如何入门 Python 爬虫?
Posted 程序汪小陈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何入门 Python 爬虫?相关的知识,希望对你有一定的参考价值。
很多人一上来就要爬虫,其实没有弄明白要用爬虫做什么,最后学完了却用不上。
大多数人其实是不需要去学习爬虫的,因为工作所在的公司里有自己的数据库,里面就有数据来帮助你完成业务分析。
什么时候要用到爬虫呢?
当工作中没有你需要的数据,你必须要从上网搜集一些数据时,这时候就可以利用爬虫模拟浏览器打开网页,获取网页中我们想要的那部分数据,从而提高工作效率。
另外构建自动化表格也是可以用爬虫做到的,也就是通过爬虫搜集特定数据,然后自动保存到Excel中实现自动化表格的构建。
不管是构建爬虫,还上自动化表格,这其中爬虫所要做的包括4步流程(下图),模拟浏览器发起请求(获取代码)->获取响应内容(获取爬到的内容)->解析内容(从爬到的内容里面提取有用的数据)->保存数据(把爬到的数据保存到数据库或Excel文件)中。

实现爬虫的工具有有两种,一种是傻瓜式的爬虫工具,这种工具通过可视化界面就可以操作,上手快。另一个种是通过Python编程来爬虫,这种需要一定的学习成本。
傻瓜式的爬虫工具
1.后羿
官网:http://houyicaiji.com
打开官网后点击下图“文档中心”有入门教程。
2.集搜客
官网:http://gooseeker.com
通过编程来爬虫涉及到的知识特别多,很多人因为学习爬虫知识点的步骤不对,导致从入门到放弃。下面是学习Python爬虫的整体步骤,从整体上先有个认知:
1.学习爬虫就好比做菜,首先要学会基本的Python语法知识,熟悉食谱,才能心中有数,做好烹饪。
2.相比于厨师的菜刀,Python爬虫常用到的几个重要内置库urllib, http等,则是我们我们爬虫无往不利的利器,它们可以帮我们下载网页。
3.厨师烹饪前对食材的熟悉是基本的要求,而对于爬虫来说,正则表达式re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具的学习,也是基本要求,只有学会它们,我们才能知道特定网站的规则,成功爬取其中数据。
4.熟悉了食谱,了解了食材,有了菜刀,我们就可以开始一些简单的网站爬取,了解爬取数据过程。这时候你已经是入门爬虫了。
而如果你不仅仅满足于烹饪简单食材,想继续精进爬虫,那么你可以开始下面步骤的学习,它们是成为爬虫大神的必经之路:
5.了解爬虫的一些反爬机制,header,robot,时间间隔,代理ip,隐含字段等 。
6.学习一些特殊网站的爬取,解决登录、Cookie、动态网页等问题 。
7.了解爬虫与数据库的结合,如何将爬取数据进行储存 。
8.学习应用Python的多线程、多进程进行爬取,提高爬虫效率 。
9.学习爬虫的框架,Scrapy、PySpider等 。
10.学习分布式爬虫(数据量庞大的需求)
学习Python爬虫的渠道推荐有CSDN,BiliBili,知乎。这些网站有很多免费优质的资源,可以帮助你快速入门爬虫学习。
Python 针对 Excel 有很多的第三方库可以用,比如 xlwings、xlsxwriter、xlrd、xlwt、pandas、xlsxwriter、win32com、xlutils 等等。
这些库可以很方便地实现对Excel文件的增删改写、格式修改等,当然并不推荐你全部都去尝试一下,这样时间成本太大了。使用 xlwings、 xlrd和 xlwt这两个就够了,基本能解决 Excel 自动化表格的所有问题。
xlwing 不光可以读写Excel ,还能进行格式调整、VBA 操作,非常强大且易于使用。
这是关于xlwing官方教程(https://www.xlwings.org)里面有着丰富的实例教学视频,不过里面是英文讲解。
需要提醒的是,爬虫作为获取数据的技术手段之一,由于部分数据存在敏感性,如果不能甄别哪些数据是可以爬取,哪些会触及法律,可能下一位上新闻的主角就是你。所以你要格外注意。
对于如何界定爬虫的合法性,可以从三个角度考虑,分别是采集途径、采集行为、使用目的。
1.通过什么途径爬取数据,这个是最需要重视的一点。总体来说,未公开、未经许可、且带有敏感信息的数据,不管是通过什么渠道获得,都是一种不合法的行为。
所以在采集这类比较敏感的数据时,最好先查询下相关法律法规,特别是用户个人信息、其他商业平台的信息 等这类信息,寻找一条合适的途径。
2.使用技术手段应该懂得克制,如果爬虫会导致其他公司服务器和业务造成干扰甚至破坏的行为,这种行为是不能有的。
3.数据使用目的同样是一大关键,就算你通过合法途径采集的数据,如果对数据没有正确的使用,同样会存在不合法的行为。常见的违规行为有:不遵循数据许可协议,超出约定的使用;出售个人信息;不正当商业行为等。
最后提醒,如果不是必须要用到爬虫,能不爬就别爬。
关于Python的技术储备
如果你是准备学习Python或者正在学习,下面这些你应该能用得上:
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤历年互联网企业Python面试真题,复习时非常方便
文末有领取方式哦
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python课程视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
三、Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
四、Python漫画教程
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。

五、互联网企业面试真题
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要也可以扫描下方csdn官方二维码或者点击主页和文章下方的微信卡片获取领取方式,【保证100%免费】

如何入门 Python 爬虫
爬虫我也是接触了1个月,从python小白到现在破译各种反爬虫机制,我给你说说我的方向:
1、学习使用解析网页的函数,例如:
import urllib.request
if __name__ == '__main__':
url = "..."
data = urllib.request.urlopen(url).read() #urllib.request.urlopen(需要解析的网址)
data = data.decode('unicode_escape','ignore') #用unicode_escape方式解码
print(data)
2、学习正则表达式:
正则表达式的符号意义在下面,而正则表达式是为了筛选出上面data中的信息出来,例如:
def get_all(data):
reg = r'(search.+)(" )(mars_sead=".+title=")(.+)(" data-id=")'
all = re.compile(reg);
alllist = re.findall(all, data)
return alllist
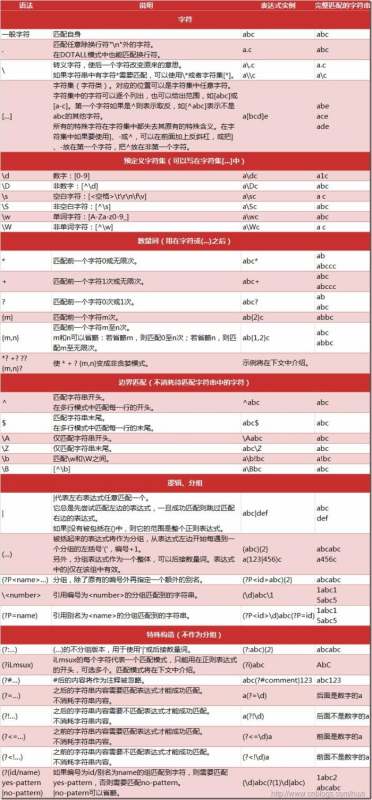
3、将得到的结果压进数组:
if __name__ == '__main__':
info = []
info.append(get_all(data))
4、将数组写进excel:
import xlsxwriter
if __name__ == '__main__':
info = []
info.append(get_all(data))
workbook = xlsxwriter.Workbook('C:\\\\Users\\\\Administrator\\\\Desktop\\\\什么文件名.xlsx') # 创建一个Excel文件
worksheet = workbook.add_worksheet() # 创建一个工作表对象
for i in range(0,len(info)):
worksheet.write(行, 列, info[i], font)#逐行逐列写入info[i]
workbook.close()#关闭excel
一个简单的爬虫搞定,爬虫的进阶不教了,你还没接触过更加看不懂
参考技术A先长话短说summarize一下:
你需要学习
基本的爬虫工作原理
基本的http抓取工具,scrapy
Bloom Filter: Bloom Filters by Example
如果需要大规模网页抓取,你需要学习分布式爬虫的概念。其实没那么玄乎,你只要学会怎样维护一个所有集群机器能够有效分享的分布式队列就好。最简单的实现是python-rq: https://github.com/nvie/rq
rq和Scrapy的结合:darkrho/scrapy-redis · GitHub
后续处理,网页析取(grangier/python-goose · GitHub),存储(Mongodb)
以上是关于如何入门 Python 爬虫?的主要内容,如果未能解决你的问题,请参考以下文章