Elasticsearch:如何使 Elasticsearch 和 Kibana 中的文本字段可聚合?
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:如何使 Elasticsearch 和 Kibana 中的文本字段可聚合?相关的知识,希望对你有一定的参考价值。
我们知道文本字段是不可以进行聚合的。要想把该字段变成为可以进行聚合的字段,一种方法就是把它变成为 keyword 字段,这样就可以进聚合了,但是一旦我们把字段变为另外一种数据类型,那么我们首先失去了对该字段的全文搜索功能。我们只能对该字段进行精确的匹配。更为严重的是,我们必须使用 reindex 把该索引转变为另外一个索引。一种比较合理的解决方式就是使用 mulit-fields。我们可以在不改变索引 mappings 的情况下,增加一个新的 keyword 字段,从而达到能够实现聚合的目的。
如何检查字段是否可聚合?
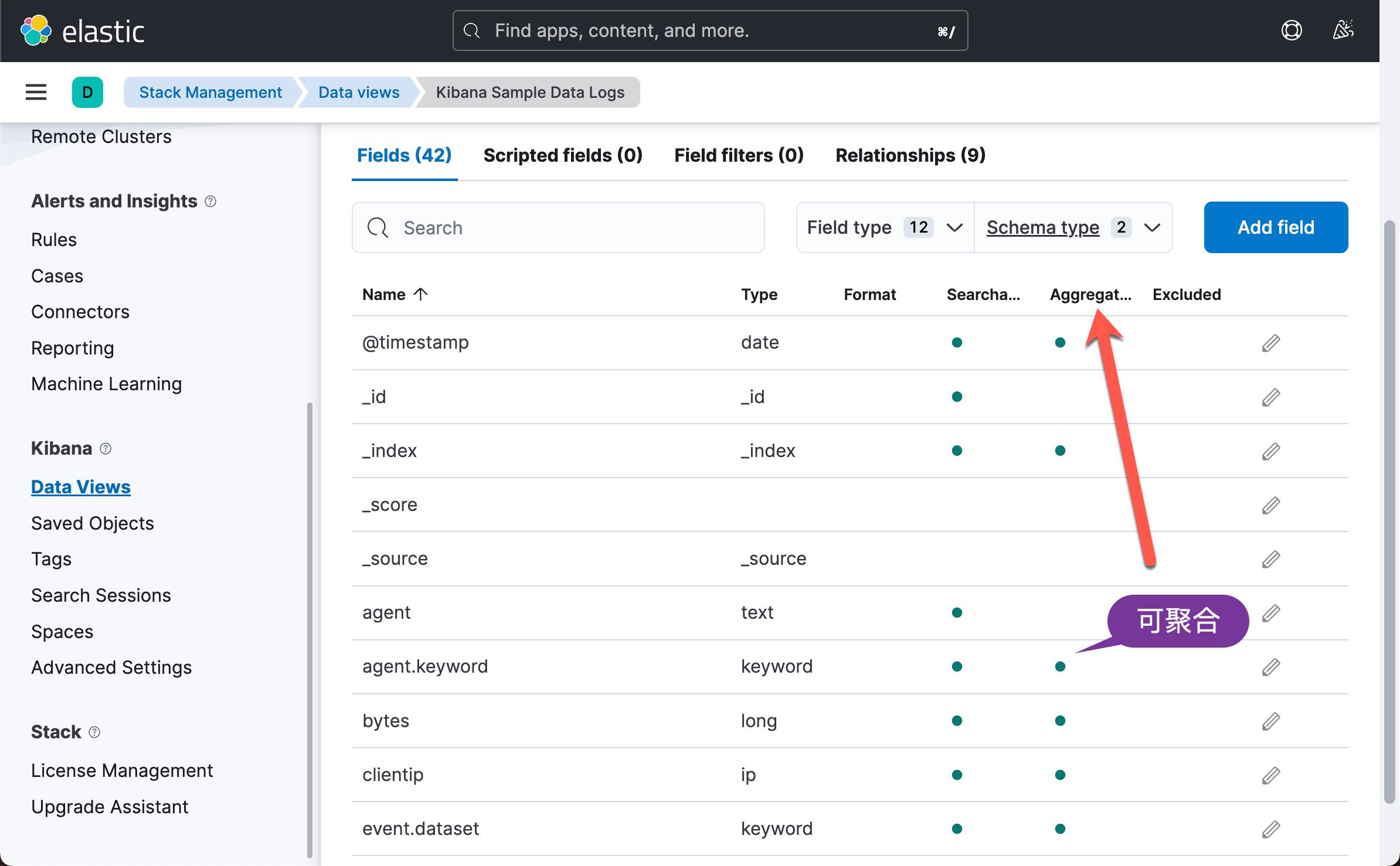
要检查字段是否可聚合,请打开 Kibana,选择左侧菜单中的 Stack Management 选项,然后选择索引模式。 如果可聚合列下有复选/圆圈,则表示该字段已聚合。
如何使字段可聚合?
选择一个字段
首先,你需要选择一个字段。 对于此示例,我选择使用 message 字段,如下图所示,message 字段不可以被聚合,因为它是 text 类型的字段。
现在你需要找出这个特定 message 字段出现在什么索引模式下。 当你在索引模式页面上时,你将能够在页面顶部查看索引模式。 上例中使用了 Logstash-* 索引模式。
获取索引 template
第二部分需要使用 Kibana Dev Tools 部分。然后在 Dev Tools 部分运行以下命令。 你还可以使用 Elasticsearch API 获取模板,但在本示例中,你将使用 Kibana Dev Tools。
GET _cat/templates这将返回当前在 Elasticsearch 和 Kibana 中的模板的名称。 我们需要找到我们需要的模板名称,比如 Logstash。 现在,在 Kibana Dev Tools 的新行上,你将运行以下命令。
GET _template/logstash运行此命令将获取 Logstash 索引模板,如下所示。
"order" : 0,
"version" : 60001,
"index_patterns" : [
"logstash-*"
],
"settings" :
"index" :
"refresh_interval" : "5s"
,
"mappings" :
"_default_" :
"dynamic_templates" : [
"message_field" :
"path_match" : "message",
"match_mapping_type" : "string",
"mapping" :
"type" : "text",
"norms" : false,
,
"string_fields" :
"match" : "*",
"match_mapping_type" : "string",
"mapping" :
"type" : "text",
"norms" : false,
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
],
"properties" :
"@timestamp" :
"type" : "date"
,
"@version" :
"type" : "keyword"
,
"geoip" :
"dynamic" : true,
"properties" :
"ip" :
"type" : "ip"
,
"location" :
"type" : "geo_point"
,
"latitude" :
"type" : "half_float"
,
"longitude" :
"type" : "half_float"
,
"aliases" :
创建一个 keyword 字段
在上面的模板中找到 message 字段部分。 可以看到当前映射类型是文本,不能在文本字段类型上进行聚合。 你需要一个 keyword 字段类型才能聚合。
更改字段映射类型的最简单方法是输入新模板。 将上面的模板复制到文本编辑器中,并将 message_field 转换为 keyword。 你可以通过将下一个代码片段添加到message 字段来执行此操作。
"fields" :
"keyword" :
"ignore_above" : 2048,
"type" : "keyword"
message 字段映射现在应该如下所示:
"mappings" :
"_default_" :
"dynamic_templates" : [
"message_field" :
"path_match" : "message",
"match_mapping_type" : "string",
"mapping" :
"type" : "text",
"norms" : false,
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 2048
,
(mappings __default__ has been deprecated in version 7 and will appear as mappings _doc)
"mappings" :
"_doc" :
"dynamic_templates" : [您需要在 ignore_above 上设置合理的大小,以免影响性能。 大多数消息都小于 1500 个字符,但它们可能会增加。 在此示例中,你最多允许使用 2048 个字符,较长的消息将被忽略。
改变 template order
你还需要更改模板的顺序以确保它应用于 message 字段。 如果你将 order 号更改为 4,它将具有所有模板中最高的 order 号。 这意味着它将是应用的顶级模板。 order 在模板中的工作方式是首先应用最低的 order 号,而较高的 order 号位于其上。 因此,将首先应用订单号为 0 的模板,然后将应用订单号为 1 的模板,订单号为 4 的模板将位于这两个模板之上并作为顶级模板应用。 继续更改顺序,使其值为 4。
PUT _template/logstash_msg_keyword
"order" : 4,
"version" : 60001,
"index_patterns" : [
"logstash-*"在 Kibana 中创建新的 template
复制新模板,因为它已准备好添加。 在将模板粘贴到 Kibana 之前。 你需要先将以下行添加到 Kibana Dev Tools 中。 这会告诉 Kibana 你将要输入一个新模板并将其命名为 logstash_msg_keyword。
PUT _template/logstash_msg_keyword我们在 Kibana Dev Tools 中有一个新行粘贴新模板。 你应该有类似于以下部分的内容。
PUT _template/logstash_msg_keyword
"order" : 4,
"version" : 60001,
"index_patterns" : [
"logstash-*"
],
"settings" :
"index" :
"refresh_interval" : "5s"
,
"mappings" :
"_default_" :
"dynamic_templates" : [
"message_field" :
"path_match" : "message",
"match_mapping_type" : "string",
"mapping" :
"type" : "text",
"norms" : false,
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 2048
,
"string_fields" :
"match" : "*",
"match_mapping_type" : "string",
"mapping" :
"type" : "text",
"norms" : false,
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
],
"properties" :
"@timestamp" :
"type" : "date"
,
"@version" :
"type" : "keyword"
,
"geoip" :
"dynamic" : true,
"properties" :
"ip" :
"type" : "ip"
,
"location" :
"type" : "geo_point"
,
"latitude" :
"type" : "half_float"
,
"longitude" :
"type" : "half_float"
,
"aliases" :
发送带有未来日期的测试数据
模板应用于索引创建,因为数据很可能今天已经发送到 ELK 堆栈。 你需要使用未来的索引创建。 这可以通过使用将来的日期来实现,例如 1/1/2030。 然后,你可以使用 Stack API 密钥将数据从命令行发送到堆栈中。
curl -i -H "ApiKey: <your-stack-api-key" -i -H "Content-Type: application/json" https://localhost:9200 -d '"message":"This is so cool", "@timestamp":"2030-11-08T11:00:0.000Z"'检验结果
一旦你确认数据已到达你的 Elasticsearch。 在 Kibana 上,你需要进入 Stack Management 选项卡,选择索引模式,刷新索引字段列表并搜索 message.keyword 字段,检查该字段现在是否可聚合。
应用于已有数据
之前的数据可能还没有 message.keyword 这个字段。我们可以通过如下的方式来更新之前的数据:
POST logstash-*/_update_by_query这样我们之前的已有数据将会含有 message.keyword 这个字段。你将可以对它们进行聚合了。
以上是关于Elasticsearch:如何使 Elasticsearch 和 Kibana 中的文本字段可聚合?的主要内容,如果未能解决你的问题,请参考以下文章