如何使用iText的HTML转换为PDF
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用iText的HTML转换为PDF相关的知识,希望对你有一定的参考价值。
首先下载 JAR 包
创建 html 文档(将要使用的 HTML 文档素材)
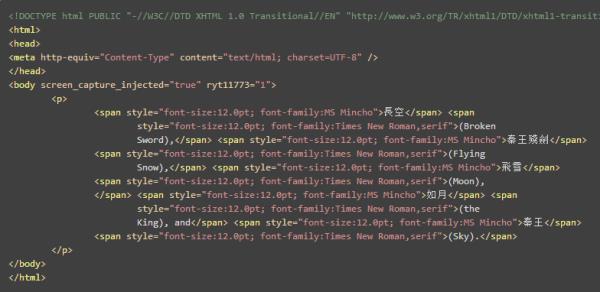
引入 JAR 包 ,编写JAVA 转换代码
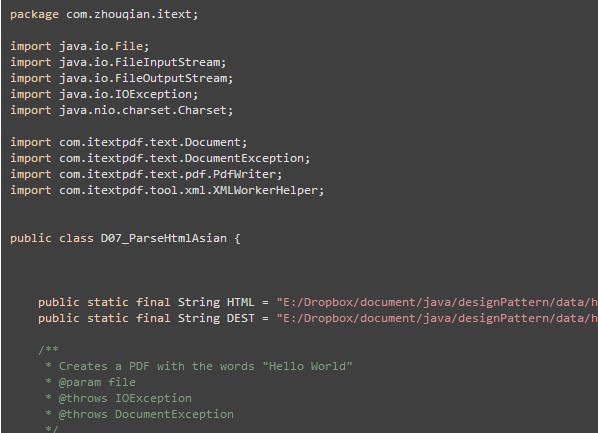
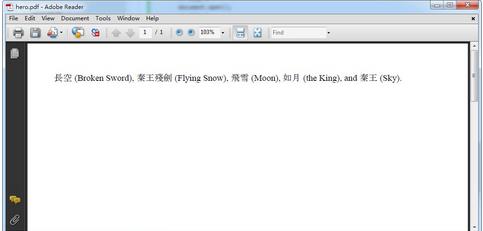
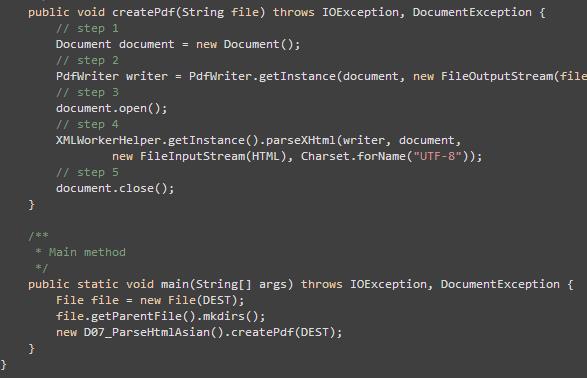 5.在指定路径下就可以得到 PDF 结果
5.在指定路径下就可以得到 PDF 结果
iText PDF;如何使用 Java 将 jpeg2000 转换为 jpg
【中文标题】iText PDF;如何使用 Java 将 jpeg2000 转换为 jpg【英文标题】:iText PDF; howto convert jpeg2000 to jpg using Java 【发布时间】:2011-12-19 01:30:42 【问题描述】:我正在尝试使用 java、iText 和 Java 高级成像库来解决问题。我的软件系统使用 ghostscript 从 PDF 文件创建 jpg 缩略图等。然而,在 CentOS 5.x 上,ghostscript 的最高版本是 8.7,它的一个已知问题是无法处理其中包含 JPEG 2000 图像的 PDF 文件。我的计划是先扫描文件,看看它是否包含 jpeg2000 图像(我已经弄清楚了这部分);如果是这样,则使用 iText 和 Java Advanced Imaging 库(包含 jpeg2000 读写编解码器)将包含的 jpeg2000 文件转换为常规 jpeg 文件,然后将新的 PDF 文件传递给 ghostscript。下面的代码尝试这样做,但会生成另一个包含 jpeg2000 文件的文件。对此的任何帮助将不胜感激。
public class ImageReplacer
public static void main(String [] args)
try
String RESULT = "";
PdfReader reader = new PdfReader("pdf_containing_jpeg2000_images.pdf");
PdfReaderContentParser parser = new PdfReaderContentParser(reader);
MyImageRenderListener listener = new MyImageRenderListener(RESULT);
MyImageConverterListener clistener = new MyImageConverterListener(RESULT);
clistener.setReader(reader);
for (int i = 1; i <= reader.getNumberOfPages(); i++)
parser.processContent(i, clistener);
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream("out.pdf"));
stamper.close();
catch(Exception e)
e.printStackTrace();
class MyImageConverterListener implements RenderListener
protected String path = "";
protected PdfReader reader;
public MyImageConverterListener(String path)
this.path = path;
public void beginTextBlock()
public void endTextBlock()
public void renderImage(ImageRenderInfo renderInfo)
try
PdfImageObject image = renderInfo.getImage();
PdfName filter = (PdfName)image.get(PdfName.FILTER);
if (PdfName.JPXDECODE.equals(filter))
if(image.getDictionary().isStream())
BufferedImage bi = image.getBufferedImage();
if (bi == null) return;
int width = (int)bi.getWidth();
int height = (int)bi.getHeight();
ByteArrayOutputStream imgBytes = new ByteArrayOutputStream();
ImageIO.write(bi, "JPG", imgBytes);
PRStream stream = new PRStream(reader,imgBytes.toByteArray());
stream.clear();
stream.setData(imgBytes.toByteArray(), false, PRStream.NO_COMPRESSION);
stream.put(PdfName.TYPE, PdfName.XOBJECT);
stream.put(PdfName.SUBTYPE, PdfName.IMAGE);
stream.put(new PdfName("foo"+Math.random()), new PdfName("bar"+Math.random()));
stream.put(PdfName.FILTER, PdfName.DCTDECODE);
stream.put(PdfName.WIDTH, new PdfNumber(width));
stream.put(PdfName.HEIGHT, new PdfNumber(height));
stream.put(PdfName.BITSPERCOMPONENT, new PdfNumber(8));
stream.put(PdfName.COLORSPACE, PdfName.DEVICERGB);
catch (Exception e)
e.printStackTrace();
public void renderText(TextRenderInfo renderInfo)
public void setReader(PdfReader r)
reader = r;
【问题讨论】:
【参考方案1】:所以我设法自己解决了这个问题(在 iText 的帮助下,Bruno Lowagie 的行动 - 很棒的书)。重申一下,我的意图是使用 iText 扫描 PDF 以查看它是否包含任何 JPEG2000 图像,以及它是否输出相同的 PDF,但内部 JPEG2000 图像替换为常规 JPEG 图像。这解决了致命的 ghostscript 8.7“无法处理 JPXDecode 数据”错误,但也有助于使 PDF 的 iOS 兼容。
所以孩子们不用再做任何事情了;来了……
步骤 1) 下载 iText 5.x .jar 文件,并下载 jai_imageio-1.1.jar(Java 高级成像库,可让您转换 JPEG2000 文件)
步骤 2) 创建一个名为 PDFConverter.java 的文件并将此代码放入其中:
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.PdfName;
import com.itextpdf.text.pdf.PdfObject;
import com.itextpdf.text.pdf.PRStream;
import com.itextpdf.text.pdf.parser.PdfImageObject;
import com.itextpdf.text.pdf.PdfNumber;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import com.itextpdf.text.pdf.PdfStamper;
import java.io.*;
public class PDFConverter
public static void main(String [] args)
if(args.length==1)
if(hasJpeg2000(args[0]))
System.out.println("Contains JPEG2000 images: Converting them to JPEG...");
convertPDF(args[0]);
System.out.println("Done...");
else
System.out.println("Doesn't contain any JPEG2000 images: Nothing to be done...");
else
System.out.println("Please specify a PDF filename as a command line argument!");
public static boolean hasJpeg2000(String s)
try
PdfReader reader = new PdfReader(s);
int n = reader.getXrefSize();
PdfObject object;
PRStream stream;
for (int i = 0; i < n; i++)
object = reader.getPdfObject(i);
if (object == null || !object.isStream())continue;
stream = (PRStream)object;
PdfImageObject image = new PdfImageObject(stream);
PdfName filter = (PdfName)image.get(PdfName.FILTER);
if (PdfName.JPXDECODE.equals(filter))
return true;
catch(Exception e)
e.printStackTrace();
return false;
public static void convertPDF(String s)
try
PdfReader reader = new PdfReader(s);
int n = reader.getXrefSize();
PdfObject object;
PRStream stream;
for (int i = 0; i < n; i++)
object = reader.getPdfObject(i);
if (object == null || !object.isStream())continue;
stream = (PRStream)object;
PdfImageObject image = new PdfImageObject(stream);
PdfName filter = (PdfName)image.get(PdfName.FILTER);
if (PdfName.JPXDECODE.equals(filter))
BufferedImage bi = image.getBufferedImage();
if (bi == null) continue;
int width = (int)(bi.getWidth());
int height = (int)(bi.getHeight());
ByteArrayOutputStream imgBytes = new ByteArrayOutputStream();
ImageIO.write(bi, "JPG", imgBytes);
stream.clear();
stream.setData(imgBytes.toByteArray(),false, PRStream.NO_COMPRESSION);
stream.put(PdfName.TYPE, PdfName.XOBJECT);
stream.put(PdfName.SUBTYPE, PdfName.IMAGE);
stream.put(new PdfName("foo"+Math.random()), new PdfName("bar"+Math.random()));
stream.put(PdfName.FILTER, PdfName.DCTDECODE);
stream.put(PdfName.WIDTH, new PdfNumber(width));
stream.put(PdfName.HEIGHT, new PdfNumber(height));
stream.put(PdfName.BITSPERCOMPONENT,new PdfNumber(8));
stream.put(PdfName.COLORSPACE, PdfName.DEVICERGB);
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream("out.pdf")); stamper.close();
catch(Exception e)
e.printStackTrace();
步骤3)按如下方式编译上述文件:
javac -cp .:iText-5.0.4.jar:jai_imageio-1.1.jar PDFConverter.java
第 4 步)使用 PDF 运行程序...
java -cp .:iText-5.0.4.jar:jai_imageio-1.1.jar PDFConverter PDFFileName.pdf
嘘……
【讨论】:
【参考方案2】:效果很好,但我在使用 GlassFish v3.1 时遇到了一些问题。 Glassfish 的行为就像 Classpath 中没有 jai_imageio-1.1.jar 一样。我修复了这个问题,将 jai_imageio.jar 放在我的“/path/to/glassfish/domains/domain1/lib/ext/”文件夹中。
【讨论】:
【参考方案3】:我在使用 Reece 的 PDFConverter 时遇到了一些 NullPointer 问题,因为我的 PDF 在 GhostScript on CentOS 5.3 - Unable to process JPXDecode data 中有不同类型的嵌入元素。所以我做了一些对象/类型检查并将输出文件名添加到命令行。
其他一切都很棒,并且非常适合图像 jpeg2000 问题。感谢里斯 :)
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.PdfName;
import com.itextpdf.text.pdf.PdfObject;
import com.itextpdf.text.pdf.*;
import com.itextpdf.text.pdf.PRStream;
import com.itextpdf.text.pdf.parser.PdfImageObject;
import com.itextpdf.text.pdf.PdfNumber;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import com.itextpdf.text.pdf.PdfStamper;
import java.io.*;
public class PDFConverter
public static void main(String [] args)
if(args.length==2)
if(hasJpeg2000(args[0]))
System.out.println("Contains JPEG2000 images: Converting them to JPEG...");
convertPDF(args[0], args[1]);
System.out.println("Done...");
else
System.out.println("Doesn't contain any JPEG2000 images: Nothing to be done...");
else
System.out.println("Please specify a PDF filename and a output filename as a command line arguments!");
public static boolean hasJpeg2000(String s)
try
PdfReader reader = new PdfReader(s);
int n = reader.getXrefSize();
PdfObject object;
PRStream stream;
for (int i = 0; i < n; i++)
object = reader.getPdfObject(i);
if (object == null || !object.isStream())continue;
stream = (PRStream)object;
PdfObject pdfsubtype = stream.get(PdfName.SUBTYPE);
System.out.println(pdfsubtype);
if (pdfsubtype != null && pdfsubtype.toString().equals(PdfName.IMAGE.toString()))
PdfImageObject image = new PdfImageObject(stream);
PdfName filter = (PdfName)image.get(PdfName.FILTER);
if (PdfName.JPXDECODE.equals(filter))
return true;
catch(Exception e)
e.printStackTrace();
return false;
private static void filterObject(PdfImageObject image,PdfName filter,PRStream stream) throws java.io.IOException
if (PdfName.JPXDECODE.equals(filter))
BufferedImage bi = image.getBufferedImage();
if (bi == null) return;
int width = (int)(bi.getWidth());
int height = (int)(bi.getHeight());
ByteArrayOutputStream imgBytes = new ByteArrayOutputStream();
ImageIO.write(bi, "JPG", imgBytes);
stream.clear();
stream.setData(imgBytes.toByteArray(),false, PRStream.NO_COMPRESSION);
stream.put(PdfName.TYPE, PdfName.XOBJECT);
stream.put(PdfName.SUBTYPE, PdfName.IMAGE);
stream.put(new PdfName("foo"+Math.random()), new PdfName("bar"+Math.random()));
stream.put(PdfName.FILTER, PdfName.DCTDECODE);
stream.put(PdfName.WIDTH, new PdfNumber(width));
stream.put(PdfName.HEIGHT, new PdfNumber(height));
stream.put(PdfName.BITSPERCOMPONENT,new PdfNumber(8));
stream.put(PdfName.COLORSPACE, PdfName.DEVICERGB);
public static void convertPDF(String s, String out)
try
PdfReader reader = new PdfReader(s);
int n = reader.getXrefSize();
PdfObject object;
PRStream stream;
for (int i = 0; i < n; i++)
object = reader.getPdfObject(i);
if (object == null || !object.isStream())continue;
stream = (PRStream)object;
PdfObject pdfsubtype = stream.get(PdfName.SUBTYPE);
if (pdfsubtype != null && pdfsubtype.toString().equals(PdfName.IMAGE.toString()))
PdfImageObject image = new PdfImageObject(stream);
Object listOrName = image.get(PdfName.FILTER);
if (listOrName instanceof PdfName)
PdfName filter = (PdfName)image.get(PdfName.FILTER);
filterObject(image, filter, stream);
else if (listOrName instanceof PdfArray)
PdfArray list = (PdfArray)image.get(PdfName.FILTER);
for (int j = 0; j < list.size(); j++)
PdfName filter = list.getAsName(j);
filterObject(image, filter, stream);
else
System.err.println("Unknown Obejcttype: " + listOrName);
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(out)); stamper.close();
catch(Exception e)
e.printStackTrace();
【讨论】:
以上是关于如何使用iText的HTML转换为PDF的主要内容,如果未能解决你的问题,请参考以下文章
如何使用 iText 将带有图像和超链接的 HTML 转换为 PDF?
iText 7 将 HTML 转换为 PDF - 如何查看整个宽表?
如何使用 iText 和 XMLWorker 生成有效的 PDF/A 文件(HTML 到 PDF/A 过程)