ElasticSearch 常见的集群部署方式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch 常见的集群部署方式相关的知识,希望对你有一定的参考价值。
参考技术A 在开发环境,一个节点可以承担多种角色;生产环境中,需要根据数据量,写入和查询的吞吐量,选择合适的部署方式,建议设置单一角色的节点(dedicated node);一个节点在默认情况下会同时扮演:Master Node,Data Node 和 Ingest Node。
建议将 Kibana 部署在 Coordinating 上。
集群处在 3 个数据中心,数据 3 写,GTM 分发读请求。
基于Kubernetes集群部署Elasticsearch集群
在k8s中部署elasticsearch集群
文章目录
1.部署分析
elasticsearch集群节点规划为3台
elasticsearch采用statefulset控制器部署无状态的应用,配合StorageClass将每个Pod的数据进行持久化
elasticsearch由于是3个节点,每个节点的配置文件都需要写上三个节点的ip,但是我们是k8s里跑es集群,pod的ip是无法固定的,但是我们使用了statfulset之后,pod的的名称就是固定的,因此我们可以在配置文件里写好pod的名称,通过服务发现的方式就可以识别到3个pod
elasticsearch数据存储采用StorageClass PV动态供给的方式实现每个Pod都使用自己的PVC,进行数据持久化存储
2.准备镜像并推送至Harbor仓库
1.拉取镜像
[root@k8s-master1 EFK]# docker pull elasticsearch:7.4.2
7.4.2: Pulling from library/elasticsearch
d8d02d457314: Pull complete
f26fec8fc1eb: Pull complete
8177ad1fe56d: Pull complete
d8fdf75b73c1: Pull complete
47ac89c1da81: Pull complete
fc8e09b48887: Pull complete
367b97f47d5c: Pull complete
Digest: sha256:543bf7a3d61781bad337d31e6cc5895f16b55aed4da48f40c346352420927f74
Status: Downloaded newer image for elasticsearch:7.4.2
docker.io/library/elasticsearch:7.4.2
2.添加harbor仓库
#所有节点都按如下操作
1)增加harbor仓库地址
vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://7lhvut0q.mirror.aliyuncs.com"],
"insecure-registries": [
"harbor.jiangxl.com"
]
}
2)添加hosts解析
vim /etc/hosts
192.168.16.106 harbor.jiangxl.com
3)重启docker
systemctl restart docker
4)登陆Harbor
docker login harbor.jiangxl.com
Username: admin
Password: admin
3.推送镜像到harbor
[root@k8s-master1 EFK]# docker tag elasticsearch:7.4.2 harbor.jiangxl.com/efk/elasticsearch:7.4.2
[root@k8s-master1 EFK]# docker push elasticsearch:7.4.2
3.创建StorageClass动态PV资源
[root@k8s-master1 elasticsearch]# vim es-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: es-storageclass
provisioner: nfs-storage-01
reclaimPolicy: Retain
[root@k8s-master1 elasticsearch]# kubectl create -f es-storageclass.yaml
storageclass.storage.k8s.io/es-storageclass created
4.编写es集群configmap资源
无法对每个Pod设置单独配置文件,因此配置文件中每个节点不同的配置都以POD内部变量来实现
[root@k8s-master1 elasticsearch]# vimelasticsearch-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: es-cluster-config
namespace: elasticsearch
data:
elasticsearch.yml: |-
cluster.name: es-cluster #设置集群的名称
node.name: ${POD_NAME} #设置节点的名称,无法为每个POD单独设置配置文件,因此采用POD环境变量来设置
path.data: /data/elasticsearch/data #数据存储路径
http.port: 9200
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["es-cluster-0.es-cluster", "es-cluster-1.es-cluster","es-cluster-2.es-cluster"] #集群节点列表,我们利用k8s的coredns通过域名来找到对应的pod,格式:pod名称.svc名称
cluster.initial_master_nodes: ["es-cluster-0.es-cluster", "es-cluster-1.es-cluster","es-cluster-2.es-cluster"]
node.data: true
node.master: true
node.max_local_storage_nodes: 3
discovery.zen.fd.ping_timeout: 120s
discovery.zen.fd.ping_retries: 6
discovery.zen.fd.ping_interval: 30s
http.cors.enabled: true
http.cors.allow-origin: "*"
5.编写es集群statfulset资源
elasticsearch部署采用statfulset资源,并结合StorageClass为每个Pod提供数据持久化
[root@k8s-master1 elasticsearch]# vim elasticsearch-statfulset.yaml
apiVersion: apps/v1 #api版本号
kind: StatefulSet #控制器类型为statfulset
metadata: #定义元数据
labels: #定义标签
k8s-app: es-cluster
version: v7.4.2
name: es-cluster #指定控制器名称
namespace: elasticsearch #指定资源所在的命名空间
spec: #定义属性
replicas: 3 #设置副本数
selector: #定义标签选择器,指定去管理哪些pod
matchLabels:
k8s-app: es-cluster
version: v7.4.2
serviceName: es-cluster #指定servicename,也就是容器的主机名,第一个pod就是es-cluster-0以此类推
template: #定义pod模板信息
metadata: #定义元数据
labels: #定义标签
k8s-app: es-cluster
version: v7.4.2
spec: #定义pod的属性
containers: #定义容器
- name: es-cluster #容器的名称
image: harbor.jiangxl.com/efk/elasticsearch:7.4.2 #镜像的版本号
ports: #定义容器开放的端口号
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
env: #定义环境变量
- name: ES_JAVA_OPTS #ES_JAVA_OPTS变量会替换对应配置文件中的内容
value: "-Xms512m -Xmx512m"
- name: POD_NAME #定义一个POD名称的环境变量,用于configmap调用
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_IP #定义一个PODIP的环境变量,用于configmap调用
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts: #定义存储卷挂载
- name: es-cluster-data #挂载卷的名称
mountPath: /data/elasticsearch/data #挂载到容器的指定路径
- name: es-cluster-config #挂载卷的名称
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml #挂载到容器的指定路径
subPath: elasticsearch.yml #由于是只挂载一个文件,而不是覆盖整个目录,因此需要声明挂载的文件名称
initContainers: #定义初始化容器,初始化容器在主容器启动执行进行系统调优
- name: es-cluster-init #初始化容器的名称
image: harbor.jiangxl.com/efk/alpine:3.6 #初始化容器的版本号
command: ["/sbin/sysctl","-w","vm.max_map_count=262144"] #初始化容器执行的命令,整个目录就是调整一个内核参数
securityContext: #开启特权模式,如果不开启特权模式,容器将无权限执行命令
privileged: true
- name: es-cluster-permissions #定义第二个初始化容器的名称
image: harbor.jiangxl.com/efk/alpine:3.6 #初始化容器的版本号
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] #执行命令,这个命令主要是将主容器挂载的数据路径权限进行调整,否则主容器启动后无权限在里面写入数据
securityContext: #开启特权模式
privileged: true
volumeMounts: #定义存储卷挂载,这里主要是将主容器挂载的存储首先挂载到初始化容器,权限调整后,主容器方可使用
- name: es-cluster-data
mountPath: /usr/share/elasticsearch/data
volumes: #定义存储卷
- name: es-cluster-config #定义存储卷的名称
configMap: #存储卷的类型为configMap
name: es-cluster-config #指定的configMap名称
volumeClaimTemplates: #定义pvc模板,由于es是有状态的服务,每个pod都需要单独存储数据,因此需要使用StorageClass动态创建pv
- metadata: #定义元数据
name: es-cluster-data #定义pvc的名称,容器挂载pvc的名称要与这里的名称保持一致
spec: #定义属性
storageClassName: es-storageclass #指定使用哪个StorageClass动态创建pv
accessModes: #访问模式为多主机可读可写
- ReadWriteMany
resources: #设置存储卷的容量
requests:
storage: 10Gi
6.编写es集群svc资源
也可以通过ingress实现,其实es暴露在外部的意义并不大,毕竟也是项目程序调用的,我暴露在外面主要为了方便使用es-head插件观察es集群上的数据
[root@k8s-master1 elasticsearch]# vim elasticsearch-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: es-cluster
name: es-cluster
namespace: elasticsearch
spec:
ports:
- port: 9200
protocol: TCP
targetPort: 9200
nodePort: 19200 #对外暴露的端口
selector:
k8s-app: es-cluster
type: NodePort #类型采用Nodeport方式
7.创建所有资源
[root@k8s-master1 elasticsearch]# kubectl apply -f ./
configmap/es-cluster-config created
statefulset.apps/es-cluster created
service/es-cluster created
storageclass.storage.k8s.io/es-storageclass created
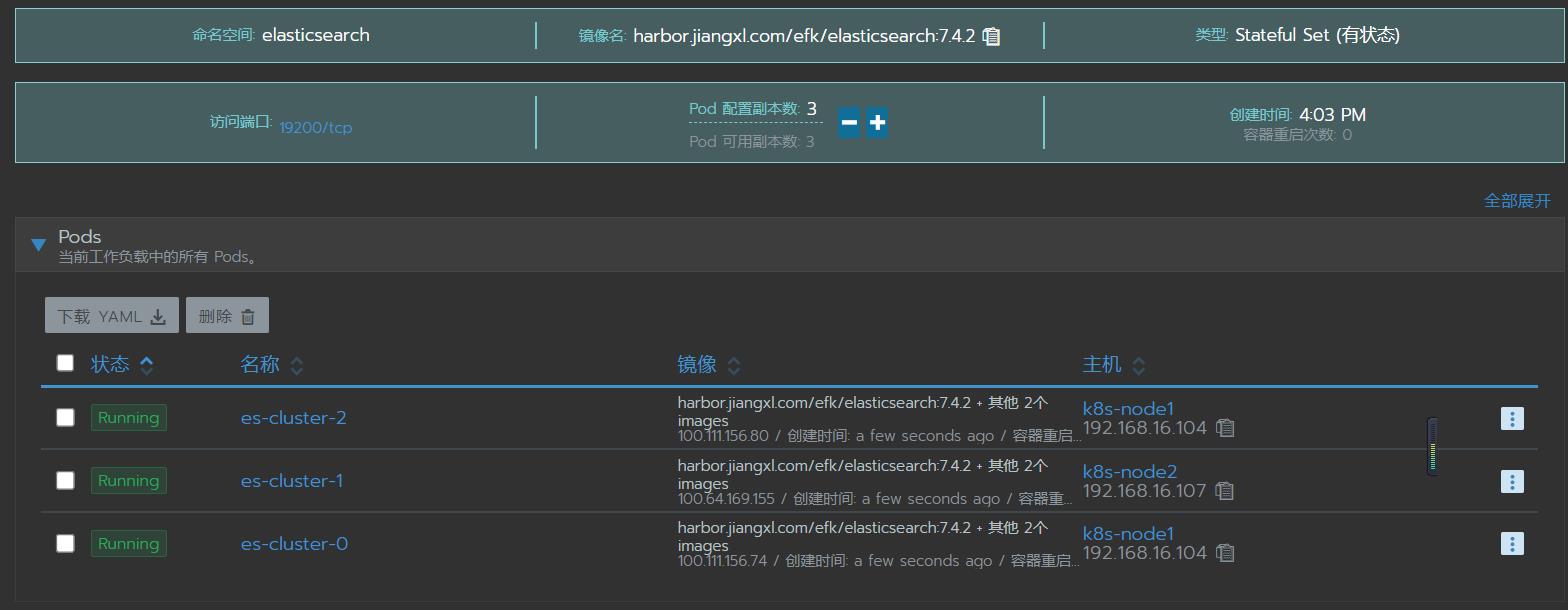
8.查看资源的状态
8.1.查看es的资源状态
[root@k8s-master1 elasticsearch]# kubectl get all -n elasticsearch
NAME READY STATUS RESTARTS AGE
pod/es-cluster-0 1/1 Running 0 27m
pod/es-cluster-1 1/1 Running 0 27m
pod/es-cluster-2 1/1 Running 0 27m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/es-cluster NodePort 10.99.141.102 <none> 9200:19200/TCP 27m
NAME READY AGE
statefulset.apps/es-cluster 3/3 27m
、
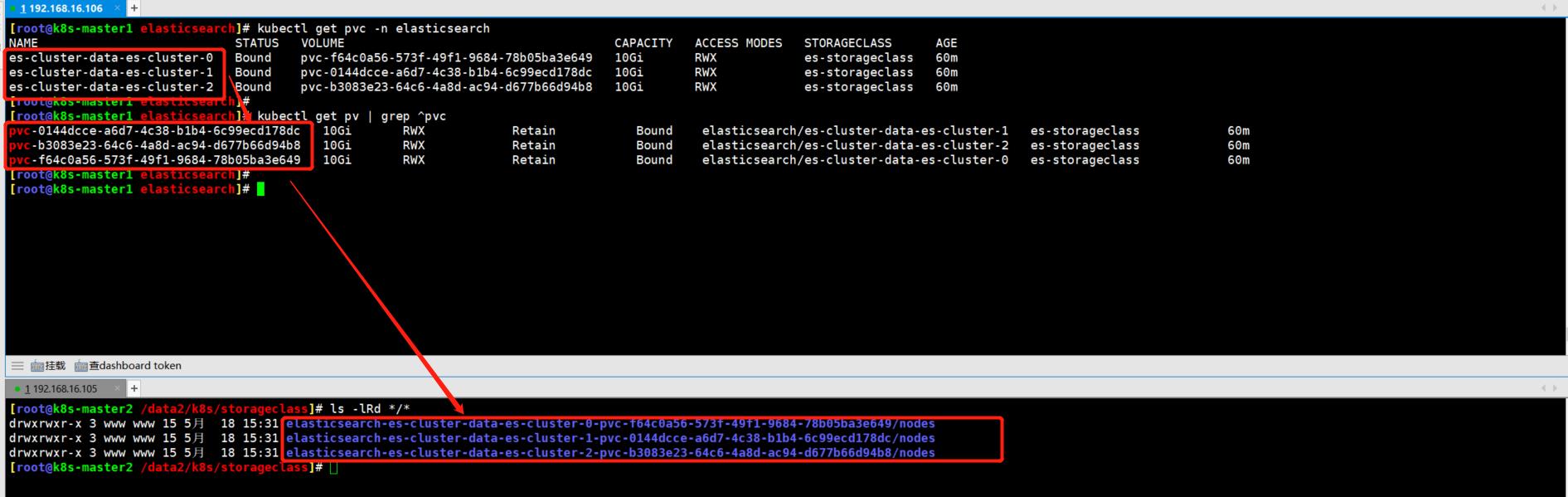
8.2.查看es每个节点使用的pv和pvc信息
每个pod都是一个es节点,每个节点都一个pvc将数据持久化
[root@k8s-master1 elasticsearch]# kubectl get pvc -n elasticsearch
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
es-cluster-data-es-cluster-0 Bound pvc-f64c0a56-573f-49f1-9684-78b05ba3e649 10Gi RWX es-storageclass 60m
es-cluster-data-es-cluster-1 Bound pvc-0144dcce-a6d7-4c38-b1b4-6c99ecd178dc 10Gi RWX es-storageclass 60m
es-cluster-data-es-cluster-2 Bound pvc-b3083e23-64c6-4a8d-ac94-d677b66d94b8 10Gi RWX es-storageclass 60m
[root@k8s-master1 elasticsearch]# kubectl get pv | grep ^pvc
pvc-0144dcce-a6d7-4c38-b1b4-6c99ecd178dc 10Gi RWX Retain Bound elasticsearch/es-cluster-data-es-cluster-1 es-storageclass 60m
pvc-b3083e23-64c6-4a8d-ac94-d677b66d94b8 10Gi RWX Retain Bound elasticsearch/es-cluster-data-es-cluster-2 es-storageclass 60m
pvc-f64c0a56-573f-49f1-9684-78b05ba3e649 10Gi RWX Retain Bound elasticsearch/es-cluster-data-es-cluster-0 es-storageclass 60m
9.查看es集群信息
9.1.查看集群状态
[root@k8s-master1 ~]# curl http://192.168.16.106:19200/_cluster/health?pretty{ "cluster_name" : "es-cluster", "status" : "green", #集群状态为green "timed_out" : false, "number_of_nodes" : 3, #3个节点 "number_of_data_nodes" : 3, #3个数据节点 "active_primary_shards" : 0, "active_shards" : 0, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0}
9.2.查看集群的节点信息
[root@k8s-master1 ~]# curl http://192.168.16.106:19200/_cat/nodes100.64.169.155 20 96 14 1.29 1.16 0.93 dilm - es-cluster-1100.111.156.74 24 92 8 0.08 0.24 0.50 dilm * es-cluster-0100.111.156.80 19 92 8 0.08 0.24 0.50 dilm - es-cluster-2
10.创建索引并在es-head查看集群
curl -XPUT 'http://192.168.16.106:19200/index1?pretty' -H 'Content-Type: application/json' -d '{"settings": { "number_of_shards":3, "number_of_replicas": 2}}'curl -XPUT 'http://192.168.16.106:19200/index2?pretty' -H 'Content-Type: application/json' -d '{"settings": { "number_of_shards":5, "number_of_replicas": 2}}'curl -XPUT 'http://192.168.16.106:19200/es-cluster-successful?pretty' -H 'Content-Type: application/json' -d '{"settings": { "number_of_shards":7, #分片数 "number_of_replicas": 2 #副本数,一般是集群节点个数-1}}'

以上是关于ElasticSearch 常见的集群部署方式的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch7.8.0版本入门——集群部署(linux环境-centos7)
ElasticSearch 集群与x-pack监控集群分开部署