使用Web Scraper 插件,不需要编程,也能爬网,使用Web Scraper插件,能够创建一个网站地图,并能遍历网站,抓取我们感兴趣的数据,比如,我们登陆淘宝,京东等商务网站,我们可以通过 Web Scraper,抓取某一类商品的规格说明,价格,厂家等信息,我们通过Web Scraper可以抓取我们进入头条上的最热门的文章,也可以抓取我们自己的所有文章列表,发布时间,阅读和浏览量等信息,当然也能抓取我们的粉丝列表。 最最最重要的是,你不需要写任何的代码,只需点击,点击,点击,最后还能把抓取的结果导出为Excel可以识别的CSV格式。这功能,爽!!!
其官方网站如下:http://webscraper.io/tutorials
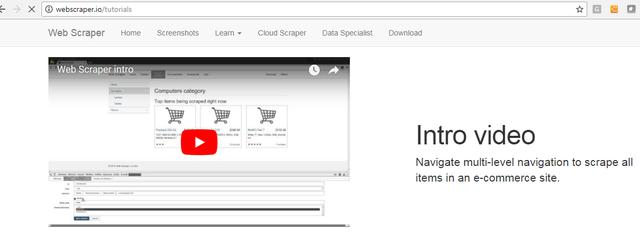
Web Scraper Chrome 插件的安装
打开Chrome浏览器,输入下面的URL地址:
https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn
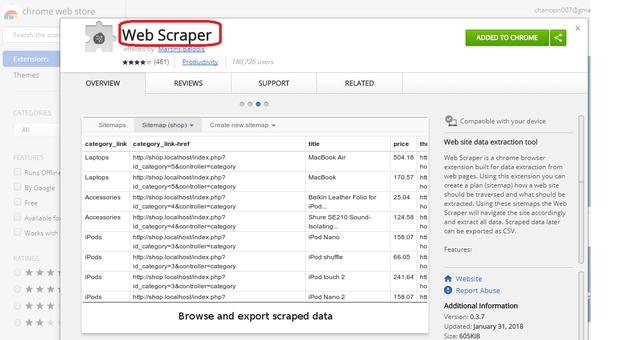
点击“Added to Chrome”就安装了,安装后,在浏览器中按下F12或者点击右键,选择“检查(Inspect)”,在开发者工具下面就能看到WebScraper的Tab。
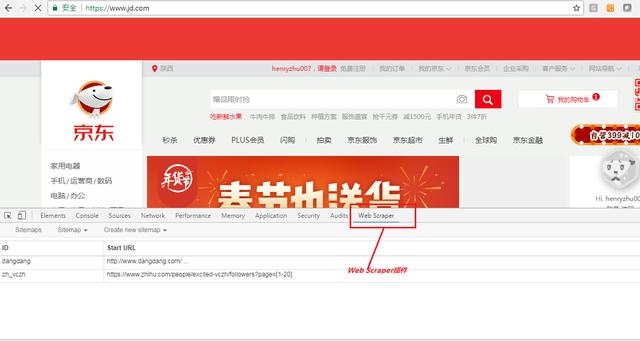
Web Scraper Chrome 插件的入门例子
下面以抓取京东上面的所有的手机信息为例子,使用Web Scraper演示一下其使用和操作方法。
Step1. 创建一个京东手机的SiteMap(网站站点图)
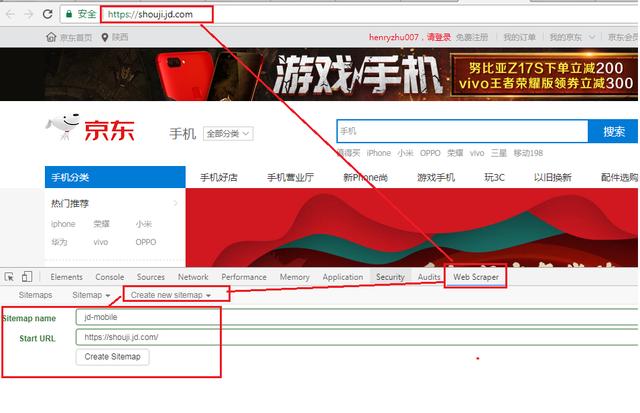
Step2. 在SiteMap上点击选择需要抓取的信息
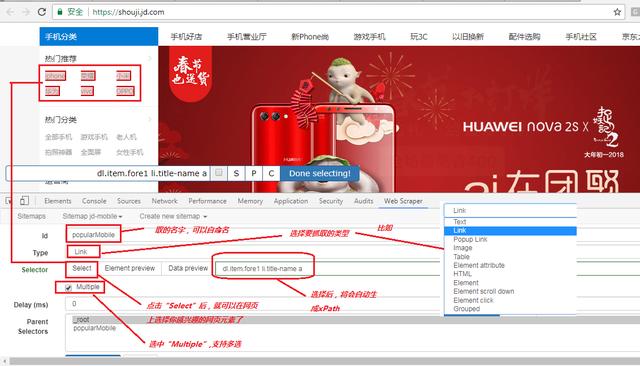
如下图所示意,想抓取当前京东上,热门推荐的手机的网站和品牌信息,则抓取方法如下:命名一个id,这个id是自己定义的,然后选择抓取的类型,比如本例子中我们选择,“Link”
-
Link
-
PopupLink
-
Table
-
Element Attribute
-
Image
-
Groupped
-
Element
-
Element Click
-
Element Scroll down
然后选择你感兴趣元素,比如我选择了iPhone,荣耀,小米,华为,Vivo,Oppo,其会自动生成一个获取这些信息数据的表达式,我们可以称呼其为XPath,最后,点击保存。
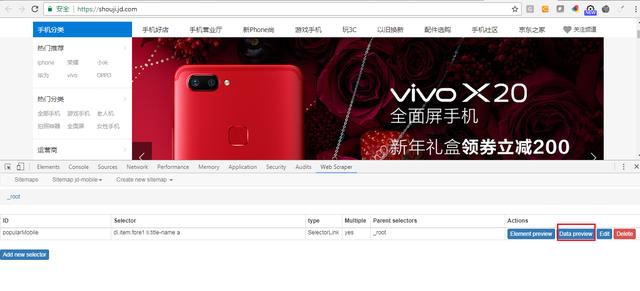
Step3. 保存后,点击“Data Preview”预览数据。
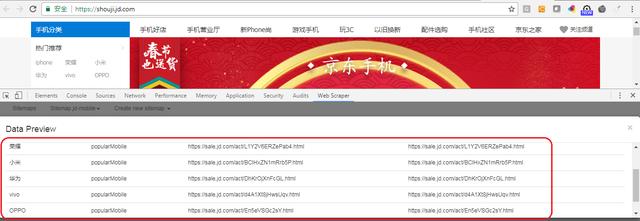
Step4. 点击“Data Preview”预览的数据如下。
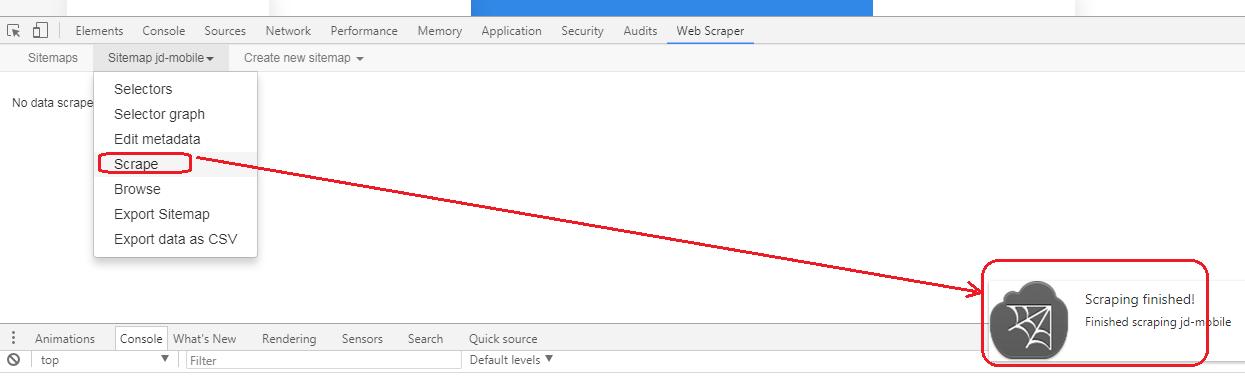
Step5. 点击“Scrape”,立马开始抓取数据。
当出现“Scraping Finished”的字样的时候,说明已经抓取成功。
Step6. 点击“Export Data as CSV”,导出为CVS的数据格式,这样Excel就能打开

写在最后的话
本文简单介绍总结了Web Scraper的插件的功能,安装以及一个简单的单页面例子。其实Web Scraper的功能远远不止于此,其实还能抓取分页,还能多页多元素的抓取,还能抓取二级页面,比如,所有iphone或者华为手机的价格,配置等信息