世界悲结束了,章鱼哥也退役了,连非诚勿扰中的拜金女也突然的少了很多。这本《Linux内核修炼之道》在卓越、当当、china-pub上也已经开卖了,虽然是严肃文学,但为了保证流畅性,大部分文字我还都是斟词灼句,反复的念几遍才写上去的,尽量考虑到写上去的每段话能够让读者产生什么疑惑,然后也都会紧接着尽量的去进行解释清楚,中间的很多概念也有反复纠结过怎么解释能够更容易的理解,力求即使对于初学者也可以有很少阻碍的一气读完。同时我也把书中一部分自己的感悟抽出来整理了精华版,share出来。当然水平有限,错漏之处有发现而修订时遗漏的,也有尚没有发现的。这本书如果对您有用,乃我之幸事,如果无用,就在此先诚惶诚恐的向大家拜个不是了。
在6月份做过一次《高效学习Linux内核》的presentation,下面是前面的一部分内容及讲义,或许对大家有用吧。至于剩余的,因为和之前博客中的部分文章内容差不多,就不贴了。
**********************************************************************
既然有高效,相对的就有低效。学习本身就是一件很玄乎的事情,有些人整天潇潇洒洒没见怎么用心就能够获得很好的成绩,而有些人则相反,即使投悬梁锥刺骨也还是成绩平平收获平平。这里面很大一部分的原因就是学习的方法。
但是学习方法这样的题目并不好讲,因为基于每个人不同的情况,并没有那样一个标准的方法存在,所以讲起来就很容易成为一场大忽悠。就像我们的任志强先生前阵子演讲卖房子 的方法时,就因为太像一场忽悠,从而被听众扔了鞋。

接下来我就通过自己的一些感悟,抛砖引玉来介绍一下如何比较高效的去学习 linux 内核。这些话并不局限于某个部分的内容,很像一句句的口号,我们也可以将它们看作内核学习的大字报。
首先是第一句话:把内核当朋友。今年笑来老师有本新书,叫把时间当朋友,告诉我们只有把时间当朋友,才能更好的利用自己的时间做些有益的事情。同样,我们只有把内核当朋友,把它放在对等的地位上,而不仅仅是一堆死气沉沉的代码,我们才能够更好的认识和理解到它的精髓。
然后是第二句话:先会使用它。意思就是我们在学习内核前首先要会用 linux ,依照一个由上至下循序渐进的过程,在能够熟练的使用 Linux 操作系统之后再去研究内核中的实现。这也是 linus 本人的观点。
第三句是依照四个层次进行内核学习。笛卡儿在 17 世纪的某一天,闲极无聊写了这么一本书,书名就叫《方法论》,在这本目前来说绝大部分人都不知道的书里将方法上升到了理论的高度。笛卡儿在他的这本书里将研究问题的方法归纳为简单的一句话,就是 “ 复杂问题要简单化 ” 。就是说要将复杂的问题分解为很多个简单的小问题,一个个的分开解决。这句话当然可以借鉴运用到内核的学习上,不过需要做些改动,不是分解为多个简单的小问题,而是将内核学习这么一件很复杂的事情划分为由低到高多个不同的层次,每一层次都有自己需要达到的目标和要求。这也是我自己认为比较好的认识学习内核的方法。
第四句是走出心理误区。 对于学习这种复杂的事情来说,无论是我们在学校的课堂学习,还是这里说的内核学习,它的效果好与坏,最主要取决于两个方面:一个是学习的方法,另一个就是学习时的心理。注意,在这儿我无视了智商的差异,智商这玩意儿太玄了,可以将它归于迷信的范畴。而我们在学习时经常会产生一系列的问题或者说误区,只有走出这些误区,在学习中养成一个坚强的心理,我们才能够真正的做到高效。
第五句是使用 vim+cscope+ctags 浏览内核源码。其实这句话更主要的意思是说我们需要一个好的工具去浏览内核的代码。在 windows 下面,我们或许可以很容易的找到很多比较好的 IDE 可以用来浏览代码,比如 source insight ,它可以很方便的在代码之间进行关联阅读。但是对于 Linux 新人来说,有没有一个功能类似的浏览代码的工具就成为一个很常见的问题。
第六句是使用 kernel 地图定位目标代码。应该说学习内核就是学习内核的源代码,但是内核代码千千万,又到处像个迷宫一样,不迷路都很难,又怎么去直面它?这时我们就需要这样的一幅内核地图来帮助我们去定位所要分析的目标代码,并缩小目标代码的范围与代码量。
接下来是第七句话:分析内核源码,态度决定一切。我们很多人或许有这样的困惑,也分析浏览了很多内核的源码,可总是觉得分析完浏览完脑子里还是空空的,并没有感觉到多大的收获。这个时候我们或许可以去看看是不是自己在分析代码时的态度出现了问题。我们在分析内核源码时,只有遵循严谨的态度,去理解每一段代码的实现,多问多想多记,而不是抱着走马观花,得过且过的态度,最终必然会有很大的收获。
最后一句是:以内核源码为中心,坚持学习资源建设。在我们内核学习的过程中,内核源码本身就是最好的参考资料,其他任何经典或非经典的书最多只是起到个辅助作用,不能也不应该取代内核代码在我们学习过程中的主导地位。但是这些辅助的作用也是不可忽视的,我们需要以内核源码为中心,坚持各种学习资源的长期建设不动摇。
除了这里的八句话,其他的可能会对大家有帮助的感悟或者方法还有很多 。

把内核当朋友,就是要把内核看成一个鲜活的生命体,而不是一堆死气沉沉的代码。
具体一点来说,我们在学习与浏览内核的实现时,可以将它看成是现实世界的映射。内核是由现实中的人写出来的,因此不管是有意还是无意,都会不可避免的包含了一些自己的现实感情,我们研究内核时可以体会下这种脉络,这种隐藏在代码背后的哲学。比如,我们可以认为内核是个大世界,一个个进程就是这个世界中的一个个生命体,进程管理和调度就是这个大世界中的权力机关,内存是进程的家,内核的目标就是要做到使每个进程都居者有其屋。
既然要把内核看成是一个鲜活的个体,那么我们认识它的第一件事就是了解它的一些基本信息,就像我们人与人之间互相认识首先也是通过个人的基本信息一样。
首先从名字开始, kernel 在字典中主要有两种定义,一种是 “ 软的,一个坚果可食用的部分 ” ,对 Linux kernel 来说,当然适用的是第二种定义: “ 某个东西的核心部分 ” 。所以从广义上来说, linux kernel 就是 linux 操作系统里最为核心的部分,而从狭义上来说,它不过就是 Linus 那群人人写的那点儿代码。
当然,这点儿代码是相当复杂的,单单从代码量上来说,早已经突破了千万级。从结构上来说,也早就不是一个人穷自己一己之力就能够全部理解的了。所以,现在强调第二句话:学内核切忌求大求全,选择一点研究的足够深入就很不容易了。
下面介绍介绍 kernel 的年龄, kernel 又不是一个怀春的少女,所以它的年龄并不需要保密,从 1991 年诞生开始,在去年刚刚举行了它自己的成人礼,进入了成熟发展期。
就像我们人有自己的青春期、中年期等一样, kernel 相应的也有很多不同的版本号,不过不同的是,我们的青春期一去就不复返了, kernel 不同的版本号却是共存的。
很多年以来,内核的版本都是以 X.Y.Z 这 3 个数字的形式分配的,中间的偶数 Y 代表稳定版,奇数 Y 代表了不稳定的开发版。所谓的稳定版本是指内核的特性都已经固定,代码运行稳定可靠,不会再增加新的特性,要改进也只是修改代码中的错误。而不稳定版本是指相对于上一个稳定版本增加了新的特性,还处于发展之中,代码的运行不大可靠。
对于目前来说, 2.6 内核的发布已经持续了很长时间,那么什么时候将会推出 2.7 ? Linus 本人的回答是,不会有 2.7 ,他不会再遵循旧的模式,新采用的模式会更好,不值得重复过去。他表示正在考虑新的编号方式,一种基于时间的版本号。比如用 2008.7 取代 2.6.26 ,中间第二个数字代表年, 2008 年就是 2.8 , 2009 年的第一个版本就是 2.9.1 ,之后 2010 年是 3.0 ,等等。
最后不得不提到是那些眼花缭乱的发行版,内核与发行版的关系就类似那种双生花,彼此互相依赖互相扶持共同成长。没有那些发行版,内核就只能是束之高阁的一个貌似好看的玩具,并不能真正的走进我们的工作生活,而没有内核,那些发行版就缺少了存在的地基,就只能是个豆腐渣工程。
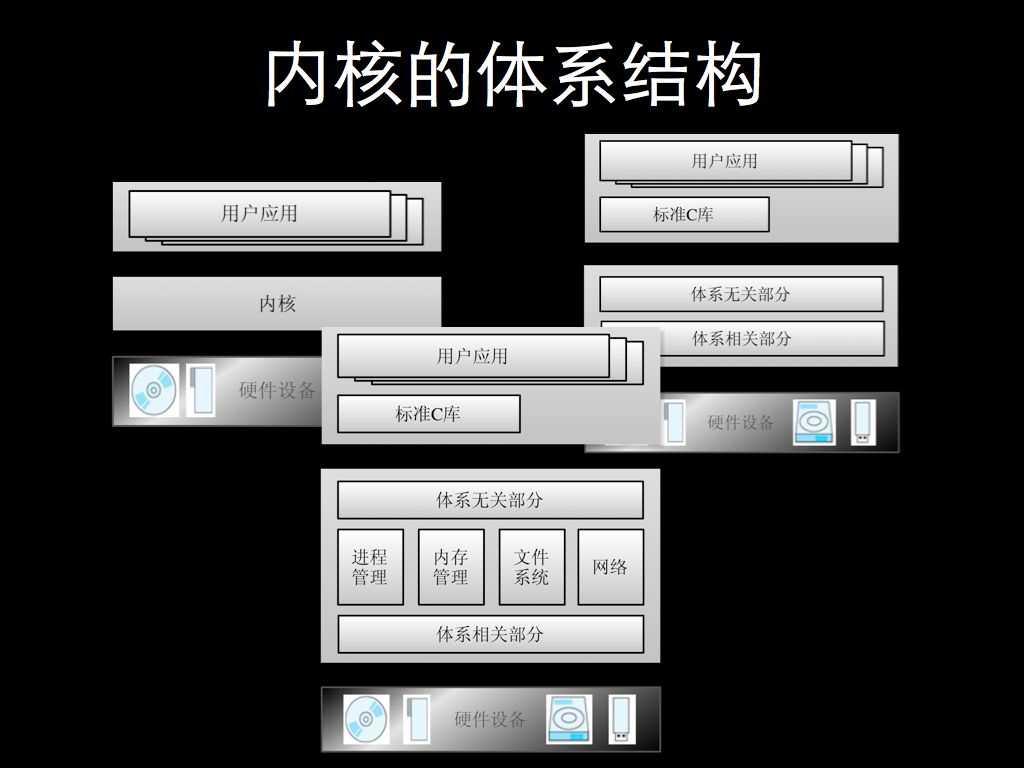
现在我们了解了内核这个朋友的外表,这个时候我们不能像非诚勿扰中的那些拜金女一样只关心外在的信息,我们还要接着了解内核的内涵,也就是内核的体系结构以及内核是如何工作的。
首先看第一张图,它向我们传递了这样的信息 —— 内核将应用程序和硬件分离开来。内核一方面负责与计算机硬件进行交互,实现对硬件的控制,调度对硬件资源的访问,另一方面为用户应用程序提供一个高级的执行环境和访问硬件的虚拟接口。
提供硬件的兼容性是内核的设计目标之一,几乎所有的硬件,只要不是为其他操作系统所定制的,都可以得到 Linux 的支持。
与硬件兼容性相关的是可移植性,也就是在不同的硬件平台上运行 Linux 的能力。从最初只支持标准 IBM 兼容机上的 Intel X86 架构到现在可以支持 ARM 、 MIPS 、 PowerPC 等几乎所有硬件平台,如此广泛的平台支持之所以能够成功,部分原因在于,内核清晰地划分为了体系相关部分和体系无关部分。因此也就有了第二张图。
体系无关部分通常会定义与体系相关部分的接口,这样,内核向新的体系结构移植的过程就变成确认这些接口的特性并将它们加以实现的过程。
同时,用户应用程序和内核之间的联系,一般是通过它和内核的中间层 —— 标准 C 库来实现,而标准 C 库函数本身,则是建立在内核提供的系统调用基础之上。通过标准 C 库,以及内核体系无关部分与体系相关部分的接口,用户应用程序和部分内核都成为可移植的。
因此更为准确的是第三张图。其中,进程管理部分实现了一个进程世界的抽象,这个进程世界类似于我们的人类世界,只不过我们的世界里的个体是人,而在进程世界里则是一个一个的进程,我们人与人之间通过书信、手机、网络等交通往来,而各个进程之间则是通过不同方式的进程间通信,我们所有人都在分享同一个地球,而所有进程都在分享一个或多个 CPU 。
在这个进程的世界里,内存是重要的资源之一,就好似我们的土地。因此,管理内存的策略与方式,也就是内存管理是决定系统性能的一个关键因素。
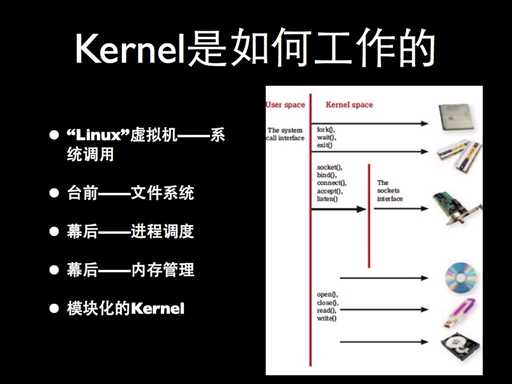
了解了内核的体系结构,我们再来看看内核是如何工作的。
首先,内核通过系统调用来使得运行在它上面的应用程序可用。系统调用是内核和应用程序之间的桥梁,比如图中的针对文件操作的 open() , close() , read() , write() ,针对进程操作的 fork() , wait() ,还有针对网络操作的 socket() 等等,它们提供了对硬件的抽象,所以有时也被称为 linux 虚拟机。
内核提供的最接近实际用户的明显抽象是文件系统,我们很容易能够利用 open() 等几个系统调用编写一段程序打开一个文件并将它的内容拷贝到标准输出。内核通过这些系统调用为用户提供了一个文件的 " 错觉 " ,而实际上它不过是一堆数据有了个名字,这样一来就不必去与硬件底层的堆栈、分区和指针等交涉,这也就是我们经常所说的抽象 (abstraction) ,将底层的东西以更易懂的方式表达出来。
文件系统是内核提供的比较明显的一种抽象,我们可以说它是位于台前的,而相对还有一些是位于幕后的,比如进程调度。在 linux 上,任何 一个时间,都可能有好几个进程或者程序等待着运行。内核的时间调度给每个进程分配 CPU 时间,所以就一段时间内来说,我们会有种错觉:电脑同一时间运行好几个程序。
再比如另外一个位于幕后的内存管理,幕后到应用开发者都不易察觉的地步。每个程序运行得都好像它有个自己的地址空间来调用一样,实际上它跟其他进程一样共享计算机的物理存储。内存管理的另外一个方面是防止一个进程访问其他进程的地址空间 —— 对于多进程操作系统来说这是很必要的一个防范措施。
当然位于台前幕后的还有其他的角色,比如网络等。
我们现在再来简单看下它的物理组成。早期版本的内核是整体式的,也就是说所有的部分都静态地连接成一个很大的执行文件。