1、前言
一直在从事linux下后台开发,经常与core文件打交道。还记得刚开始从事linux下开发时,程序突然崩溃了,也没有任何日志。我不知所措,同事叫我看看core,我却问什么是core,怎么看。同事鄙视的眼神,我依然在目。后来学会了从core文件中分析原因,通过gdb看出程序挂再哪里,分析前后的变量,找出问题的原因。当时就觉得很神奇,core文件是怎么产生的呢?难道系统会自动产生,可是我在自己的linux系统上面写个非法程序测试,并没有产生core问题?这又是怎么回事呢?今天在ngnix的源码时候,发现可以在程序中设置core dump,又是怎么回事呢?在公司发现生成的core文件都带有进程名称、进程ID、和时间,这又是怎么做到的呢?今天带着这些疑问来说说core文件是如何生成,如何配置。
2、基本概念
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”)。我们可以认为 core dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时 dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。core dump 对于编程人员诊断和调试程序是非常有帮助的,因为对于有些程序错误是很难重现的,例如指针异常,而 core dump 文件可以再现程序出错时的情景。
3、开启core dump
可以使用命令ulimit开启,也可以在程序中通过setrlimit系统调用开启。
程序中开启core dump,通过如下API可以查看和设置RLIMIT_CORE
#include <sys/resource.h>
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
参考程序如下所示:
#include <unistd.h>
#include <sys/time.h>
#include <sys/resource.h>
#include <stdio.h>
#define CORE_SIZE 1024 * 1024 * 500
int main()
{
struct rlimit rlmt;
if (getrlimit(RLIMIT_CORE, &rlmt) == -1) {
return -1;
}
printf("Before set rlimit CORE dump current is:%d, max is:%d\\n", (int)rlmt.rlim_cur, (int)rlmt.rlim_max);
rlmt.rlim_cur = (rlim_t)CORE_SIZE;
rlmt.rlim_max = (rlim_t)CORE_SIZE;
if (setrlimit(RLIMIT_CORE, &rlmt) == -1) {
return -1;
}
if (getrlimit(RLIMIT_CORE, &rlmt) == -1) {
return -1;
}
printf("After set rlimit CORE dump current is:%d, max is:%d\\n", (int)rlmt.rlim_cur, (int)rlmt.rlim_max);
/*测试非法内存,产生core文件*/
int *ptr = NULL;
*ptr = 10;
return 0;
}
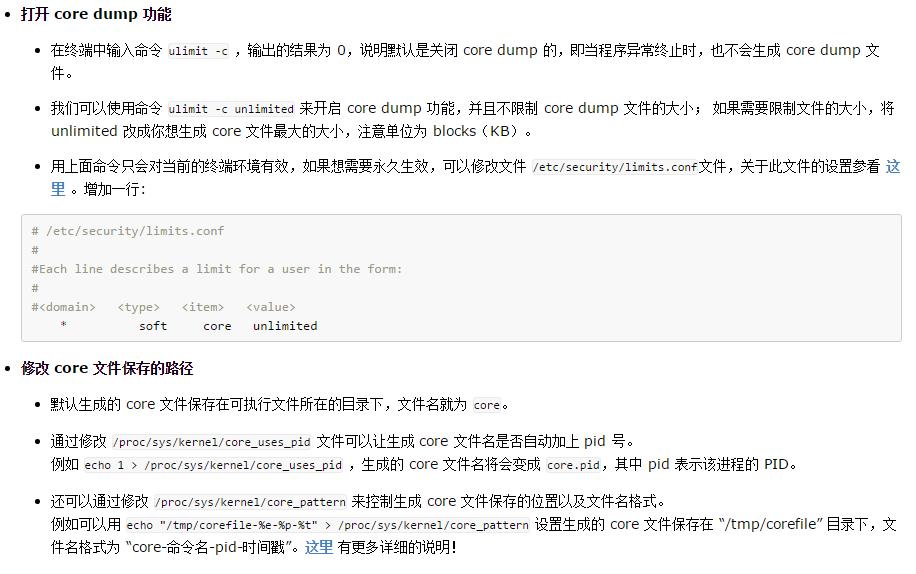
执行./main, 生成的core文件如下所示
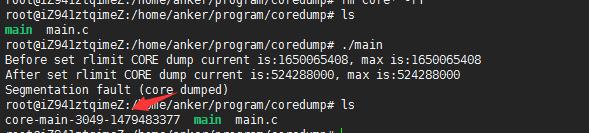
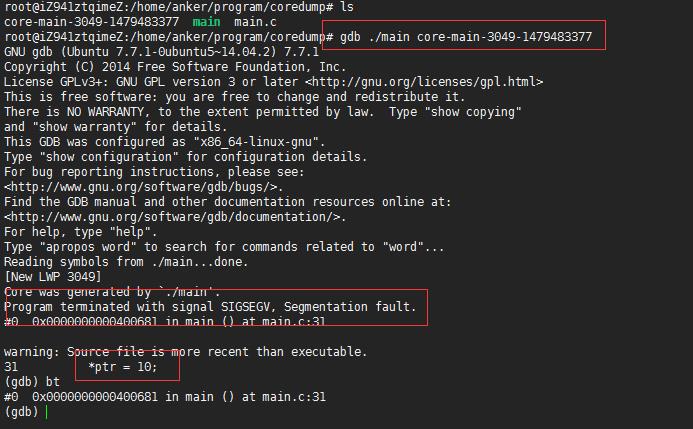
GDB调试core文件,查看程序挂在位置。当core dump 之后,使用命令 gdb program core 来查看 core 文件,其中 program 为可执行程序名,core 为生成的 core 文件名。
4、参考资料
http://www.cnblogs.com/hazir/p/linxu_core_dump.html
http://www.cnblogs.com/niocai/archive/2012/04/01/2428128.html
http://baidutech.blog.51cto.com/4114344/904419/
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”)。我们可以认为 core dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时 dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。core dump 对于编程人员诊断和调试程序是非常有帮助的,因为对于有些程序错误是很难重现的,例如指针异常,而 core dump 文件可以再现程序出错时的情景。
Core Dump 名词解释
在半导体作为电脑内存材料之前,电脑内存使用的是 磁芯内存(Magnetic Core Memory),Core Dump 中的 Core 沿用了磁芯内存的 Core 表达。图为磁芯内存的一个单元,来自 Wikipedia.

在 APUE 一书中作者有句话这样写的:
Because the file is named core, it shows how long this feature has been part of the Unix System.
这里的 core 就是沿用的是早期电脑磁芯内存中的表达,也能看出 Unix 系统 Core Dump 机制的悠久历史。
Dump 指的是拷贝一种存储介质中的部分内容到另一个存储介质,或者将内容打印、显示或者其它输出设备。dump 出来的内容是格式化的,可以使用一些工具来解析它。
现代操作系统中,用 Core Dump 表示当程序异常终止或崩溃时,将进程此时的内存中的内容拷贝到磁盘文件中存储,以方便编程人员调试。
Core Dump 如何产生
上面说当程序运行过程中异常终止或崩溃时会发生 core dump,但还没说到什么具体的情景程序会发生异常终止或崩溃,例如我们使用 kill -9 命令杀死一个进程会发生 core dump 吗?实验证明是不能的,那么什么情况会产生呢?
Linux 中信号是一种异步事件处理的机制,每种信号对应有其默认的操作,你可以在 这里 查看 Linux 系统提供的信号以及默认处理。默认操作主要包括忽略该信号(Ingore)、暂停进程(Stop)、终止进程(Terminate)、终止并发生core dump(core)等。如果我们信号均是采用默认操作,那么,以下列出几种信号,它们在发生时会产生 core dump:
| Signal | Action | Comment |
|---|
| SIGQUIT |
Core |
Quit from keyboard |
| SIGILL |
Core |
Illegal Instruction |
| SIGABRT |
Core |
Abort signal from abort |
| SIGSEGV |
Core |
Invalid memory reference |
| SIGTRAP |
Core |
Trace/breakpoint trap |
当然不仅限于上面的几种信号。这就是为什么我们使用 Ctrl+z 来挂起一个进程或者 Ctrl+C 结束一个进程均不会产生 core dump,因为前者会向进程发出 SIGTSTP 信号,该信号的默认操作为暂停进程(Stop Process);后者会向进程发出SIGINT 信号,该信号默认操作为终止进程(Terminate Process)。同样上面提到的 kill -9 命令会发出 SIGKILL 命令,该命令默认为终止进程。而如果我们使用 Ctrl+\\ 来终止一个进程,会向进程发出 SIGQUIT 信号,默认是会产生 core dump 的。还有其它情景会产生 core dump, 如:程序调用 abort() 函数、访存错误、非法指令等等。
下面举两个例子来说明:
-
终端下比较 Ctrl+C 和 Ctrl+\\:
guohailin@guohailin:~$ sleep 10 #使用sleep命令休眠 10 s
^C #使用 Ctrl+C 终止该程序,不会产生 core dump
guohailin@guohailin:~$ sleep 10
^\\Quit (core dumped) #使用 Ctrl+\\ 退出程序, 会产生 core dump
guohailin@guohailin:~$ ls #多出下面一个 core 文件
-rw------- 1 guohailin guohailin 335872 10月 22 11:31 sleep.core.21990
-
小程序产生 core dump
#include <stdio.h>
int main()
{
int *null_ptr = NULL;
*null_ptr = 10; //对空指针指向的内存区域写,会发生段错误
return 0;
}
#编译执行
guohailin@guohailin:~$ ./a.out
Segmentation fault (core dumped)
guohailin@guohailin:~$ ls #多出下面一个 core 文件
-rw------- 1 guohailin guohailin 200704 10月 22 11:35 a.out.core.22070
Linux 下打开 Core Dump
我使用的 Linux 发行版是 Ubuntu 13.04,设置生成 core dump 文件的方法如下:
-
打开 core dump 功能
- 在终端中输入命令
ulimit -c ,输出的结果为 0,说明默认是关闭 core dump 的,即当程序异常终止时,也不会生成 core dump 文件。
- 我们可以使用命令
ulimit -c unlimited 来开启 core dump 功能,并且不限制 core dump 文件的大小; 如果需要限制文件的大小,将 unlimited 改成你想生成 core 文件最大的大小,注意单位为 blocks(KB)。
- 用上面命令只会对当前的终端环境有效,如果想需要永久生效,可以修改文件
/etc/security/limits.conf文件,关于此文件的设置参看 这里 。增加一行:
# /etc/security/limits.conf
#
#Each line describes a limit for a user in the form:
#
#<domain> <type> <item> <value>
* soft core unlimited
-
修改 core 文件保存的路径
- 默认生成的 core 文件保存在可执行文件所在的目录下,文件名就为
core。
- 通过修改
/proc/sys/kernel/core_uses_pid 文件可以让生成 core 文件名是否自动加上 pid 号。
例如 echo 1 > /proc/sys/kernel/core_uses_pid ,生成的 core 文件名将会变成 core.pid,其中 pid 表示该进程的 PID。
- 还可以通过修改
/proc/sys/kernel/core_pattern 来控制生成 core 文件保存的位置以及文件名格式。
例如可以用 echo "/tmp/corefile-%e-%p-%t" > /proc/sys/kernel/core_pattern 设置生成的 core 文件保存在 “/tmp/corefile” 目录下,文件名格式为 “core-命令名-pid-时间戳”。这里 有更多详细的说明!
使用 gdb 调试 Core 文件
产生了 core 文件,我们该如何使用该 Core 文件进行调试呢?Linux 中可以使用 GDB 来调试 core 文件,步骤如下:
- 首先,使用 gcc 编译源文件,加上
-g 以增加调试信息;
- 按照上面打开 core dump 以使程序异常终止时能生成 core 文件;
- 运行程序,当core dump 之后,使用命令
gdb program core 来查看 core 文件,其中 program 为可执行程序名,core 为生成的 core 文件名。
下面用一个简单的例子来说明:
#include <stdio.h>
int func(int *p)
{
int y = *p;
return y;
}
int main()
{
int *p = NULL;
return func(p);
}
编译加上调试信息, 运行之后core dump, 使用 gdb 查看 core 文件.
guohailin@guohailin:~$ gcc core_demo.c -o core_demo -g
guohailin@guohailin:~$ ./core_demo
Segmentation fault (core dumped)
guohailin@guohailin:~$ gdb core_demo core_demo.core.24816
...
Core was generated by \'./core_demo\'.
Program terminated with signal 11, Segmentation fault.
#0 0x080483cd in func (p=0x0) at core_demo.c:5
5 int y = *p;
(gdb) where
#0 0x080483cd in func (p=0x0) at core_demo.c:5
#1 0x080483ef in main () at core_demo.c:12
(gdb) info frame
Stack level 0, frame at 0xffd590a4:
eip = 0x80483cd in func (core_demo.c:5); saved eip 0x80483ef
called by frame at 0xffd590c0
source language c.
Arglist at 0xffd5909c, args: p=0x0
Locals at 0xffd5909c, Previous frame\'s sp is 0xffd590a4
Saved registers:
ebp at 0xffd5909c, eip at 0xffd590a0
(gdb)
从上面可以看出,我们可以还原 core_demo 执行时的场景,并使用 where 可以查看当前程序调用函数栈帧, 还可以使用 gdb 中的命令查看寄存器,变量等信息.
参考资料
功能描述:
获取或设定资源使用限制。每种资源都有相关的软硬限制,软限制是内核强加给相应资源的限制值,硬限制是软限制的最大值。非授权调用进程只可以将其软限制指定为0~硬限制范围中的某个值,同时能不可逆转地降低其硬限制。授权进程可以任意改变其软硬限制。RLIM_INFINITY的值表示不对资源限制。
用法:
#include <sys/resource.h>
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
参数:
resource:可能的选择有
RLIMIT_AS //进程的最大虚内存空间,字节为单位。
RLIMIT_CORE //内核转存文件的最大长度。
RLIMIT_CPU //最大允许的CPU使用时间,秒为单位。当进程达到软限制,内核将给其发送SIGXCPU信号,这一信号的默认行为是终止进程的执行。然而,可以捕捉信号,处理句柄可将控制返回给主程序。如果进程继续耗费CPU时间,核心会以每秒一次的频率给其发送SIGXCPU信号,直到达到硬限制,那时将给进程发送 SIGKILL信号终止其执行。
RLIMIT_DATA //进程数据段的最大值。
RLIMIT_FSIZE //进程可建立的文件的最大长度。如果进程试图超出这一限制时,核心会给其发送SIGXFSZ信号,默认情况下将终止进程的执行。
RLIMIT_LOCKS //进程可建立的锁和租赁的最大值。
RLIMIT_MEMLOCK //进程可锁定在内存中的最大数据量,字节为单位。
RLIMIT_MSGQUEUE //进程可为POSIX消息队列分配的最大字节数。
RLIMIT_NICE //进程可通过setpriority() 或 nice()调用设置的最大完美值。
RLIMIT_NOFILE //指定比进程可打开的最大文件描述词大一的值,超出此值,将会产生EMFILE错误。
RLIMIT_NPROC //用户可拥有的最大进程数。
RLIMIT_RTPRIO //进程可通过sched_setscheduler 和 sched_setparam设置的最大实时优先级。
RLIMIT_SIGPENDING //用户可拥有的最大挂起信号数。
RLIMIT_STACK //最大的进程堆栈,以字节为单位。
rlim:描述资源软硬限制的结构体,原型如下
struct rlimit {
rlim_t rlim_cur;
rlim_t rlim_max;
};
返回说明:
成功执行时,返回0。失败返回-1,errno被设为以下的某个值
EFAULT:rlim指针指向的空间不可访问
EINVAL:参数无效
EPERM:增加资源限制值时,权能不允许
延伸阅读:
ulimit和setrlimit轻松修改task进程资源上限值
在linux系统中,Resouce limit指在一个进程的执行过程中,它所能得到的资源的限制,比如进程的core file的最大值,虚拟内存的最大值等。
Resouce limit的大小可以直接影响进程的执行状况。其有两个最重要的概念:soft limit 和 hard limit。
struct rlimit {
rlim_t rlim_cur; //soft limit
rlim_t rlim_max; //hard limit
};
soft limit是指内核所能支持的资源上限。比如对于RLIMIT_NOFILE(一个进程能打开的最大文件数,内核默认是1024),soft limit最大也只能达到1024。对于RLIMIT_CORE(core文件的大小,内核不做限制),soft limit最大能是unlimited。
hard limit在资源中只是作为soft limit的上限。当你设置hard
limit后,你以后设置的soft limit只能小于hard limit。要说明的是,hard
limit只针对非特权进程,也就是进程的有效用户ID(effective user
ID)不是0的进程。具有特权级别的进程(具有属性CAP_SYS_RESOURCE),soft limit则只有内核上限。
我们可以来看一下下面两条命令的输出。
sishen@sishen:~$ ulimit -c -n -s
core file size (blocks, -c) 0
open files (-n) 1024
stack size (kbytes, -s) 8192
sishen@sishen:~$ ulimit -c -n -s -H
core file size (blocks, -c) unlimited
open files (-n) 1024
stack size (kbytes, -s) unlimited
-H表示显示的是hard limit。从结果上可以看出soft limit和hard limit的区别。unlimited表示no limit, 即内核的最大值。
对于resouce limit的读取修改,有两种方法。
* 使用shell内建命令ulimit
* 使用getrlimit和setrlimit API
ulimit是改变shell的resouce limit,并达到改变shell启动的进程的resouce limit效果(子进程继承)。
usage:ulimit [-SHacdefilmnpqrstuvx [limit]]
当不指定limit的时候,该命令显示当前值。这里要注意的是,当你要修改limit的时候,如果不指定-S或者-H,默认是同时设置soft limit和hard limit。也就是之后设置时只能减不能增。所以,建议使用ulimit设置limit参数是加上-S。
getrlimit和setrlimit的使用也很简单,manpage里有很清楚的描述。
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
需要注意的是你在setrlimit,需要检查是否成功来判断新值有没有超过hard limit。如下例Linux系统中在应用程序运行过程中经常会遇到程序突然崩溃,提示:Segmentation fault,这是因为应用程序收到了SIGSEGV信号。这个信号提示当进程发生了无效的存储访问,当接收到这个信号时,缺省动作是:终止w/core。终止w/core的含义是:在进程当前目录生成core文件,并将进程的内存映象复制到core文件中,core文件的默认名称就是“core”(这是 Unix类系统的一个由来已久的功能)。
事实上,并不是只有SIGSEGV信号产生coredump,还有下面一些信号也产生coredump:SIGABRT(异常终止)、SIGBUS(硬件故障)、SIGEMT(硬件故障)、SIGFPE(算术异常)、SIGILL(非法硬件指令)、SIGIOT(硬件故障),SIGQUIT,SIGSYS(无效系统调用),SIGTRAP(硬件故障)等。Linux系统中在应用程序运行过程中经常会遇到程序突然崩溃,提示:Segmentation
fault,这是因为应用程序收到了SIGSEGV信号。这个信号提示当进程发生了无效的存储访问,当接收到这个信号时,缺省动作是:终止w/core。终止w/core的含义是:在进程当前目录生成core文件,并将进程的内存映象复制到core文件中,core文件的默认名称就是“core”(这是
Unix类系统的一个由来已久的功能)。
事实上,并不是只有SIGSEGV信号产生coredump,还有下面一些信号也产生coredump:SIGABRT(异常终止)、SIGBUS(硬件故障)、SIGEMT(硬件故障)、SIGFPE(算术异常)、SIGILL(非法硬件指令)、SIGIOT(硬件故障),SIGQUIT,SIGSYS(无效系统调用),SIGTRAP(硬件故障)等。对于resouce
limit的读取修改,有两种方法。
* 使用shell内建命令ulimit
* 使用getrlimit和setrlimit APIsetrlimit:
if (getrlimit(RLIMIT_CORE, &rlim)==0) {
rlim_new.rlim_cur = rlim_new.rlim_max = RLIM_INFINITY;
if (setrlimit(RLIMIT_CORE, &rlim_new)!=0) {
rlim_new.rlim_cur = rlim_new.rlim_max = rlim.rlim_max;
(void) setrlimit(RLIMIT_CORE, &rlim_new);
}
}
Linux上Core Dump文件的形成和分析
Core,又称之为Core Dump文件,是Unix/Linux操作系统的一种机制,对于线上服务而言,Core令人闻之色变,因为出Core的过程意味着服务暂时不能正常响应,需要恢复,并且随着吐Core进程的内存空间越大,此过程可能持续很长一段时间(例如当进程占用60G+以上内存时,完整Core文件需要15分钟才能完全写到磁盘上),这期间产生的流量损失,不可估量。
凡事皆有两面性,OS在出Core的同时,虽然会终止掉当前进程,但是也会保留下第一手的现场数据,OS仿佛是一架被按下快门的相机,而照片就是产出的Core文件。里面含有当进程被终止时内存、CPU寄存器等信息,可以供后续开发人员进行调试。
关于Core产生的原因很多,比如过去一些Unix的版本不支持现代Linux上这种GDB直接附着到进程上进行调试的机制,需要先向进程发送终止信号,然后用工具阅读core文件。在Linux上,我们就可以使用kill向一个指定的进程发送信号或者使用gcore命令来使其主动出Core并退出。如果从浅层次的原因上来讲,出Core意味着当前进程存在BUG,需要程序员修复。从深层次的原因上讲,是当前进程触犯了某些OS层级的保护机制,逼迫OS向当前进程发送诸如SIGSEGV(即signal 11)之类的信号, 例如访问空指针或数组越界出Core,实际上是触犯了OS的内存管理,访问了非当前进程的内存空间,OS需要通过出Core来进行警示,这就好像一个人身体内存在病毒,免疫系统就会通过发热来警示,并导致人体发烧是一个道理(有意思的是,并不是每次数组越界都会出Core,这和OS的内存管理中虚拟页面分配大小和边界有关,即使不出Core,也很有可能读到脏数据,引起后续程序行为紊乱,这是一种很难追查的BUG)。
说了这些,似乎感觉Core很强势,让人感觉缺乏控制力,其实不然。控制Core产生的行为和方式,有两个途径:
1.修改/proc/sys/kernel/core_pattern文件,此文件用于控制Core文件产生的文件名,默认情况下,此文件内容只有一行内容:“core”,此文件支持定制,一般使用%配合不同的字符,这里罗列几种:
%p 出Core进程的PID
%u 出Core进程的UID
%s 造成Core的signal号
%t 出Core的时间,从1970-01-0100:00:00开始的秒数
%e 出Core进程对应的可执行文件名
2.Ulimit –C命令,此命令可以显示当前OS对于Core文件大小的限制,如果为0,则表示不允许产生Core文件。如果想进行修改,可以使用:
Ulimit –cn
其中n为数字,表示允许Core文件体积的最大值,单位为Kb,如果想设为无限大,可以执行:
Ulimit -cunlimited
产生了Core文件之后,就是如何查看Core文件,并确定问题所在,进行修复。为此,我们不妨先来看看Core文件的格式,多了解一些Core文件。
首先可以明确一点,Core文件的格式ELF格式,这一点可以通过使用readelf -h命令来证实,如下图:

从读出来的ELF头信息可以看到,此文件类型为Core文件,那么readelf是如何得知的呢?可以从下面的数据结构中窥得一二:

其中当值为4的时候,表示当前文件为Core文件。如此,整个过程就很清楚了。
了解了这些之后,我们来看看如何阅读Core文件,并从中追查BUG。在Linux下,一般读取Core的命令为:
gdb exec_file core_file
使用GDB,先从可执行文件中读取符号表信息,然后读取Core文件。如果不与可执行文件搅合在一起可以吗?答案是不行,因为Core文件中没有符号表信息,无法进行调试,可以使用如下命令来验证:
Objdump –x core_file | tail
我们看到如下两行信息:
SYMBOL TABLE:
no symbols
表明当前的ELF格式文件中没有符号表信息。
为了解释如何看Core中信息,我们来举一个简单的例子:
#include “stdio.h”
int main(){
int stack_of[100000000];
int b=1;
int* a;
*a=b;
}
这段程序使用gcc –g a.c –o a进行编译,运行后直接会Core掉,使用gdb a core_file查看栈信息,可见其Core在了这行代码:
int stack_of[100000000];
原因很明显,直接在栈上申请如此大的数组,导致栈空间溢出,触犯了OS对于栈空间大小的限制,所以出Core(这里是否出Core还和OS对栈空间的大小配置有关,一般为8M)。但是这里要明确一点,真正出Core的代码不是分配栈空间的int stack_of[100000000], 而是后面这句int b=1, 为何?出Core的一种原因是因为对内存的非法访问,在上面的代码中分配数组stack_of时并未访问它,但是在其后声明变量并赋值,就相当于进行了越界访问,继而出Core。为了解释得更详细些,让我们使用gdb来看一下出Core的地方,使用命令gdb a core_file可见:

可知程序出现了段错误“Segmentation fault”, 代码是int b=1这句。我们来查看一下当前的栈信息:

其中可见指令指针rip指向地址为0×400473, 我们来看下当前的指令是什么:

这条movl指令要把立即数1送到0xffffffffe8287bfc(%rbp)这个地址去,其中rbp存储的是帧指针,而0xffffffffe8287bfc很明显是一个负数,结果计算为-400000004。这就可以解释了:其中我们申请的int stack_of[100000000]占用400000000字节,b是int类型,占用4个字节,且栈空间是由高地址向低地址延伸,那么b的栈地址就是0xffffffffe8287bfc(%rbp),也就是$rbp-400000004。当我们尝试访问此地址时:

可以看到无法访问此内存地址,这是因为它已经超过了OS允许的范围。
下面我们把程序进行改进:
#include “stdio.h”
int main(){
int* stack_of = malloc(sizeof(int)*100000000);
int b=1;
int* a;
*a=b;
}
使用gcc –O3 –g a.c –o a进行编译,运行后会再次Core掉,使用gdb查看栈信息,请见下图:

可见BUG出在第7行,也就是*a=b这句,这时我们尝试打印b的值,却发现符号表中找不到b的信息。为何?原因在于gcc使用了-O3参数,此参数可以对程序进行优化,一个负面效应是优化过程中会舍弃部分局部变量,导致调试时出现困难。在我们的代码中,b声明时即赋值,随后用于为*a赋值。优化后,此变量不再需要,直接为*a赋值为1即可,如果汇编级代码上讲,此优化可以减少一条MOV语句,节省一个寄存器。
此时我们的调试信息已经出现了一些扭曲,为此我们重新编译源程序,去掉-O3参数(这就解释了为何一些大型软件都会有debug版本存在,因为debug是未经优化的版本,包含了完整的符号表信息,易于调试),并重新运行,得到新的core并查看,如下图:

这次就比较明显了,b中的值没有问题,有问题的是a,其指向的地址是非法区域,也就是a没有分配内存导致的Core。当然,本例中的问题其实非常明显,几乎一眼就能看出来,但不妨碍它成为一个例子,用来解释在看Core过程中,需要注意的一些问题。
