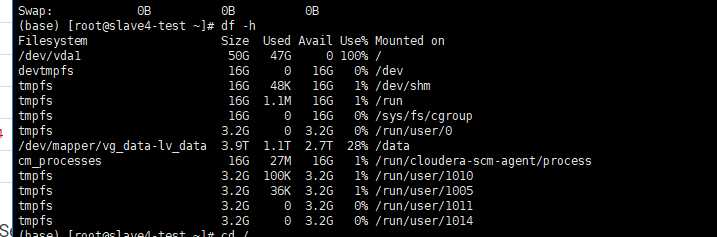
清理磁盘的时候发现主要是/tmp目录下面生成了很多 
类似这种的日志。
清理完空间之后 重启nodemanager。发现还是启不来
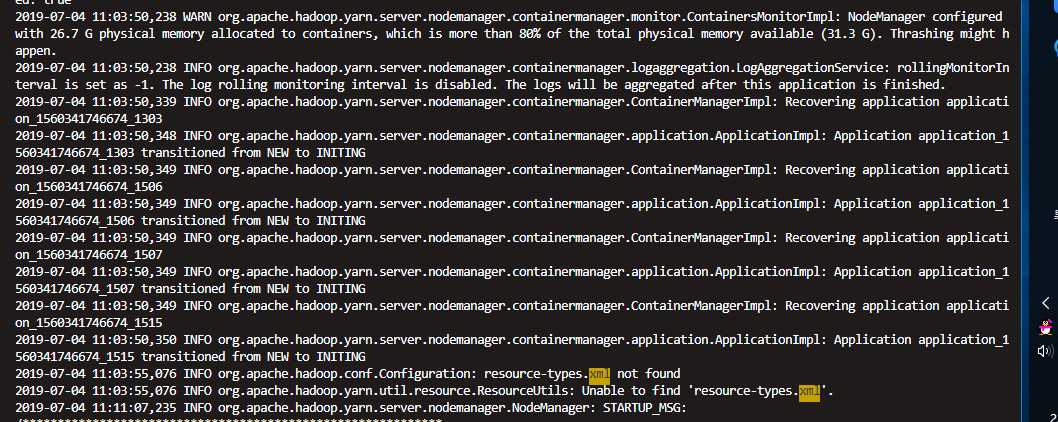
到这里之后发现就停住了。。。。然后CDH页面就挂了nodemanager还是起不来。
继续查看
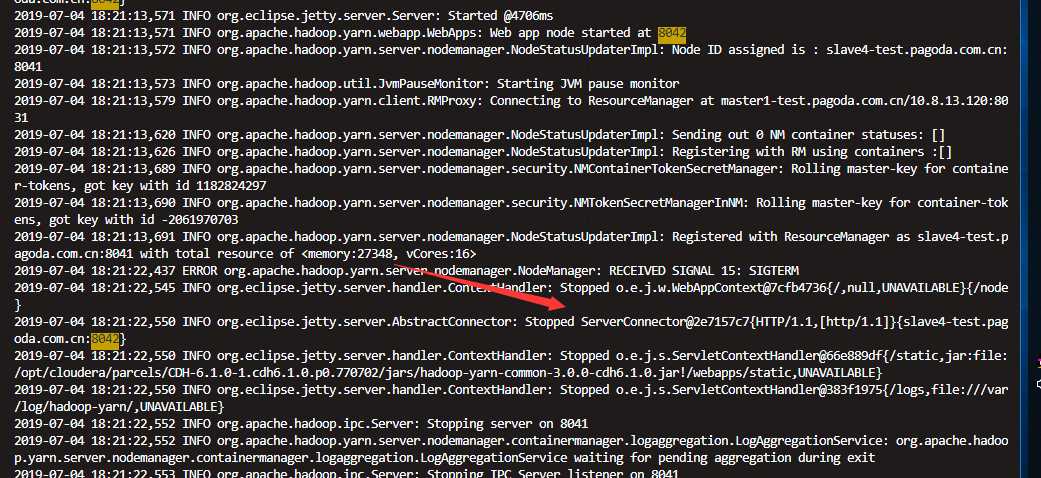
发现8042端口注册不上。 然后继续追述上个日志 只要nodemanager启动就会recovering application
所以 find 一下
find /* -name *application application_1560341746674_1515*
发现 /data/yarn/nm/usercache/root/appcache/* 目录下面很多 类似的文件,时间为头一天晚上7点过,继续看zabbix监控 发现

内存不足,
然后晚上九点过显示磁盘空间不足,解决办法
rm -fr /data/yarn/nm/usercache/*
删除cache之后 重启nodemanager正常
并且删除
/var/lib/hadoop-yarn/yarn-nm-recovery/*
问题分析:由于这台机器上跑大任务,导致内存不足,内存不足 yarnnodemanager会一直报警写到 /tmp目录下,产生很多大文件,进而导致磁盘不足,
删除/tmp 下面的日志之后 启动node 但是一直起不来,yarn会去cache里面 recovering任务,但是这些任务已经过时导致一直起不来,解决办法就是删除这些cache
详细信息可以参考
https://mapr.com/docs/61/AdministratorGuide/c-config-nodemanager-restart.html
以上是关于hadoop2.2的nodemanager无法启动的主要内容,如果未能解决你的问题,请参考以下文章