目标检测(10) Mosaic 数据增强方法,附Python完整代码
Posted 立Sir
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测(10) Mosaic 数据增强方法,附Python完整代码相关的知识,希望对你有一定的参考价值。
各位同学好,今天和大家分享一下目标检测算法中常用的图像数据增强方法 Mosaic。先放张图看效果。将四张图片缩放后裁剪拼接在一起,并调整检测框的坐标位置,处理位于图像边缘的检测框。文末有完整代码

1. 方法介绍
Mosaic 数据增强算法将多张图片按照一定比例组合成一张图片,使模型在更小的范围内识别目标。Mosaic 数据增强算法参考 CutMix数据增强算法。CutMix数据增强算法使用两张图片进行拼接,而 Mosaic 数据增强算法一般使用四张进行拼接,但两者的算法原理是非常相似的。
方法步骤:
(1)随机选取图片拼接基准点坐标(xc,yc),另随机选取四张图片。
(2)四张图片根据基准点,分别经过 尺寸调整 和 比例缩放 后,放置在指定尺寸的大图的左上,右上,左下,右下位置。
(3)根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
(4)依据指定的横纵坐标,对大图进行拼接。处理超过边界的检测框坐标。
方法优点:
(1)增加数据多样性,随机选取四张图像进行组合,组合得到图像个数比原图个数要多。
(2)增强模型鲁棒性,混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
(3)加强批归一化层(Batch Normalization)的效果。当模型设置 BN 操作后,训练时会尽可能增大批样本总量(BatchSize),因为 BN 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
(4)Mosaic 数据增强算法有利于提升小目标检测性能。Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标。
2. 代码展示
2.1 加载图片及标签
我以四张图片及其标签文件为例,导入 xml.etree 库解析XML标签文件,这里我只读取检测框的左上和右下角坐标信息,我习惯使用opencv方法处理图片,当然也可以使用Image库处理。将读取的图片及其对应的坐标信息保存在同一个列表中。

代码如下:
# 主函数,获取图片路径和检测框路径
if __name__ == '__main__':
# 给出图片文件夹和检测框文件夹所在的位置
image_dir = 'D:/deeplearning/database/VOC2007/picture/'
annotation_dir = 'D:/deeplearning/database/VOC2007/annotation/'
image_list = [] # 存放每张图像和该图像对应的检测框坐标信息
# 读取4张图像及其检测框信息
for i in range(4):
image_box = [] # 存放每张图片的检测框信息
# 某张图片位置及其对应的检测框信息
image_path = image_dir + str(i+1) + '.jpg'
annotation_path = annotation_dir + str(i+1) + '.xml'
image = cv2.imread(image_path) # 读取图像
# 读取检测框信息
with open(annotation_path, 'r') as new_f:
# getroot()获取根节点
root = ET.parse(annotation_path).getroot()
# findall查询根节点下的所有直系子节点,find查询根节点下的第一个直系子节点
for obj in root.findall('object'):
obj_name = obj.find('name').text # 目标名称
bndbox = obj.find('bndbox')
left = eval(bndbox.find('xmin').text) # 左上坐标x
top = eval(bndbox.find('ymin').text) # 左上坐标y
right = eval(bndbox.find('xmax').text) # 右下坐标x
bottom = eval(bndbox.find('ymax').text) # 右下坐标y
# 保存每张图片的检测框信息
image_box.append([left, top, right, bottom]) # [[x1,y1,x2,y2],[..],[..]]
# 保存图像及其对应的检测框信息
image_list.append([image, image_box])
# 分割、缩放、拼接图片
get_random_data(image_list, input_shape=[416,416])2.2 图像分割
输入图片的尺寸是 (iw, ih) ;指定图片的尺寸是 (w, h) ,其中w=h=416;缩放后的图片的尺寸是 (nw, nh)
(1)先通过cv2.resize()将图片尺寸从(iw, ih) 变成 (w, h);再乘以缩放比例 scale,是0.6至0.8之间的一个随机数;得到压缩后的图像尺寸 (nw, nh)
(2)生成一个尺寸为 (w, h) 的画板 np.zeros((h,w,3), np.uint8),将第一张压缩后的图片放在画板的左上方,第二张放在右上方,第三张放在左下方,第四张放在右下方。
(3)h-nh 代表y轴方向上画板边界距离缩放后图片边界的距离,w-nw 代表x轴方向上画板边界距离缩放后图片边界的距离
(4)检测框中心点坐标为 (cx, cy),坐标调整比例是 nw/iw,但需要分开调整位于不同位置的四张图的检测框。
代码如下:
def get_random_data(image_list, input_shape):
h, w = input_shape # 获取图像的宽高
'''设置拼接的分隔线位置'''
min_offset_x = 0.4
min_offset_y = 0.4
scale_low = 1 - min(min_offset_x, min_offset_y) # 0.6
scale_high = scale_low + 0.2 # 0.8
image_datas = [] # 存放图像信息
box_datas = [] # 存放检测框信息
index = 0 # 当前是第几张图
#(1)图像分割
for frame_list in image_list:
frame = frame_list[0] # 取出的某一张图像
box = np.array(frame_list[1:]) # 该图像对应的检测框坐标
ih, iw = frame.shape[0:2] # 图片的宽高
cx = (box[0,:,0] + box[0,:,2]) // 2 # 检测框中心点的x坐标
cy = (box[0,:,1] + box[0,:,3]) // 2 # 检测框中心点的y坐标
# 对输入图像缩放
new_ar = w/h # 图像的宽高比
scale = np.random.uniform(scale_low, scale_high) # 缩放0.6--0.8倍
# 调整后的宽高
nh = int(scale * h) # 缩放比例乘以要求的宽高
nw = int(nh * new_ar) # 保持原始宽高比例
# 缩放图像
frame = cv2.resize(frame, (nw,nh))
# 调整中心点坐标
cx = cx * nw/iw
cy = cy * nh/ih
# 调整检测框的宽高
bw = (box[0,:,2] - box[0,:,0]) * nw/iw # 修改后的检测框的宽高
bh = (box[0,:,3] - box[0,:,1]) * nh/ih
# 创建一块[416,416]的底版
new_frame = np.zeros((h,w,3), np.uint8)
# 确定每张图的位置
if index==0: new_frame[0:nh, 0:nw] = frame # 第一张位于左上方
elif index==1: new_frame[0:nh, w-nw:w] = frame # 第二张位于右上方
elif index==2: new_frame[h-nh:h, 0:nw] = frame # 第三张位于左下方
elif index==3: new_frame[h-nh:h, w-nw:w] = frame # 第四张位于右下方
# 修正每个检测框的位置
if index==0: # 左上图像
box[0,:,0] = cx - bw // 2 # x1
box[0,:,1] = cy - bh // 2 # y1
box[0,:,2] = cx + bw // 2 # x2
box[0,:,3] = cy + bh // 2 # y2
if index==1: # 右上图像
box[0,:,0] = cx - bw // 2 + w - nw # x1
box[0,:,1] = cy - bh // 2 # y1
box[0,:,2] = cx + bw // 2 + w - nw # x2
box[0,:,3] = cy + bh // 2 # y2
if index==2: # 左下图像
box[0,:,0] = cx - bw // 2 # x1
box[0,:,1] = cy - bh // 2 + h - nh # y1
box[0,:,2] = cx + bw // 2 # x2
box[0,:,3] = cy + bh // 2 + h - nh # y2
if index==3: # 右下图像
box[0,:,2] = cx - bw // 2 + w - nw # x1
box[0,:,3] = cy - bh // 2 + h - nh # y1
box[0,:,0] = cx + bw // 2 + w - nw # x2
box[0,:,1] = cy + bh // 2 + h - nh # y2
index = index + 1 # 处理下一张
# 保存处理后的图像及对应的检测框坐标
image_datas.append(new_frame)
box_datas.append(box)
# 取出某张图片以及它对应的检测框信息, i代表图片索引
for image, boxes in zip(image_datas, box_datas):
# 复制一份原图
image_copy = image.copy()
# 遍历该张图像中的所有检测框
for box in boxes[0]:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('img', image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()分割后的图像如下:
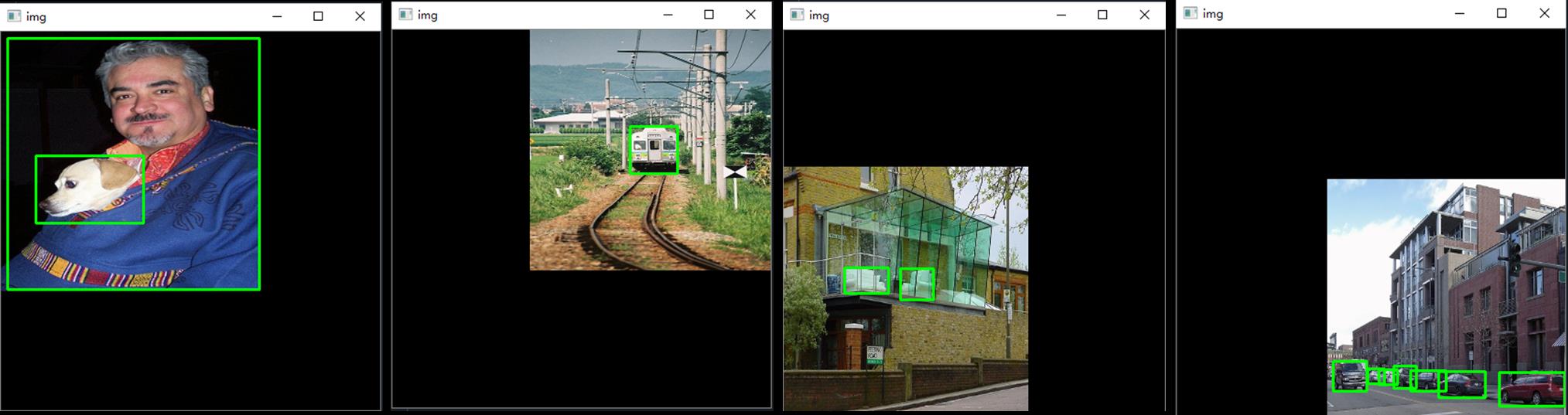
2.3 图像合并
首先设置拼接线,cutx代表x轴方向把图像分割成两块区域,cuty代表y轴方向把图片分割成两块。设置 (cutx, cuty) 代表四张图在何坐标下切割,如右上方的图只取 cutx左侧 且 cuty上侧 的区域。
创建一块新的画板new_image,大小为(416, 416),将切割后的四张图片组合在一起
#(2)将四张图像拼接在一起
# 在指定范围中选择横纵向分割线
cutx = np.random.randint(int(w*min_offset_x), int(w*(1-min_offset_x)))
cuty = np.random.randint(int(h*min_offset_y), int(h*(1-min_offset_y)))
# 创建一块[416,416]的底版用来组合四张图
new_image = np.zeros((h,w,3), np.uint8)
new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :]
new_image[:cuty, cutx:, :] = image_datas[1][:cuty, cutx:, :]
new_image[cuty:, :cutx, :] = image_datas[2][cuty:, :cutx, :]
new_image[cuty:, cutx:, :] = image_datas[3][cuty:, cutx:, :]
# 显示合并后的图像
cv2.imshow('new_img', new_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 复制一份合并后的原图
final_image_copy = new_image.copy()
# 显示有检测框并合并后的图像
for boxes in box_datas:
# 遍历该张图像中的所有检测框
for box in boxes[0]:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(final_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', final_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()拼接后的图像如下:
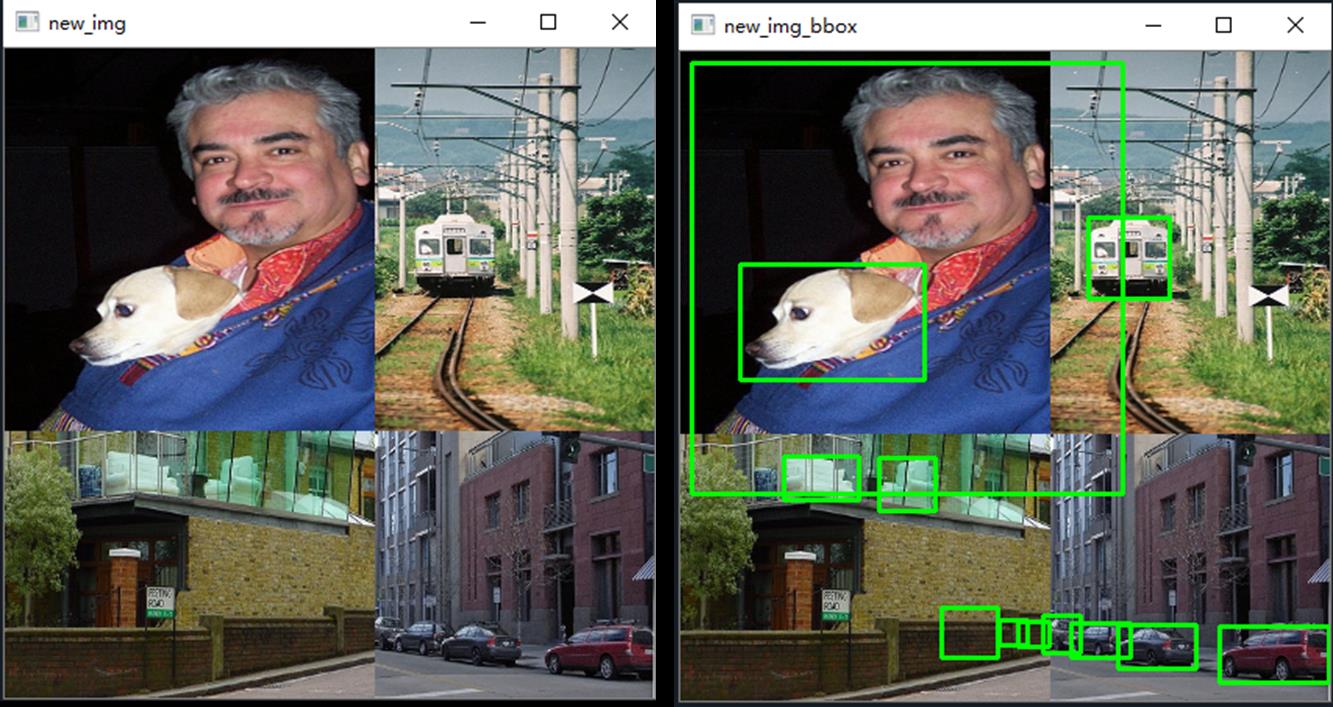
2.4 处理检测框边界
如上图,我们发现左上图的检测框伸展到了其他区域,右下图的部分检测车辆的框中没有目标。因为我们只对图片进行了拼接,而图片对应的检测框仍然是原来分割前的检测框坐标。
(1)将不在其对应图像所在区域内的检测框都剔除;如右下侧图中的检测车的框跑到左下侧图中去了。
(2)将检测框一部分在图像区域内,一部分不在图像区域内的,以该图的区域分界线(cutx, cuty)代替越界的检测框线条。如左上图人的检测框需要用边界线代替区域外的边缘线
(3)如果修正后的检测框的高度或者宽度过于小,那么就没有意义,剔除这个修正后的框
代码如下:
#(4)处理超出边缘的检测框
def merge_bboxes(bboxes, cutx, cuty):
# 保存修改后的检测框
merge_box = []
# 遍历每张图像,共4个
for i, box in enumerate(bboxes):
# 每张图片中需要删掉的检测框
index_list = []
# 遍历每张图的所有检测框,index代表第几个框
for index, box in enumerate(box[0]):
# axis=1纵向删除index索引指定的列,axis=0横向删除index指定的行
# box[0] = np.delete(box[0], index, axis=0)
# 获取每个检测框的宽高
x1, y1, x2, y2 = box
# 如果是左上图,修正右侧和下侧框线
if i== 0:
# 如果检测框左上坐标点不在第一部分中,就忽略它
if x1 > cutx or y1 > cuty:
index_list.append(index)
# 如果检测框右下坐标点不在第一部分中,右下坐标变成边缘点
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if y2-y1 < 5:
index_list.append(index)
if x2 >= cutx and x1 <= cutx:
x2 = cutx
# 如果修正后的左上坐标和右下坐标之间的距离过小,就忽略这个框
if x2-x1 < 5:
index_list.append(index)
# 如果是右上图,修正左侧和下册框线
if i == 1:
if x2 < cutx or y1 > cuty:
index_list.append(index)
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if y2-y1 < 5:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x1 = cutx
if x2-x1 < 5:
index_list.append(index)
# 如果是左下图
if i == 2:
if x1 > cutx or y2 < cuty:
index_list.append(index)
if y1 <= cuty and y2 >= cuty:
y1 = cuty
if y2-y1 < 5:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x2 = cutx
if x2-x1 < 5:
index_list.append(index)
# 如果是右下图
if i == 3:
if x2 < cutx or y2 < cuty:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x1 = cutx
if x2-x1 < 5:
index_list.append(index)
if y1 <= cuty and y2 >= cuty:
y1 = cuty
if y2-y1 < 5:
index_list.append(index)
# 更新坐标信息
bboxes[i][0][index] = [x1, y1, x2, y2] # 更新第i张图的第index个检测框的坐标
# 删除不满足要求的框,并保存
merge_box.append(np.delete(bboxes[i][0], index_list, axis=0))
# 返回坐标信息
return merge_box
#(3)处理超出图像边缘的检测框
new_boxes = merge_bboxes(box_datas, cutx, cuty)
# 复制一份合并后的图像
modify_image_copy = new_image.copy()
# 绘制修正后的检测框
for boxes in new_boxes:
# 遍历每张图像中的所有检测框
for box in boxes:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(modify_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', modify_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows() 效果图如下:
3. 完整代码
from xml.etree import ElementTree as ET # xml文件解析方法
import numpy as np
import cv2
#(3)处理超出边缘的检测框
def merge_bboxes(bboxes, cutx, cuty):
# 保存修改后的检测框
merge_box = []
# 遍历每张图像,共4个
for i, box in enumerate(bboxes):
# 每张图片中需要删掉的检测框
index_list = []
# 遍历每张图的所有检测框,index代表第几个框
for index, box in enumerate(box[0]):
# axis=1纵向删除index索引指定的列,axis=0横向删除index指定的行
# box[0] = np.delete(box[0], index, axis=0)
# 获取每个检测框的宽高
x1, y1, x2, y2 = box
# 如果是左上图,修正右侧和下侧框线
if i== 0:
# 如果检测框左上坐标点不在第一部分中,就忽略它
if x1 > cutx or y1 > cuty:
index_list.append(index)
# 如果检测框右下坐标点不在第一部分中,右下坐标变成边缘点
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if y2-y1 < 5:
index_list.append(index)
if x2 >= cutx and x1 <= cutx:
x2 = cutx
# 如果修正后的左上坐标和右下坐标之间的距离过小,就忽略这个框
if x2-x1 < 5:
index_list.append(index)
# 如果是右上图,修正左侧和下册框线
if i == 1:
if x2 < cutx or y1 > cuty:
index_list.append(index)
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if y2-y1 < 5:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x1 = cutx
if x2-x1 < 5:
index_list.append(index)
# 如果是左下图
if i == 2:
if x1 > cutx or y2 < cuty:
index_list.append(index)
if y1 <= cuty and y2 >= cuty:
y1 = cuty
if y2-y1 < 5:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x2 = cutx
if x2-x1 < 5:
index_list.append(index)
# 如果是右下图
if i == 3:
if x2 < cutx or y2 < cuty:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x1 = cutx
if x2-x1 < 5:
index_list.append(index)
if y1 <= cuty and y2 >= cuty:
y1 = cuty
if y2-y1 < 5:
index_list.append(index)
# 更新坐标信息
bboxes[i][0][index] = [x1, y1, x2, y2] # 更新第i张图的第index个检测框的坐标
# 删除不满足要求的框,并保存
merge_box.append(np.delete(bboxes[i][0], index_list, axis=0))
# 返回坐标信息
return merge_box
#(1)对传入的四张图片数据增强
def get_random_data(image_list, input_shape):
h, w = input_shape # 获取图像的宽高
'''设置拼接的分隔线位置'''
min_offset_x = 0.4
min_offset_y = 0.4
scale_low = 1 - min(min_offset_x, min_offset_y) # 0.6
scale_high = scale_low + 0.2 # 0.8
image_datas = [] # 存放图像信息
box_datas = [] # 存放检测框信息
index = 0 # 当前是第几张图
#(1)图像分割
for frame_list in image_list:
frame = frame_list[0] # 取出的某一张图像
box = np.array(frame_list[1:]) # 该图像对应的检测框坐标
ih, iw = frame.shape[0:2] # 图片的宽高
cx = (box[0,:,0] + box[0,:,2]) // 2 # 检测框中心点的x坐标
cy = (box[0,:,1] + box[0,:,3]) // 2 # 检测框中心点的y坐标
# 对输入图像缩放
new_ar = w/h # 图像的宽高比
scale = np.random.uniform(scale_low, scale_high) # 缩放0.6--0.8倍
# 调整后的宽高
nh = int(scale * h) # 缩放比例乘以要求的宽高
nw = int(nh * new_ar) # 保持原始宽高比例
# 缩放图像
frame = cv2.resize(frame, (nw,nh))
# 调整中心点坐标
cx = cx * nw/iw
cy = cy * nh/ih
# 调整检测框的宽高
bw = (box[0,:,2] - box[0,:,0]) * nw/iw # 修改后的检测框的宽高
bh = (box[0,:,3] - box[0,:,1]) * nh/ih
# 创建一块[416,416]的底版
new_frame = np.zeros((h,w,3), np.uint8)
# 确定每张图的位置
if index==0: new_frame[0:nh, 0:nw] = frame # 第一张位于左上方
elif index==1: new_frame[0:nh, w-nw:w] = frame # 第二张位于右上方
elif index==2: new_frame[h-nh:h, 0:nw] = frame # 第三张位于左下方
elif index==3: new_frame[h-nh:h, w-nw:w] = frame # 第四张位于右下方
# 修正每个检测框的位置
if index==0: # 左上图像
box[0,:,0] = cx - bw // 2 # x1
box[0,:,1] = cy - bh // 2 # y1
box[0,:,2] = cx + bw // 2 # x2
box[0,:,3] = cy + bh // 2 # y2
if index==1: # 右上图像
box[0,:,0] = cx - bw // 2 + w - nw # x1
box[0,:,1] = cy - bh // 2 # y1
box[0,:,2] = cx + bw // 2 + w - nw # x2
box[0,:,3] = cy + bh // 2 # y2
if index==2: # 左下图像
box[0,:,0] = cx - bw // 2 # x1
box[0,:,1] = cy - bh // 2 + h - nh # y1
box[0,:,2] = cx + bw // 2 # x2
box[0,:,3] = cy + bh // 2 + h - nh # y2
if index==3: # 右下图像
box[0,:,2] = cx - bw // 2 + w - nw # x1
box[0,:,3] = cy - bh // 2 + h - nh # y1
box[0,:,0] = cx + bw // 2 + w - nw # x2
box[0,:,1] = cy + bh // 2 + h - nh # y2
index = index + 1 # 处理下一张
# 保存处理后的图像及对应的检测框坐标
image_datas.append(new_frame)
box_datas.append(box)
# 取出某张图片以及它对应的检测框信息, i代表图片索引
for image, boxes in zip(image_datas, box_datas):
# 复制一份原图
image_copy = image.copy()
# 遍历该张图像中的所有检测框
for box in boxes[0]:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('img', image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()
#(2)将四张图像拼接在一起
# 在指定范围中选择横纵向分割线
cutx = np.random.randint(int(w*min_offset_x), int(w*(1-min_offset_x)))
cuty = np.random.randint(int(h*min_offset_y), int(h*(1-min_offset_y)))
# 创建一块[416,416]的底版用来组合四张图
new_image = np.zeros((h,w,3), np.uint8)
new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :]
new_image[:cuty, cutx:, :] = image_datas[1][:cuty, cutx:, :]
new_image[cuty:, :cutx, :] = image_datas[2][cuty:, :cutx, :]
new_image[cuty:, cutx:, :] = image_datas[3][cuty:, cutx:, :]
# 显示合并后的图像
cv2.imshow('new_img', new_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 复制一份合并后的原图
final_image_copy = new_image.copy()
# 显示有检测框并合并后的图像
for boxes in box_datas:
# 遍历该张图像中的所有检测框
for box in boxes[0]:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(final_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', final_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 处理超出图像边缘的检测框
new_boxes = merge_bboxes(box_datas, cutx, cuty)
# 复制一份合并后的图像
modify_image_copy = new_image.copy()
# 绘制修正后的检测框
for boxes in new_boxes:
# 遍历每张图像中的所有检测框
for box in boxes:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(modify_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', modify_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 主函数,获取图片路径和检测框路径
if __name__ == '__main__':
# 给出图片文件夹和检测框文件夹所在的位置
image_dir = 'D:/deeplearning/database/VOC2007/picture/'
annotation_dir = 'D:/deeplearning/database/VOC2007/annotation/'
image_list = [] # 存放每张图像和该图像对应的检测框坐标信息
# 读取4张图像及其检测框信息
for i in range(4):
image_box = [] # 存放每张图片的检测框信息
# 某张图片位置及其对应的检测框信息
image_path = image_dir + str(i+1) + '.jpg'
annotation_path = annotation_dir + str(i+1) + '.xml'
image = cv2.imread(image_path) # 读取图像
# 读取检测框信息
with open(annotation_path, 'r') as new_f:
# getroot()获取根节点
root = ET.parse(annotation_path).getroot()
# findall查询根节点下的所有直系子节点,find查询根节点下的第一个直系子节点
for obj in root.findall('object'):
obj_name = obj.find('name').text # 目标名称
bndbox = obj.find('bndbox')
left = eval(bndbox.find('xmin').text) # 左上坐标x
top = eval(bndbox.find('ymin').text) # 左上坐标y
right = eval(bndbox.find('xmax').text) # 右下坐标x
bottom = eval(bndbox.find('ymax').text) # 右下坐标y
# 保存每张图片的检测框信息
image_box.append([left, top, right, bottom]) # [[x1,y1,x2,y2],[..],[..]]
# 保存图像及其对应的检测框信息
image_list.append([image, image_box])
# 缩放、拼接图片
get_random_data(image_list, input_shape=[416,416])目标检测yolo系列-yolo_v5学习笔记
文章参考自江大白知乎文章,作为yoloV5的学习记录笔记。
知乎链接:https://zhuanlan.zhihu.com/p/172121380
目录
一、Yolov5四种网络模型
Yolov5一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。下面给出网络结构图这样更加直观。
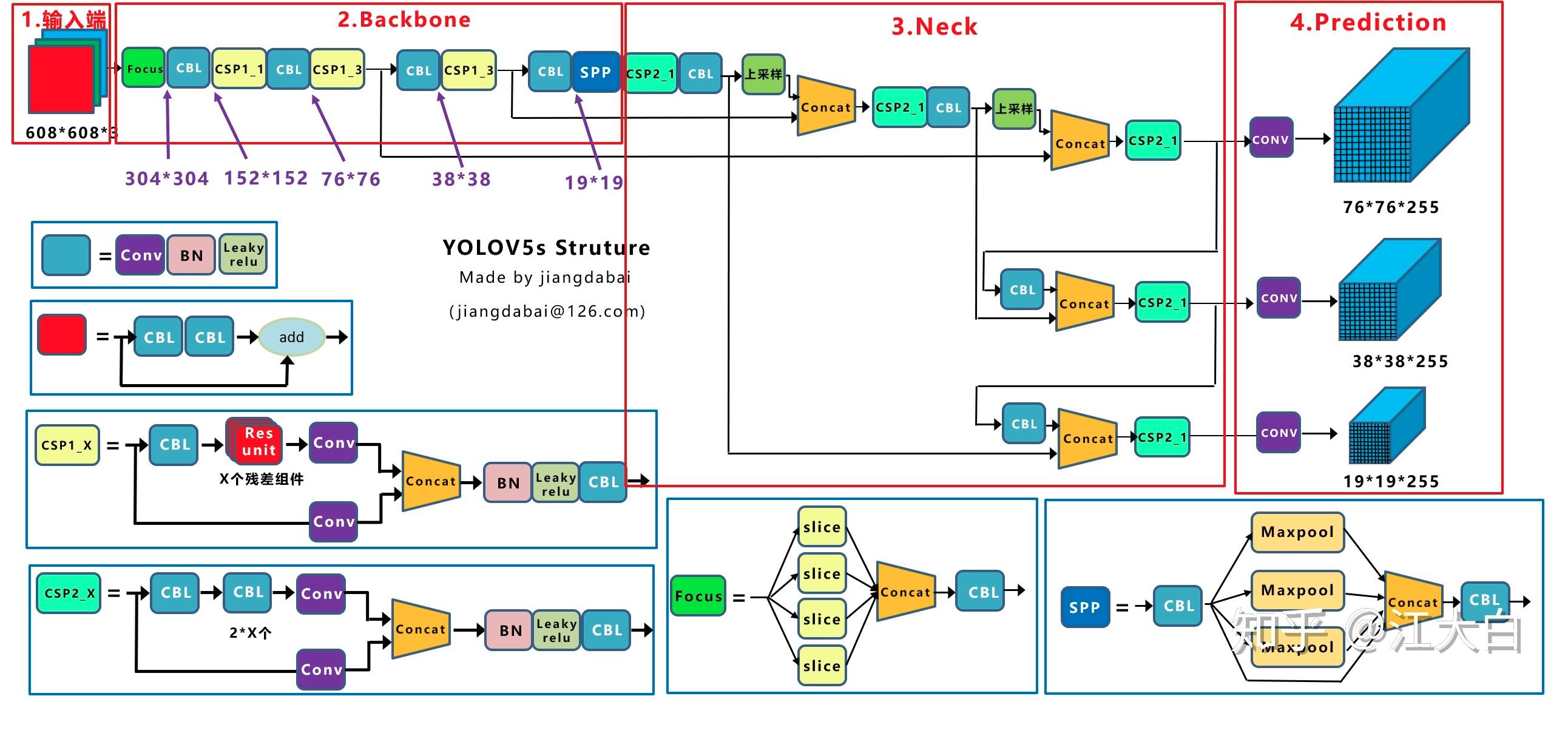
Yolov5与Yolov3的一些主要的不同点:
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
Yolov5的算法性能测试图:
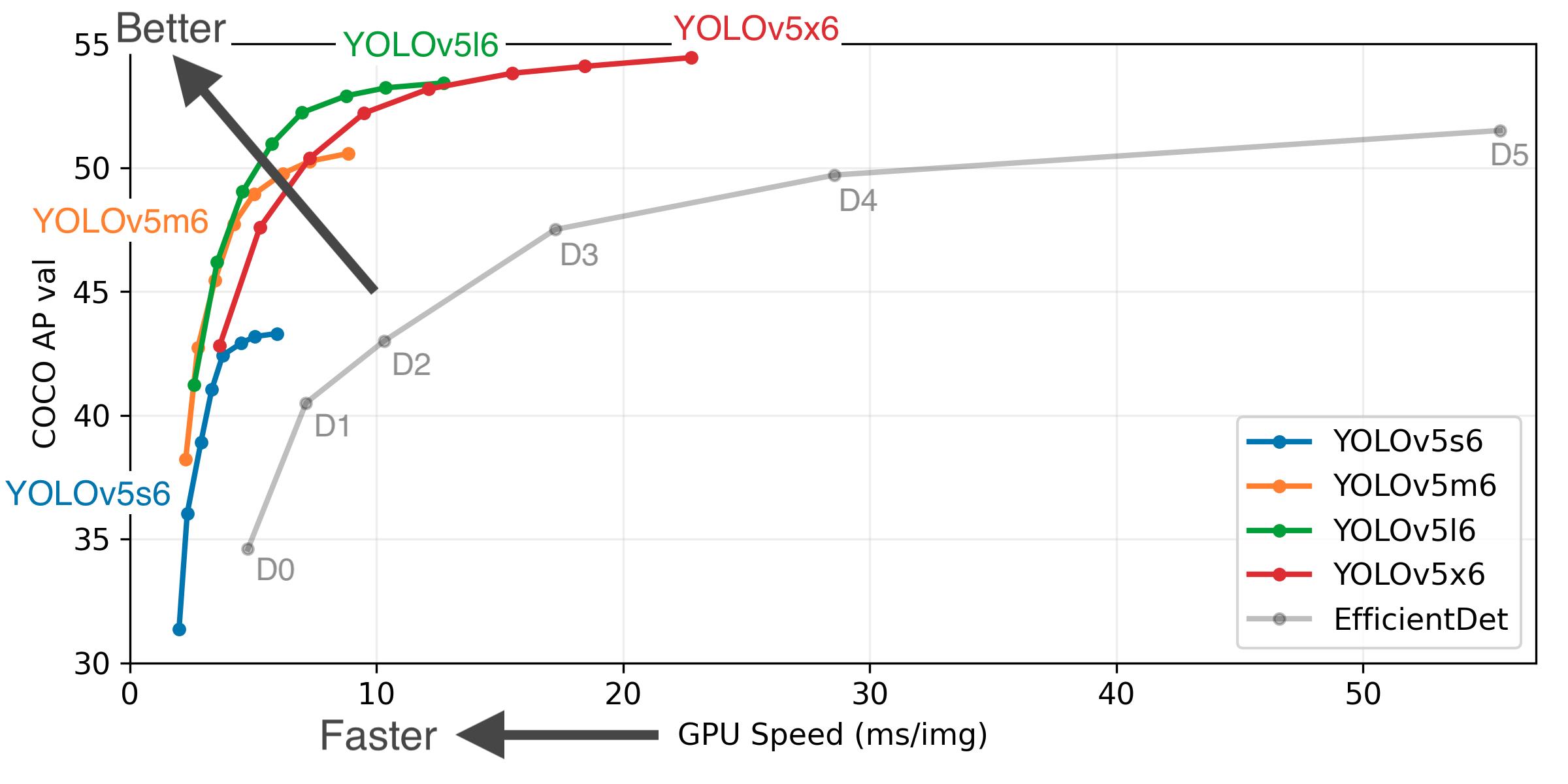
上图可以看出,Yolov5s网络最小,速度最少,AP精度也最低。但如果检测的以大目标为主,追求速度,倒也是个不错的选择。其他的三种网络,在此基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
二、yolo_v5改进点详解
1 输入端改进
1)Mosaic数据增强
Yolov5的输入端采用了和Yolov4一样的Mosaic数据增强的方式。Mosaic数据增强提出的作者也是来自Yolov5团队的成员,不过,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果还是很不错的。

2) 自适应锚框计算
在网络训练中,先设定一个初始的先验框。网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。Yolov5在Coco数据集上初始设定的锚框:

在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
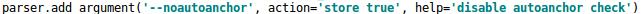
控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
3)自适应图片缩放
目标检测算法常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。例如Yolo算法中常用416*416,608*608等尺寸。对下面800*600的图像直接缩放到416*416。

作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
操作步骤:
第一步:计算宽高的缩放比例
原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。

第二步:计算缩放后的尺寸(以长边为基准)
原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。

第三步:☆计算黑边填充数值(这里是重点)
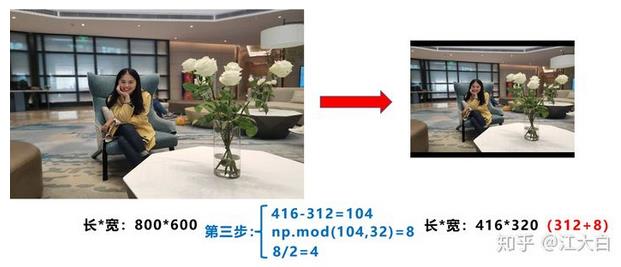
将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式(32是网络下采样的步长),得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
此外,需要注意的是:
- a. 这里大白填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一样的效果。
- b. 训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
- c. 为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。
- 个人见解:一张800*600的图片,如果训练和测试使用的填充方式不一样,感觉会导致物体的形变不一致,对检测的效果是有影响的。理论上训练和测试的填充方式应该一致,但是作者应该是考虑到训练时一个batch内的尺寸必须一致,所有训练时没有采用这种填充方式。
2 Backbone的改进点
1)Focus结构
Focus结构,在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。比如右图的切片示意图,4*4*3的图像切片后变成2*2*12的特征图。注意:切片不是像切蛋糕那样直接十字切成四份,是通过采样的方式,在四个区域分别采样。
以Yolov5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。
需要注意的是:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的数量有所增加,先注意下,后面会讲解到四种结构的不同点。
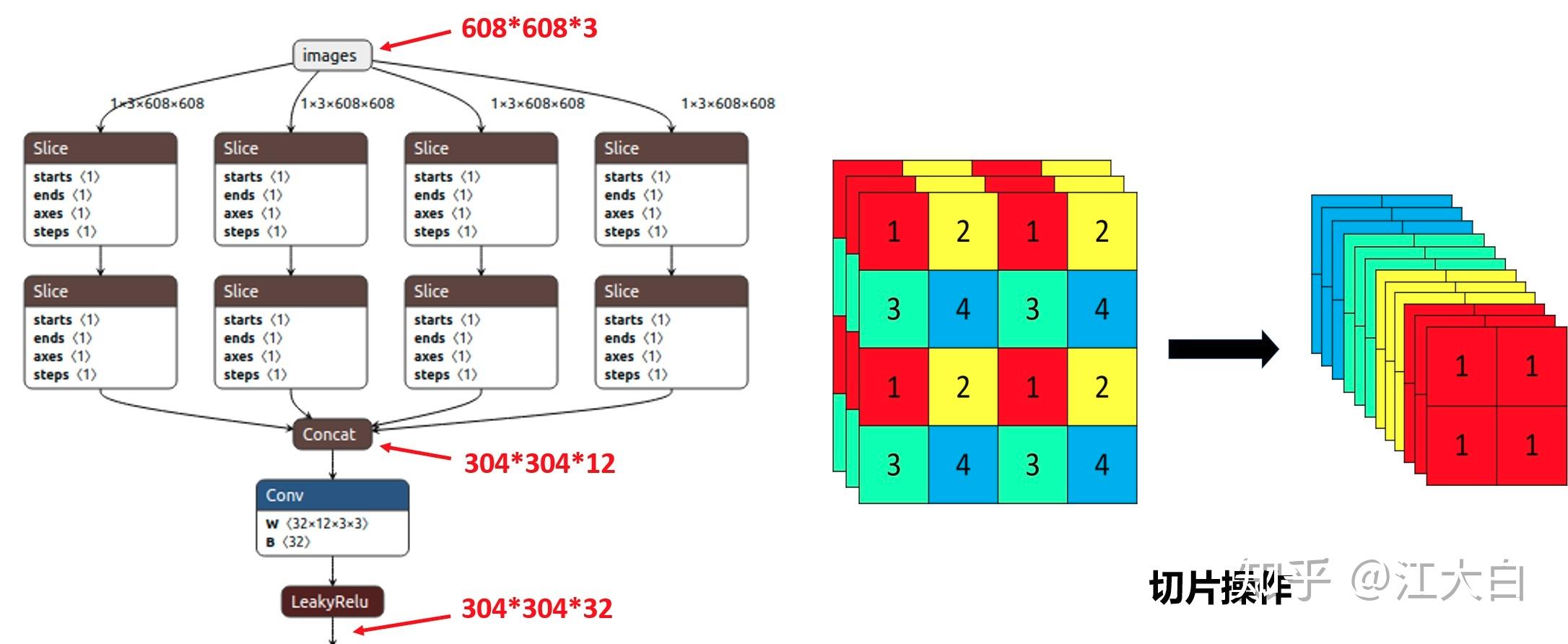
2)CSP结构
Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
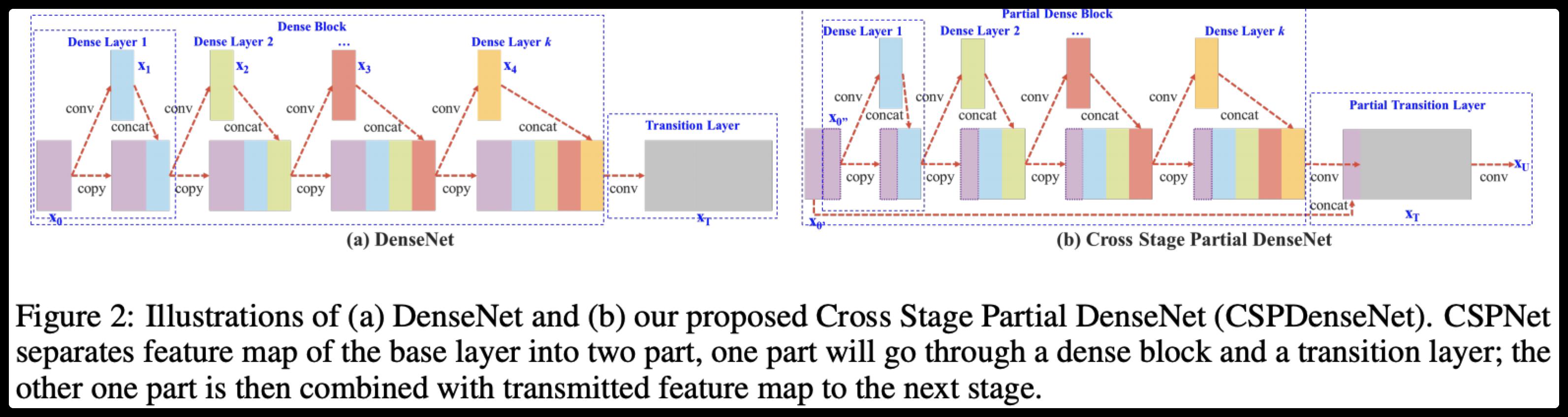
CSPNet全称是Cross Stage Paritial Network(跨阶段的平行网络),主要从网络结构设计的角度解决推理中从计算量很大的问题。CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
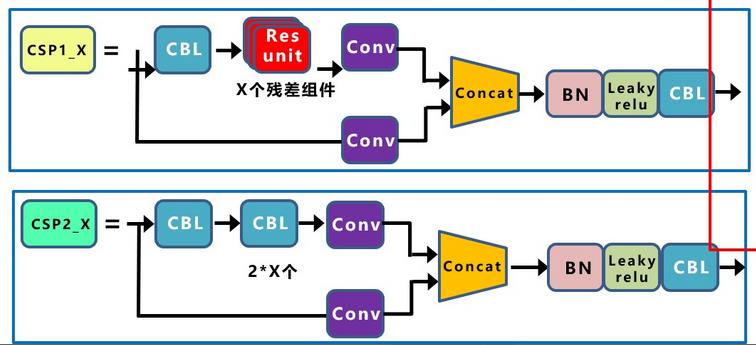
3 Neck部分的改进点
1)FPN处增加PAN结构
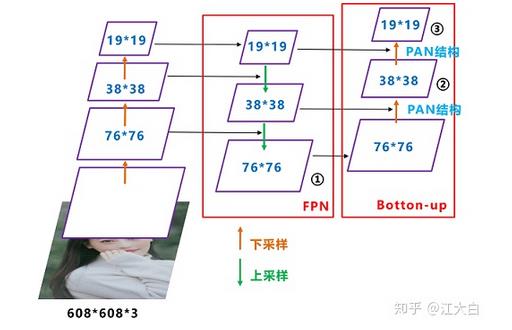
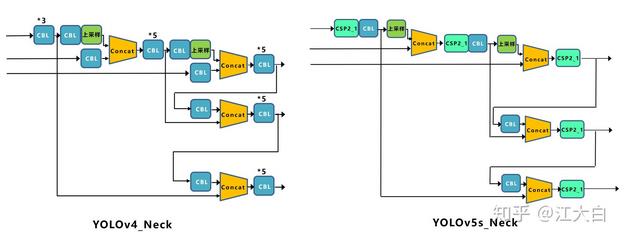
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
4 输出端改进点
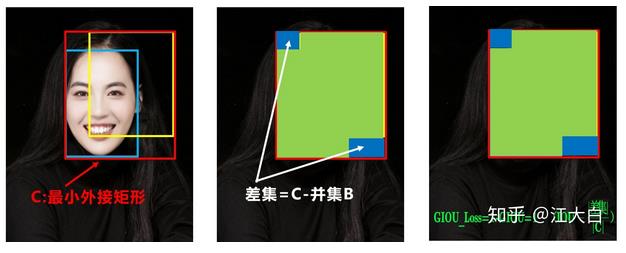
1)Bounding box损失函数:GIoU
Yolov5中采用其中的GIOU_Loss做Bounding box的损失函数。而Yolov4中采用CIOU_Loss作为目标Bounding box的损失。
2)nms非极大值抑制
Yolov5中采用加权nms的方式。参看yolov4的nms部分。
三、Yolov5四种网络结构的不同点
Yolov5代码中的四种网络,和之前的Yolov3,Yolov4中的cfg文件不同,都是以yaml的形式来呈现。而且四个文件的内容基本上都是一样的,只有最上方的depth_multiple和width_multiple两个参数不同。
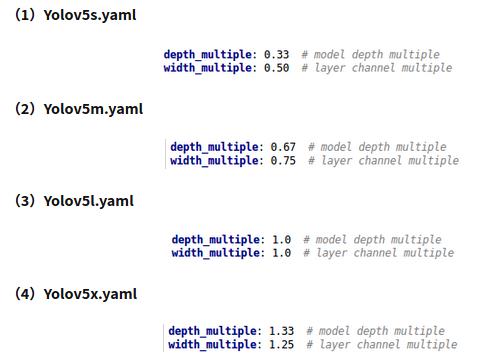
四种结构就是通过上面的两个参数,来进行控制网络的深度和宽度。其中depth_multiple控制网络的深度,width_multiple控制网络的宽度。
深度和宽度简单解释:
- 深度depth_multiple:指的是CSP结构中残差块的数量,残差块的数量越多,网络就越深。
- 宽度width_multiple:指的是卷积核的维度,卷积核的维度越大,网络越厚,yolov5这是用宽度来表示。
1)depth_multiple控制网络深度
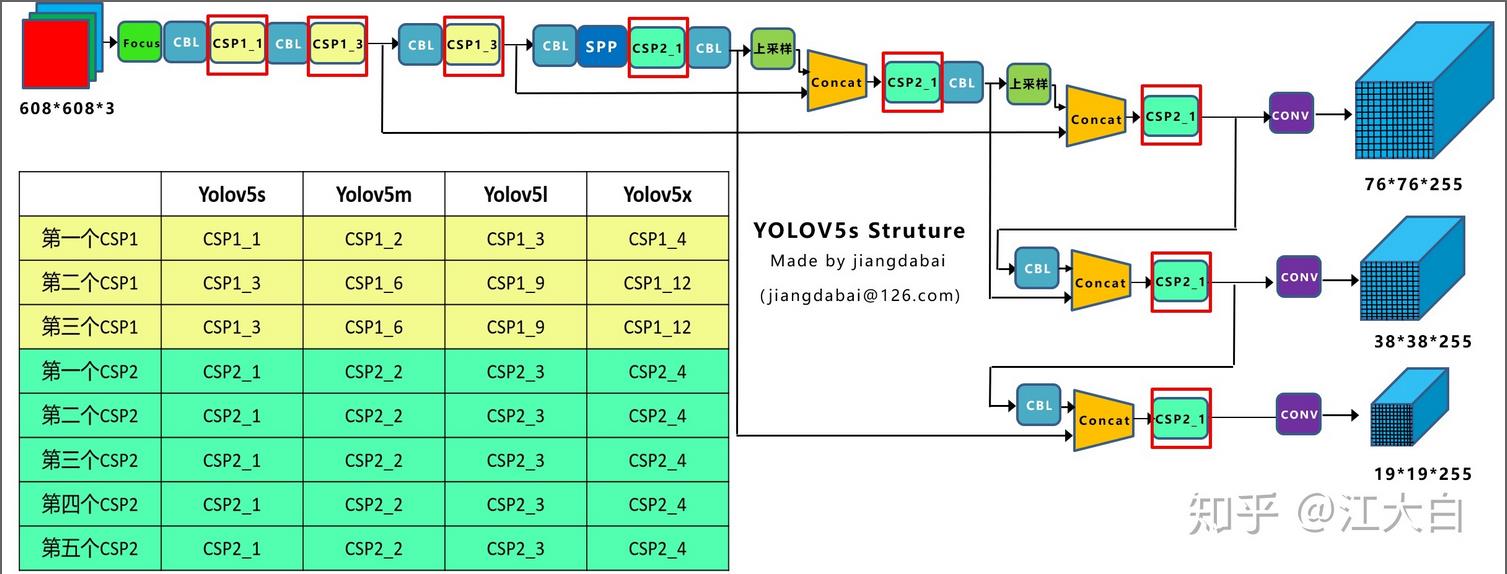
在上图中两种CSP结构,CSP1和CSP2,其中CSP1结构主要应用于Backbone中,CSP2结构主要应用于Neck中。
需要注意的是,四种网络结构中每个CSP结构的深度都是不同的。a.以yolov5s为例,第一个CSP1中,使用了1个残差组件,因此是CSP1_1。而在Yolov5m中,则增加了网络的深度,在第一个CSP1中,使用了2个残差组件,因此是CSP1_2。Yolov5l中使用了3组,Yolov5x中使用了4组。
Yolov5中,网络的不断加深,也在不断增加网络特征提取和特征融合的能力。
2)width_multiple控制网络宽度(厚度)
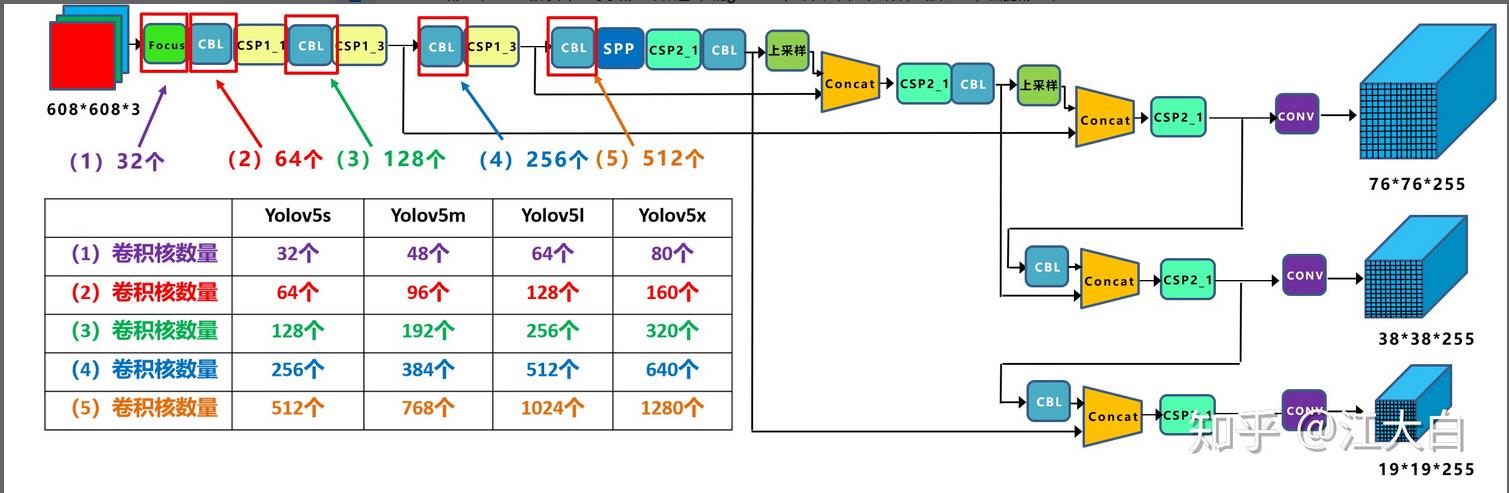
如上图表格中所示,四种yolov5结构在不同阶段的卷积核的数量都是不一样的,因此也直接影响卷积后特征图的第三维度,即厚度。
a.以Yolov5s结构为例,第一个Focus结构中,最后卷积操作时,卷积核的数量是32个,因此经过Focus结构,特征图的大小变成304*304*32。而yolov5m的Focus结构中的卷积操作使用了48个卷积核,因此Focus结构后的特征图变成304*304*48。yolov5l,yolov5x也是同样的原理。
当然卷积核的数量越多,特征图的厚度,即宽度越宽,网络提取特征的学习能力也越强。
以上是关于目标检测(10) Mosaic 数据增强方法,附Python完整代码的主要内容,如果未能解决你的问题,请参考以下文章