Python爬虫 自动爬取图片并保存
Posted 清忖灬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫 自动爬取图片并保存相关的知识,希望对你有一定的参考价值。
一、准备工作
用python来实现对图片网站的爬取并保存,以情绪图片为例,搜索可得到下图所示
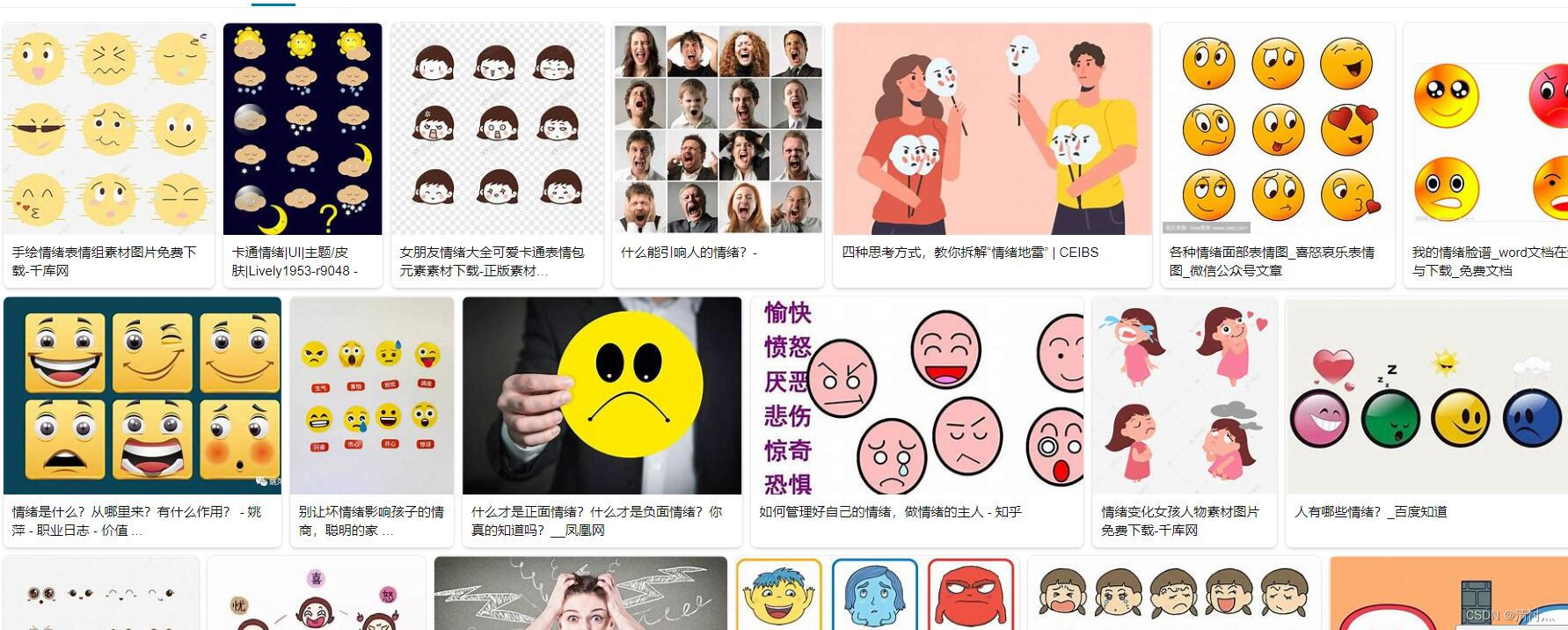
f12打开源码

在此处可以看到这次我们要爬取的图片的基本信息是在img - scr中
二、代码实现
这次的爬取主要用了如下的第三方库
import re
import time
import requests
from bs4 import BeautifulSoup
import os简单构思可以分为三个小部分
1.获取网页内容
2.解析网页
3.保存图片至相应位置
下面来看第一部分:获取网页内容
baseurl = 'https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'
head =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67"
response = requests.get(baseurl, headers=head) # 获取网页信息
html = response.text # 将网页信息转化为text形式是不是so easy
第二部分解析网页才是大头
来看代码
Img = re.compile(r'img.*src="(.*?)"') # 正则表达式匹配图片
soup = BeautifulSoup(html, "html.parser") # BeautifulSoup解析html
#i = 0 # 计数器初始值
data = [] # 存储图片超链接的列表
for item in soup.find_all('img', src=""): # soup.find_all对网页中的img—src进行迭代
item = str(item) # 转换为str类型
Picture = re.findall(Img, item) # 结合re正则表达式和BeautifulSoup, 仅返回超链接
for b in Picture:
data.append(b)
#i = i + 1
return data[-1]
# print(i)这里就运用到了BeautifulSoup以及re正则表达式的相关知识,需要有一定的基础哦
下面就是第三部分:保存图片
for m in getdata(
baseurl='https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'):
resp = requests.get(m) #获取网页信息
byte = resp.content # 转化为content二进制
print(os.getcwd()) # os库中输出当前的路径
i = i + 1 # 递增
# img_path = os.path.join(m)
with open("path.jpg".format(i), "wb") as f: # 文件写入
f.write(byte)
time.sleep(0.5) # 每隔0.5秒下载一张图片放入D://情绪图片测试
print("第张图片爬取成功!".format(i))各行代码的解释已经给大家写在注释中啦,不明白的地方可以直接私信或评论哦~
下面是完整的代码
import re
import time
import requests
from bs4 import BeautifulSoup
import os
# m = 'https://tse2-mm.cn.bing.net/th/id/OIP-C.uihwmxDdgfK4FlCIXx-3jgHaPc?w=115&h=183&c=7&r=0&o=5&pid=1.7'
'''
resp = requests.get(m)
byte = resp.content
print(os.getcwd())
img_path = os.path.join(m)
'''
def main():
baseurl = 'https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'
datalist = getdata(baseurl)
def getdata(baseurl):
Img = re.compile(r'img.*src="(.*?)"') # 正则表达式匹配图片
datalist = []
head =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67"
response = requests.get(baseurl, headers=head) # 获取网页信息
html = response.text # 将网页信息转化为text形式
soup = BeautifulSoup(html, "html.parser") # BeautifulSoup解析html
# i = 0 # 计数器初始值
data = [] # 存储图片超链接的列表
for item in soup.find_all('img', src=""): # soup.find_all对网页中的img—src进行迭代
item = str(item) # 转换为str类型
Picture = re.findall(Img, item) # 结合re正则表达式和BeautifulSoup, 仅返回超链接
for b in Picture: # 遍历列表,取最后一次结果
data.append(b)
# i = i + 1
datalist.append(data[-1])
return datalist # 返回一个包含超链接的新列表
# print(i)
'''
with open("img_path.jpg","wb") as f:
f.write(byte)
'''
if __name__ == '__main__':
os.chdir("D://情绪图片测试")
main()
i = 0 # 图片名递增
for m in getdata(
baseurl='https://cn.bing.com/images/search?q=%E6%83%85%E7%BB%AA%E5%9B%BE%E7%89%87&qpvt=%e6%83%85%e7%bb%aa%e5%9b%be%e7%89%87&form=IGRE&first=1&cw=418&ch=652&tsc=ImageBasicHover'):
resp = requests.get(m) #获取网页信息
byte = resp.content # 转化为content二进制
print(os.getcwd()) # os库中输出当前的路径
i = i + 1 # 递增
# img_path = os.path.join(m)
with open("path.jpg".format(i), "wb") as f: # 文件写入
f.write(byte)
time.sleep(0.5) # 每隔0.5秒下载一张图片放入D://情绪图片测试
print("第张图片爬取成功!".format(i))最后的运行截图
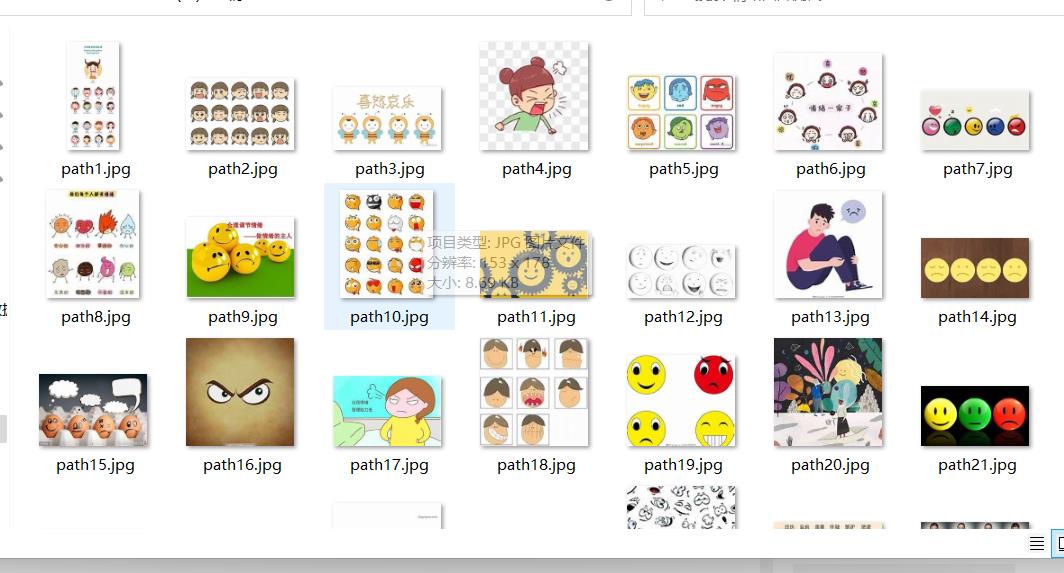
三、总结
这次仅仅是保存了29张图片,在爬取其他网页的时候,用的方法都是大同小异,最主要还是根据网页的内容灵活变换,观察它的源码。另外有部分网站可能会有反爬措施,爬的时候要注意哦~如果还有不懂的地方,欢迎留言私信
Python爬虫爬取目标小说并保存到本地
利用Python爬虫爬取目标小说并保存到本地
小说地址:http://book.zongheng.com/showchapter/749819.html(目录地址)
通过小说目录获取小说所有章节对应的url地址,然后逐个访问解析得到每一章节小说的内容,最后保存到本地文件内
文章中的代码只是第一个版本,可以自行优化
例如:使用IP代理池防止IP地址被封禁
使用多线程对小说章节内容进行爬取可以提高爬取效率,降低运行时间
构建更加详细的requests请求头
代码还有诸多不足,欢迎指导
1 import requests 2 import bs4 3 from bs4 import BeautifulSoup 4 import lxml 5 import urllib 6 7 8 def getMuLu(Html): 9 """ 10 函数getMuLu由主函数传入小说目录网址,经解析后返回每一章节的具体网址 11 涉及内容: 12 requests库:进行网页请求 13 BeautifulSouping库:解析请求返回的网页内容 14 时间:2020-05-15 15 16 环境:Windows + python3.8 17 工具:Pycharm 18 21 22 """ 23 #构建请求头 24 headers = { 25 ‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36‘ 26 } 27 #使用requests中的get方法请求网址并转换为text格式 28 demo = requests.get(Html) 29 demo1 = demo.text 30 31 #使用BeautifulSoup库对text格式的网页内容进行解析 32 soup = BeautifulSoup(demo1, ‘html.parser‘) 33 34 #将soup变量的值中的所有ID为list的标签返回到MuLu在转换为str类型后再次使用BeautifulSoup库进行解析 35 MuLu = soup.find_all(class_ = ‘volume-list‘) 36 soup1 = BeautifulSoup(str(MuLu), ‘html.parser‘) 37 38 #对soup1解析后将所有的a标签进行取出并赋值href1 39 href1 = soup1.find_all(‘li‘) 40 soup2 = BeautifulSoup(str(href1), ‘html.parser‘) 41 href2 = soup2.find_all(‘a‘) 42 43 #将所有a标签取出后,将a标签中href属性的值存储到列表类型的Web3中 44 Web3 = [] 45 for link in href2: 46 Web1 = link.get(‘href‘) 47 Web3.append(Web1) 48 return Web3 49 50 51 def getText(TextUrl): 52 53 """ 54 函数getText由主函数传入小说目录网址,经解析后返回小说目录以及正文 55 涉及内容: 56 requests库:进行网页请求 57 BeautifulSouping库:解析请求返回的网页内容 58 时间:2020-05-15 59 60 """ 61 i = 0 62 Mu = [] 63 for i in range(len(TextUrl)): 64 headers = { 65 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘, 66 ‘Cookie‘: ‘lianjia_uuid=9d3277d3-58e4-440e-bade-5069cb5203a4; ‘ 67 ‘UM_distinctid=16ba37f7160390-05f17711c11c3e-454c0b2b-100200-16ba37f716618b; _smt_uid=5d176c66.5119839a; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22%24device_id%22%3A%2216ba37f7a942a6-0671dfdde0398a-454c0b2b-1049088-16ba37f7a95409%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _ga=GA1.2.1772719071.1561816174; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1561822858; _jzqa=1.2532744094467475000.1561816167.1561822858.1561870561.3; CNZZDATA1253477573=987273979-1561811144-%7C1561865554; CNZZDATA1254525948=879163647-1561815364-%7C1561869382; CNZZDATA1255633284=1986996647-1561812900-%7C1561866923; CNZZDATA1255604082=891570058-1561813905-%7C1561866148; _qzja=1.1577983579.1561816168942.1561822857520.1561870561449.1561870561449.1561870847908.0.0.0.7.3; select_city=110000; lianjia_ssid=4e1fa281-1ebf-e1c1-ac56-32b3ec83f7ca; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMzQ2MDU5ZTQ0OWY4N2RiOTE4NjQ5YmQ0ZGRlMDAyZmFhODZmNjI1ZDQyNWU0OGQ3MjE3Yzk5NzFiYTY4ODM4ZThiZDNhZjliNGU4ODM4M2M3ODZhNDNiNjM1NzMzNjQ4ODY3MWVhMWFmNzFjMDVmMDY4NWMyMTM3MjIxYjBmYzhkYWE1MzIyNzFlOGMyOWFiYmQwZjBjYjcyNmIwOWEwYTNlMTY2MDI1NjkyOTBkNjQ1ZDkwNGM5ZDhkYTIyODU0ZmQzZjhjODhlNGQ1NGRkZTA0ZTBlZDFiNmIxOTE2YmU1NTIxNzhhMGQ3Yzk0ZjQ4NDBlZWI0YjlhYzFiYmJlZjJlNDQ5MDdlNzcxMzAwMmM1ODBlZDJkNmIwZmY0NDAwYmQxNjNjZDlhNmJkNDk3NGMzOTQxNTdkYjZlMjJkYjAxYjIzNjdmYzhiNzMxZDA1MGJlNjBmNzQxMTZjNDIzNFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCIzMGJlNDJiN1wifSIsInIiOiJodHRwczovL2JqLmxpYW5qaWEuY29tL3p1ZmFuZy9yY28zMS8iLCJvcyI6IndlYiIsInYiOiIwLjEifQ==‘ 68 } 69 70 QingQiu = urllib.request.urlopen(TextUrl[i]).read() 71 date = QingQiu.decode(‘utf-8‘) 72 73 SoupText = BeautifulSoup(date,‘html.parser‘) 74 #通过解析SoupText获取章节名称 75 MingCheng = SoupText.find_all(class_ = ‘title_txtbox‘) 76 MingCheng1 = BeautifulSoup(str(MingCheng),‘lxml‘) 77 MingCheng2 = MingCheng1.get_text() 78 ls4 = ‘‘.join(MingCheng2) 79 80 #通过解析SoupText获取章节正文 81 BiaoTi = SoupText.find_all(class_ = ‘content‘) #在全部的html中查找class_ = ‘content‘的div标签 82 83 BiaoTi1 = BeautifulSoup(str(BiaoTi), ‘lxml‘) 84 BiaoTi2 = BiaoTi1.find_all(‘p‘) #获取p标签 85 86 #通过遍历p标签获取正文内容 87 qbs = 0 88 KongList = [] 89 for qbs in range(len(BiaoTi2)): 90 ZhangJie = BiaoTi2[qbs] 91 S = BeautifulSoup(str(ZhangJie), ‘html.parser‘) 92 str1 = S.get_text() 93 KongList.append(str1) 94 qbs += 1 95 96 #将列表转换为字符串类型 97 ls3 = ‘‘.join(KongList) 98 #通过组合返回章节名称以及正文内容 99 100 #将两个字符串类型数据组合为一个并返回 101 NeiRong = ls4 + ls3 102 103 104 #将所有内容写入列表Mu并返回 105 Mu.append(NeiRong) 106 107 return Mu 108 109 def BaoCunText(WenBen): 110 """ 111 函数BaoCunText由主函数传入小说目录以及内容,写入txt文件 112 涉及内容: 113 文件处理: 114 打开,写入,关闭文件 115 for遍历 116 时间:2020-05-16 117 """ 118 #打开文件 119 FlieText = open(‘MiMiShiMing.txt‘,‘a‘,encoding=‘utf-8‘) 120 #遍历列表WenBen,并利用索引写入文件,在每章节后换行 121 i = 0 122 for i in range(len(WenBen)): 123 FlieText.write(str(WenBen[i])) 124 FlieText.write(‘ ‘) 125 print("第{}章写入成功".format(i)) 126 i += 1 127 print("写入完成") 128 #关闭文件 129 FlieText.close() 130 131 if __name__ == ‘__main__‘: 132 """ 133 主函数:调用其他函数以及向函数传值 134 135 时间:2020-5-17 136 137 138 """ 139 140 url = ‘http://book.zongheng.com/showchapter/749819.html‘ 141 MuLuLianjie = getMuLu(url) 142 XiaoShuo = getText(MuLuLianjie) 143 BaoCunText(XiaoShuo)
以上是关于Python爬虫 自动爬取图片并保存的主要内容,如果未能解决你的问题,请参考以下文章