RocketMq实现延时队列
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMq实现延时队列相关的知识,希望对你有一定的参考价值。
参考技术A 1.yml配置需要注意name-server是rocket部署的ip+端口
2.config
3.消息生产者
4.消息消费者
5.发送普通消息和发送延迟消息
如果有人再问你怎么实现分布式延时消息,这篇文章丢给他
1.背景
上篇文章介绍了RocketMQ整体架构和原理有兴趣的可以阅读一下,在这篇文章中的延时消息部分,我写道开源版的RocketMQ只提供了18个层级的消息队列延时,这个功能在开源版中显得特别鸡肋,但是在阿里云中的RocketMQ却提供了支持40天之内任意秒级延时队列,果然有些功能你只能充钱才能拥有。当然你或许想换一个开源的消息队列,在开源社区中消息队列延时消息很多都没有被支持比如:RabbitMQ,Kafka等,都只能通过一些特殊方法才能完成延时的功能。为什么这么多都没有实现这个功能呢?是因为技术难度比较复杂吗?接下来我们分析一下如何才能实现一个延时消息。
2.本地延时
在实现分布式消息队列的延时消息之前,我们想想我们平时是如何在自己的应用程序上实现一些延时功能的?在Java中可以通过下面的方式来完成我们延时功能:
-
ScheduledThreadPoolExecutor:ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,我们提交任务的时候,会将任务首先提交到DelayedWorkQueue一个优先级队列中,按照过期时间进行排序,这个优先级队列也就是我们堆结构,每次提交任务排序的复杂度是O(logN)。然后取任务的时候就会从堆顶取出我们的任务,也就是我们延迟时间最小的任务。ScheduledThreadPoolExecutor有个好处是执行延时任务可以支持多线程并行执行,因为他继承的是ThreadPoolExecutor。
- Timer:Timer也是利用优先级队列结构做的,但是其没有继承线程池,相对来说比较独立,不支持多线程,只能使用单独的一个线程。
3.分布式消息队列延时
我们实现本地延时比较简单,直接使用Java中现成的即可,那我们分布式消息队列的实现有哪些难点呢?
有很多同学首先会想到我们实现分布式消息队列的延时任务,可不可以直接使用本地的那一套,用ScheduledThreadPoolExecutor,Timer,当然这是可以的,前提是你的消息量很小,但是我们分布式消息队列往往都是企业级别的中间件,数据量都是非常的大,那么我们纯内存的方案肯定是行不通的。所以我们就有了下面这几个方案来解决我们这个问题。
3.1 数据库
数据库一般来说是我们很容易想到的一个办法,我们通常可以建立下面这样一个表:
CREATE TABLE `delay_message` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`excute_time` bigint(16) DEFAULT NULL COMMENT ‘执行时间,ms级别‘,
`body` varchar(4096) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT ‘消息体‘,
PRIMARY KEY (`id`),
KEY `time_index` (`excute_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;这个表中我们使用excute_time代表我们真实的执行时间,并且对其建立索引,然后在我们的消息服务中,启动一个定时任务,定时从数据库中扫描已经可以执行的消息,然后开始执行,具体流程如下面所示: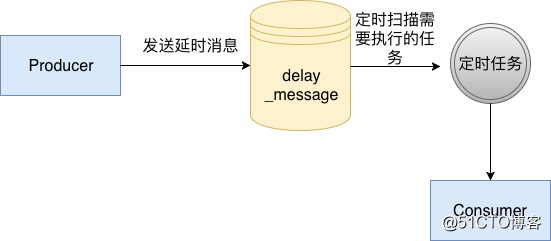
使用数据库的方法是一个比较原始的方法,在没有延时消息这个概念之前,要做一个订单多少分钟过期的这种功能,通常使用这个方法去完成。而这个方法通常也比较局限于我们单个业务,如果想扩展为我们企业级的一个中间件的话是不行的,因为mysql由于BTree的特性,会随着维护二级索引的开销越来越大,导致写入会越来越慢,所以这个方案通常不会被考虑。
RocksDB/LevelDB
我们之前介绍RocketMQ在开源版本中只实现了18个Level的延时消息,但是有很多公司基于RocketMQ做了自己的一套支持任意时间的延时消息,在美团内部封装了RocketMQ使用LevelDB做了对延时消息的封装,在滴滴开源的DDMQ中,使用了RocksDB对RocketMQ的延时消息部分进行了封装。
其原理基本和Mysql类似,如下图所示: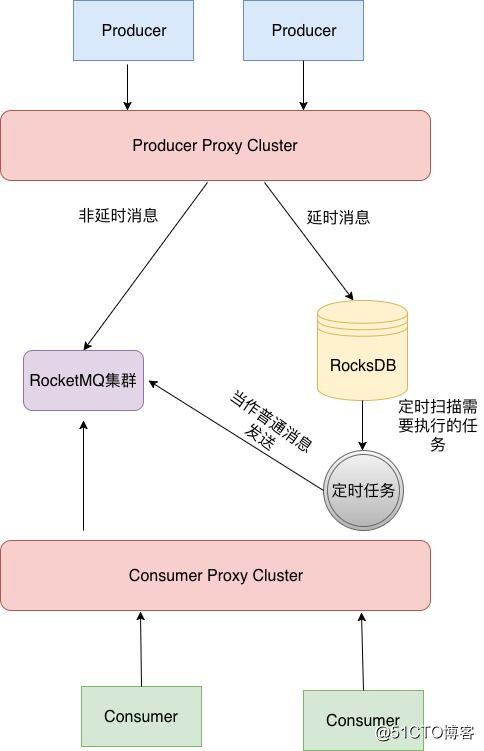
- Step1: DDMQ发送消息的时候会有一个代理层,用于将消息做分发,因为其内部有多种消息队列,kafka,rocketMQ等等,如果是延时消息会将消息发送到RockesDB的存储。
- Step2: 通过定时任务轮训扫描将数据转发投递至RocketMQ集群。
- Step3: 消费者进行消费。
为什么同样是数据库RocksDB会比Mysql更加合适呢?因为RocksDB的特性是LSM树,其使用场景适用于大量写入,和消息队列的场景更加契合,所以这个也是滴滴和美团选择其作为延时消息封装的存储介质。
3.2 时间轮+磁盘存储
再说时间轮之前,让我们再次回到我们的实现本地延时的时候使用的ScheduledThreadPoolExecutor还有Timer,他们都是使用的优先级队列完成的,优先级队列本质上也就是堆结构,堆结构的插入的时间复杂度是O(LogN),如果未来我们的内存可以做到无限,我们使用使用优先级队列去做延时消息的存储,但是随着消息的增多,我们的插入消息的效率也会越来越低,那么怎么才能让我们的插入消息的效率不随着消息的增多而变低呢?答案就是时间轮。
什么是时间轮呢?其实我们可以简单的将其看做是一个多维数组。在很多框架中都使用了时间轮来做一些定时的任务,用来替代我们的Timer,比如我之前讲过的有关本地缓存Caffeine一篇文章,在Caffeine中是一个二层时间轮,也就是二维数组,其一维的数据表示较大的时间维度比如,秒,分,时,天等,其二维的数据表示该时间维度较小的时间维度,比如秒内的某个区间段。当定位到一个TimeWhile[i][j]之后,其数据结构其实是一个链表,记录着我们的Node。在Caffeine利用时间轮记录我们在某个时间过期的数据,然后去处理。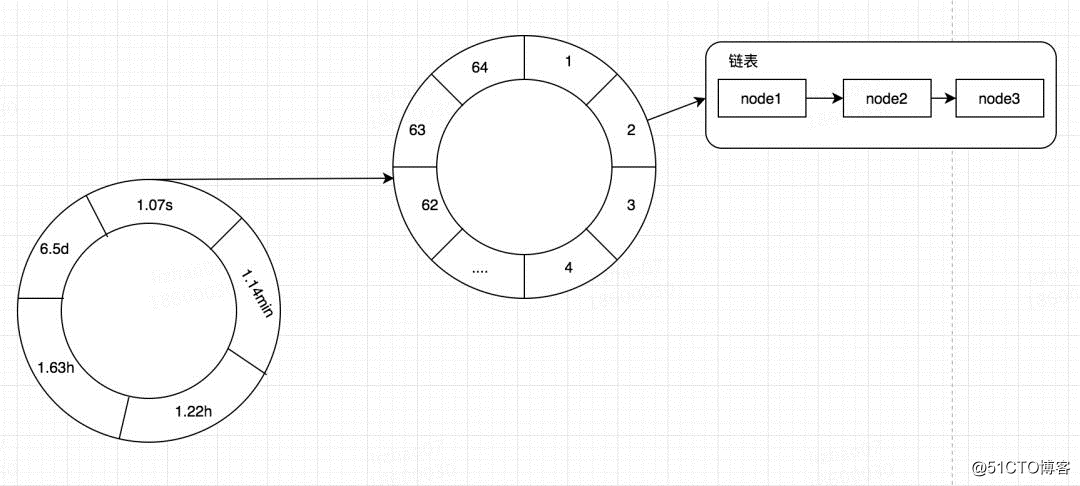
由于时间轮是一个数组的结构,那么其插入复杂度是O(1)。我们解决了效率之后,但是我们的内存依旧不是无限的,我们时间轮如何使用呢?答案当然就是磁盘,在去哪儿开源的QMQ中已经实现了时间轮+磁盘存储,这里为了方便描述我将其转化为RocketMQ中的结构来进行讲解,实现图如下: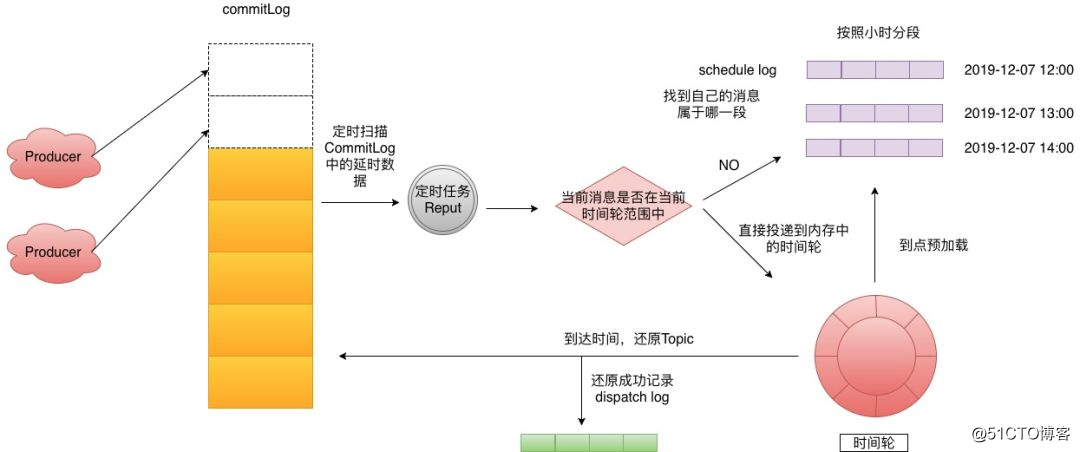
- Step 1: 生产者投递延时消息到CommitLog,这个时候使用了偷换Topic的那招,来达到后面的效果。
- Step 2: 后台有一个Reput的任务定时拉取,延时Topic相关的Message。
- Step 3: 判断这个Message是否在当前时间轮范围中,如果不在则来到Step4,如果在的话就直接将消息投递进入时间轮。
- Step 4: 找到当前消息所属的scheduleLog,然后写入进去,去哪儿默认划分是一个小时为一段,这里可以根据业务自行调整。
- Step 5:时间轮会定时预加载下个时间段的scheduleLog到内存。
- Step 6: 到点的消息会还原topic再次投递到CommitLog,如果投递成功这里会记录dispatchLog。记录的原因是因为时间轮是内存的,你不知道已经执行到哪个位置了,如果执行到最后最后1s钟的时候挂了,这段时间轮之前的所有数据又得重新加载,这里是用来过滤已经投递过的消息。
时间轮+磁盘存储我个人觉得比上面的RocksDB要更加正统一点,不依赖其他的中间件就可以完成,可用性自然也就更高,当然阿里云的RocketMQ具体怎么实现的这个两种方案都有可能。
3.3 redis
在社区中也有很多公司使用的Redis做的延时消息,在Redis中有一个数据结构是Zest,也就是有序集合,他可以实现类似我们的优先级队列的功能,同样的他也是堆结构,所以插入算法复杂度依然是O(logN),但是由于Redis足够快,所以这一块可以忽略。(这块没有做对比的基准测试,只是猜测)。有同学会问,redis不是纯内存的k,v吗,同样的应该也会受到内存限制啊,为什么还会选择他呢?
其实在这个场景中,Redis是很容易水平扩展的当一个Redis内存不够,这里可以使用两个甚至更多,来满足我们的需要,redis延时消息的原理图(原图出自:https://www.cnblogs.com/lylife/p/7881950.html)如下: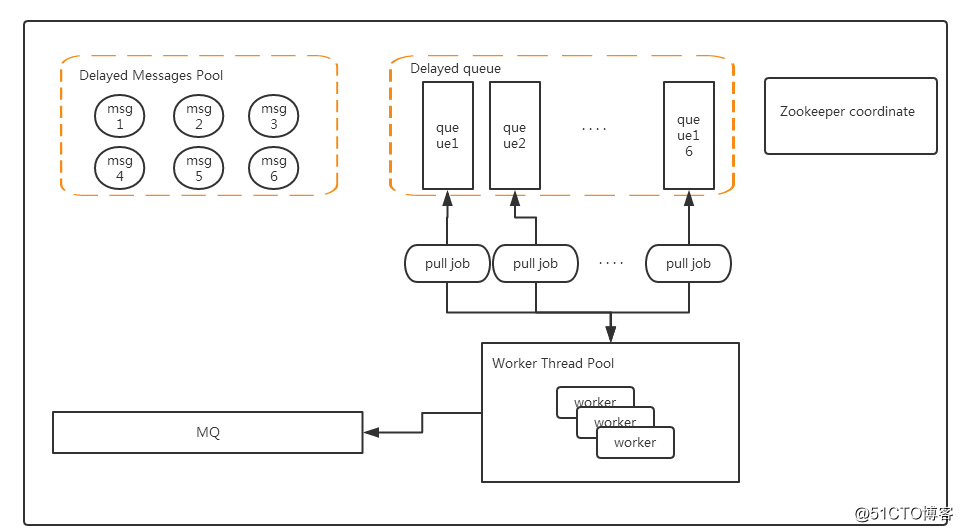
- Delayed Messages Pool: Redis Hash结构,key为消息ID,value为具体的message,当然这里也可以用磁盘或者数据库代替。这里主要存储我们所有消息的内容。
- Delayed Queue: ZSET数据结构,value为消息ID,score为执行时间,这里Delayed Queue可以水平扩展从而增加我们可以支持的数据量。
- Worker Thread Pool: 其中有多个Worker,可以部署在多个机器上形成一个集群,集群中的所有Worker通过ZK进行协调,分配Delayed Queue。
我们怎么才能知道Delayed Queue中的消息到期了呢?这里有两种方法:
- 每个Worker定时扫描,ZSET的最小执行时间,如果到了就取出,这个方法在消息少的时候特别浪费资源,在消息量多的时候,由于轮训不及时导致延时的时间不准确。
- 因为第一个方法问题比较多,所以这里借鉴了Timer中的一些思想,通过wait-notify可以达到一个比较好的延时效果,并且资源也不会浪费,第一次的时候还是获取ZSET中最小的时间,然后wait(执行时间-当前时间),这样就不需要浪费资源到达时间时会自动响应,如果当前ZSET有新的消息进入,并且比我们等待的消息还要小,那么直接notify唤醒,重新获取这个更小的消息,然后又wait,如此循环。
总结
本文介绍了三种方式实现分布式延时消息,希望能在你实现自己的延迟消息的时候提供一点思路。总的来说可能前两种方法来说适用面更加广一点,毕竟在RocketMQ这些大型的消息队列中间件,还有一些其他的集成功能,比如顺序消息,事务消息等,延时消息可能更加倾向于是分布式消息队列中的一个功能,而不是作为一个独立的组件存在。当然其中还有一些细节并没有一一介绍,具体细节可以去参考QMQ和DDMQ的源码。
如果大家觉得这篇文章对你有帮助,你的关注和转发是对我最大的支持,O(∩_∩)O:

以上是关于RocketMq实现延时队列的主要内容,如果未能解决你的问题,请参考以下文章
Spring boot实战项目整合阿里云RocketMQ 消息队列实现发送普通消息,延时消息
Spring boot实战项目整合阿里云RocketMQ 消息队列实现发送普通消息,延时消息