Apache Flink 的提出背景
我们先从较高的抽象层次上总结当前数据处理方面主要遇到的数据集类型(types of datasets)以及在处理数据时可供选择的处理模型(execution models),这两者经常被混淆,但实际上是不同的概念
数据集的类型
当前数据处理主要遇到的数据集类型可分为两大类,①Unbounded,无限的数据集,体现为快速持续到达的流式数据 ②Bounded,有限的数据集,通常不可改变,即不会发生更新的数据集
传统数据处理框架通常把现实世界的数据抽象为有限的数据集,或者说是批(batch)数据,但现实世界的数据实际上是无限的,下面是一些 Unbounded 数据集的例子
-
产生于终端用户与移动应用或 Web 应用交互的数据
-
物理传感器传输的实时测量数据
-
金融市场的实时数据
-
机器日志
数据处理模型的类型
主要也分为两类,①Streaming,流式的,在数据不断产生的同时持续处理数据 ②Batch,批式的,在有限的时间内完成一批数据完整的处理,在处理结束后释放计算资源
尽管不对应的搭配的处理效果可能不尽如人意,但是确实可以用任一种数据处理模型来处理任一种类型的数据集,例如,批处理模型长久以来的被用于处理 Unbounded 数据集,尽管它在 Windowing,状态管理和无序数据处理上有着各种各样的问题
Flink 是基于流式处理模型设计的,它连续地处理不断产生的数据,这种在数据集类型和数据处理模型上的一致性保证了数据处理的准确性和高效性
Apache Flink 的流式基因
Flink 是一个为分布式流式数据处理设计的开源框架,①它能保证即使处理的数据以乱序到达,或者延时到达,都能得到正确的处理结果 ②Flink 是有状态的(stateful),并且有良好的容错性(fault-tolerant),因此它能够在出错时无缝地恢复,并且可以保证 Excatly-once 的应用状态 ③在大规模应用上有良好的表现,可以在数千个节点上以高吞吐量和低延迟运行
前面提到了保持数据集类型和数据处理模型一致性的好处,下面提到的 Flink 的性质,包括状态管理,无序数据处理和灵活的 Windowing 等等,都是针对准确地在无限数据集上进行计算设计和优化的
Excatly-once 语义
Flink 为带状态的计算提供了 Excatly-once 的语义保证,有状态意味着应用程序可以维护已处理数据的集合或聚集结果,Flink 的 checkpointing 机制为在故障发生时恢复应用程序状态保证了 Excatly-once 的语义
Event time 语义
Flink 支持流处理和 Windowing 的 Event time 语义,Event time 能简化在流上对无序到达的事务或延迟到达的事务计算出准确结果
灵活的 Windowing
除了数据驱动的 Windows,Flink 支持基于时间,计数或会话的 Windowing,可以通过定制 Windowing 的触发条件来支持复杂的流模式,Flink 的 Windowing 提供了模拟数据创建时的环境的方法
轻量级的 Fault tolerant
Flink 提供轻量级的 Fault tolerant 以支持同时提供高吞吐率和 Excatly-once 的语义,Flink 可以从错误中无数据丢失(zero data loss)的恢复,这不会太过影响 Flink 的可靠性和性能
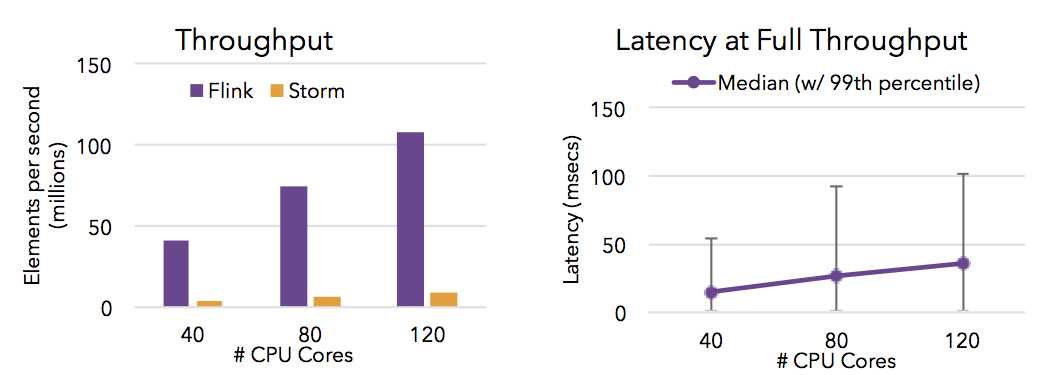
高吞吐与低延迟
Savepoint 机制
Flink 的 Savepoint 机制提供了版本化妆台的功能,在不丢失状态和仅需短暂停工的条件下,支持了上传应用程序以及重新处理历史数据
分布式的支持
Flink 可以在数千个节点上的部署和运行,提供了 Mesos 和 YARN 上运行的支持
Apache Flink 的批式兼容
Flink 使用 DataStream API 处理 Unbounded 数据集,用 DataSet API 处理 Bounded 数据集
在 Flink 框架下,Bounded 数据集可以视为 Unbounded 数据集的特例,DataSet API 正是这么处理 Bounded 数据集的,它将 Bounded 数据集视为有限的流
Flink 使用大同小异的方式处理 Bounded 和 Unbounded 数据集