软件测试系列第一阶段:第一课 计算机基础
Posted m0_62395433
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件测试系列第一阶段:第一课 计算机基础相关的知识,希望对你有一定的参考价值。
软件测试相关的理论和工具
学习周期
3-4周期
软件测试就业岗位
自动化测试
手动测试
接口测试
学习建议
不要过分追求新技术
稳定心态 态度决定一切
记笔记和总结
提高工作效率
快捷键 命令
不计较眼前的得失
深入研究 耐得住寂寞
学习的三重境界
树立目标
为了目标而努力
超越了设立的目标
什么是软件测试
通过人工或者软件的方式去找到程序运行期间存在的问题,并配合开发人员解决问题,保证程序能正常的运行和交付
IT服务外包
外包公司:专门承接其他公司的技术开发项目
第二课:计算机基础
计算机的构成
内部设备
中央处理器-CPU,用来处理数据
个人电脑内存条插槽:1-2
个人电脑得内存大小范围普遍:8G-32G
特点
内存得存储空间相对较小
内存中得数据据断电就没有了
速度非常快
主板:将CPU.内存.网卡等设备链接到一起
主板通过使用纽扣电池供电
外包设备
输入设备:鼠标.键盘.麦克风.扫描仪
输出设备:音响.显示器.打印机
存储设备:外存:可以实现数据永久存储得设备
类型:硬盘 u盘 光盘
特点
存储空间相对较大,例如硬盘空间普遍是1T-4T
数据不会丢失
速度慢
手机
8+256
8:运行内存,也就是内部存储,断电会丢失,这个存储读取速度很快
256:外部储存,外存中得数据,会永久储存,但是这个存储得读写数据得很慢
常识:
计算机能识别和处理得只有0和1,这叫做二进制数
数学
十进制
二进制
计算机得存储单位
bit(位,b):一个二进制得0或者一个二进制得1就是1位
byte(字节,B):1字节等于8位
K(千字节):1千个字节
M(兆字节):1024个K
G(G字节):1024个M
单位换算
1B=8b
1K=1024B
1M=1024B
1T=1024G
操作系统
用户无法直接使用计算机硬件
用户是通过OS(operation system:操作系统)来控制和使用硬件的
类型的类型
windows
个人系统:windowsXP windwos7 Windows8 Windows10
服务器系统:Windows server2003 Windows server2008 Windowsserver2012
dos命令
打开dos窗口的方法
打开‘运行窗口’,快捷键是win+r,在输入空中输入cmd
清屏命令:cls
切换硬盘:盘符:
查看目录中有哪些文件:dir
查看IP地址信息:ipconfig/all
常规的IP地址:
点分十进制的地址,也就是用点来分割十进制数
每个十进制数的范围0-255
mac地址
每个网卡有一个全球唯一的地址,这个地址是设备出厂的时候,固化在设备中
mac地址是有12个16进制数字构成的
行人重识别计算机视觉进阶系列 第一课 基础知识
【行人重识别】🖐计算机视觉进阶系列🖐 第一课 基础知识
概述
行人重识别 (Person Re-Identification) 是利用计算机视觉技术判断图片或视频中是否存在特定行人的技术. 行人重识别技术可以帮助我们在多摄像头的复杂场景中快速定位查找到指定目标的所有结果. 行人重识别技术在智能安防, 监控等领域有者巨大的前景. 今天小白就带大家来一起学习一下行人重识别的技术.

行人重识别
行人重识别 (Person Re-Identification) 是利用计算机视觉技术判断图片或视频中是否存在特定行人的技术.
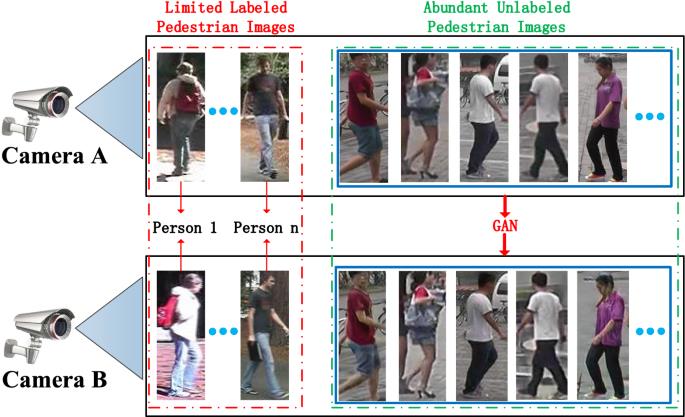
行人重识别面临的挑战:
- 图像分辨率低
- 遮挡
- 视角, 姿势变化
- 光照变化
- 视觉模糊性
rank-1
rank-1 即预测最高概率的标签与真实标签占比的百分比, 即第一张返回的图像正确的百分比. 例如, 模型识别了 100 只猪, 但实际上, 里面 90 只是猪, 10 只是大象. rank-1 的值就为 90/100 = 90%.
mAP
mAP (Mean Average Precision) 即 AP 的平均值.
ap 的计算过程:
- 找到第一张返回图片正确的位置, 取得 P r e c i s i o n 1 = i n d e x p 1 i n d e x t o t a l Precision_1 = \\frac index_p1 index_total Precision1=indextotalindexp1
- 找到第二章返回图片正确的位置, 取得 P r e c i s i o n 2 = i n d e x p 2 i n d e x t o t a l Precision_2 = \\frac index_p2 index_total Precision2=indextotalindexp2
- 重复以上步骤, 取得 A P = P r e c i s i o n 1 + P r e c i s i o n 2 + . . . + P r e c i s i o n n n AP = \\frac Precision_1 + Precision_2 + ... + Precision_n n AP=nPrecision1+Precision2+...+Precisionn
损失函数
行人重识别通常使用的函数为分类损失 + Triplet Loss, 增加 Triplet 可以使得特征提取的更好. 下面我们就分别来讲解一下.
交叉熵
交叉熵 (Cross Entropy) 是分类任务最常用的一种损失, 可以帮助我们求得目标与预测值之间的差距. 关于交叉熵的具体推导流程请大家自行百度, 在这里就不过多赘述.
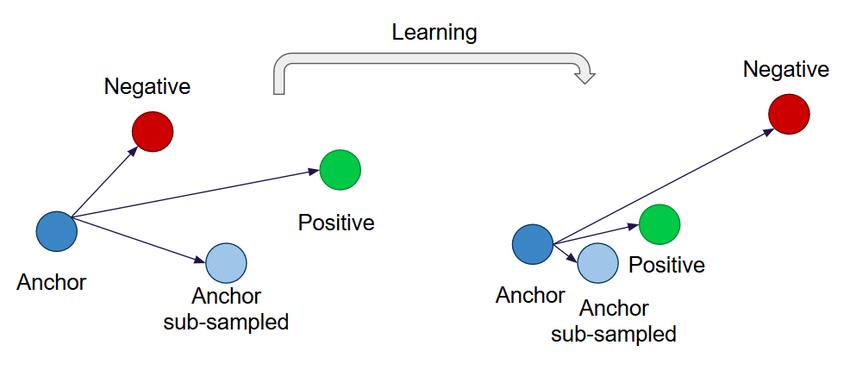
Triplet Loss
Triplet Loss 是深度学习的一种损失函数, 主要用于训练差异性小的样本.
Triplet Loss 由三个部分组成, 分别为:
- 锚 (Anchor): 当前数据
- 正示例 (Positive): 和锚为同一人的数据
- 负示例 (Negative): 和锚为不同人的数据
Triplet Loss 计算流程:
- 分别对三份数据进行编码
- 分别将三份数据经过相同的网络
- 计算三份数据之间的差异
- 通过差值来更新权重参数
Triplet Loss 训练的目标是拉近锚 (Anchor) 与正示例 (Positive) 的距离, 拉远锚 (Anchor) 与负示例 (Negative) 的距离.
Triplet Loss 公式:
∣ ∣ f ( A ) − f ( P ) ∣ ∣ 2 − ∣ ∣ f ( A ) − f ( N ) ∣ ∣ 2 + a ≤ 0 || f(A) - f(P)||^2 - || f(A) - f(N)||^2 + a \\le 0 ∣∣f(A)−f(P)∣∣2−∣∣f(A)−f(N)∣∣2+a≤0
我们可以看到
公式中存在一个
a
a
a, 也被称作间隔 (Margin), 表示 d(A, P) 与 d(A, N) 至少相差多少, 从而避免模型走捷径将正示例和负示例的距离训练的相等.
Hard Negative
Hard Negative 即难以正确分类的样本. 在行人重识别中, 我们会尽量挑选和正示例相近的负示例 d(A, P) ≈ \\approx ≈ d(A, N), 从而使模型多进行训练以达到更好的效果.
以上是关于软件测试系列第一阶段:第一课 计算机基础的主要内容,如果未能解决你的问题,请参考以下文章