联邦学习论文阅读三:ChainFL
Posted 一步一个脚印ッ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习论文阅读三:ChainFL相关的知识,希望对你有一定的参考价值。
联邦学习论文阅读三:ChainFL
Secure and Efficient Federated Learning Through Layering and Sharding Blockchain
论文地址:https://arxiv.org/abs/2104.13130
本篇文章以课程汇报PPT的形式进行展示,如需获取博主PPT评论区留言。
文章目录
1. Introduction
1.1 问题来源
区块链被引入到FL系统中,将范式转变为去中心化的方式,从而进一步提高了系统的安全性和学习可靠性。遗憾的是,由于资源消耗巨大、事务吞吐量有限、通信复杂度高,区块链系统的传统共识机制和架构难以处理大规模的FL任务。
1.2 问题论述
- 传统FL在无信任边缘计算环境下的一些安全和效率问题,具体表现为:
- Security Issues:传统的FL系统依赖于一个中央聚合器来编排整个训练过程。因此,它很容易受到单点故障(SPOF)和有针对性的攻击,导致服务瘫痪。此外,中央聚合器在每一轮选择少数相同的物联网设备的潜在偏差将损害全局模型的准确性。此外,传统的FL无法处理模型在传输和学习过程中的信任问题,例如恶意IoT设备产生的有毒模型。
- Efficiency Issues:大多数FL系统以同步方式运行,其中中央服务器等待所有参与物联网设备上传本地模型,然后在每一轮更新。因此,离散点的存在不可避免地会降低算法的收敛速度,这些离散点是指完成一次训练迭代所需时间较长的设备。另一方面,在异步训练中,由于从全局模型的旧版本(称为陈旧模型)训练的模型可能会在更新中使用,因此全局模型将是不稳定的。
- 引入区块链后的挑战
- 高计算成本,区块链的PoW共识带来的高计算成本。
- 有限的可伸缩性,PoW共识由于密集的哈希计算导致事务吞吐量较低,无法随着区块链节点的增加扩展其事务处理效率。此外,PBFT (Practical Byzantine Fault Tolerance)协议[17]由于通信交换频繁,其吞吐量受到网络带宽的限制。
- 巨大的存储要求,区块链节点存储有限。
- 掉队者,大多数区块链支持的FL系统,如BlockFL、PIRATE和DeepChain以同步方式处理。因此,掉队者会降低训练效率,这与传统的FL类似。目前,基于区块链的异步训练研究较少,更不用说对陈旧模型的检测了。
1.3 本文贡献
- 作者提出了一种由分级区块链驱动的新型FL系统ChainFL,旨在为大规模物联网网络提供安全有效的FL解决方案。作者设计了一个基于raft的区块链分片体系结构来提高可伸缩性,并设计了一个改进的基于daga的主链来实现跨分片交互。
- 定义了ChainFL执行FL任务的操作流程和交互规则。为了提高学习效率,ChainFL将同步和异步训练相结合,以减轻掉队者的拖累。基于改进的DAG共识设计了虚拟修剪机制,消除了异常模型的影响。
- 建立了基于Hyperledger Fabric的分片网络原型,实现了ChainFL的子链层,开发了基于dag的区块链实现了ChainFL的主链层,实现了跨层交互。原型采用链下存储方案,降低了两层区块链节点的存储需求。
- 广泛的评估结果表明,与FedAvg和AsynFL相比,ChainFL对于cnn和rnn提供了可接受的,有时更好的收敛速度(高达14%),并增强了FL系统的鲁棒性(最高可达3倍)。


2. RELATED WORKS
该章节介绍了论文使用的相关技术,主要是一些区块链的相关技术,感兴趣的可以去看论文原文,接下来的文章我将按课程汇报的方式给大家呈现,想获取本人的课程汇报PPT请在评论区留言。
- 区块链简介


 - 联邦学习简介:数据存储在本地,数据在本地训练,将训练后的参数或者梯度上传到中心服务器,由中心服务器进行参数聚合后,将聚合后的参数下发到本地,继续进行下一轮训练,实现了数据不出界,保证了各方隐私安全,解决数据孤岛问题,但目前实际上已经有实验证明参数也会泄露隐私,因此对参数还需要进一步处理。
- 联邦学习简介:数据存储在本地,数据在本地训练,将训练后的参数或者梯度上传到中心服务器,由中心服务器进行参数聚合后,将聚合后的参数下发到本地,继续进行下一轮训练,实现了数据不出界,保证了各方隐私安全,解决数据孤岛问题,但目前实际上已经有实验证明参数也会泄露隐私,因此对参数还需要进一步处理。
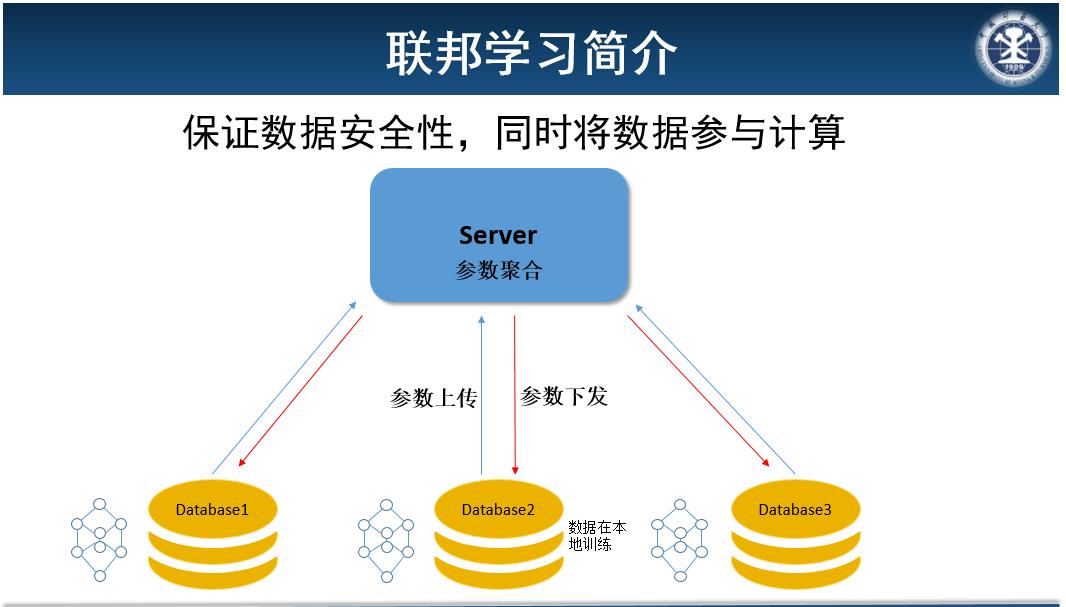 本文关注的是横向联邦学习
本文关注的是横向联邦学习
 - 本文结构
- 本文结构
3. OUR PROPOSED CHAINFL SYSTEM
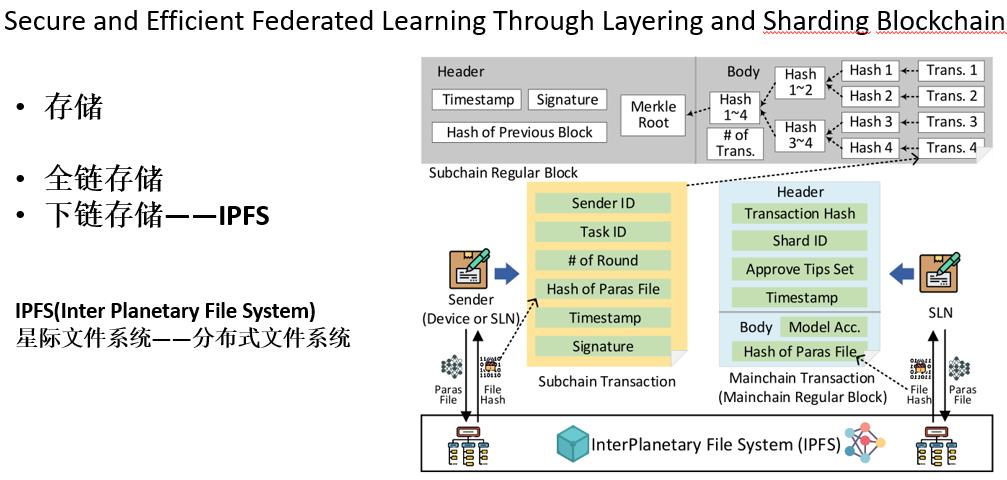
为了解决上述问题,本文提出了一个两层区块链驱动的链层框架(ChainsFL),该框架由多个子链网络(子链层)和一个基于直接无环图(DAG)的主链(主链层)组成,子链层为小范围的信息交换限制了每个分片的规模,主链层允许每个分片并行和异步地共享和验证学习模型,提高了跨分片验证的效率。
- 1)设备层:该层由参与FL任务的设备组成,如手机、车辆、智能家电等。FL中这些设备的职责是维护本地收集的数据,然后训练本地模型。此外,设备需要将更新的本地模型打包到带有一些附加信息(如授权信息和时间戳)的事务中,然后将事务提交给子链。
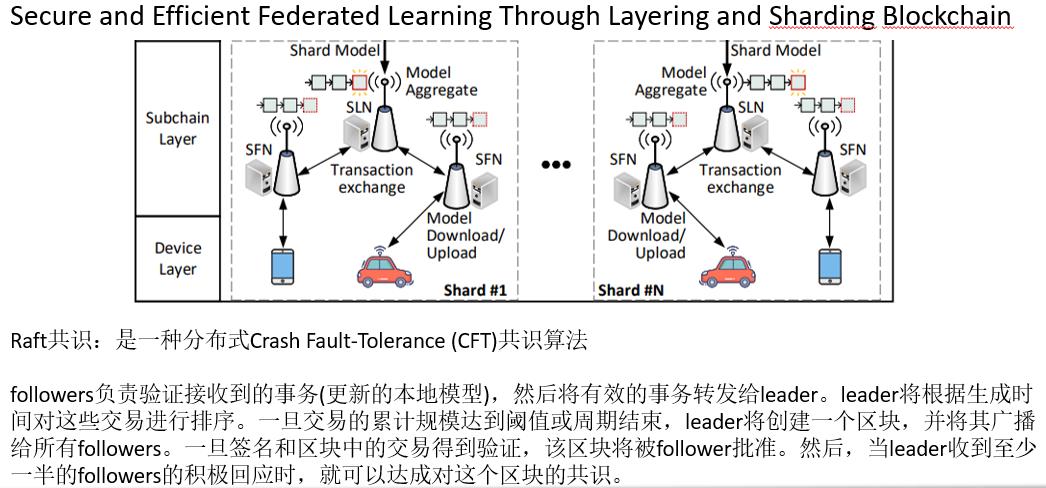
- 2)子链层:每个分片中部署的子链是独立的,负责协调分片中的设备同步完成训练任务。每个子链中使用的Raft共识。考虑到Raft协议计算复杂度较低,通过分片减少leader的事务处理量,有效消除了其原有的瓶颈(即单个节点性能限制的吞吐量)。
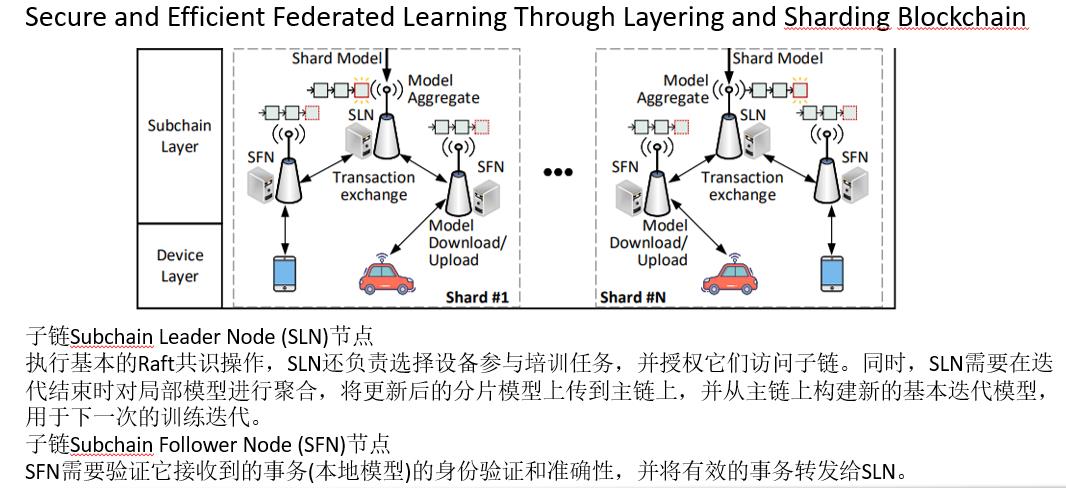
- 子链的Raft共识
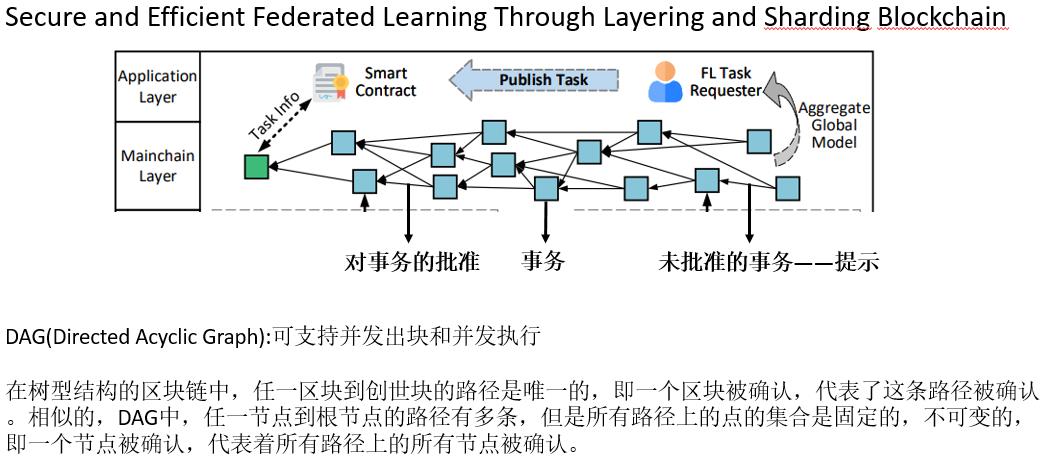
- 3)主链层:主链采用基于DAG架构的异步共识机制,顶点表示事务,边表示对另一个事务的批准。主链网络中的每笔交易都包含一个分片训练的模型。未被任何其他交易批准的交易被称为提示。与其他区块链系统不同的是,由于图的结构,主链不依赖单链作为单个可信度来源。因此,能够内生地容忍分叉的主链能够异步地处理事务。此外,主链网络中的每个边缘节点都维护一个可以用来构建DAG的本地分类账。
- 4)应用层:通过智能合约触发FL任务。FL任务请求者通过签署智能合约来发布任务,声明其任务需求和完成任务的条件。相应的,参与任务的设备和边缘节点在任务完成时将获得一定的奖励。
 - 主链DAG共识
- 主链DAG共识

- 存储:
- 数据存储在链下数据库中,数据的hash存入链上。
- 是一个点对点的分布式系统文档分布式存储,IPFS的企业愿景是搭建一个全球的分布式系统互联网,用于取代传统式去中心化的网络服务器方式,全部的IPFS连接点构成一个分布式系统互联网,每一个连接点都能够储存文档。客户能够从IPFS搭建的互联网中以DHT(DistributedHashTable,分布式系统哈希表)的方法获得文档。
4. IMPLEMENTATION
实验细节详见论文原文。
5. 代码
Ditto论文阅读笔记
《Ditto: Fair and Robust Federated Learning Through Personalization》这篇文章的作者之一Virginia Smith于2017年提出了Federated Multi-Task Learning用于实现个性化联邦学习。这篇文章提出的Ditto算法也是基于联邦多任务学习的个性化方法,目的在于同时提升联邦学习中的公平性和鲁棒性。
FL公平性和鲁棒性的定义
公平性:不同设备的本地模型具有相同性能
鲁棒性:具体指拜占庭鲁棒性,即恶意节点可以给服务器发送任意更新来破坏训练阶段。常见的三类比较常见的训练阶段攻击:

存在的问题:
之前的研究只单独考虑公平性或者鲁棒性,并且提高公平性会以牺牲鲁棒性为代价。而提高鲁棒性的方法可能会过滤掉一些罕见但又有价值的更新参数,从而降低了不公平。简单讲就是目前还没有一种有效方法能同时提升公平性和鲁棒性。
这篇文章的作者提出数据异构性是导致这一问题的而主要原因,并提出用应用多任务学习(多任务学习内在原理可以很自然的同时提升公平性和鲁棒性)
Ditto
Ditto的全局目标函数
Ditto的全局目标是对参与训练的本地模型的聚合,可以应用目前所有的聚合方法,如FedAvg,FedProx等。式中
F
k
F_k
Fk(w)是本地目标函数,G(·)是聚合函数。
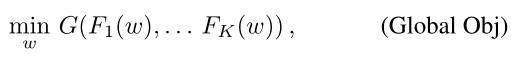
Ditto的本地目标函数
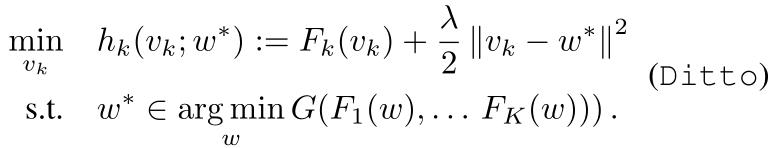
Ditto新定义的本地目标函数其实就是在原始的本地目标函数的基础上加上一个正则项,其中
v
k
v_k
vk是设备k的个性化模型,
w
∗
w^*
w∗是全局模型。实际上文章的重点就在于这个超参数λ,也是λ实现了能够同时提升鲁棒性和公平性。具体为什么可以看后面的分析。
Ditto算法框架
Ditto的伪代码如Algorithm 1所示。需要注意的是设备训练的本地模型是通过加上正则化项的目标函数,而传给服务器的更新参数则是不加正则化项的。

正如前面说的Sever aggregates可以应用目前任何聚合算法,文章以FedAvg为例给出了伪代码如Algorithm 2所示

粉色标记部分就是文章所做的主要研究,可以看到,除了聚合函数可以随意选择外,主要的特点在于往加入了原先的本地目标函数加上了一个正则化项,为什么这么简单就能同时满足鲁棒性和公平性呢?
正则化项的作用
由于恶意节点会破环全局模型的训练,所以单纯将全局模型应用于各异构性设备的效果可能会非常糟糕;而良性节点单纯依靠本地的少量数据又无法训练出较好的模型。Ditto通过超参数λ在个性化模型和全局模型之间做trade-off。λ越大,个性化模型 v k v_k vk越接近全局模型w,λ越小,个性化模型 v k v_k vk越偏离受毒害的全局模型w。各设备通过调整λ的值在全局模型和本地模型之间找到适合自己的个性化模型。这样就可以同时提升鲁棒性和公平性。
实验
实验设置
数据集使用的是常规的联邦学习数据集,包括图像数据集和文本数据集,模型包括凸模型和非凸模型。

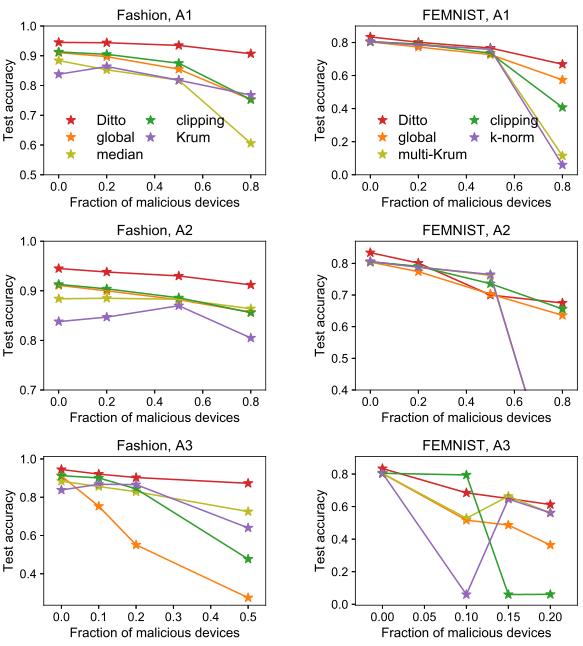
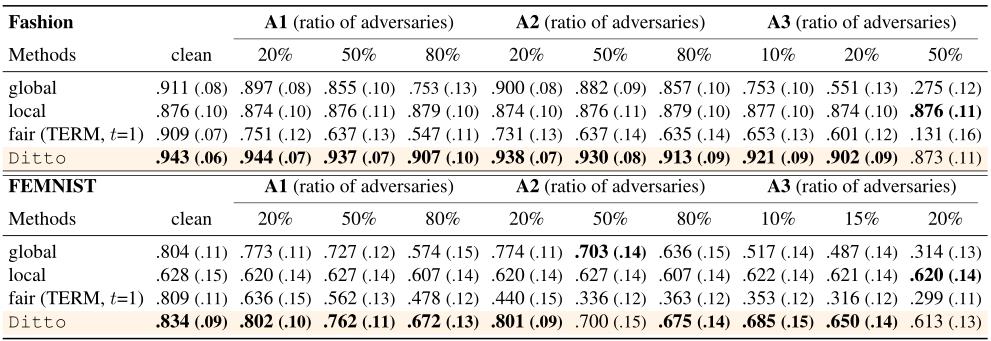
鲁棒性实验
测试Ditto在不同比例的恶意节点下的鲁棒性,比较对象为其他鲁棒性算法。
鲁棒性评价指标:良性节点在测试集的平均准确率
公平性实验
将Ditto与近期提出的公平性联邦学习算法TERM进行实验对比
公平性评价指标:良性节点在测试集的平均准确率
Ditto,FedProx,L2GD
前面总结过FedProx,L2GD这两个算法。这三个算法都是在聚合全局模型的基础上加入一个正则化项
其中FedProx算法是通过γ不等式动态控制每个节点在每轮通信下的更新次数;
L2GD算法是通过概率p控制节点训练/服务器聚合,并且分两次进行GD更新,一次是在节点训练的时候,一次是在服务器聚合后;
Ditto算法是通过在原处的本地目标函数中加上一个正则项,再继续优化本地模型,最后传给服务器的是没有加正则项的优化参数更新,实现了Local和Global两不耽误。
此外,FedProx和L2GD算法正则项的参数是固定的,Ditto的正则参数是动态调整的。正则项中节点模型减去的项也有所差别,FedProx是减去上一轮的全局模型,L2GD减去所有节点模型的平均值,Ditto减去全局最优模型。
参考
https://zhuanlan.zhihu.com/p/372772592
https://zhuanlan.zhihu.com/p/375761132
以上是关于联邦学习论文阅读三:ChainFL的主要内容,如果未能解决你的问题,请参考以下文章