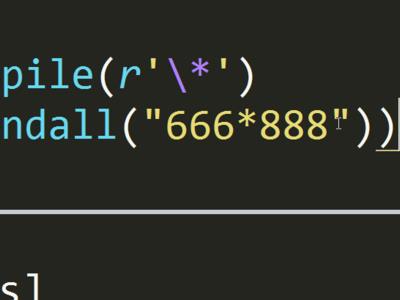
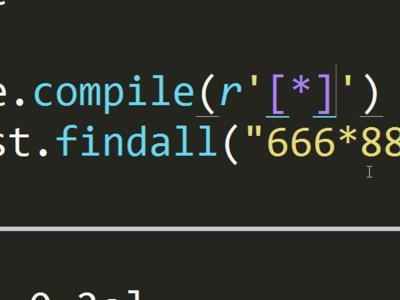

执行数据库查询时,有完整查询和模糊查询之分。
一般模糊语句如下:
SELECT 字段 FROM 表 WHERE 某字段 Like 条件
其中关于条件,SQL提供了四种匹配模式:
1、%:表示任意0个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请运用两个百分号(%%)表示。
比如 SELECT * FROM [user] WHERE u_name LIKE ‘%三%‘
将会把u_name为“张三”,“张猫三”、“三脚猫”,“唐三藏”等等有“三”的记录全找出来。
另外,如果须要找出u_name中既有“三”又有“猫”的记录,请运用 and条件
SELECT * FROM [user] WHERE u_name LIKE ‘%三%‘ AND u_name LIKE ‘%猫%‘
若运用 SELECT * FROM [user] WHERE u_name LIKE ‘%三%猫%‘
虽然能搜索出“三脚猫”,但不能搜索出符合条件的“张猫三”。
2、_: 表示任意单个字符。匹配单个任意字符,它常用来限定表达式的字符长度语句:
比如 SELECT * FROM [user] WHERE u_name LIKE ‘_三_‘
只找出“唐三藏”这样u_name为三个字且中间一个字是“三”的;
再比如 SELECT * FROM [user] WHERE u_name LIKE ‘三__‘;
只找出“三脚猫”这样name为三个字且第一个字是“三”的;
3、[ ]:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
比如 SELECT * FROM [user] WHERE u_name LIKE ‘[张李王]三‘
将找出“张三”、“李三”、“王三”(而不是“张李王三”);
如 [ ] 内有一系列字符(01234、abcde之类的)则可略写为“0-4”、“a-e”
SELECT * FROM [user] WHERE u_name LIKE ‘老[1-9]‘
将找出“老1”、“老2”、……、“老9”;
4、[^ ] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
比如 SELECT * FROM [user] WHERE u_name LIKE ‘[^张李王]三‘
将找出不姓“张”、“李”、“王”的“赵三”、“孙三”等;
SELECT * FROM [user] WHERE u_name LIKE ‘老[^1-4]‘;
将排除“老1”到“老4”,寻找“老5”、“老6”、……
5、查询内容包含通配符时
由于通配符的缘故,导致我们查询特殊字符“%”、“_”、“[”的语句不能正常实现,而把特殊字符用“[ ]”括起便可正常查询。据此我们写出以下函数:
function sqlencode(str)
str=replace(str,"[","[[]") ‘此句一定要在最前
str=replace(str,"_","[_]")
str=replace(str,"%","[%]")
sqlencode=str
end function
在查询前将待查字符串先经该函数处理即可。
由MySQL提供的模式匹配的其他类型是使用扩展正则表达式。
当你对这类模式进行匹配测试时,使用REGEXP和NOT REGEXP操作符(或RLIKE和NOT RLIKE,它们是同义词)。
扩展正则表达式的一些字符是:
“.”匹配任何单个的字符。
一个字符类“[...]”匹配在方括号内的任何字符。例如,“[abc]”匹配“a”、“b”或“c”。为了命名字符的一个范围,使用一个“-”。“[a-z]”匹配任何小写字母,而“[0-9]”匹配任何数字。
“ * ”匹配零个或多个在它前面的东西。例如,“x*”匹配任何数量的“x”字符,“[0-9]*”匹配的任何数量的数字,而“.*”匹配任何数量的任何东西。
正则表达式是区分大小写的,但是如果你希望,你能使用一个字符类匹配两种写法。例如,“[aA]”匹配小写或大写的“a”而“[a-zA-Z]”匹配两种写法的任何字母。
如果它出现在被测试值的任何地方,模式就匹配(只要他们匹配整个值,SQL模式匹配)。
为了定位一个模式以便它必须匹配被测试值的开始或结尾,在模式开始处使用“^”或在模式的结尾用“$”。
为了说明扩展正则表达式如何工作,上面所示的LIKE查询在下面使用REGEXP重写:
为了找出以“b”开头的名字,使用“^”匹配名字的开始并且“[bB]”匹配小写或大写的“b”:
mysql> SELECT * FROM pet WHERE name REGEXP "^[bB]";
+--------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+------------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+--------+--------+---------+------+------------+------------+
为了找出以“fy”结尾的名字,使用“$”匹配名字的结尾:
mysql> SELECT * FROM pet WHERE name REGEXP "fy$";
+--------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+-------+
| Fluffy | Harold | cat | f | 1993-02-04 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+--------+--------+---------+------+------------+-------+
为了找出包含一个“w”的名字,使用“[wW]”匹配小写或大写的“w”:
mysql> SELECT * FROM pet WHERE name REGEXP "[wW]";
+----------+-------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+------------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
+----------+-------+---------+------+------------+------------+
既然如果一个正规表达式出现在值的任何地方,其模式匹配了,就不必再先前的查询中在模式的两方面放置一个通配符以使得它匹配整个值,就像如果你使用了一个SQL模式那样。
为了找出包含正好5个字符的名字,使用“^”和“$”匹配名字的开始和结尾,和5个“.”实例在两者之间:
mysql> SELECT * FROM pet WHERE name REGEXP "^.....$";
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| hahah | hahah | cat | m | 1990-03-15 | NULL |
| Buffy | Harold | dog | f | 1989-05-20 | NULL |
+-------+--------+---------+------+------------+-------+
你也可以使用“{n}”“重复n次”操作符重写先前的查询:
mysql> SELECT * FROM pet WHERE name REGEXP "^.{5}$";
+-------+--------+---------+------+------------+-------+
| name
| owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| hahah | hahah | cat | m | 1990-03-15 | NULL |
| Buffy | Harold | dog | f | 1989-05-20 | NULL |
+-------+--------+---------+------+------------+-------+