详述numpy中的np.random.rand()np.random.randn()np.random.randint()np.random.uniform()函数的用法
Posted 术业还未专攻
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详述numpy中的np.random.rand()np.random.randn()np.random.randint()np.random.uniform()函数的用法相关的知识,希望对你有一定的参考价值。
目录
(三)np.random.randint(low,high,size,dtype)
(四)np.random.uniform(low,high,size)
引言:在机器学习还有深度学习中,经常会用到这几个函数,为了便于以后熟练使用,现在对这几个函数进行总结。
(一)np.random.rand()
该函数括号内的参数指定的是返回结果的形状,如果不指定,那么生成的是一个浮点型的数;如果指定一个数,那么生成的是一个numpy.ndarray类型的数组;如果指定两个数字,那么生成的是一个二维的numpy.ndarray类型的数组。如果是两个以上的数组,那么返回的维度就和指定的参数的数量个数一样。其返回结果中的每一个元素是服从0~1均匀分布的随机样本值,也就是返回的结果中的每一个元素值在0-1之间。
举例说明:
import numpy as np
mat = np.random.rand()
print(mat)
print(type(mat))
mat = np.random.rand(2)
print(mat)
print(type(mat))
mat = np.random.rand(3, 2)
print(mat)
print(type(mat))结果为:注意我用红框框起来的一组对应两个print输出,可对应程序看结果。

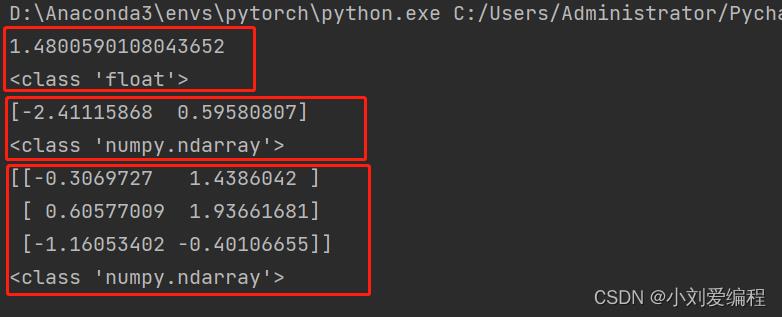
(二)np.random.randn()
该函数和rand()函数比较类似,只不过运用该函数之后返回的结果是服从均值为0,方差为1的标准正态分布,而不是局限在0-1之间,也可以为负值,因为标准正态分布的曲线是关于x轴对阵的。其括号内的参数如果不指定,那么生成的是一个浮点型的数;如果指定一个数,那么生成的是一个numpy.ndarray类型的数组;如果指定两个数字,那么生成的是一个二维的numpy.ndarray类型的数组。和rand()相比,除了元素值不一样,其他的性质是一样的。
举例说明:
import numpy as np
mat = np.random.randn()
print(mat)
print(type(mat))
mat = np.random.randn(2)
print(mat)
print(type(mat))
mat = np.random.randn(3, 2)
print(mat)
print(type(mat))结果为:
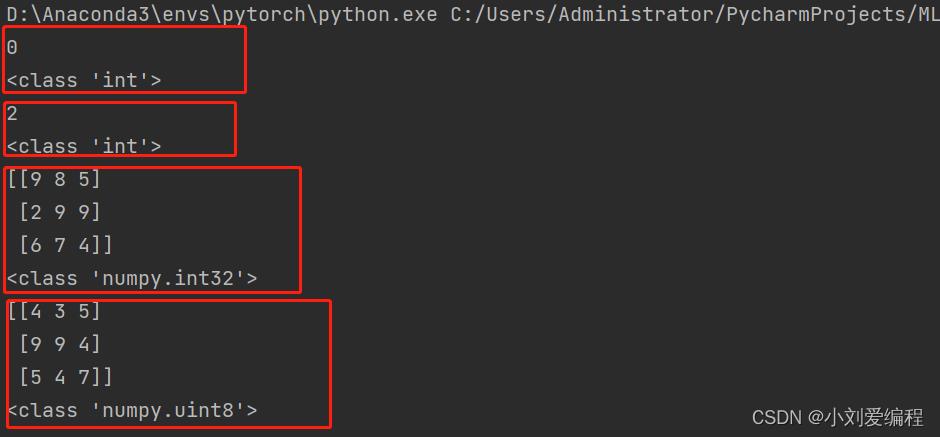
(三)np.random.randint(low,high,size,dtype)
该函数中包含了几个参数,其具体含义为:
low:生成的元素值的最小值,即下限,如果没有指定high这个参数,则low为生成的元素值的最大值。
high:生成的元素值的最大值,即上限。
size:指定生成元素值的形状,也就是数组维度的大小。
dtype:指定生成的元素值的类型,如果不指定,默认为整数型
返回结果:返回值是一个大小为size的数组,如果指定了low和high这两个参数,那么生成的元素值的范围为[low,high),不包括high;如果不指定high这个参数,则生成的元素值的范围为[0,low)。如果不指定size这个参数,那么生成的元素值的个数只有一个。
举例说明:
import numpy as np
# 指定一个参数low
mat = np.random.randint(low=1)
print(mat)
print(type(mat))
# 指定low和high,生成一个[low,high)的元素值
mat = np.random.randint(low=1, high=5)
print(mat)
print(type(mat))
# 指定size大小,生成一个三行三列的二维数组,元素个数为3x3=9个
mat = np.random.randint(low=2, high=10, size=(3, 3))
print(mat)
# 查看默认元素值的类型
print(type(mat[0][0]))
mat = np.random.randint(low=2, high=10, size=(3, 3), dtype=np.uint8)
print(mat)
print(type(mat[0][0]))
结果为:
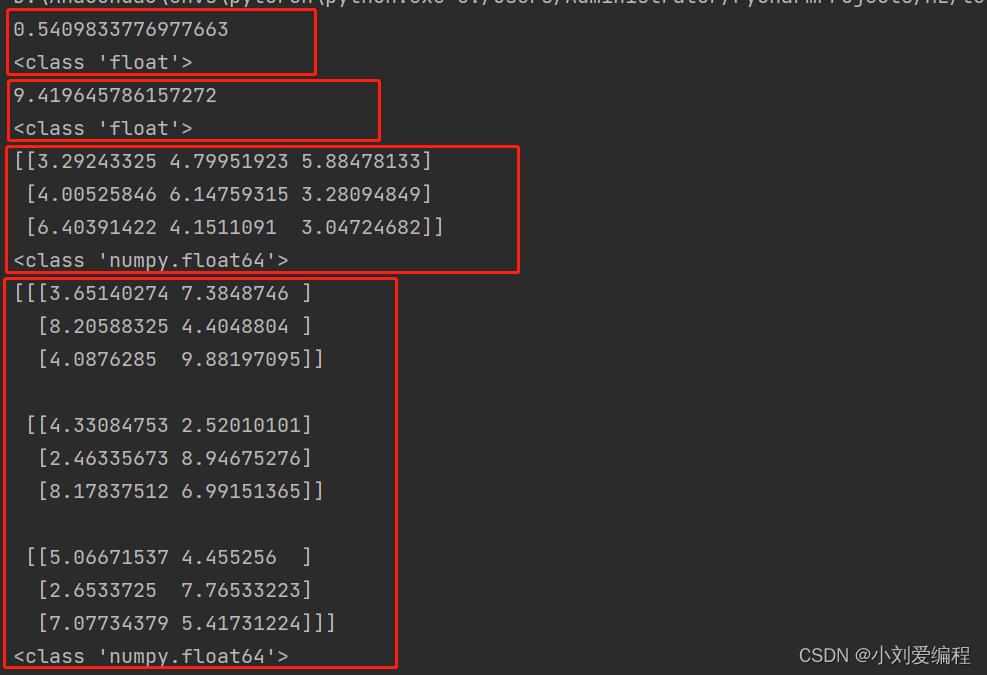
(四)np.random.uniform(low,high,size)
参数说明:
low:生成元素值的下界,float类型,默认值为0
high:生成元素值的上界,float类型,默认值为1
size:输出样本的数目,可以指定一个值,也可指指定大于等于两个值
返回对象:ndarray类型,形状为size中的数值指定,其元素个数为size指定的参数的乘积
我们前面已经说过了rand()这个函数,它返回的元素值是服从0-1的均匀分布,那如果不想要生成的是0-1范围内的均匀分布,想要其它范围内的均匀分布怎么办呢。
uniform()实现了这个功能,它可以生成服从指定范围内的均匀分布的元素。其返回值的元素类型为浮点型。需注意的是元素值的范围包含low,不包含high。
举例说明:
import numpy as np
# 指定一个参数low
mat = np.random.uniform()
print(mat)
print(type(mat))
# 指定low和high,生成一个[low,high)的元素值
mat = np.random.uniform(low=5, high=10)
print(mat)
print(type(mat))
# 指定size大小,生成一个三行三列的二维数组,元素个数为3x3=9个
mat = np.random.uniform(low=2, high=10, size=(3, 3))
print(mat)
# 查看默认元素值的类型
print(type(mat[0][0]))
mat = np.random.uniform(low=2, high=10, size=(3, 3, 2))
print(mat)
print(type(mat[0][0][0]))
结果为:
总结:以上就是常用的随机数生成函数,具体用哪一个,可根据自己需求,想要生成什么随机数,那就使用什么样的函数。
编写不易,转载请注明出处!
Numpy学习—np.random.randn()np.random.rand()和np.random.randint()
展开
在机器学习和神经网络中,常常会利用Numpy库中的随机函数来生产随机数,比如随机初始化神经网络中的参数权重W(备注:W是不能全部初始化为0的,这样会引起symmetry breaking problem,这样隐藏层设置多个神经元就没有任何意义了)。
在Numpy库中,常用使用np.random.rand()、np.random.randn()和np.random.randint()随机函数。这几个函数的区别如下:
(1)np.random.randn()函数
语法:
np.random.randn(d0,d1,d2……dn)
1)当函数括号内没有参数时,则返回一个浮点数;
2)当函数括号内有一个参数时,则返回秩为1的数组,不能表示向量和矩阵;
3)当函数括号内有两个及以上参数时,则返回对应维度的数组,能表示向量或矩阵;
4)np.random.standard_normal()函数与np.random.randn()类似,但是np.random.standard_normal()的输入参数为元组(tuple).
5)np.random.randn()的输入通常为整数,但是如果为浮点数,则会自动直接截断转换为整数。
作用:
通过本函数可以返回一个或一组服从标准正态分布的随机样本值。
特点:
标准正态分布是以0为均数、以1为标准差的正态分布,记为N(0,1)。对应的正态分布曲线如下所示,即
标准正态分布曲线下面积分布规律是:
在-1.96~+1.96范围内曲线下的面积等于0.9500(即取值在这个范围的概率为95%),在-2.58~+2.58范围内曲线下面积为0.9900(即取值在这个范围的概率为99%).
因此,由 np.random.randn()函数所产生的随机样本基本上取值主要在-1.96~+1.96之间,当然也不排除存在较大值的情形,只是概率较小而已。
用例:
应用场景:
在神经网络构建中,权重参数W通常采用该函数进行初始化,当然需要注意的是,通常会在生成的矩阵后面乘以小数,比如0.01,目的是为了提高梯度下降算法的收敛速度。
W = np.random.randn(2,2)*0.01
(2) np.random.rand()函数
语法:
np.random.rand(d0,d1,d2……dn)
注:使用方法与np.random.randn()函数相同
作用:
通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
应用:在深度学习的Dropout正则化方法中,可以用于生成dropout随机向量(dl),例如(keep_prob表示保留神经元的比例):dl = np.random.rand(al.shape[0],al.shape[1]) < keep_prob
用例:
(3) np.random.randint()函数
语法:
numpy.random.randint(low, high=None, size=None, dtype=’l’)
输入:
low—–为最小值
high—-为最大值
size—–为数组维度大小
dtype—为数据类型,默认的数据类型是np.int。
返回值:
返回随机整数或整型数组,范围区间为[low,high),包含low,不包含high;
high没有填写时,默认生成随机数的范围是[0,low)
用例:
————————————————
版权声明:本文为CSDN博主「o_Eagle_o」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zenghaitao0128/java/article/details/78556535
以上是关于详述numpy中的np.random.rand()np.random.randn()np.random.randint()np.random.uniform()函数的用法的主要内容,如果未能解决你的问题,请参考以下文章
Numpy学习—np.random.randn()np.random.rand()和np.random.randint()