Java缓存面试题——Redis应用
Posted 叫我二蛋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java缓存面试题——Redis应用相关的知识,希望对你有一定的参考价值。
文章目录
- 1、为什么要使用Redis做缓存?
- 2、为什么Redis单线程模型效率也能那么高?
- 3、Redis6.0为什么要引入多线程呢?
- 4、Redis常见数据结构以及使用场景
- 5、pipeline有什么好处,为什么要用 pipeline?
- 6、Redis官方为什么不提供 Windows版本?
- 7、Redis 持久化方式有哪些?以及有什么区别?
- 8、什么是Redis事务?原理是什么?
- 9、如何在100个亿URL中快速判断某URL是否存在?
- 10、Redis的数据结构组织?
- 11、渐进式rehash是什么?
1、为什么要使用Redis做缓存?
缓存的好处
使用缓存的目的就是提升读写性能。而实际业务场景下,更多的是为了提升读性能,带来更高的并发量。
Redis的好处
- 读取速度快,单机轻松10W+并发。
- 支持多种数据结构,包括字符串、列表、集合、有序集合、哈希等
- 拥有其他丰富的功能,主从复制、集群、数据持久化等
- 可以实现其他功能,消息队列、分布式锁等
2、为什么Redis单线程模型效率也能那么高?
- C语言实现,效率高:C语言程序运行时要比其他语言编写的程序快得多,因为它“离底层机器很近”
- 单线程的优势:使用了单线程后可以省去多线程的CPU上下文会切换的时间,也不用去考虑锁导致的性能消耗等问题,可维护性高
- Pipeline:Redis主要受限于内存和网络,几乎不会占用太多CPU。利用pipeline操作,减少命令在网络上的传输时间,将多次网络IO缩减为一次网络IO
- 存储实现优化:Redis的基础数据结构每一种至少有2种及2种以上的实现,在不同的大小或长度下选用适合的数据类型,达到极致的存储效率,从而提高写入和读取速度
3、Redis6.0为什么要引入多线程呢?
多线程只是针对IO线程,执行命令还是单线程。
Redis服务器可以处理80,000到100,000QPS,对于80%的公司来说,单线程的Redis已经足够使用了。但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的QPS。所以Redis作者在6.0引入了多线程,性能提升至少一倍以上。当然集群方案也可以解决更大QPS的问题,但是集群方案还是有一些问题的:
- 常见集群方案是对数据进行分区并采用多个服务器,但该方案有非常大的缺点,例如要管理的Redis服务器太多,维护代价大
- 某些适用于单个Redis服务器的命令不适用于数据分区
- 数据分区无法解决热点读/写问题;数据倾斜、重新分配变得更加复杂等等
4、Redis常见数据结构以及使用场景
字符串(String)
使用场景
- 计数:使用Redis 作为计数的基础工具,它可以实现快速计数、查询缓存的功能,同时数据可以异步落地到其他数据源
- 共享Session:使用Redis将用户的Session进行集中管理,避免在访问分布式服务时Session不存在导致重新登录
- 限速:短信接口不被频繁访问,例如一分钟不能超过5次
哈希(Hash)
Java里提供了HashMap,Redis中也有类似的数据结构,就是哈希类型。但是要注意,哈希类型中的映射关系叫作field-value,注意这里的value是指field对应的值,不是键对应的值。
使用场景
哈希类型比较适宜存放对象类型的数据,我们可以比较下,如果数据库中表记录user为:
| id | name | age |
|---|---|---|
| 1 | test1 | 18 |
| 2 | test2 | 20 |
使用String类型
set user:1 "id":1,"name":"test1","age":18;
优点:简单直观,每个键对应一个值
缺点:键数过多,占用内存多,用户信息过于分散
使用hash类型
hmset user:1 name test1 age 18
hmset user:2 name test2 age 20
优点:简单直观,使用合理可减少内存空间消耗
列表(list)
列表( list)类型是用来存储多个有序的字符串,a、b、c、c、b四个元素从左到右组成了一个有序的列表,列表中的每个字符串称为元素(element),一个列表最多可以存储(2^32-1)个元素(4294967295)。

使用场景
- 每个用户有属于自己的文章列表,需要分页展示文章列表。
- 消息队列,Redis的lpush+rpop命令组合即可实现阻塞队列。
集合(set)

集合( set)类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。
使用场景
集合类型比较典型的使用场景是标签(tag)。例如一个用户可能对娱乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共同喜好的标签,这些数据对于用户体验以及增强用户黏度比较重要。
除此之外,集合还可以通过生成随机数进行比如抽奖活动,以及社交图谱等等。
有序集合(ZSET)
有序集合给每个元素设置一个分数(score)作为排序的依据。提供了获取指定分数和元素范围查询、计算成员排名等功能,合理的利用有序集合,能帮助我们在实际开发中解决很多问题。
适合场景
- 有序集合比较典型的使用场景就是排行榜系统。例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。
5、pipeline有什么好处,为什么要用 pipeline?
Redis客户端执行一条命令分为如下4个部分:1)发送命令2)命令排队3)命令执行4)返回结果。

其中1和4花费的时间称为Round Trip Time (RTT,往返时间),也就是数据在网络上传输的时间,占用了绝大多的时间。
举个例子:Redis的客户端和服务端两地直线距离约为800公里,那么1次RTT时间=800 x2/ ( 300000×2/3 ) =8毫秒,(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3 )。而Redis命令真正执行的时间通常在微秒(1000微妙=1毫秒)级别,所以才会有Redis性能瓶颈是网络这样的说法。
Pipeline(流水线)机制能改善上面这类问题,它能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端。

非Pipeline和Pipeline执行10000次set操作的效果,在执行时间上的比对如下:

差距有100多倍,可以得到如下两个结论:
- Pipeline减少了网络的开销,执行速度一般比逐条执行要快。
- 客户端和服务端的网络延时越大,Pipeline的效果越明显。
6、Redis官方为什么不提供 Windows版本?
目前Linux版本已经相当稳定,而且用户量很大,开发windows版本,反而会带来兼容性等问题。
7、Redis 持久化方式有哪些?以及有什么区别?
Redis 提供两种持久化机制 RDB 和 AOF 机制
RDB
RDB(Redis DataBase)持久化是把当前进程数据生成快照保存到硬盘的过程。所谓内存快照,就是指内存中的数据在某一个时刻的状态记录。
优点:
- 只有一个文件 dump.rdb,方便持久化。
- 容灾性好,一个文件可以保存到安全的磁盘。
- 相对于数据集大时,比AOF的启动效率更高。
缺点:
- 数据安全性低。 RDB是间隔一段时间进行持久化,如果持久化之间Redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候。
AOF
AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
缺点:
(1) AOF 文件比 RDB 文件大,且恢复速度慢。
(2)数据集大的时候,比 RDB 启动效率低。
8、什么是Redis事务?原理是什么?
Redis 中的事务是一组命令的集合,将一组需要一起执行的命令放到multi和exec两个命令之间。multi 命令代表事务开始,exec命令代表事务结束。它可以保证一次执行多个命令,每个事务是一个单独的隔离操作,事务中的所有命令都会序列化、按顺序地执行。
但是要注意Redis的事务功能很弱。在事务回滚机制上,Redis只能对基本的语法错误进行判断。
如下,当语法命令错误时,会造成整个事务无法执行,事务内的操作都没有执行:

如下,当命令错误时,虽然有异常提示,但是事务执行成功。

9、如何在100个亿URL中快速判断某URL是否存在?
传统数据结构HashMap
可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率极高。
但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,举个例子如果一个1000万个int类型,会占据HashMap多少空间呢?1.2个G。实际上,1000万个int型,只需要40M左右空间,占比3%,1000万个Integer,需要161M左右空间,占比13.3%。可见一旦值很多例如上亿的时候,那HashMap 占据的内存大小就变得很可观了。
如果整个网页黑名单系统包含100亿个网页URL,在数据库查找是很费时的,并且如果每个URL空间为64B,那么需要内存为640GB,一般的服务器很难达到这个需求。
布隆过滤器
1970 年布隆提出了一种布隆过滤器的算法,用来判断一个元素是否在一个集合中。这种算法由一个二进制数组和一个 Hash 算法组成。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器广泛应用于网页黑名单系统、垃圾邮件过滤系统、爬虫网址判重系统等,Google 著名的分布式数据库 Bigtable 使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数,Google Chrome浏览器使用了布隆过滤器加速安全浏览服务。
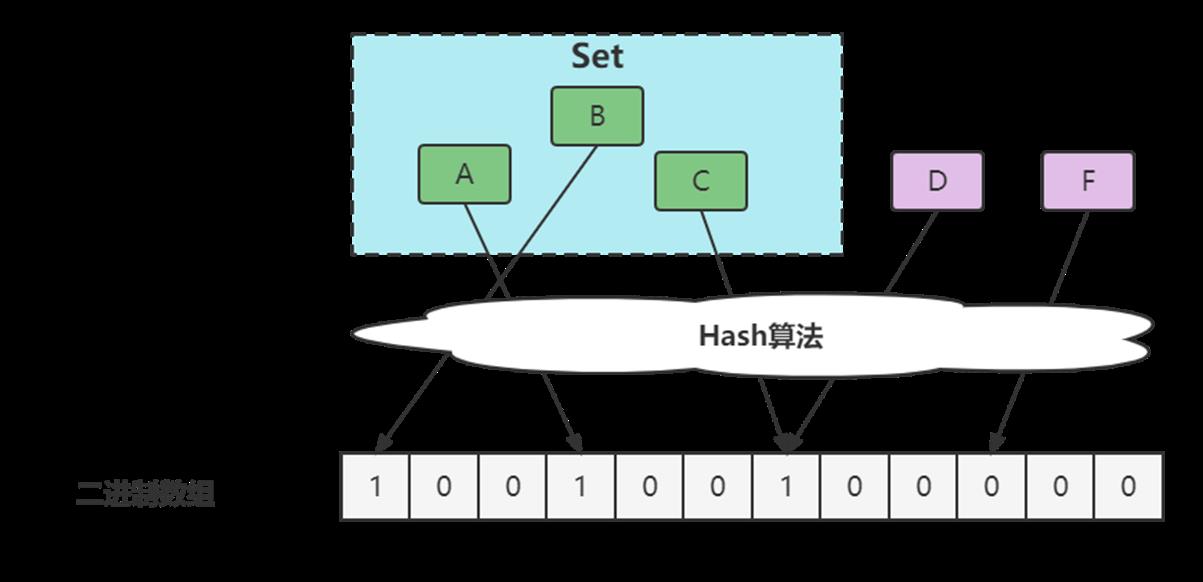
布隆过滤器的误判问题
- 通过hash计算在数组上,因为hash冲突实际上可能不在,如下图中的D。
- 通过hash计算在数组上,因为数组中已存在,不能确定在不在,如下图中的C。
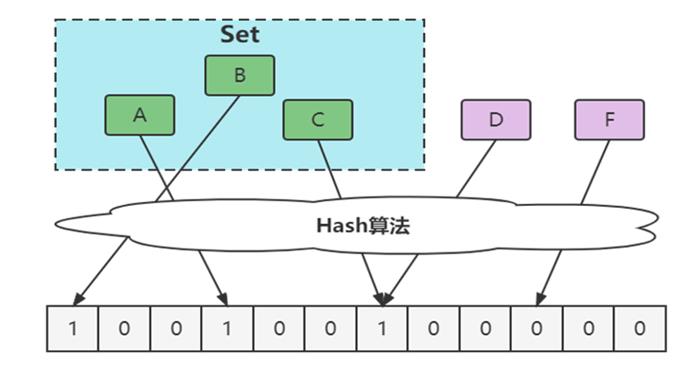
优化方案
- 增大数组(预估适合值)
- 增加hash函数,通过两次Hash算法,都为1时确定为存在。
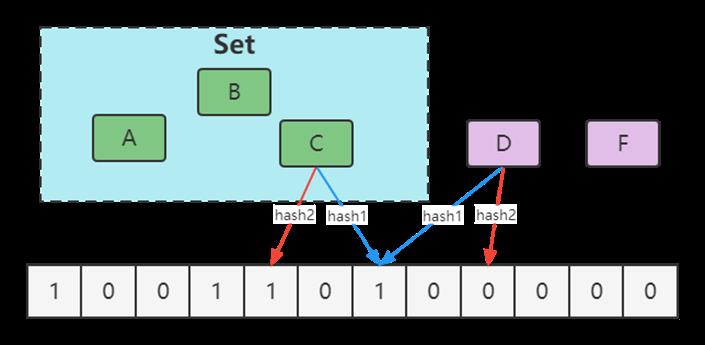
10、Redis的数据结构组织?
为了实现从键到值的快速访问,Redis 使用了一个全局哈希表来保存所有键值对。一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,我们常说,一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据。

哈希表的最大好处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对。但是当往 Redis 中写入大量数据后,哈希表的冲突问题和 rehash 可能带来的操作阻塞,这里的哈希冲突,两个 key 的哈希值和哈希桶计算对应关系时,正好落在了同一个哈希桶中。
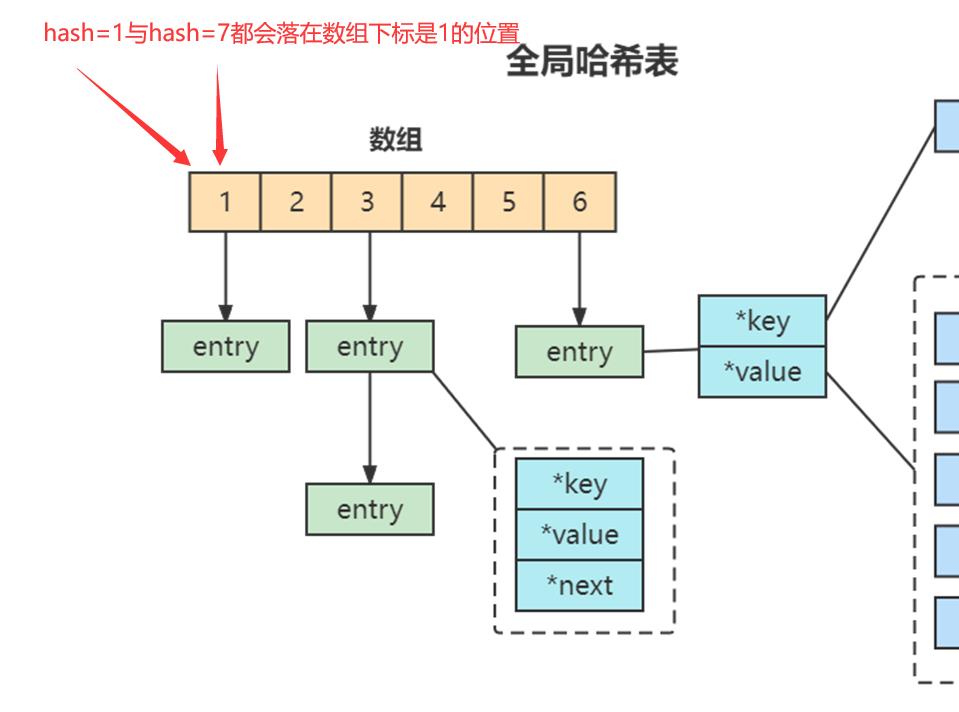
Redis 解决哈希冲突的方式,就是链式哈希。链式哈希也很容易理解,就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
11、渐进式rehash是什么?
Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash。
- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中
- 释放哈希表 1 的空间
在上面的第二步涉及大量的数据拷贝,如果一次性把哈希表 1 中的数据都迁移完,会造成 Redis 线程阻塞。在Redis 开始执行 rehash,Redis仍然正常处理客户端请求,但是要加入一个额外的处理:
- 处理第1个请求时,把哈希表 1中的第1个索引位置上的所有 entries 拷贝到哈希表 2 中
- 处理第2个请求时,把哈希表 1中的第2个索引位置上的所有 entries 拷贝到哈希表 2 中
如此循环,直到把所有的索引位置的数据都拷贝到哈希表 2 中。这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问。

高频面试题-如何避免Redis中缓存穿透缓存雪崩问题?
Redis,因为其速度快等各方面的原因,被开发人员一直应用于企业级开发。
而一旦开始使用Redis,就必然要考虑的问题就当属缓存穿透、缓存雪崩的问题了,这也是面试过程中很容易问到的点了,下面我们就来聊一下这些吧。
1. 什么是缓存穿透?
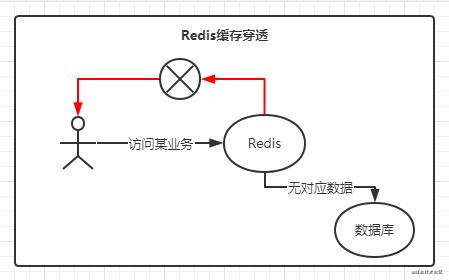
缓存穿透是指当查询一个不存在的数据,由于无法命中对应的值,就会一直需要去数据库中查询;所以这个时候Redis并没有起到减少查询的次数,失去了使用Redis的初心,反而性能方面有了更大的消耗,就会造成整体的性能下降。
2. 如何解决缓存穿透问题?
一句话答案:给没有命中的key值设置‘空值’。
虽然无法命中对应的值,但是我们依然要给对应的key设置空值。
这样,我们就又可以降低直接访问数据库的次数,从而一定程度上提高了系统性能。
如果你觉得自己学习效率低,缺乏正确的指导,可以加入资源丰富,学习氛围浓厚的技术圈一起学习交流吧!
[Java架构群]
群内有许多来自一线的技术大牛,也有在小厂或外包公司奋斗的码农,我们致力打造一个平等,高质量的JAVA交流圈子,不一定能短期就让每个人的技术突飞猛进,但从长远来说,眼光,格局,长远发展的方向才是最重要的。
3. 什么是缓存雪崩?
雪崩时,没有一片雪花是无辜的。
缓存雪崩是指当一批缓存数据均设置了相同的过期时间时,会导致一批缓存数据同一时间失效,届时就会存在大批的请求同时去访问数据库,会造成数据库的瞬时压力过大,造成雪崩。
4. 如何解决缓存雪崩问题?
一句话答案:给缓存数据的key设置不同的过期时间
缓存雪崩问题就是同一时间缓存过期问题,所以只需要给缓存数据设置不同的过期时间即可。
由于系统内部业务的限制,可以在某一个区间内取随机值,如:30分钟-60分钟之间的任意值;这样即便会存在相同过期时间,也不会很多。
当然了,如果你系统业务缓存量级比较大,加大区间就可以了。
最后
给大家分享一篇一线开发大牛整理的java高并发核心编程神仙文档,里面主要包含的知识点有:多线程、线程池、内置锁、JMM、CAS、JUC、高并发设计模式、Java异步回调、CompletableFuture类等。
码字不易,如果觉得本篇文章对你有用的话,请给我一键三连!关注作者,后续会有更多的干货分享,请持续关注!
以上是关于Java缓存面试题——Redis应用的主要内容,如果未能解决你的问题,请参考以下文章