微服务治理之监控APM系统监控架构概述
Posted 人工智
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务治理之监控APM系统监控架构概述相关的知识,希望对你有一定的参考价值。
APM 简介
APM 通常认为是 Application Performance Management 的简写,它主要有三个方面的内容,分别是
- Logs(日志)、
- Traces(链路追踪)
- Metrics(报表统计)。
以后大家接触任何一个 APM 系统的时候,都可以从这三个方面去分析它到底是什么样的一个系统。Metrics可以用于服务告警,Tracing 和 Logging 用于调试发现问题。监控、追踪和日志是可观测性(observability)的基石

有些场景中,APM 特指上面三个中的 Metrics,我们这里不去讨论这个概念。这节我们先对这 3 个方面进行介绍,同时介绍一下这 3 个领域里面一些常用的工具。
1、Metrics
Prometheus:收集度量标准
告警管理器:根据指标查询向各种提供者发送警报
Grafana:把prometheus收集到的数据,变成可视化豪华仪表板

还有一个方案是使用美团开源监控系统CAT,提供了比较全面的实时监控告警服务。
优势:监控功能强大,基本上可以覆盖各种监控场景
劣势:接入成本较高、对业务代码侵入较大
1、Logs ,就是对个应用中打印的 log 进行收集和提供查询能力。
- Logs 的典型实现是 ELK (ElasticSearch、Logstash、Kibana),三个项目都是由 Elastic 开源,其中最核心的就是 ES 的储存和查询的性能得到了大家的认可,经受了非常多公司的业务考验。Logstash 负责收集日志,然后解析并存储到 ES。通常有两种比较主流的日志采集方式,一种是通过一个客户端程序 FileBeat,收集每个应用打印到本地磁盘的日志,发送给 Logstash;另一种则是每个应用不需要将日志存储到磁盘,而是直接发送到 Kafka 集群中,由 Logstash 来消费。
Kibana 是一个非常好用的工具,用于对 ES 的数据进行可视化,简单来说,它就是 ES 的客户端。
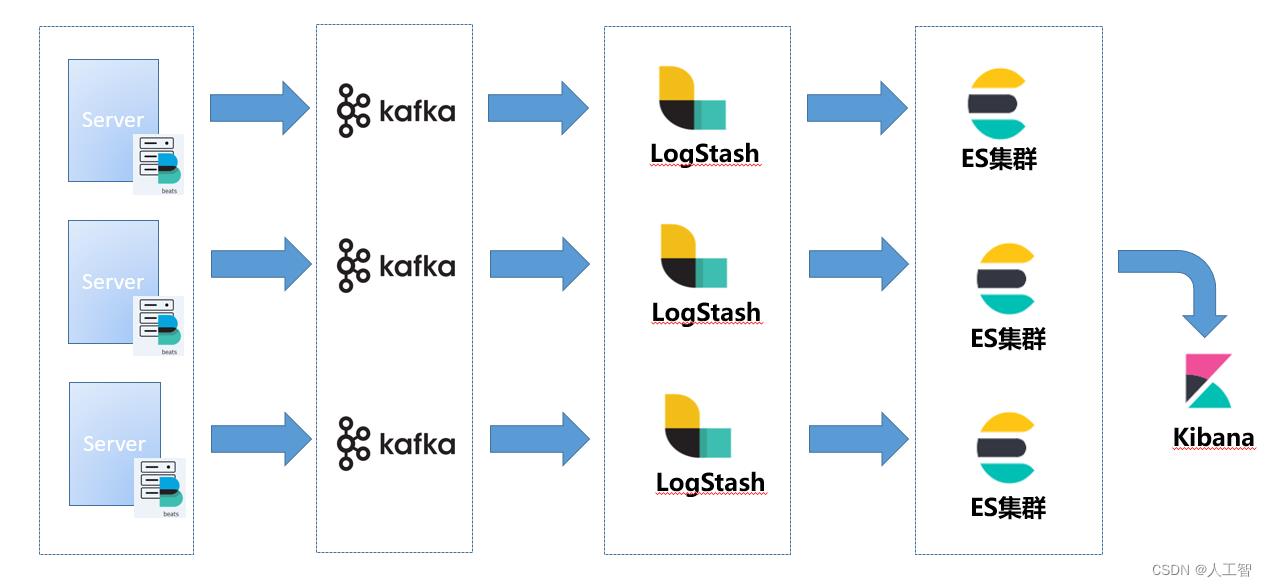
我们回过头来分析 Logs 系统,Logs 系统的数据来自于应用中打印的日志,它的特点是数据量可能很大,取决于应用开发者怎么打日志,Logs 系统需要存储全量数据,通常都要支持至少 1 周的储存。
每条日志包含 ip、thread、class、timestamp、traceId、message 等信息,它涉及到的技术点非常容易理解,就是日志的存储和查询。
使用也非常简单,排查问题时,通常先通过关键字搜到一条日志,然后通过它的 traceId 来搜索整个链路的日志。
题外话,Elastic 其实除了 Logs 以外,也提供了 Metrics 和 Traces 的解决方案,不过目前国内用户主要是使用它的 Logs 功能。
2、 Traces 系统,它用于记录整个调用链路。
前面介绍的 Logs 系统使用的是开发者打印的日志,所以它是最贴近业务的。而 Traces 系统就离业务更远一些了,它关注的是一个请求进来以后,经过了哪些应用、哪些方法,分别在各个节点耗费了多少时间,在哪个地方抛出的异常等,用来快速定位问题。
经过多年的发展,Traces 系统虽然在服务端的设计很多样,但是客户端的设计慢慢地趋于统一,所以有了 OpenTracing 项目,我们可以简单理解为它是一个规范,它定义了一套 API,把客户端的模型固化下来。
微服务架构普及,分布式追踪系统大量涌现,但API互不兼容,难以整合和切换,因此OpenTracing提出了统一的平台无关、厂商无关的API,不同的分布式追踪系统去实现。这种作用与“JDBC”类似。
OpenTracing是一个轻量级的标准化层,位于“应用程序/类库”和“日志/追踪程序”之间。
应用程序/类库层示例:开发者在开发应用代码想要加入追踪数据、ORM类库想要加入ORM和SQL的关系、HTTP负载均衡器使用OpenTracing标准来设置请求、跨进程的任务(gRPC等)使用OpenTracing的标准格式注入追踪数据。所有这些,都只需要对接OpenTracing API,而无需关心后面的追踪、监控、日志等如何采集和实现。
当前比较主流的 Traces 系统中**,Jaeger、SkyWalking** 是使用这个规范的,而 Zipkin、Pinpoint 没有使用该规范。
SkyWalking 在国内应该比较多公司使用,是一个比较优秀的由国人发起的开源项目,已进入 Apache 基金会。
另一个比较好的开源 Traces 系统是由韩国人开源的 Pinpoint,它的打点数据非常丰富。国内用skywalking比较好,有成熟的社区,可以加群和创始人沟通。
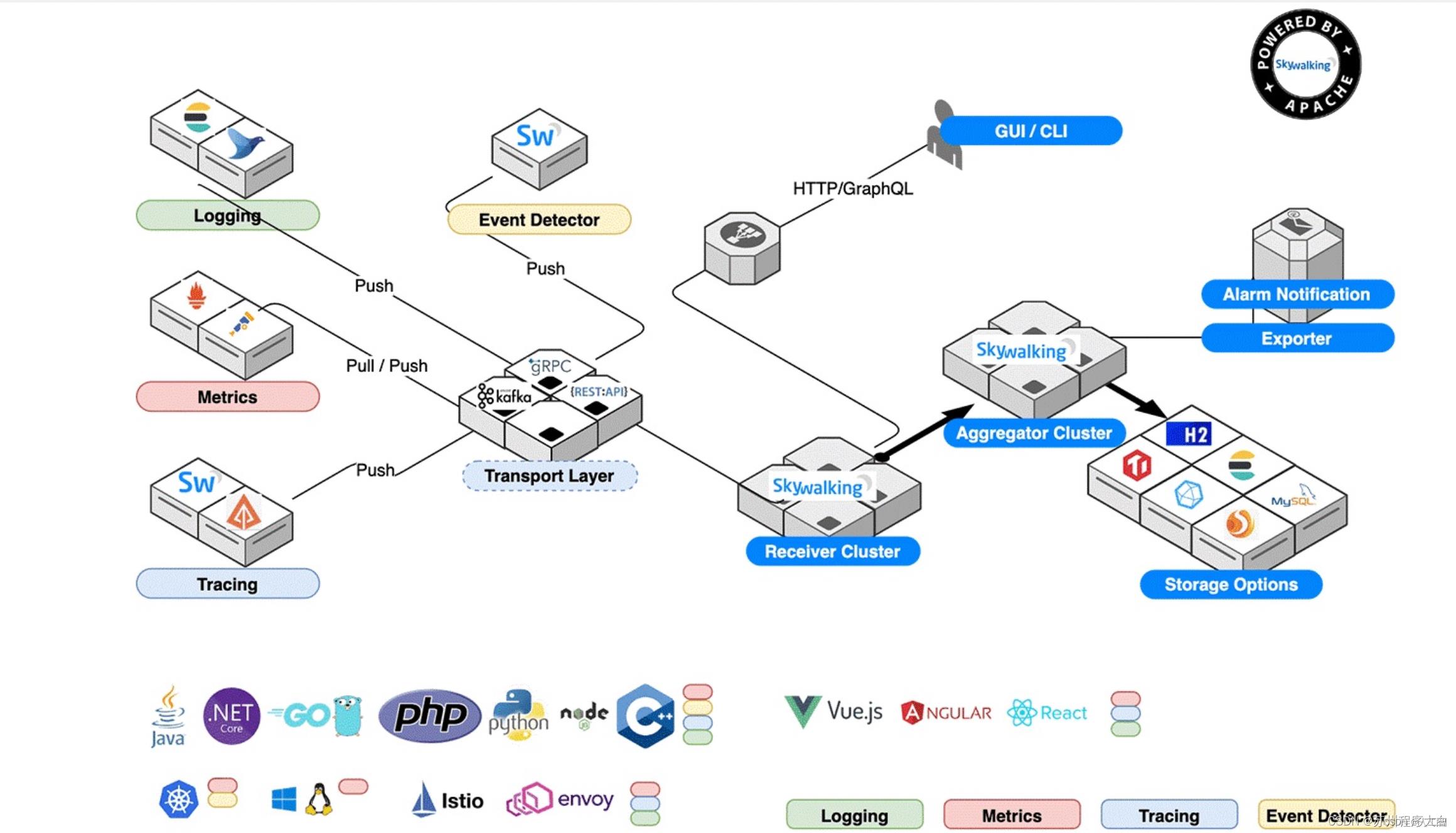 Skywalking目前想要做成跟踪、监控、日志一体的解决方案(Tracing, Metrics and Logging all-in-one solution)。
Skywalking目前想要做成跟踪、监控、日志一体的解决方案(Tracing, Metrics and Logging all-in-one solution)。
数据收集:Tracing依赖探针(Agent),Metrics依赖Prometheus或者新版的Open Telemetry,日志通过ES或者Fluentd。
数据传输:通过kafka、Grpc、HTTP传输到Skywalking Reveiver
数据解析和分析:OAP系统进行数据解析和分析。
数据存储:后端接口支持多种存储实现,例如ES。
UI模块:通过GraphQL进行查询,然后通过VUE搭建的前端进行展示。
告警:可以对接多种告警,最新版已经支持钉钉。
参考:
1、https://developer.aliyun.com/article/971591?spm=a2c6h.14164896.0.0.5b90c520Bz1nGI
2、https://developer.aliyun.com/article/1053064
3、https://blog.51cto.com/mingongge/3313415
微服务架构之「 监控系统 」
(给Linux爱好者加星标,提升Linux技能)
今天这篇文章我们来聊一聊一个重要模块:「 监控系统 」。
因为在微服务的架构下,我们对服务进行了拆分,所以用户的每次请求不再是由某一个服务独立完成了,而是变成了多个服务一起配合完成。这种情况下,一旦请求出现异常,我们必须得知道是在哪个服务环节出了故障,就需要对每一个服务,以及各个指标都进行全面的监控。
一、什么是「 监控系统 」?
在微服务架构中,监控系统按照原理和作用大致可以分为三类(并非严格分类,仅从日常使用角度来看):
日志类(Log)
调用链类(Tracing)
度量类(Metrics)
下面来分别对这三种常见的监控模式进行说明:
日志类(Log)
日志类比较常见,我们的框架代码、系统环境、以及业务逻辑中一般都会产出一些日志,这些日志我们通常把它记录后统一收集起来,方便在需要的时候进行查询。
日志类记录的信息一般是一些事件、非结构化的一些文本内容。日志的输出和处理的解决方案比较多,大家熟知的有 ELK Stack 方案(Elasticseach + Logstash + Kibana),如图:
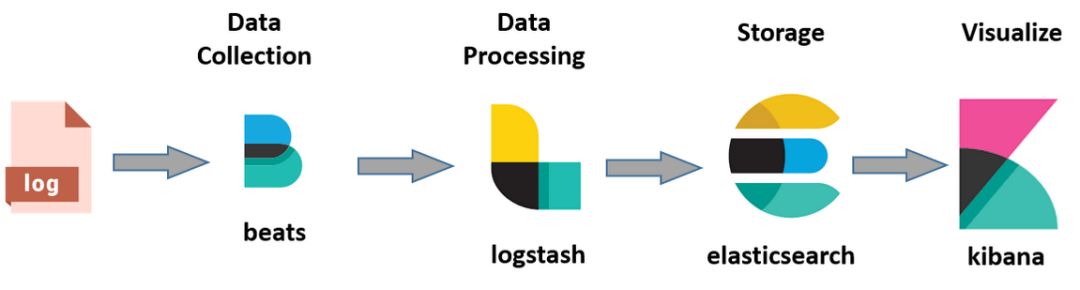 使用Beats(可选)在每台服务器上安装后,作为日志客户端收集器,然后通过Logstash进行统一的日志收集、解析、过滤等处理,再将数据发送给Elasticsearch中进行存储分析,最后使用Kibana来进行数据的展示。
使用Beats(可选)在每台服务器上安装后,作为日志客户端收集器,然后通过Logstash进行统一的日志收集、解析、过滤等处理,再将数据发送给Elasticsearch中进行存储分析,最后使用Kibana来进行数据的展示。当然还可以升级方案为:
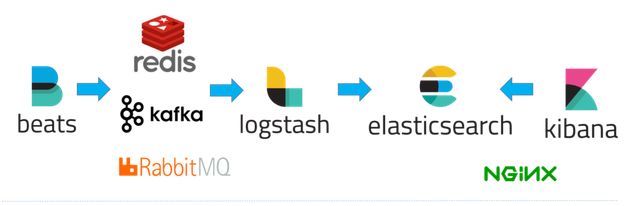 这些方案都比较成熟,搭建起来也比较简单,除了用作监控系统以外,还可以作为日志查询系统使用,非常适用于做分析、以及问题调试使用。
这些方案都比较成熟,搭建起来也比较简单,除了用作监控系统以外,还可以作为日志查询系统使用,非常适用于做分析、以及问题调试使用。调用链类(Tracing)
调用链类监控主要是指记录一个请求的全部流程。一个请求从开始进入,在微服务中调用不同的服务节点后,再返回给客户端,在这个过程中通过调用链参数来追寻全链路行为。通过这个方式可以很方便的知道请求在哪个环节出了故障,系统的瓶颈在哪儿。
这一类的监控一般采用 CAT 工具 来完成,一般在大中型项目较多用到,因为搭建起来有一定的成本。后面会有单独文章来讲解这个调用链监控系统。
度量类(Metrics)
度量类主要采用 时序数据库 的解决方案。它是以事件发生时间以及当前数值的角度来记录的监控信息,是可以聚合运算的,用于查看一些指标数据和指标趋势。所以这类监控主要不是用来查问题的,主要是用来看趋势的。
Metrics一般有5种基本的度量类型:Gauges(度量)、Counters(计数器)、 Histograms(直方图)、 Meters(TPS计算器)、Timers(计时器)。
基于时间序列数据库的监控系统是非常适合做监控告警使用的,所以现在也比较流行这个方案,如果我们要搭建一套新的监控系统,我也建议参考这类方案进行。
因此本文接下来也会重点以时间序列数据库的监控系统为主角来描述。
二、「 监控系统 」关注的对象和指标都是什么?
一般我们做「监控系统」都是需要做分层式监控的,也就是说将我们要监控的对象进行分层,一般主要分为:
系统层:系统层主要是指CPU、磁盘、内存、网络等服务器层面的监控,这些一般也是运维同学比较关注的对象。
应用层:应用层指的是服务角度的监控,比如接口、框架、某个服务的健康状态等,一般是服务开发或框架开发人员关注的对象。
用户层:这一层主要是与用户、与业务相关的一些监控,属于功能层面的,大多数是项目经理或产品经理会比较关注的对象。
知道了监控的分层后,我们再来看一下监控的指标一般有哪些:
延迟时间:主要是响应一个请求所消耗的延迟,比如某接口的HTTP请求平均响应时间为100ms。
请求量:是指系统的容量吞吐能力,例如每秒处理多少次请求(QPS)作为指标。
错误率:主要是用来监控错误发生的比例,比如将某接口一段时间内调用时失败的比例作为指标。
三、基于时序数据库的「 监控系统 」有哪些?
下面介绍几款目前业内比较流行的基于时间序列数据库的开源监控方案:
Prometheus
Promethes是一款2012年开源的监控框架,其本质是时间序列数据库,由Google前员工所开发。
Promethes采用拉的模式(Pull)从应用中拉取数据,并还支持 Alert 模块可以实现监控预警。它的性能非常强劲,单机可以消费百万级时间序列。
架构如下:
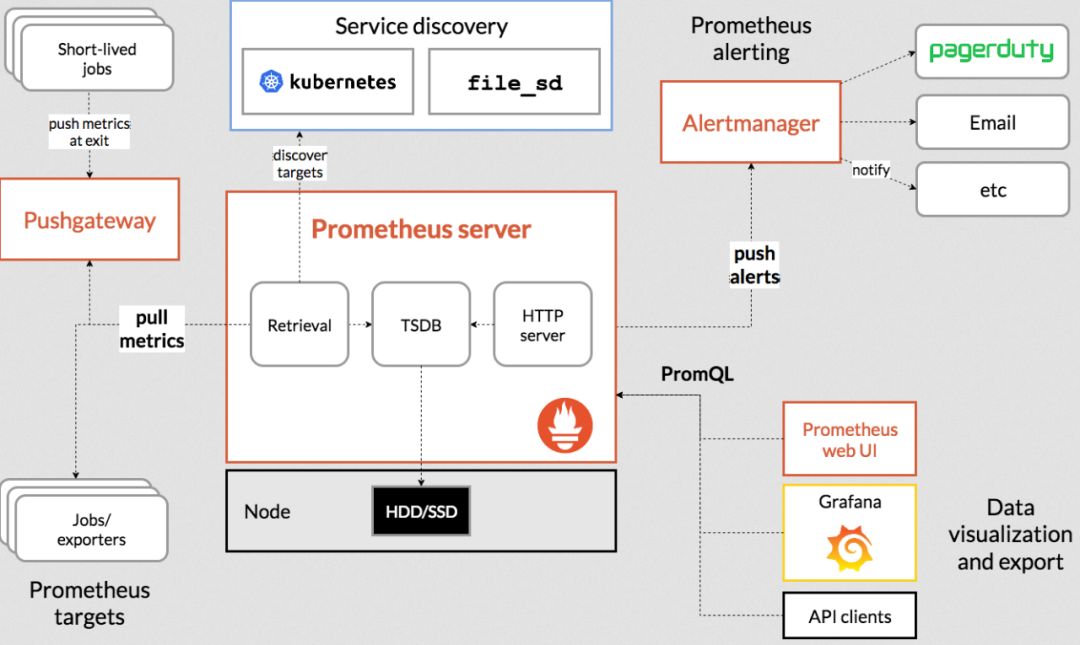 从看图的左下角可以看到,Prometheus 可以通过在应用里进行埋点后Pull到 Prometheus Server里,如果应用不支持埋点,也可以采用exporter方式进行数据采集。
从看图的左下角可以看到,Prometheus 可以通过在应用里进行埋点后Pull到 Prometheus Server里,如果应用不支持埋点,也可以采用exporter方式进行数据采集。从图的左上角可以看到,对于一些定时任务模块,因为是周期性运行的,所以采用拉的方式无法获取数据,那么Prometheus 也提供了一种推数据的方式,但是并不是推送到Prometheus Server中,而是中间搭建一个 Pushgateway,定时任务模块将metrics信息推送到这个Pushgateway中,然后Prometheus Server再依然采用拉的方式从Pushgateway中获取数据。
需要拉取的数据既可以采用静态方式配置在Prometheus Server中,也可以采用服务发现的方式(即图的中间上面的Service discovery所示)。
PromQL:是Prometheus自带的查询语法,通过编写PromQL语句可以查询Prometheus里面的数据。
Alertmanager:是用于数据的预警模块,支持通过多种方式去发送预警。
WebUI:是用来展示数据和图形的,但是一般大多数是与Grafana结合,采用Grafana来展示。
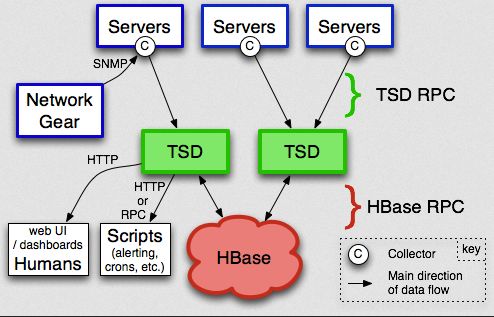
OpenTSDB
OpenTSDB是在2010年开源的一款分布式时序数据库,当然其主要用于监控方案中。
OpenTSDB采用的是Hbase的分布式存储,它获取数据的模式与Prometheus不同,它采用的是推模式(Push)。
在展示层,OpenTSDB自带有WebUI视图,也可以与Grafana很好的集成,提供丰富的展示界面。
但OpenTSDB并没有自带预警模块,需要自己去开发或者与第三方组件结合使用。
可以通过下图来了解一下OpenTSDB的架构:
InfluxDB
InfluxDB是在2013年开源的一款时序数据库,在这里我们主要还是用于做监控系统方案。它收集数据也是采用推模式(Push)。在展示层,InfluxDB也是自带WebUI,也可以与Grafana集成。
以上,就是对微服务架构中「 监控系统」的一些思考。
【本文作者】
王奎:不止思考的技术人,一名驻扎在武汉互联网的程序员老兵。
推荐阅读
(点击标题可跳转阅读)
看完本文有收获?请分享给更多人
关注「Linux 爱好者」加星标,提升Linux技能
好文章,我在看❤️
以上是关于微服务治理之监控APM系统监控架构概述的主要内容,如果未能解决你的问题,请参考以下文章