神经网络——Python实现BP神经网络算法(理论+例子+程序)
Posted 小凌Candy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络——Python实现BP神经网络算法(理论+例子+程序)相关的知识,希望对你有一定的参考价值。
一、基于BP算法的多层感知器模型
采用BP算法的多层感知器是至今为止应用最广泛的神经网络,在多层感知器的应用中,以图3-15所示的单隐层网络的应用最为普遍。一般习惯将单隐层前馈网称为三层感知器,所谓三层包括了输入层、隐层和输出层。


算法最终结果采用梯度下降法,具体详细过程此处就省略了!
二、BP算法的程序实现流程

三、标准BP算法的改进——增加动量项
标准BP算法在调整权值时,只按t时刻误差的梯度降方向调整,而没有考虑t时刻以前的梯度方向,从而常使训练过程发生振荡,收敛缓慢。为了提高网络的训练速度,可以在权值调整公式中增加一动量项。若用W代表某层权矩阵,X代表某层输入向量,则含有动量项的权值调整向量表达式为

可以看出,增加动量项即从前一次权值调整量中取出一部分迭加到本次权值调整量中,α称为动量系数,一般有a∈ (0,1)。动量项反映了以前积累的调整经验,对于t时刻的调整起阻尼作用。当误差曲面出现骤然起伏时,可减小振荡趋势,提高训练速度。目前,BP算法中都增加了动量项,以致于有动量项的BP算法成为一种新的标准算法。
四、Python实现BP神经网络及其学习算法
这里为了运用算法,简要的举了一个例子(不需归一化或标准化的例子)
输入 X=-1:0.1:1;
输出 D=.....(具体查看代码里面的数据)
为了便于查看结果我们输出把结果绘制为图形,如下:

其中黄线和蓝线代表着训练完成后的输出与输入
五、程序如下:
# -*- coding: utf-8 -*-
import math
import string
import matplotlib as mpl
############################################调用库(根据自己编程情况修改)
import numpy.matlib
import numpy as np
np.seterr(divide='ignore',invalid='ignore')
import matplotlib.pyplot as plt
from matplotlib import font_manager
import pandas as pd
import random
#生成区间[a,b]内的随机数
def random_number(a,b):
return (b-a)*random.random()+a
#生成一个矩阵,大小为m*n,并且设置默认零矩阵
def makematrix(m, n, fill=0.0):
a = []
for i in range(m):
a.append([fill]*n)
return np.array(a)
#函数sigmoid(),两个函数都可以作为激活函数
def sigmoid(x):
#return np.tanh(x)
return (1-np.exp(-1*x))/(1+np.exp(-1*x))
#函数sigmoid的派生函数
def derived_sigmoid(x):
return 1-(np.tanh(x))**2
#return (2*np.exp((-1)*x)/((1+np.exp(-1*x)**2)))
#构造三层BP网络架构
class BPNN:
def __init__(self, num_in, num_hidden, num_out):
#输入层,隐藏层,输出层的节点数
self.num_in = num_in + 1 #增加一个偏置结点
self.num_hidden = num_hidden + 1 #增加一个偏置结点
self.num_out = num_out
#激活神经网络的所有节点(向量)
self.active_in = np.array([-1.0]*self.num_in)
self.active_hidden = np.array([-1.0]*self.num_hidden)
self.active_out = np.array([1.0]*self.num_out)
#创建权重矩阵
self.wight_in = makematrix(self.num_in, self.num_hidden)
self.wight_out = makematrix(self.num_hidden, self.num_out)
#对权值矩阵赋初值
for i in range(self.num_in):
for j in range(self.num_hidden):
self.wight_in[i][j] = random_number(0.1, 0.1)
for i in range(self.num_hidden):
for j in range(self.num_out):
self.wight_out[i][j] = random_number(0.1, 0.1)
#偏差
for j in range(self.num_hidden):
self.wight_in[0][j] = 0.1
for j in range(self.num_out):
self.wight_in[0][j] = 0.1
#最后建立动量因子(矩阵)
self.ci = makematrix(self.num_in, self.num_hidden)
self.co = makematrix(self.num_hidden, self.num_out)
#信号正向传播
def update(self, inputs):
if len(inputs) != self.num_in-1:
raise ValueError('与输入层节点数不符')
#数据输入输入层
self.active_in[1:self.num_in]=inputs
#数据在隐藏层的处理
self.sum_hidden=np.dot(self.wight_in.T,self.active_in.reshape(-1,1)) #点乘
self.active_hidden=sigmoid(self.sum_hidden) #active_hidden[]是处理完输入数据之后存储,作为输出层的输入数据
self.active_hidden[0]=-1
#数据在输出层的处理
self.sum_out=np.dot(self.wight_out.T,self.active_hidden) #点乘
self.active_out = sigmoid(self.sum_out) #与上同理
return self.active_out
#误差反向传播
def errorbackpropagate(self, targets, lr,m): #lr是学习率
if self.num_out==1:
targets=[targets]
if len(targets) != self.num_out:
raise ValueError('与输出层节点数不符!')
#误差
error=(1/2)*np.dot((targets.reshape(-1,1)-self.active_out).T,(targets.reshape(-1,1)-self.active_out))
#输出误差信号
self.error_out=(targets.reshape(-1,1)-self.active_out)*derived_sigmoid(self.sum_out)
#隐层误差信号
#self.error_hidden=np.dot(self.wight_out.reshape(-1,1),self.error_out.reshape(-1,1))*self.active_hidden*(1-self.active_hidden)
self.error_hidden=np.dot(self.wight_out,self.error_out)*derived_sigmoid(self.sum_hidden)
#更新权值
#隐藏
self.wight_out=self.wight_out+lr*np.dot(self.error_out,self.active_hidden.reshape(1,-1)).T+m*self.co
self.co=lr*np.dot(self.error_out,self.active_hidden.reshape(1,-1)).T
#输入
self.wight_in=self.wight_in+lr*np.dot(self.error_hidden,self.active_in.reshape(1,-1)).T+m*self.ci
self.ci=lr*np.dot(self.error_hidden,self.active_in.reshape(1,-1)).T
return error
#测试
def test(self, patterns):
for i in patterns:
print(i[0:self.num_in-1], '->', self.update(i[0:self.num_in-1]))
return self.update(i[0:self.num_in-1])
#权值
def weights(self):
print("输入层权重")
print(self.wight_in)
print("输出层权重")
print(self.wight_out)
def train(self, pattern, itera=100, lr = 0.2, m=0.1):
for i in range(itera):
error = 0.0
for j in pattern:
inputs = j[0:self.num_in-1]
targets = j[self.num_in-1:]
self.update(inputs)
error = error+self.errorbackpropagate(targets, lr,m)
if i % 10 == 0:
print('########################误差 %-.5f######################第%d次迭代' %(error,i))
#实例
X=list(np.arange(-1,1.1,0.1))
D=[-0.96, -0.577, -0.0729, 0.017, -0.641, -0.66, -0.11, 0.1336, -0.201, -0.434, -0.5, -0.393, -0.1647, 0.0988, 0.3072, 0.396, 0.3449, 0.1816, -0.0312, -0.2183, -0.3201]
A=X+D
patt=np.array([A]*2)
#创建神经网络,21个输入节点,21个隐藏层节点,1个输出层节点
n = BPNN(21, 21, 21)
#训练神经网络
n.train(patt)
#测试神经网络
d=n.test(patt)
#查阅权重值
n.weights()
plt.plot(X,D)
plt.plot(X,d)
plt.show()来源:小凌のBlog—Good Times|一个不咋地的博客
[1] 韩力群,人工神经网络理论及应用 [M]. 北京:机械工业出版社,2016.
机器学习基础使用python实现BP算法
用pytorch跟tensorflow实现神经网络固然爽。但是想要深入学习神经网络,光学会调包是不够的,还是得亲自动手去实现一个神经网络,才能更好去理解。
一、问题介绍
传说中线性分类器无法解决的异或分类问题。我们就拿它来作为我们神经网络的迷你训练数据。把输入数据拼成一个矩阵X:
import numpy as np
#训练数据:经典的异或分类问题
train_X = np.array([[0,0],[0,1],[1,0],[1,1]])
train_y = np.array([0,1,1,0])
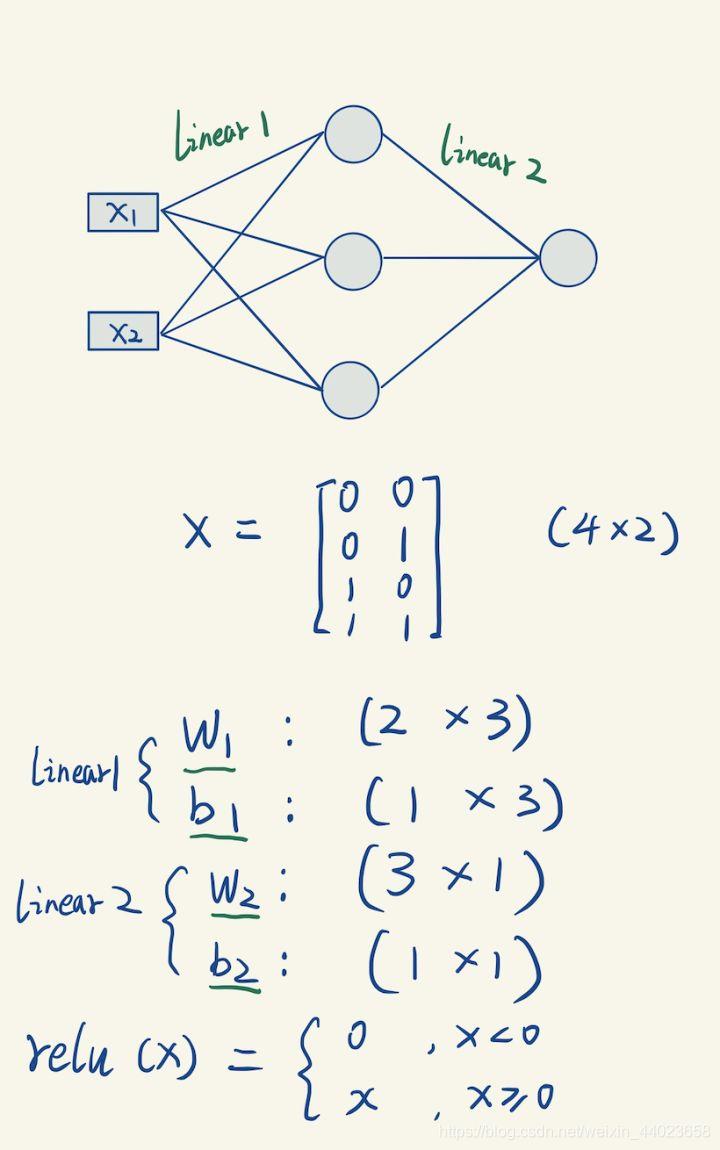
我们定义一个简单的2层神经网络: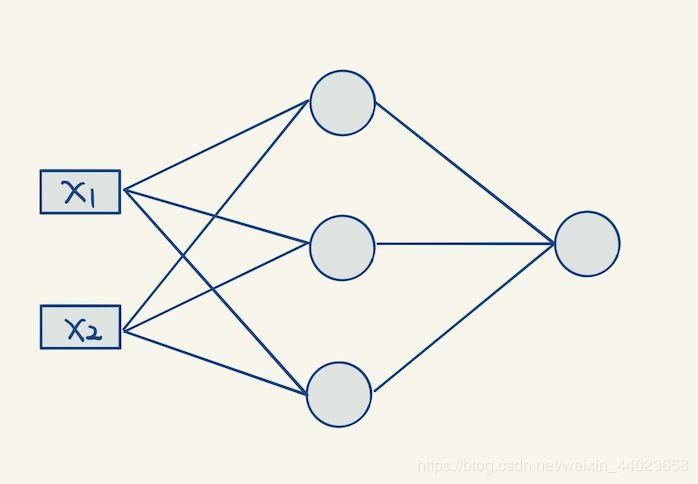 对应的代码
对应的代码
linear1 = LinearLayer(2,3)
relu1 = Relu()
linear2 = LinearLayer(3,1)
 我们还需要定义一个损失函数Loss,用来衡量我们的输出结果与实际结果的误差。这里用的是均方误差MSE,表达式如下
我们还需要定义一个损失函数Loss,用来衡量我们的输出结果与实际结果的误差。这里用的是均方误差MSE,表达式如下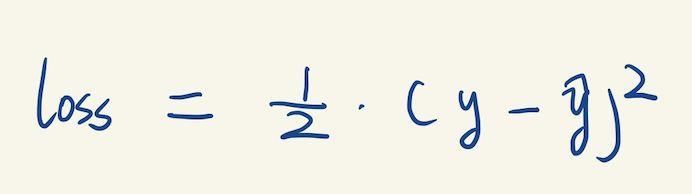
二、BP算法 和 计算图(Computing Graph)模型
里面的线性层,Relu层也得自己动手实现。
实现这些,我们首先需要知道计算图模型。计算图模型是所有神经网络框架的核心理论基础。
我们依然还是对着这个例子来讲解。
上面的神经网络,用纯数学公式表达可以表达。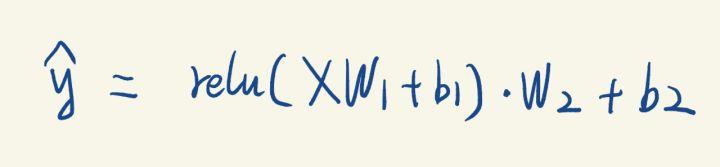 计算图模型把一个复合运算拆分成为多个子运算,因此,我们需要引入很多中间变量。
计算图模型把一个复合运算拆分成为多个子运算,因此,我们需要引入很多中间变量。
定义:
 根据这些公式,我们就可以用计算图模型来表示我们的神经网络,如下:
根据这些公式,我们就可以用计算图模型来表示我们的神经网络,如下: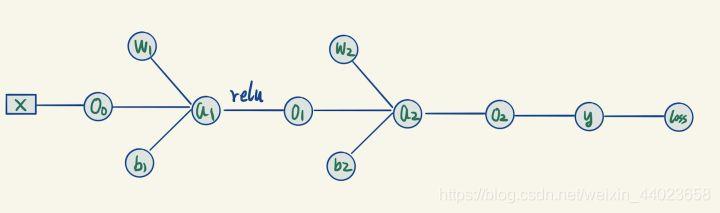 这个计算图就是上面那一堆公式的可视化表示。
这个计算图就是上面那一堆公式的可视化表示。
在图里面,公式里每个出现过的变量都被视为一个节点,变量之间的连线描述了变量之间存在直接的计算的关系。计算图的表示方法,有什么好处呢?
下面我们基于这个计算图来用BP算法进行模型的训练。
对模型进行训练,就是找到一组模型的参数,使得我们的网络模型能够准确预测我们的训练数据。在我们这个例子里面,需要训练参数其实只有线性层的矩阵跟bias项:[公式] 。
训练采用的是BP算法,采用梯度下降法来逐渐迭代去更新参数。
梯度下降法的原理很简单,每次迭代中,用损失函数关于参数的梯度乘以学习率,来更新参数。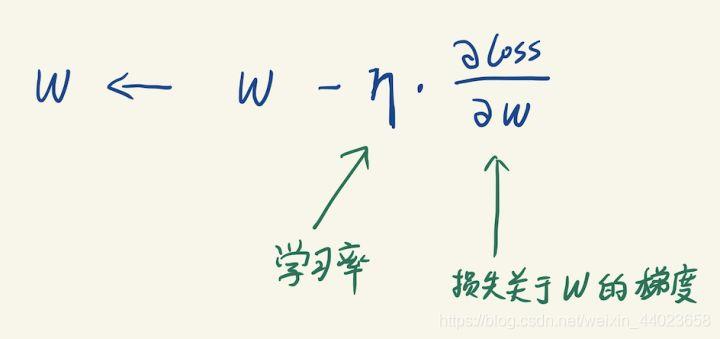 关于梯度我要多说几句。梯度表示Y关于x的变化率,可以理解成x的速度。由于W1是一个2X3的矩阵,那么loss关于W1的梯度可以理解W1的每个元素的瞬时速度。W1的梯度的形状,必然是严格跟参数本身的形状是一样的(每个点都有对应的速度)。也就是说损失函数关于W1的梯度也必然是一个2X3的矩阵(不然更新公式里面无法做加减)。
关于梯度我要多说几句。梯度表示Y关于x的变化率,可以理解成x的速度。由于W1是一个2X3的矩阵,那么loss关于W1的梯度可以理解W1的每个元素的瞬时速度。W1的梯度的形状,必然是严格跟参数本身的形状是一样的(每个点都有对应的速度)。也就是说损失函数关于W1的梯度也必然是一个2X3的矩阵(不然更新公式里面无法做加减)。
下面开始训练过程,
首先给定输入X,初始化 [公式] (记住不能初始为全0)。
正向传播(forward pass)
BP算法首先在计算图上面进行正向传播(forward pass),即从左到右计算所有未知量: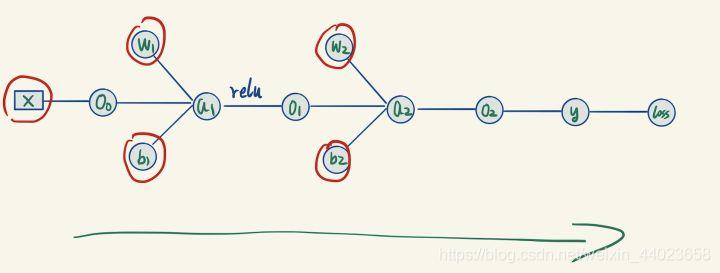 严格按照顺序计算,所有的 [公式] 都能先后求出,右边的y就是网络的当前预测结果。
严格按照顺序计算,所有的 [公式] 都能先后求出,右边的y就是网络的当前预测结果。
反向传播(backward pass)
既然我们想要用参数的梯度来更新参数,那么我们需要求出最后的节点输出loss关于每个参数的梯度,求梯度的方法是反向传播。
由于我们已经进行过一次正向传播,因此图里面所有的节点的值都变成了已知量。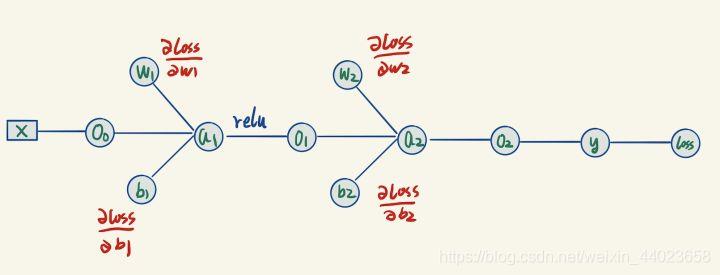 我们现在要求的是图里面标为红色的这4个梯度,它们距离loss有点儿远。
我们现在要求的是图里面标为红色的这4个梯度,它们距离loss有点儿远。
但是不急,有了这个计算图,我们可以慢慢从右往左推出这4个值。
先从最右边开始,观察到Loss节点只有一条边跟y连着,计算loss关于y的导数(这个求导只有一个变量y,怎么求不用我解释了吧):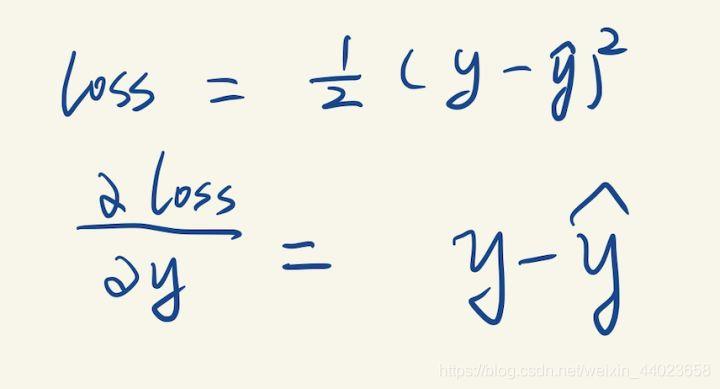 我们就求得了损失函数关于输出y的导数,然后继续往左边计算。
我们就求得了损失函数关于输出y的导数,然后继续往左边计算。
(已经求出的梯度我们用橙色来标记)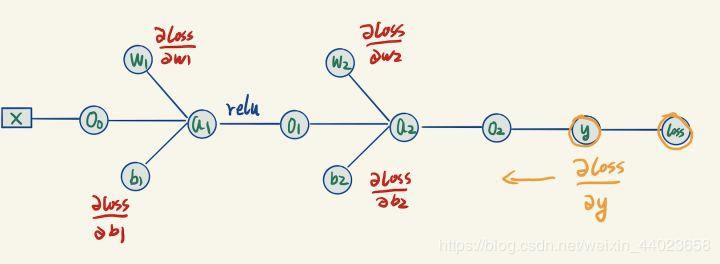 y是通过O2计算出来的,我们可以计算y关于O2的梯度:
y是通过O2计算出来的,我们可以计算y关于O2的梯度: 但是我们想要的是loss关于O2的梯度,这里应用到了链式求导法则:
但是我们想要的是loss关于O2的梯度,这里应用到了链式求导法则: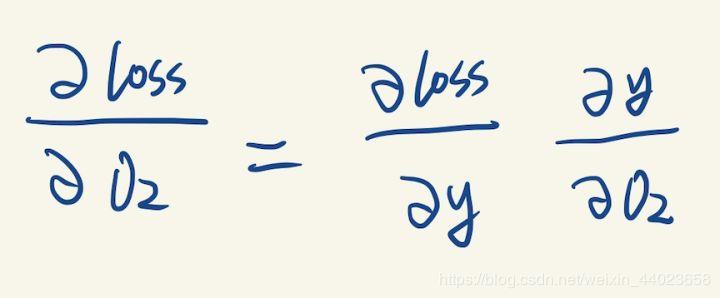 loss关于y的梯度在之前已经求出来过了,然后就可以求出loss关于O2的梯度。
loss关于y的梯度在之前已经求出来过了,然后就可以求出loss关于O2的梯度。
继续往左计算梯度: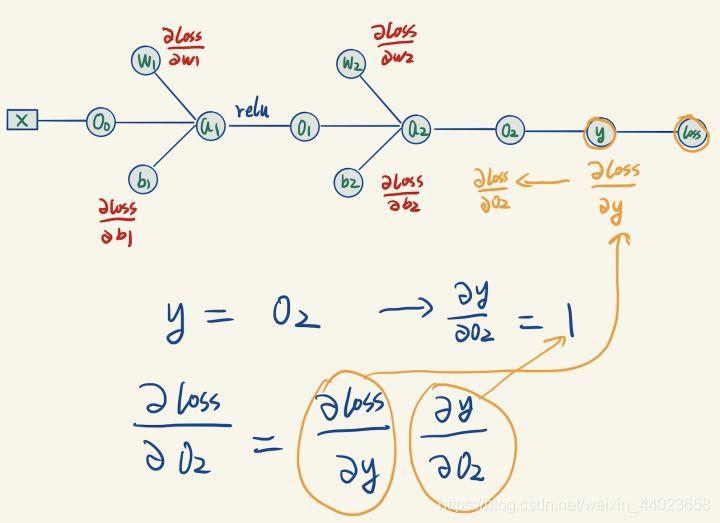
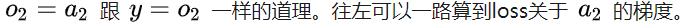
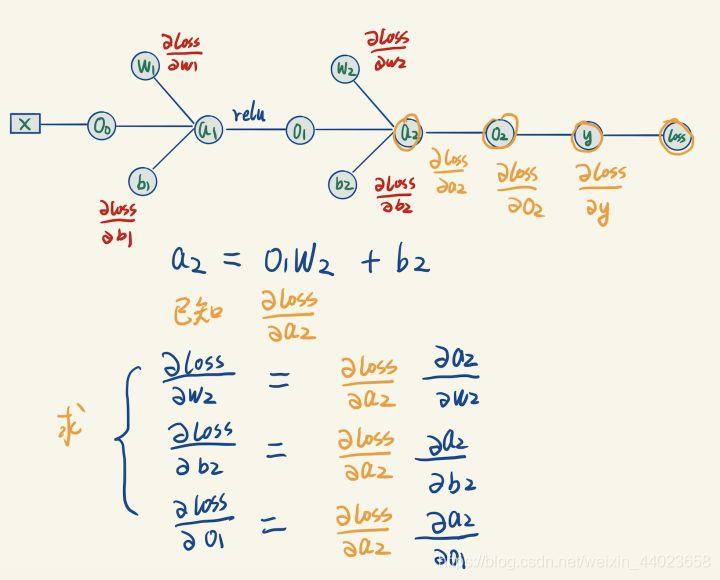 上图中 a2 关于它每个变量的梯度,可以直接根据 a2 与它左边3个变量的表达式来算出,如下:
上图中 a2 关于它每个变量的梯度,可以直接根据 a2 与它左边3个变量的表达式来算出,如下: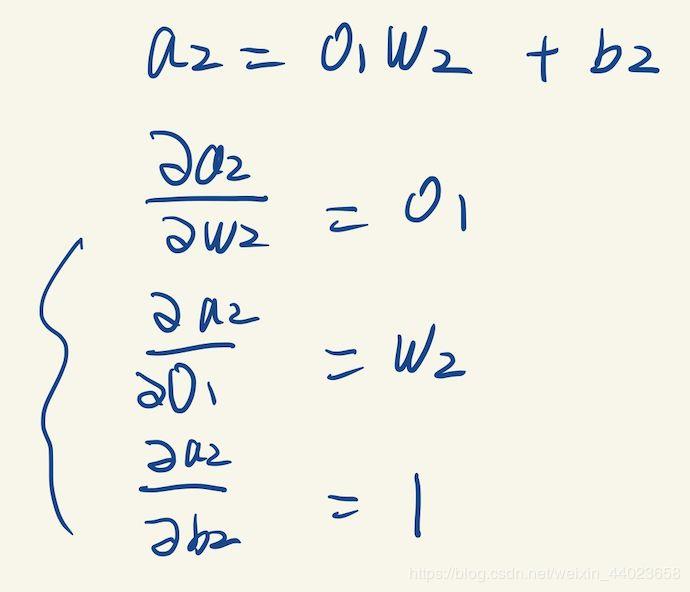 这一步我们算出了两个需要计算的梯度,似乎并没有遇到困难,继续往左传播。
这一步我们算出了两个需要计算的梯度,似乎并没有遇到困难,继续往左传播。
在计算 a1梯度的时候,我们遇到了relu激活函数,relu函数的梯度也很好求: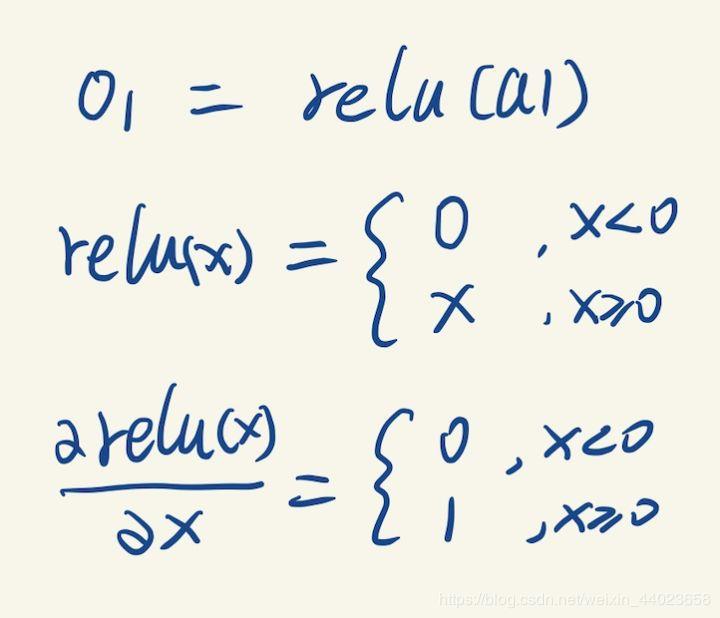 它的梯度就是在输入X的基础上,所有大于0的位置导数都是1,其他位置导数都是0,比如:
它的梯度就是在输入X的基础上,所有大于0的位置导数都是1,其他位置导数都是0,比如: (这括号里的看不懂不要紧,当N维向量对M维向量求导应用链式法则时,通用一点儿的结果是一个NM的jacobian矩阵再乘M1向量,但是这里由于1. N=M。2. jacobian矩阵是一个对角方阵。所以可以简化成两个向量相乘)
(这括号里的看不懂不要紧,当N维向量对M维向量求导应用链式法则时,通用一点儿的结果是一个NM的jacobian矩阵再乘M1向量,但是这里由于1. N=M。2. jacobian矩阵是一个对角方阵。所以可以简化成两个向量相乘)
再往左继续传,我就不写每个步骤了。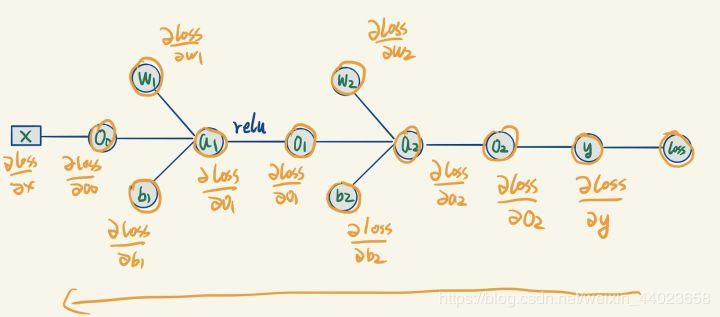 总之可以一直传到所有梯度都求出来为止。接下来一步就是愉快地进行随机梯度下降法的更新操作了。
总之可以一直传到所有梯度都求出来为止。接下来一步就是愉快地进行随机梯度下降法的更新操作了。
三、模块化各种Layer
观察我们的网络,发现里面的几个模块之间其实大部分干的事情都是相似的,无非就是层数不一样。那么我们就可以复用,我们完全可以把它们抽象成不同的Layer: 于是,我们可以把这些类似模块看成一个小黑盒子,我们的模型等价于下面这个:
于是,我们可以把这些类似模块看成一个小黑盒子,我们的模型等价于下面这个: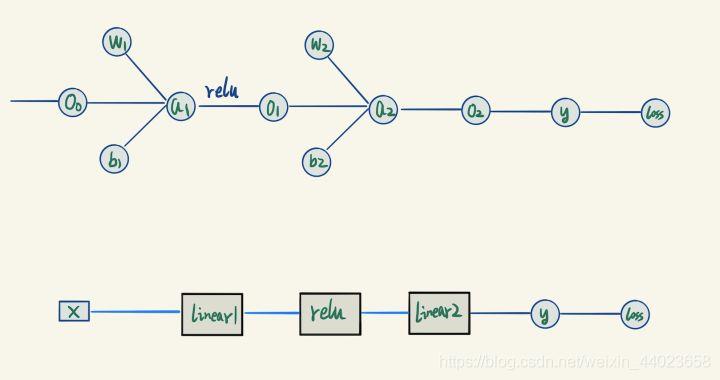 于是上面那个复杂的网状结构,被我们简化成了线性结构。
于是上面那个复杂的网状结构,被我们简化成了线性结构。
下面我对照代码实现每个小黑盒子吧,实现代码在这个文件里面:Layers.py首先介绍线性全连接层,先看代码吧:
class LinearLayer:
def __init__(self, input_D, output_D):
self._W = np.random.normal(0, 0.1, (input_D, output_D)) #初始化不能为全0
self._b = np.random.normal(0, 0.1, (1, output_D))
self._grad_W = np.zeros((input_D, output_D))
self._grad_b = np.zeros((1, output_D))
def forward(self, X):
return np.matmul(X, self._W) + self._b
def backward(self, X, grad):
self._grad_W = np.matmul( X.T, grad)
self._grad_b = np.matmul(grad.T, np.ones(X.shape[0]))
return np.matmul(grad, self._W.T)
def update(self, learn_rate):
self._W = self._W - self._grad_W * learn_rate
self._b = self._b - self._grad_b * learn_rate
forward太简单了,就不讲了,看一下backward。
backward里面其实要计算3个值,W, b的梯度算完以后要存起来,前一层的梯度算完以后直接作为返回值传出去,推导的公式如下: 注意矩阵求导应用链式法则的时候,顺序非常重要。要严格按照指定顺序来乘,不然形状对不上。具体什么顺序,可以自己想办法慢慢拼凑出来。
注意矩阵求导应用链式法则的时候,顺序非常重要。要严格按照指定顺序来乘,不然形状对不上。具体什么顺序,可以自己想办法慢慢拼凑出来。
还有一个update函数,调用此函数这一层会按照梯度下降法来更新它的W跟b的值,这个实现也很简单直接看代码就明白了。
然后实现Relu层:
class Relu:
def __init__(self):
pass
def forward(self, X):
return np.where(X < 0, 0, X)
def backward(self, X, grad):
return np.where(X > 0, X, 0) * gr
由于这一层没有需要保存参数,只需要实现以下forward跟backward方法就行了,非常简单。
接下来开始实现神经网络训练。
四、搭建神经网络
训练部分的代码在 nn.py 里面,里面的代码哪里看不懂可以翻回去看之前的解释,命名都是跟上面说的一样的。
#训练数据:经典的异或分类问题
train_X = np.array([[0,0],[0,1],[1,0],[1,1]])
train_y = np.array([0,1,1,0])
#初始化网络,总共2层,输入数据是2维,第一层3个节点,第二层1个节点作为输出层,激活函数使用Relu
linear1 = LinearLayer(2,3)
relu1 = Relu()
linear2 = LinearLayer(3,1)
#训练网络
for i in range(10000):
#前向传播Forward,获取网络输出
o0 = train_X
a1 = linear1.forward(o0)
o1 = relu1.forward(a1)
a2 = linear2.forward(o1)
o2 = a2
#获得网络当前输出,计算损失loss
y = o2.reshape(o2.shape[0])
loss = MSELoss(train_y, y) # MSE损失函数
#反向传播,获取梯度
grad = (y - train_y).reshape(result.shape[0],1)
grad = linear2.backward(o1, grad)
grad = relu1.backward(a1, grad)
grad = linear1.backward(o0, grad)
learn_rate = 0.01 #学习率
#更新网络中线性层的参数
linear1.update(learn_rate)
linear2.update(learn_rate)
#判断学习是否完成
if i % 200 == 0:
print(loss)
if loss < 0.001:
print("训练完成! 第%d次迭代" %(i))
break
我觉得没啥好讲的,就直接对着我们的计算图,一步一步来。
注意一下中间过程几个向量的形状。列向量跟行向量是不一样的,一不小心把列向量跟行向量做运算,numpy不会报错,而是会广播成一个矩阵。所以运算的之前,记得该转置得转置。
#将训练好的层打包成一个model
model = [linear1, relu1, linear2]
#用训练好的模型去预测
def predict(model, X):
tmp = X
for layer in model:
tmp = layer.forward(tmp)
return np.where(tmp > 0.5, 1, 0)
把模型打包然后用上面的predict函数来预测。也没啥好说的,就直接往后一直forward就完儿事。
#开始预测
print("-----")
X = np.array([[0,0],[0,1],[1,0],[1,1]])
result = predict(model, X)
print("预测数据1")
print(X)
print("预测结果1")
print(result)
预测训练完的网络就能拿去搞预测了,我这里设置学习率为0.01的情况下,在第3315次迭代时候完成训练。
最后我们成功地预测了训练数据。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):
以上是关于神经网络——Python实现BP神经网络算法(理论+例子+程序)的主要内容,如果未能解决你的问题,请参考以下文章