操作系统-AOSOA
Posted living_frontier
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了操作系统-AOSOA相关的知识,希望对你有一定的参考价值。
一、个人感受
1.1 权衡
在我写这份报告的时候,已经是 6 月 30 号了,经历了一个学期的“折磨”,我面对终点,已经没啥感觉了,就想着赶快呼噜完了就完事了。其实做这个项目最大的体会就是“人力有穷,一切皆权衡”。我当时选择这个项目,其实就两个原因:
- 做出来贼装逼
- 据说可以从中体会很多知识
现在看来,确实这两点都达到了,对于装逼层面而言,确实只要跟人提起“我是做移植操作系统”的,基本上就没人可以在装逼方面压过你了。从中学到的知识也是很多很丰富的,可以说指导书许诺的东西,我已经拿到了,但是我从来没有想过,我会付出以下代价:
- 用在其他课业上面的时间会很少,分数可能会下降
- 每个月都有那么几天被程序折磨的情绪失常
- 编译比赛没办法从头到尾投入
- 每天活在完成不了挑战性任务的恐惧里
- 经常睡不着或者睡不了
- 陪不了女朋友
当然很多情况都是因为我个人原因导致的,可能我再聪明一点,再勤奋一点,再坚强一点,可能这些问题都不会发生。或者再大气一点,发生了这些问题之后并不彷徨。不过我觉得哈,其实这个时候统计规律最说明一切了,从身边统计学来看,在移植操作系统任务下达后,我身边几乎每个人都摩拳擦掌,跃跃欲试,然后大概过了一个月,真正想做的人我认识的还剩下 10 个,当然跟我认识的人不多有关。到现在,从助教哥哥处获得的消息,整个 6 系和 21 系,进行 armv8 移植的人可能只有我和哲哥了(当然也有可能有大佬全程没问助教)。从这些数据可以看出,放弃才是常态,而且是一种很理智的选择。
在我打算介绍具体的知识和实验经过之前,我选择先写下这些话,虽然有一部分是矫情,但是更多的是,我意识到,最难解决的 bug 不在电脑上,而是在心态上。有的时候再坚持一下,再多做一个测试,再多想一种可能,再多问一个人,或许就 de 出来了。但是真的完全就不想再动了,因为自己内心知道自己就算做出来了,也是得不偿失的,就很难下笔了。
1.2 无问西东
这是哲哥教给我的,就是即使像上面说的一样,是一件很得不偿失的事情。但是是我觉得很多事情不能太计较利益得失,斤斤计较就让生活变得没意思的。就好像我跑步一样,没人逼我跑,我也不求跑得比谁快,我就是享受跑步那种感觉。移植操作系统我就不是很这样,我很担心,很害怕,没写的时候害怕,写了也害怕,写完 lab1 害怕,写完 lab2 也害怕。但是哲哥就很淡然,就感觉他是真的享受整个过程,他从不担心结果如何,他就很享受。
1.3 移植概述
移植其实就是解决一系列 ABI 的问题。我们之前的的操作系统是建立在 mips 处理器上的,现在我们要把它移植到armv8 上,所以很多与硬件接壤的地方都需要有改动。这里粗浅的罗列一下,详细内容会在后面介绍
| lab | 内容 |
|---|---|
| lab0 | 新的交叉编译器的使用 |
| lab1 | 汇编的学习,arm 的异常处理等级 |
| lab2 | arm 的mmu和硬件三级页表查询方式(万恶之源) |
| lab3 | arm 的异常处理 |
| lab4 | 用软件实现 COW 和 Library 机制 |
| lab5 | SD 的读写 |
| lab6 | armv8 的压栈方式 |
二、Aarch64 汇编
2.1 学习资料
这里简要介绍一下。我们使用的是 armv8 的 A64 指令集(Aarch64 叫执行模式,总是就是一种 64 位的东西),是一种 64 位的指令集(armv8 还支持其他的模式,比如 32 位的 A32)。
汇编学习官方提供的就是文档,但是众所周知,文档太难了。所以这里安利这本书,可以对于汇编还有异常处理体系有一个初步的了解。如下

2.2 寄存器
2.2.1 通用寄存器
2.2.1.1 函数 ABI
通用寄存器 x0 ~ x7 是传参寄存器,只要函数的参数少于等于 8 个,那么都会通过这些这些寄存器来传递,第一个参数会被写入 x0,第二个参数写入 x1,以此类推。
同时,对于返回值,我们也是存储在 x0 中的,也就是说,x0 在函数中有两个作用,一个是传递第一个参数,一个是传递返回值。
对于函数的返回地址会存在 x30 中,类似与 mips 中的 ra。
2.2.1.2 异常处理寄存器
arm 中的 x16 和 x17 类似于 mips 中的 k0 和 k1。都可以被利用为异常处理寄存器(就是在异常处理中可劲造,不用担心)。
2.2.1.3 调用者保存和被调用者保存
X9 ~ X15 是调用者保存寄存器,所以需要调用者进行保存和恢复,类似于 MIPS 中的 t 寄存器。
X19 ~ X29 是被调用者保存寄存器,所以需要被调用者进行保存和恢复,类似于 MIPS 中的 s 寄存器。
2.2.2 特殊寄存器
2.2.2.1 零寄存器
xzr 是 64 位的零寄存器。
2.2.2.2 pc
就是 pc,但是对于我们的实验没啥用,因为我们没有指令可以读写这个寄存器。
2.2.2.3 sp
栈指针寄存器,与 mips 不同的是,这个有很多个这样的栈指针,比如 sp_el0, sp_el1.... 。也就是说在 EL0 (用户态)的时候的栈指针使用的是 sp_el0 ,EL1 (内核态)使用的栈指针是 sp_el1。这其实对应了用户态和内核态的使用的栈是不同的。
2.2.2.4 elr
存放返回地址,类似于 mips 中的 epc
2.2.2.5 CurrentEL
可以查看当前的异常等级。
2.2.3 系统寄存器
2.2.3.1 SCR
异常等级为 3 的时候的配置寄存器,具体的参数如下
// 这位与安全内存有关,但是我不知道啥意思
#define SCR_NS 1
// 这位置 1 说明是 Arch64 而置 0 说明是 Arch32
#define SCR_RW (1 << 10)
更加详细的可以参照白书的 P144 页。
2.2.3.2 HCR
异常等级为 2 的时候的配置寄存器,具体参数如下
#define HCR_RW (1 << 31)
// SWIO hardwired on Pi3, 我不知达到哦啥意思
#define HCR_SWIO (1 << 1)
更加详细的可以参照白书的 P144 页。
2.2.3.3 SPSR
Saved Process Status Register。armv8 应该会维护一个状态寄存器 PSTATE ,当发生异常的时候,会把状态寄存器的值存储到 SPSR 当中。当异常返回的时候,会把 SPSR 的值拷贝到 PSTATE 中。我个人感觉已经可以把二者划等号了。
具体参数如下
// 对应 [9:6] DAIF 意思是关闭中断
#define SPSR_MASK_ALL (15 << 6)
// 对应 [3:0] 设置异常返回哪一个等级,我不知道具体的对应规则
#define SPSR_EL2H (9 << 0)
#define SPSR_EL1H (5 << 0)
另外可以分开访问,比如说 daifset 指的就是 SPSR 的 [9:6] 位。
2.2.3.4 SCTLR
系统控制寄存器,指导书给出了完整配置。
2.2.3.5 TCR
Translation Control Register 翻译控制寄存器,用于控制 TLB 的行为。具体的配置如下
#define TCR_IGNORE1 (1 << 38)
#define TCR_IGNORE0 (1 << 37)
// 内部共享 TTBR1_EL1
#define TCR_ISH1 (3 << 28)
// 内部共享 TTBR0_EL1
#define TCR_ISH0 (3 << 12)
// TTBR1_EL1 外写通达可缓存
#define TCR_OWT (2 << 26)
// TTBR1_EL1 内写通达可缓存
#define TCR_IWT (2 << 24)
// 25 位掩码
#define TCR_T0SZ (25)
#define TCR_T1SZ (25 << 16)
// TG2 的页面是 4K
#define TCR_TG0_4K (0 << 14)
// TG1 的页面是 4K
#define TCR_TG1_4K (0 << 30)
2.2.3.6 TTBR
一级页表的起始地址存储在这里。需要注意是物理地址。
2.2.3.7 FAR
far 寄存器里存的就是 BADDR。
2.2.3.8 ESR
esr 寄存器就是同步异常的错误原因,类似与 MOS 中的 Cause。可以在 P150 查到。
2.3 汇编指令
这个部分非常的冗杂,但是我觉得只需要记住两点,就可以轻松解决
- 看白书,书上介绍的很详细
- 用的时候查,不需要啥都会
这里总结一下用到的指令 ldr, str, msr, mrs, orr, and, cmp, bne, adr, eret, bl, b, br, lsr 等,基本上跟机组的 P7 的量差不多。
2.4 内联汇编
其实这个项目不用内联汇编也可以实现(我就没用),但是还是顺手学了一下,记录如下
这个函数将 value 的值加上 p 指向的值,并且将结果存储在 result 中
void my_add(unsigned long val, void *p)
unsigned long tmp;
int result;
asm volatile
"1: ldxr %0, [%2]\\n"
"add %0, %0, %3\\n"
"stxr %w1, %0, [%2]\\n"
"cbnz %w1, 1b\\n"
: "+r"(tmp), "+r"(result)
: "r"(p), "r"(val)
: "cc", "memory"
;
首先这个部分叫做指令部分,其实就是一条一条的汇编
"1: ldxr %0, [%2]\\n"
"add %0, %0, %3\\n"
"stxr %w1, %0, [%2]\\n"
"cbnz %w1, 1b\\n"
会发现这些汇编里面有 %0, %w1, %2 这类的东西,这被称为样版操作数,其实就是 C 语言中变量的“化身”。
我们在下面这两个语句中声明这种样版关系
: "+r"(tmp), "+r"(result) // output
: "r"(p), "r"(val) // input
可以看到这里出现了 C 语言的变量,output 代表要对变量进行写操作,而 input 表示只对变量进行读操作,其中就有 tmp -> %0, result -> %1, p -> %2, val -> %3 的对应关系。
至于 "+r" 就表示要关联一个可读可写的寄存器,而 "=r" 则表示一个只写的寄存器。之后类似
因为在这个函数中,我们修改了状态寄存器(通过 cbnz 指令),所以要在最后一个部分声明 cc,因为改变了内存,所以要声明 memory 这最后的部分叫做“损坏部分”,大致是为了维护寄存器不破坏原意形成的。
三、开发工具
3.1 manjaro
这个必须要强调,真的是重中之重,因为没有有一个 Linux 的开发环境,就意味着你要使用虚拟机完成挑战性任务。咱不说这个意味着一般情况只能使用命令行,咱就说开发的时候能忍,但是读代码的时候呢?移植操作系统的很强调对于 MOS 源码的理解,我觉得只有像 vscode 这种工具才可以方便代码的阅读,vim 的局限性还是太大了一些(不排除大佬)。
本地开发也可以利用 manjaro + docker 实现,然后挑战性任务也可以在 manjaro 上做,而且之后学习也会用得到,我觉得是个很好的东西。
我第一次装 manjaro 是叶哥哥帮我装的,这个人号称 30 分钟结束战斗,然后花了 3 个小时,不过是真的强悍,100G 的 manjaro 陪伴了我这个学期。明天我就要卸掉它了,十分感慨。明天我要自己装一个,可能会写一个攻略。
3.2 交叉编译器
直接在应用商店就有装的,所以我也没上官网去看
| 条目 | 环境 | 备注 |
|---|---|---|
| 交叉编译器 | aarch64-none-elf-gcc | 在应用市场下载安装 |
| 硬件模拟器 | QEMU emulator version 5.0.0 | 命令行安装 |
| 编辑器 | vscode |
Lab 0
manjaro
虽然指导书说可以使用 WSL 或者其他的命令行界面进行项目开发,但是从我这个菜鸡的角度来看,如果没有 vscode ,我是不可能完成整个的移植操作系统开发的。而且为了装这个 manjaro,花费的时间要远远比装交叉编译器之类的东西要花的时间久(要是没有叶哥哥和哲哥的帮助,这步就卡死了)。不过自从装上之后,开发真的势如破竹。而且 OS 实验也可以本地开发了,堪称我这个学期做过作为明智的决定。
实验环境
| 条目 | 环境 | 备注 |
|---|---|---|
| 本机操作环境 | manjaro | |
| 交叉编译器 | aarch64-none-elf-gcc | 在应用市场下载安装 |
| 硬件模拟器 | QEMU emulator version 5.0.0 | 命令行安装 |
| 编辑器 | vscode |
思考题
Linux Targeted 和 Bare-Metal 分别有怎样的含义呢?
这说的是交叉编译器的两种模式,Bare-Metal 是裸机模式(这里不会)
大小端的差异是由什么决定的?
大小端是 CPU 实现的访存接口限制,同时需要,编译器将高级的 C 语言编译成机器语言,在这过程中调整了大小端。
Lab 1
内核编译运行
内核的编译运行需要采用新的交叉编译器,可以采用 MOS 提供的方法,写一个 include 文件优化代码接口
// include.mk
CROSS_COMPILE := aarch64-none-elf-
CC := $(CROSS_COMPILE)gcc
CFLAGS := -Wall -ffreestanding -g
LD := $(CROSS_COMPILE)ld
# OC is used to transfer the file from one format to another format
# We use it to transfer the kernel from the elf to img
OC := $(CROSS_COMPILE)objcopy
需要注意的是,qemu 模拟器需要烧录 img 文件,所以相比于 gxemu 的直接烧录 .elf 文件,需要利用 objcopy 工具将 elf 格式转换为 img 格式后完成烧录,语句如下
// MAKEFILE
vmlinux: $(modules)
$(LD) -o $(vmlinux_elf) -T $(link_script) $(objects)
$(OC) $(vmlinux_elf) -O binary $(vmlinux_img)
此外,在之后的实践中,我发现将目标文件的符号表打印出来,可以方便定位 bug,故有了新的命令
// MAKEFILE
all: $(modules) vmlinux
$(CROSS_COMPILE)objdump -alD $(vmlinux_elf) > ./kernel.symbol
UART
这里参考了指导书提供的方案,我把和GPIO相关的宏放到了gpio.h 中, UART 的宏定义和 uart 的函数放在 uart.c 中。最后也需要在模拟器中声明
// MAKEFILE
run:
qemu-system-aarch64 -M raspi3 -serial null -serial stdio -kernel $(vmlinux_img)
这里需要强调的是,因为没有开启 mmu 此时我的 MMIOBASE 是一个物理地址,在之后开启以后,需要修改到高地址区
// old
#define MMIO_BASE (0x3F000000)
// new
#define MMIO_BASE (0x3F000000 + 0xffffff8000000000)
内核启动
因为处理器有四个核,我们只需要一个核,所以首先先选出一个核进行运行(0 号核)
.section ".text.boot"
_start:
// X1 will store the ID of processor, different processor has different ID
mrs X1, MPIDR_EL1
and X1, X1, #3
// Only the processor who has the ID equals 0 can jump to the _start_master, others will wait
cbz X1, _start_master
然后进行异常等级的配置
_start_master:
// 从这里看异常等级,CurrentEL 的 [3:2] 是异常等级
mrs X0, CurrentEL
and X0, X0, #12
// 如果是 EL2 那么就会发生跳转
cmp X0, #12
bne judge_EL2
// 下面是处理 EL3,但是这种情况一般不会发生
// 异常处理路由指的是异常发生时应当在哪个异常等级处理,SCR_EL3 和 HCR_EL2 都相当于配置寄存器
ldr X2, =(SCR_VALUE)
msr scr_el3, X2
ldr X2, =(SPSR_EL3_VALUE)
msr spsr_el3, X2
adr x2, judge_EL2
msr elr_el3, X2
eret
judge_EL2:
// 如果是 EL1 就会发生跳转
cmp X0, #4
beq clear_bss
// TODO 这里顺序
adr X1, _start
msr sp_el1, X1
// 底下的寄存器在普通手册里没有,但在专有手册中有,也是设置,似乎不用看
// disable coprocessor traps
mov X0, #0x33FF
msr cptr_el2, X0 //essential! give access to SIMD, see reference 1891
msr hstr_el2, xzr //seems not so useful. reference P1931
mov X0, #0xf<<20 //essential! give access to SIMD,see reference 3808
msr cpacr_el1, X0
// 设置 HCR
ldr X0, =(HCR_VALUE)
msr hcr_el2, X0
// 设置 SCTLR,但是此时没有开启 MMU
ldr X0, =(SCTLR_VALUE)
msr sctlr_el1, X0
ldr X0, =(SPSR_EL2_VALUE)
msr spsr_el2, X0
adr X0, clear_bss
msr elr_el2, X0
eret
在配置寄存器中,我们规定了 EL2 异常返回后会返回 EL1。然后配置完成后进行 eret 异常返回,返回 EL1 进行后续操作
clear_bss:
adr X1, __bss_start
ldr W2, =__bss_size
clear_loop:
cbz W2, en_mmu
str xzr, [X1], #8
sub W2, W2, #1
cbnz W2, clear_loop
最后跳到主函数中即可。首先进行 uart 的初始化
uart_init();
链接脚本
经过文档查询,发现入口是 .0x80000 所以修改之后就可以运行
// kernel.lds
. = 0x80000;
思考题
我们的内核为什么从 EL3/EL2 异常级启动而不是 EL1 异常级启动?
我觉得是因为安全性和配置性更高,在 EL2 可以对 EL1 的行为和权限进行配置,比如
在EL1(EL0)状态的时候访问physical counter和timer有两种配置,一种是允许其访问,另外一种就是trap to EL2。
Lab 2
内存地址布局
内核的地址布局:
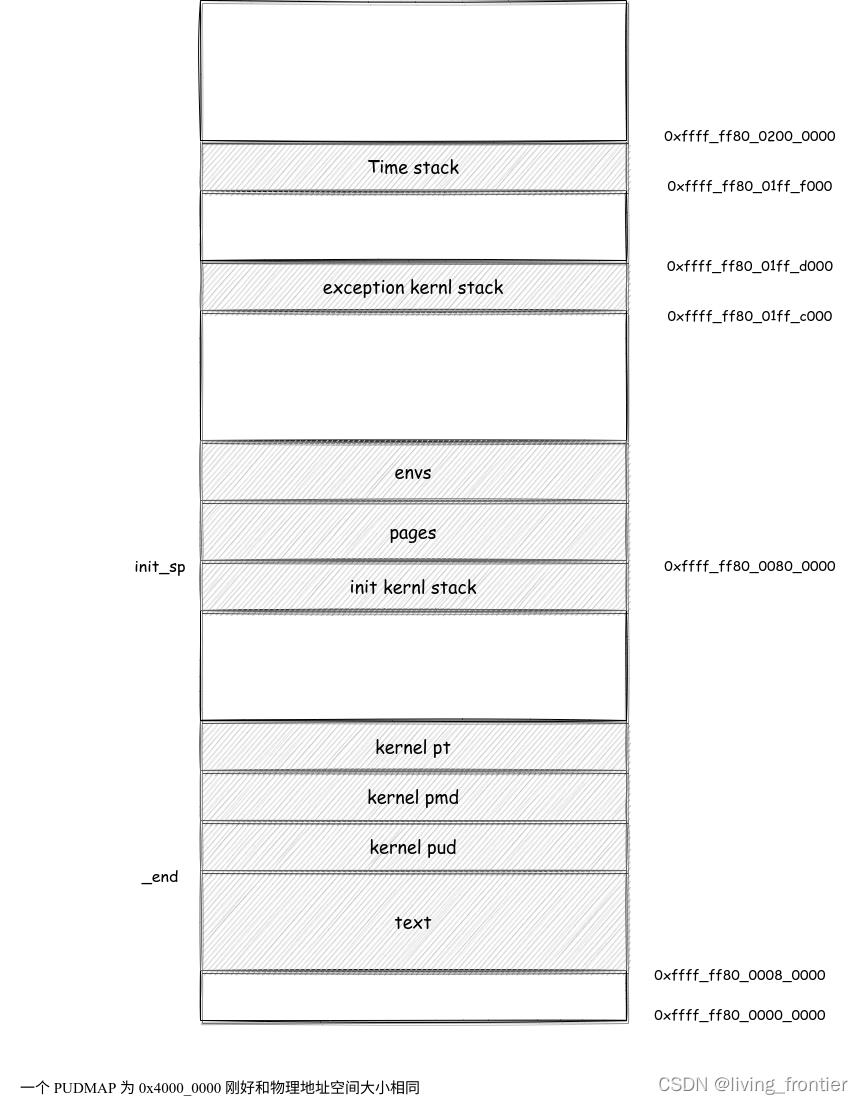
用户进程的地址布局
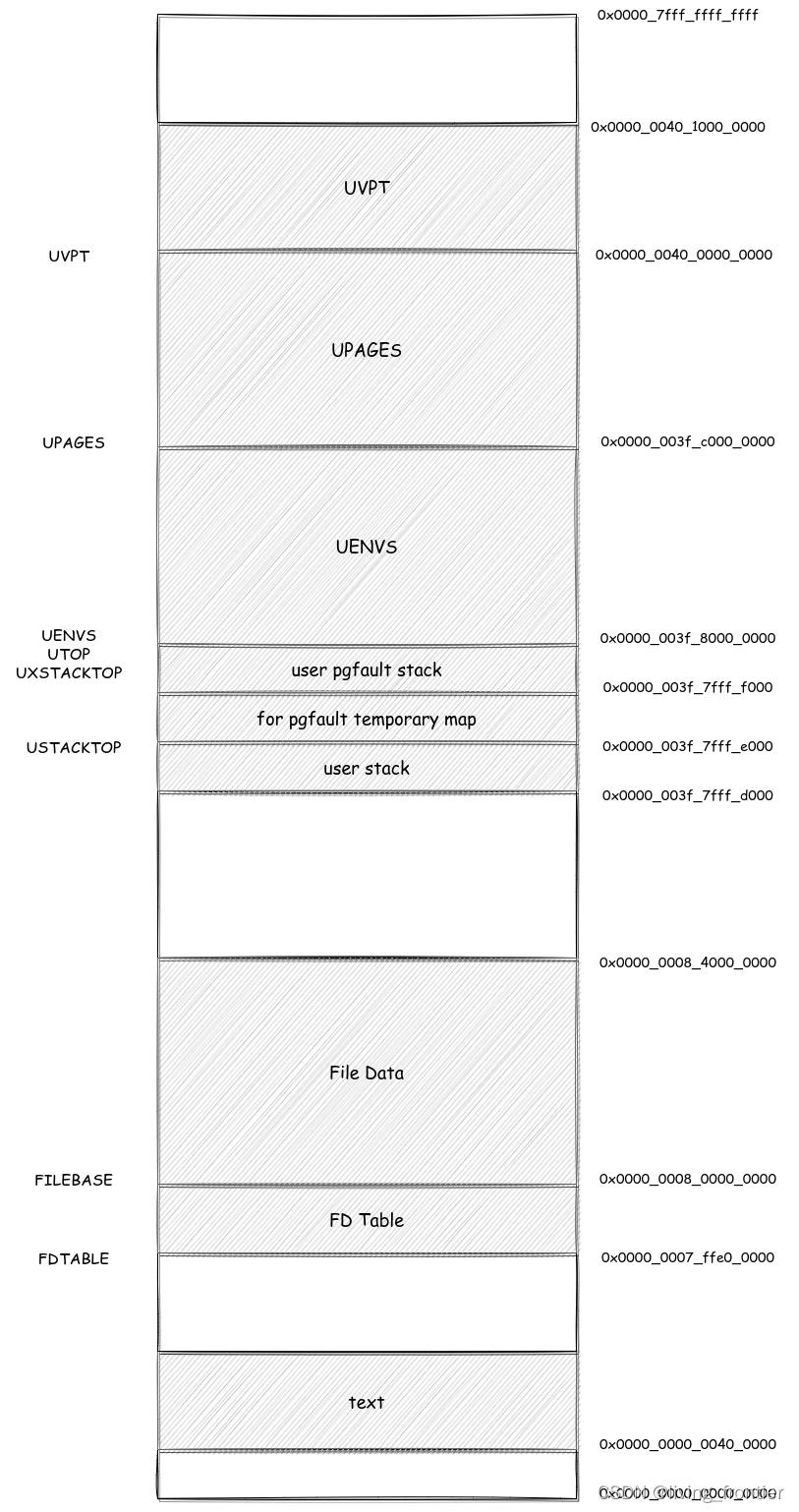
Arm 的地址映射与重定向
与 MOS 在高地址区提供直接映射不同,Arm 并不提供直接的虚拟地址到物理地址的映射,所有的映射都需要依靠页表进行,同时地址映射是一个硬件过程,相比于 MOS 在 TLB 中找不到就触发异常,然后软件查表,Arm 只需要页目录的物理地址即可自动完成查找,报异常的原因是页表项权限位错误,异常处理只需要修改页表项即可。
但是因为没有原生的直接映射,所以在开启 MMU 之前,只能使用物理地址,这里我们做出创新,利用汇编指令的相对寻址,避免了在开启 MMU 之前访问高地址区,在开启 MMU 之后,重新将 PC 重定位到高地址,解决了 bootloader 的难题
en_mmu:
msr spsel, #1
adr X0, init_page_table
blr X0
adr X0, enable_mmu
blr X0
// 这就是重定向
ldr X0, =jump_main
br X0
jump_main:
// TODO 重新设置栈指针
ldr X0, =(init_sp)
mov sp, X0
bl main
b pro_hang
开启 MMU
开启 MMU 的设置如下
#define TCR_VALUE (TCR_T0SZ | TCR_T1SZ | TCR_TG0_4K | TCR_TG1_4K | TCR_IGNORE1 | TCR_IGNORE0 | TCR_ISH1 | TCR_ISH0 | TCR_OWT0 | TCR_IWT0 | TCR_OWT1 | TCR_IWT1)
#define MAIR_VALUE (0x440488)
#define SCTLR_VALUE (0x30d01825)
.global enable_mmu
enable_mmu:
ldr x0, kernel_pud
ldr x1, user_pud
msr ttbr0_el1, x1
msr ttbr1_el1, x1
ldr x0, =(MAIR_VALUE)
msr mair_el1, x0
ldr x0, =(TCR_VALUE)
msr tcr_el1, x0
mrs x0, sctlr_el1
orr x0, x0, #0x1
msr sctlr_el1, x0
ret
除了要移入两个页表以外,还需要设置间接属性寄存器 mair,tlb 控制寄存器 tcr,最后在系统控制寄存器 sctlr 中将 MMU 打开。
三级页表
我们采用 arm 三级页表 4KB 页面设置,需要有一个人工建立高地址区到物理地址线性映射的过程,具体如下
void init_page_table()
uint_64 *pud, *pmd, *pmd_entry, *pte, *pte_entry;
uint_64 i, r, t;
if (freemem == 0)
freemem = (uint_64)_end;
freemem = ROUND(freemem, BY2PG);
// 分配第一级页表
pud = (uint_64 *)freemem;
freemem += BY2PG;
// 在第一级页表上登记上 _end 对应的这一项,需要 user 的原因是可能暴露内核的时候需要
pud[PUDX(pud)] = (freemem | PTE_VALID | PTE_TABLE | PTE_AF | PTE_USER | PTE_ISH | PTE_NORMAL);
// 分配第二级页表
pmd = (uint_64 *)freemem;
freemem += BY2PG;
// 我们在外循环填写第二级页表项
int n_pmd_entry = PHY_TOP >> PMD_SHIFT;
for (r = 0; r < n_pmd_entry; r++)
// 填写二级页表项
pmd_entry = pmd + r;
// 暴露内核的时候可能需要设置为 PTE_USER
*pmd_entry = (freemem | PTE_VALID | PTE_TABLE | PTE_AF | PTE_USER | PTE_ISH | PTE_NORMAL);
// 分配第三级页表
pte = (uint_64 *)freemem;
freemem += BY2PG;
for (t = 0; t < 512; t++)
pte_entry = pte + t;
// 填写三级页表项
i = (r << 21) + (t << 12);
// 这里确实只有当设置成 ReadOnly 的时候能跑起来,我不知道为啥
// 这个 if 里的是内核的程序段,这么看似乎用户进程可能也有这个问题
if (i >= 0x80000 && i < (uint_64)(_data))
(*pte_entry) = i | PTE_VALID | PTE_TABLE | PTE_AF | PTE_NORMAL | PTE_USER | PTE_RO;
else
(*pte_entry) = i | PTE_VALID | PTE_TABLE | PTE_AF | PTE_NORMAL | PTE_USER;
// 将这个二级页表填完
for (r = n_pmd_entry; r < 512; r++)
pmd[r] = ((r << 21) | PTE_VALID | PTE_AF | PTE_USER | PTE_NORMAL);
// 这里是 MMIO 的一种表现形式
pud[PUDX(0x40000000)] = (freemem | PTE_VALID | PTE_TABLE | PTE_AF | PTE_USER | PTE_ISH | PTE_NORMAL);
// 又分配了一个二级页表
pmd = (uint_64 *)freemem;
freemem += BY2PG;
pmd[0] = (0x40000000 | PTE_VALID | PTE_AF | PTE_USER | PTE_DEVICE);
kernel_pud = pud;
user_pud = pud;
return;
页表权限位
只记录一些易错点
PTE_TABLE:每个页表项都需要有这位PTE_AF:每个页表项都需要有PTE_RW:和PTE_RO是同一位,常规方法只能检测PTE_RO
这个页表权限位是真的狗,因为移植操作系统最大的难度就是处理硬件接口,而这里基本上就是最复杂的硬件接口,稍有一个不慎,系统就有可能出现很多莫名其妙的 bug 。所以一定要慎之又慎。
TLB 刷新
虽然似乎可以按照虚拟地址“定点清除”,但是为了稳妥起见,最终选择全部清除 tlb 代码如下
.globl tlb_invalidate
tlb_invalidate:
dsb ishst // ensure write has completed
// tlbi vmalls12e1is // invalidate tlb, all asid, el1.
tlbi vmalle1is
dsb ish // ensure completion of tlb invalidation
isb // synchronize context and ensure that no instructions
// are fetched using the old translation
ret
其中 dsb 是数据同步屏障,isb 是指令同步屏障,tlbi 用于使指令失效。
有趣的是,不知道上面注释掉的这个为什么不可以
// tlbi vmalls12e1is // invalidate tlb, all asid, el1.
内存测试测试
测试函数如下
void debug_print_pgdir(uint_64 *pg_root)
debug("start to retrieval address: %lx\\n", pg_root);
// We only print the first 16 casting
int limit = 2048;
for (uint_64 i = 0; i < 512; i++)
// First Level
uint_64 pg_info = pg_root[i];
if (pg_info & PTE_VALID)
debug("|-Level1 OK %lx|\\n", pg_info);
// So we should go to level 2
uint_64 *level2_root = (uint_64 *)KADDR(PTE_ADDR(pg_info));
for (uint_64 j = 0; j < 512; j++)
uint_64 level2_info = level2_root[j];
if (level2_info & PTE_VALID)
debug("|-|-Level2 OK|\\n");
// So we should go to level 3
uint_64 *level3_root = (uint_64 *)KADDR(PTE_ADDR(level2_info));
for (uint_64 k = 0; k < 512; k++)
uint_64 level3_info = level3_root[k];
if (level3_info & PTE_VALID)
debug("|-|-|-Level3 OK|\\n");
// We should print our info here.
uint_64 va = ((uint_64)i << PUD_SHIFT) | ((uint_64)j << PMD_SHIFT) | ((uint_64)k << PTE_SHIFT);
uint_64 pa = level3_info;
if (limit--)
debug("cast from ...0x%016lx to 0x%016lx... %d %d %d\\n", va, pa, i, j, k);
else
return;
void test_pgdir()
printf("\\n---test pgdir---\\n");
printf("Stage 1 - build up a page table");
uint_64 *pgdir;
uint_32 *data;
struct Page *lut_page;
page_alloc(&lut_page);
pgdir = (uint_64 *)page2kva(lut_page);
struct Page *data_page;
page_alloc(&data_page);
data = (uint_32 *)page2kva(data_page);
for (int i = 0; i < 1024; i++)
data[i] = i; // Fill data into the data page
// Insert data_page into lut_page
extern uint_64 *kernel_pud;
extern uint_64 *user_pud;
uint_64 *kernel = (uint_64 *)KADDR((uint_64)kernel_pud);
uint_64 *user = (uint_64 *)KADDR((uint_64)user_pud);
debug("Kernel pud is %lx , User pud is %lx\\n", kernel, user);
debug("kernel pud value is %lx\\n", kernel[0]);
page_insert(pgdir, data_page, 0x400000, 0);
// page_insert(pgdir,lut_page,PADDR(pgdir),PTE_ISH | PTE_RO | PTE_AF | PTE_NON_CACHE);
// page_insert(user,data_page,0x80000,PTE_ISH | PTE_RO | PTE_AF | PTE_NON_CACHE);
debug_print_pgdir(pgdir);
set_ttbr0(page2pa(lut_page));
// set_ttbr0(PADDR(user));
tlb_invalidate();
data = (uint_32 *)0x400000;
debug("data is %d:%d @0x%lx,0x%lx\\n", 800, data[800], data, page2pa(data_page));
思考题
在 “标准” MIPS 实验中,是如何进行地址翻译的呢?
对于高地址区,MIPS 提供直接映射,对于低地址区,硬件查询 TLB,如果没有办法完成,那么就会触发异常调用 do_refill 函数完成 TLB 的填充和物理页面的插入。
Lab 3
开启异常
原有 MOS 是用软件完成的异常分发,通过异常编号用汇编语言查找异常向量表。在 arm 中,初步的分发是通过硬件实现的,我们只需要构建好异常向量表,如下所示
.align 11
.global vectors
vectors:
handler sync_invalid_el1t // Synchronous EL1t
handler irq_invalid_el1t // IRQ EL1t
handler fiq_invalid_el1t // FIQ EL1t
handler error_invalid_el1t 操作系统-1-操作系统概述
操作系统-1-操作系统概述
1.操作系统的概念,功能和目标
1.1操作系统的概念
操作系统(Operating System,OS):是指控制和管理整个计算机系统的硬件和软件资源,并合理地组织调度计算机的工作和资源的分配,以提供给用户和其他软件方便的接口和环境,它是计算机系统中最基本的系统软件。
- 负责管理协调硬件,软件等计算机资源的工作。
- 为上层的应用程序,用户提供简单易用的服务。
- 操作系统是系统软件,而不是硬件。
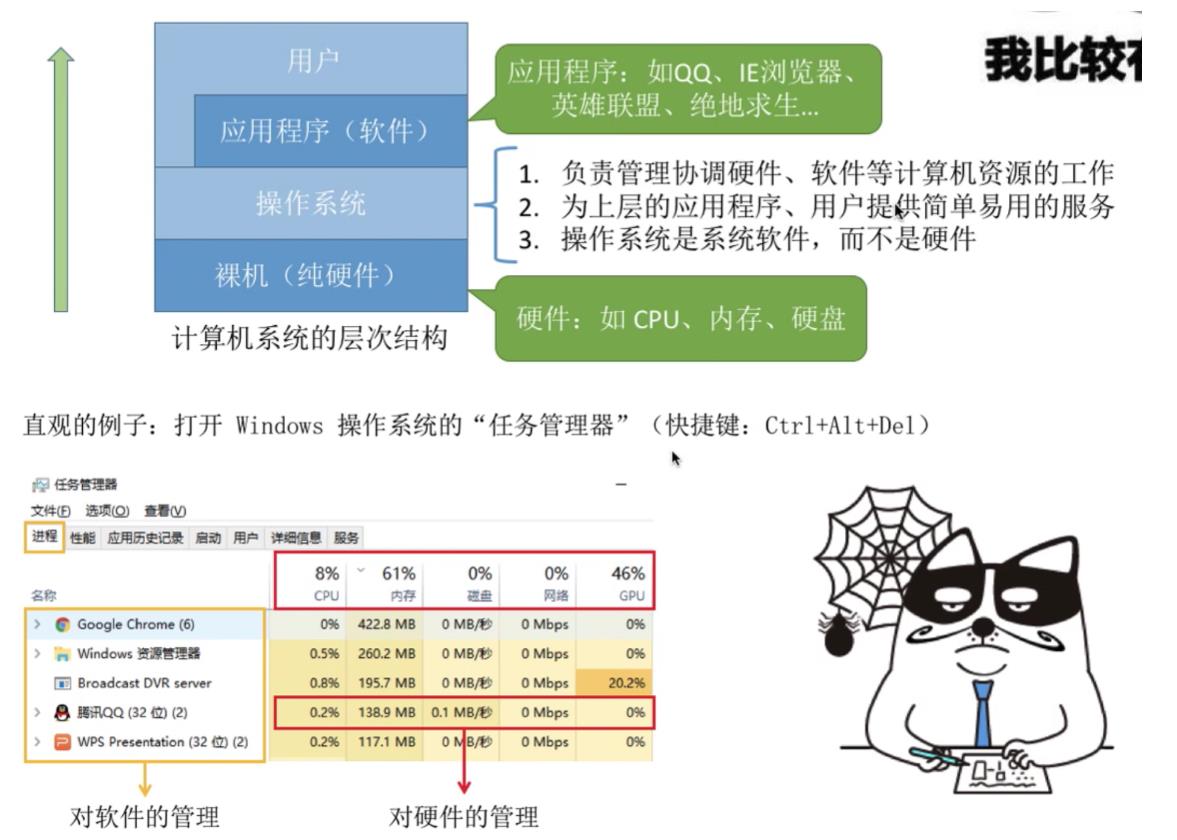
1.2操作系统的功能和目标
-
作为系统资源的管理者
- 提供的功能:
- 处理机管理
- 存储器管理
- 文件管理
- 设备管理
- 目标:安全,高效。

-
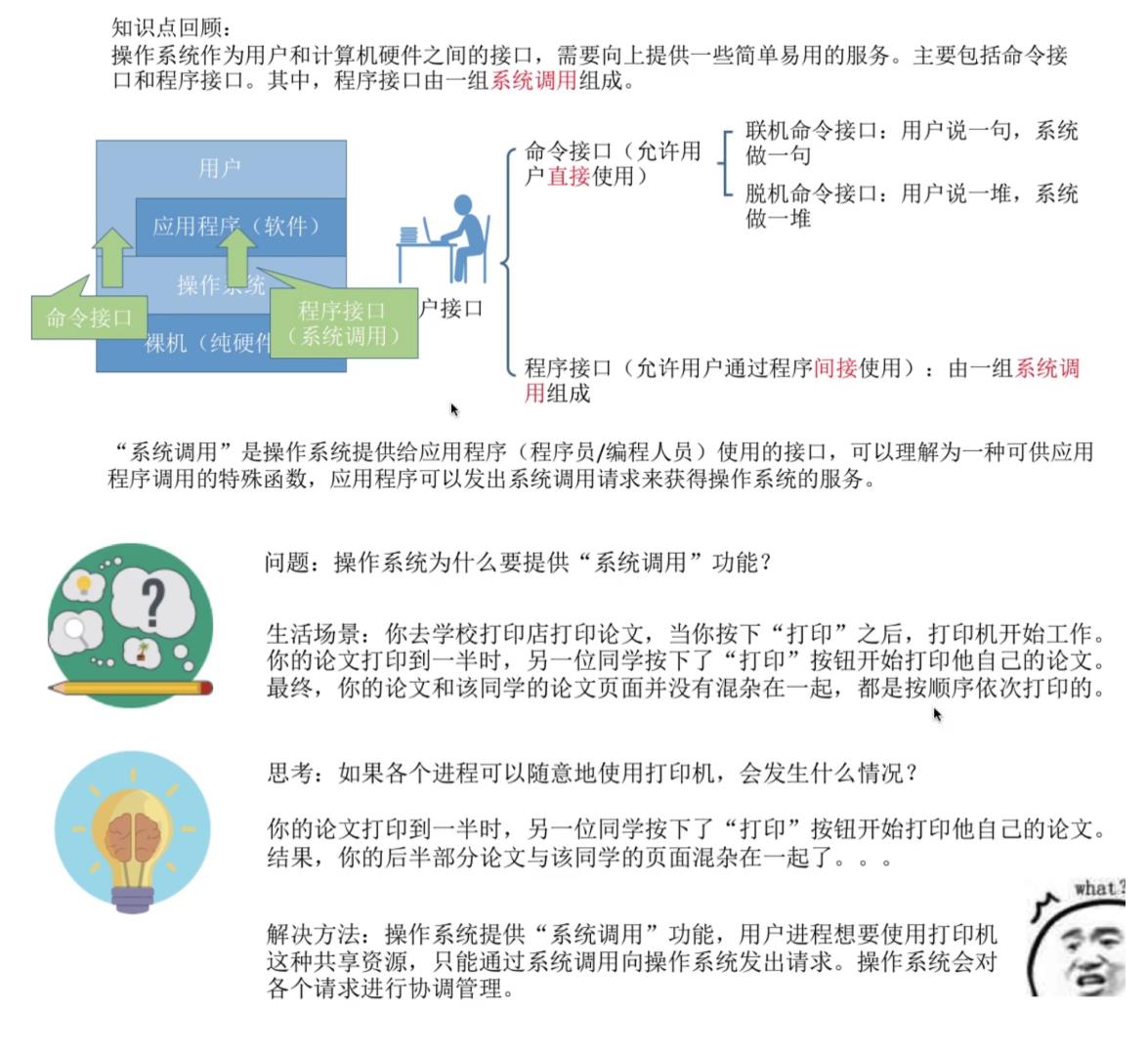
作为用户和计算机硬件之间的接口
- 提供的功能:
- 命令接口:允许用户直接使用。
- 程序接口:允许用户通过程序间接使用。
- GUI(图形用户界面):现代操作系统中最流行的图形用户接口。
- 目标:方便用户使用。
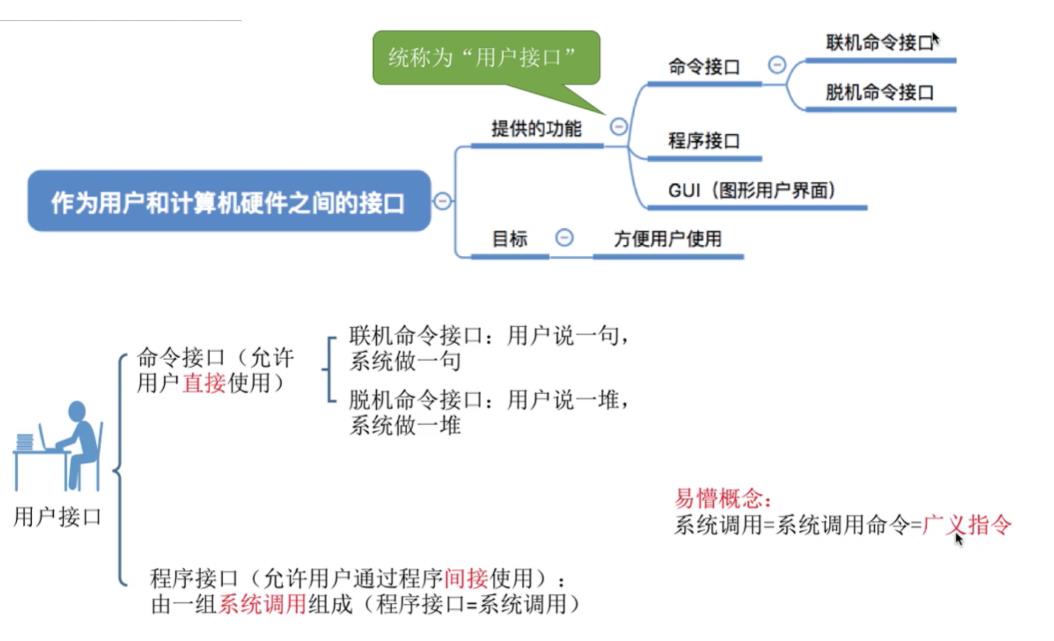
-
联机命令接口实例
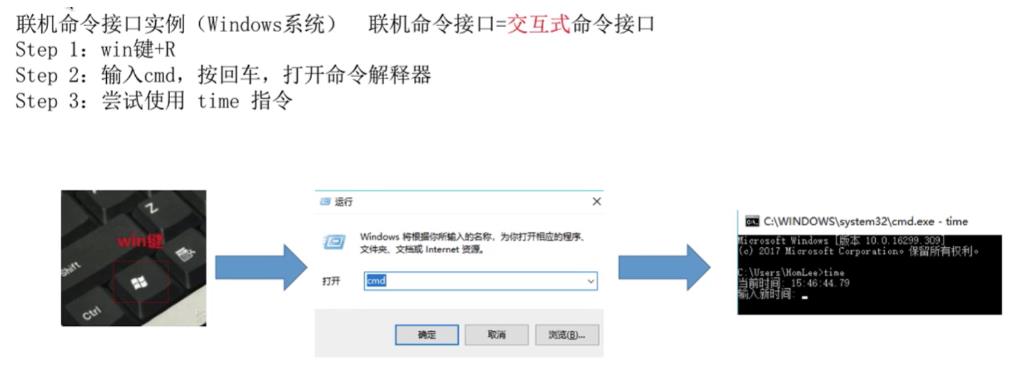
-
脱机命令接口实例
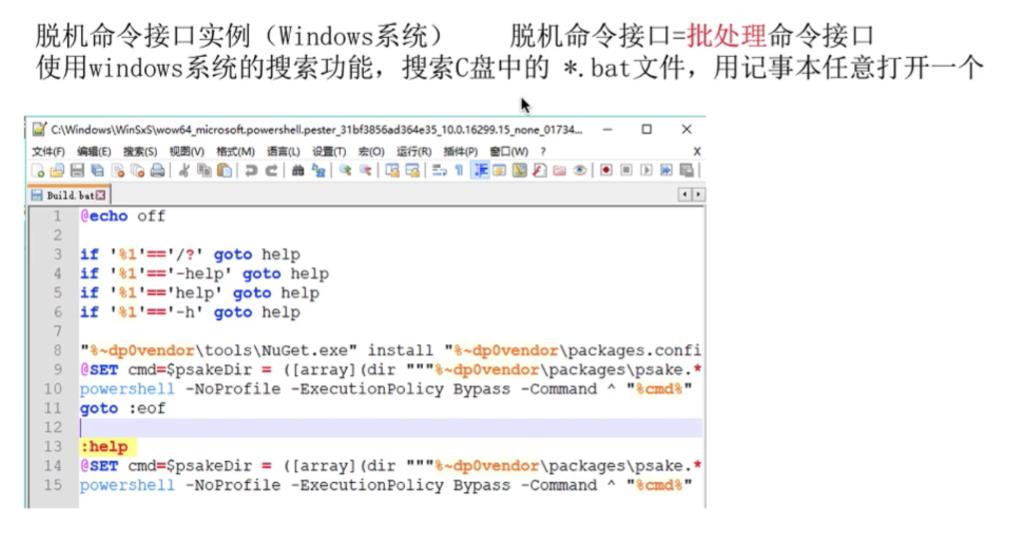
-
程序接口实例

-
GUI实例
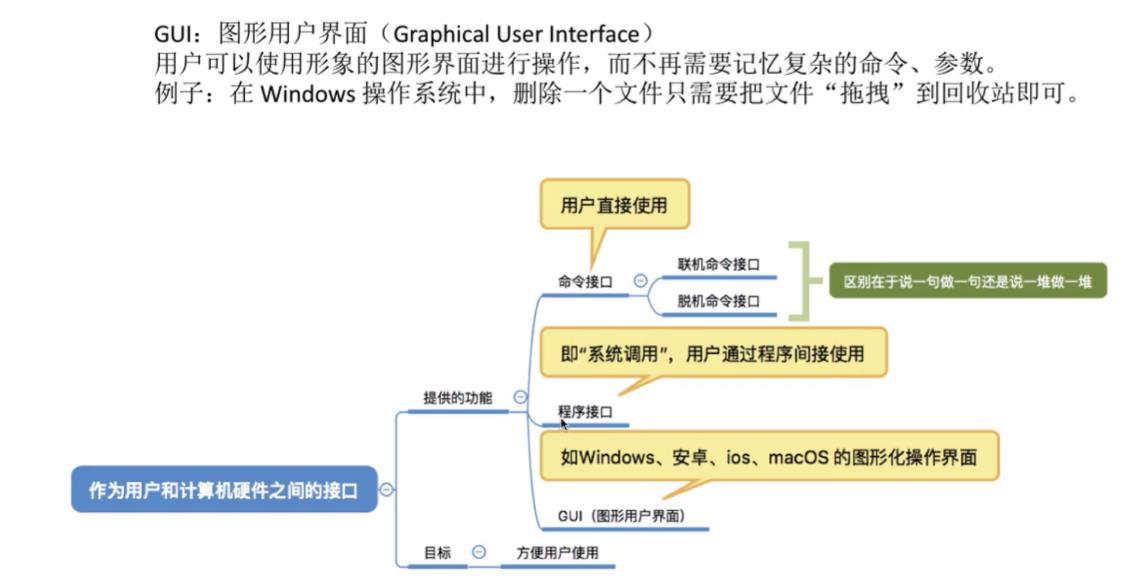
-
作为最接近硬件的层次
- 需要提供的功能和目标:实现对硬件机器的拓展。

1.3小结
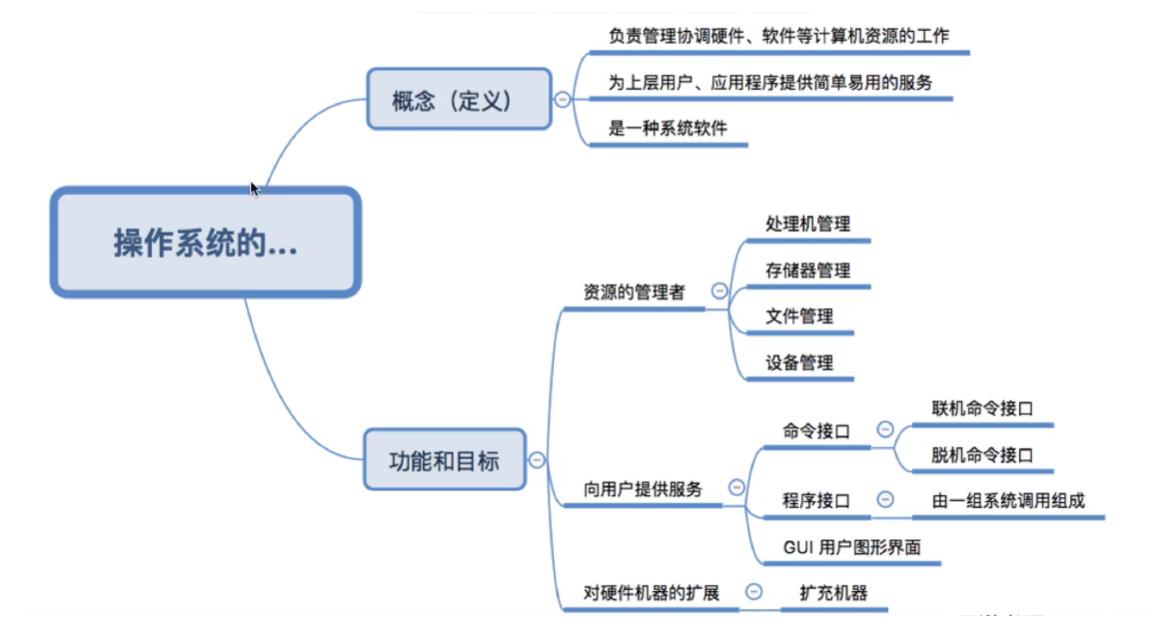
2.操作系统的特征
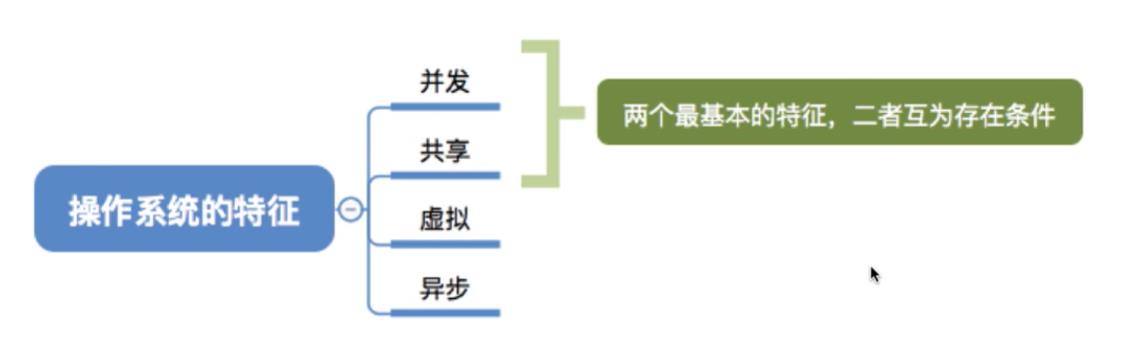
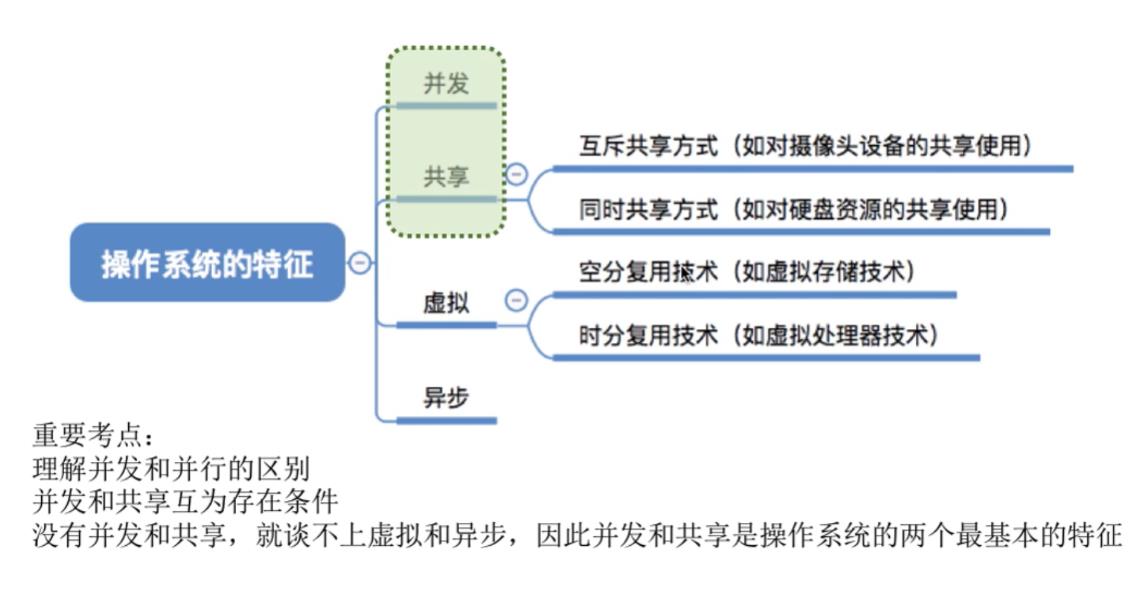
2.1并发
- 并发:指两个或多个事件在同一时间间隔内发生。这些事件宏观上是同时发生的,但微观上是交替发生的。(并行:指两个或多个事件在同一时刻同时发生。)
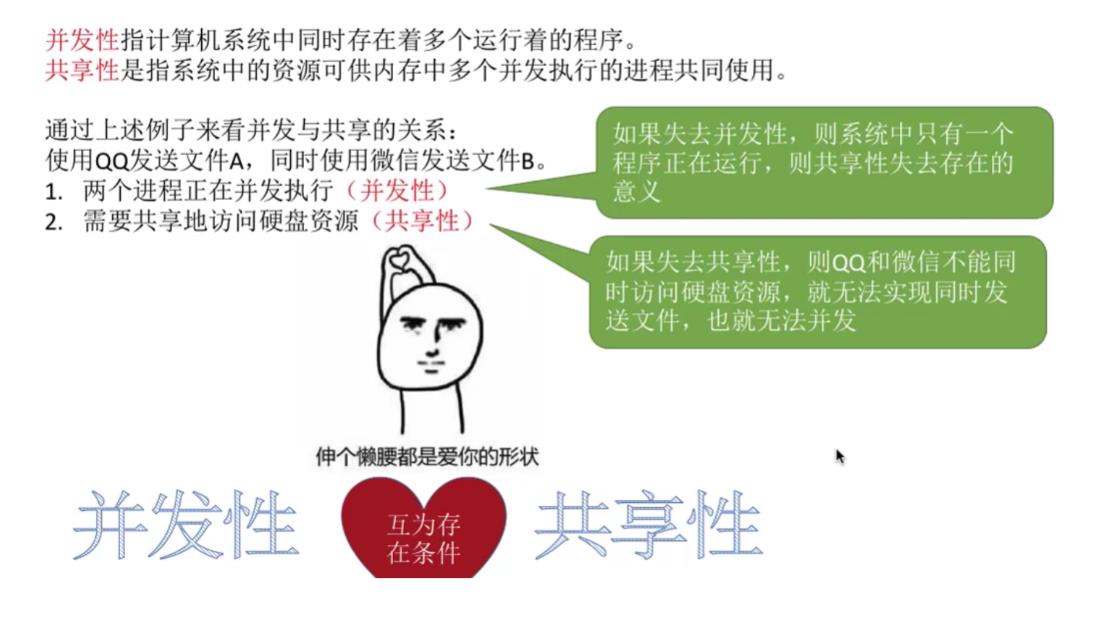
- 操作系统的并发性:指计算机系统中同时存在着多个运行着的程序。
下面的例子可以帮助我们更好的理解并发和并行区别:

2.2共享
-
共享:即共享资源,是指系统中的资源可供内存中多个并发执行的进程共同使用。
-
两种资源共享方式:
-
互斥共享方式:系统中的某些资源,虽然可以提供给多个进程使用,但一个时间段内只允许一个进程访问该资源。
-
同时共享方式:系统中的某些资源,允许一个时间段内由多个进程“同时”对它们进行访问。

- 操作系统的特征–并发和共享的关系:
2.3虚拟
-
虚拟:是指把一个物理上的实体变为若干个逻辑上的对应物。物理实体(前者)是实际存在的,而逻辑上对应物(后者)是用户感受到的。
-
虚拟技术:
- 空分复用技术:如虚拟存储器技术。
- 时分复用技术:如虚拟处理器。
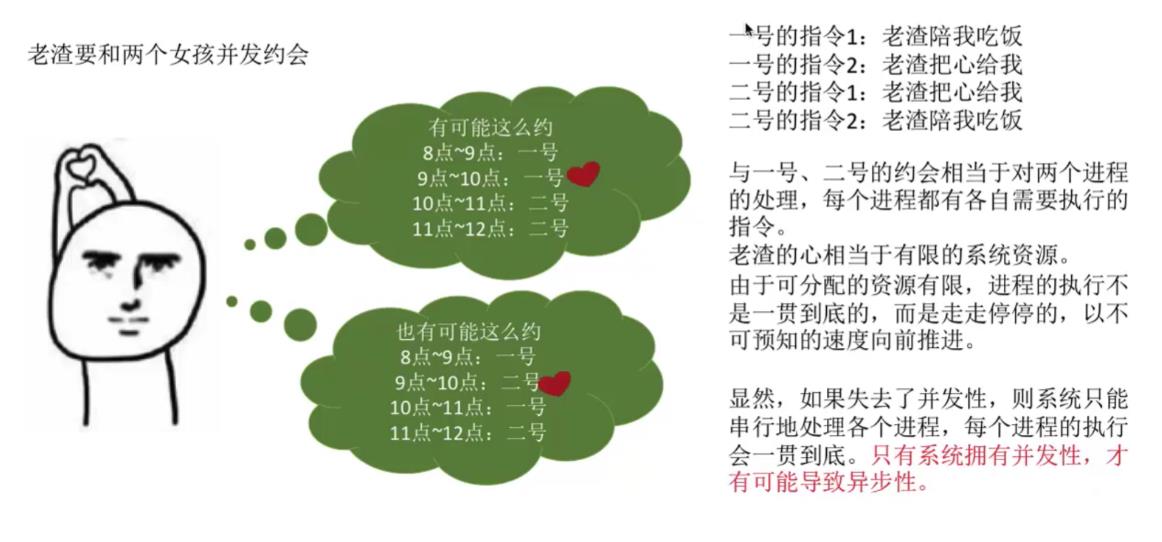
结论:显然,如果失去了并发性,则一个时间段内系统中只需运行一道程序,那么就失去了实现虚拟性的意义了。因此,没有并发性,就谈不上虚拟性。

2.4异步
异步:是指,在多道程序环境下,允许多个程序并发执行,但由于资源有限进程的执行不是一贯到底的,而是走走停停,以不可预知的速度向前推进,这就是进程的异步性。
下面一个例子帮助理解:
2.5小结
3.操作系统的发展与分类
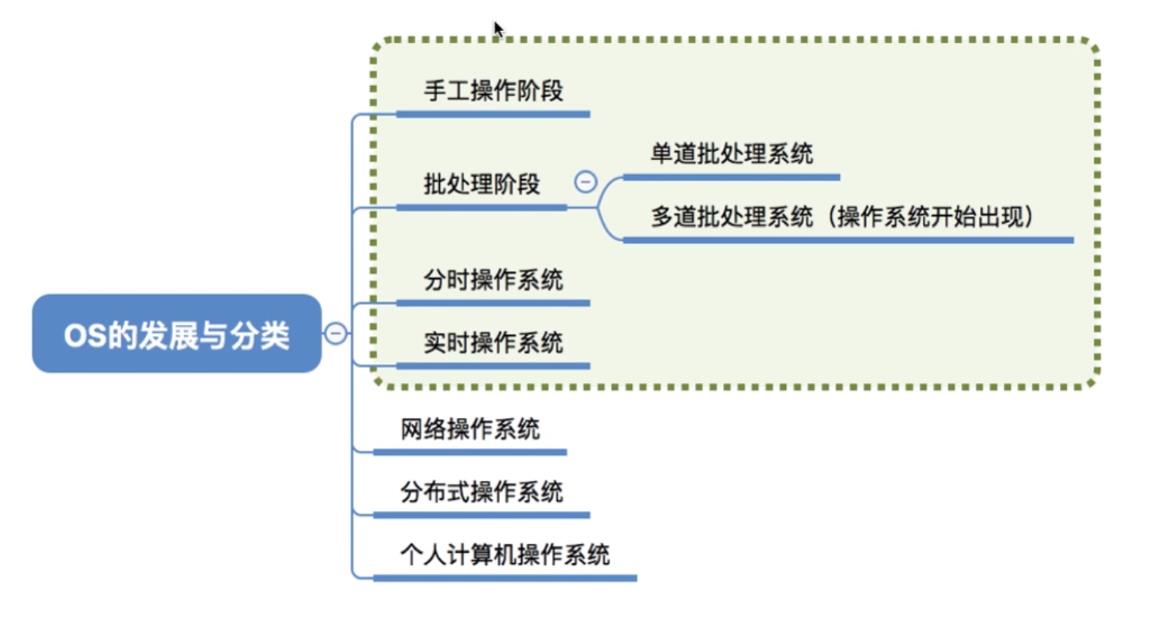
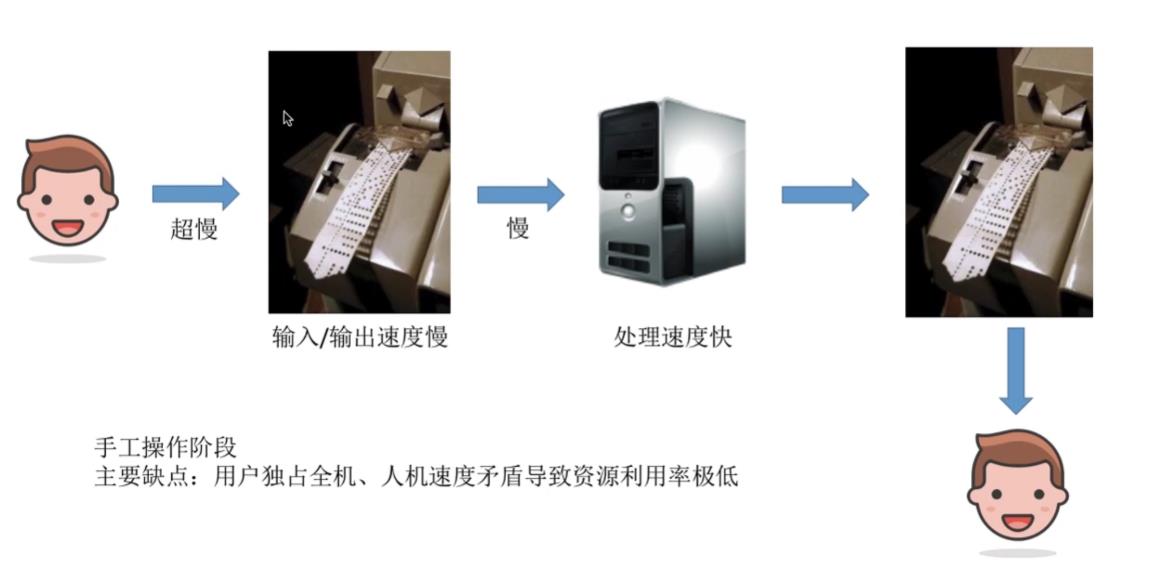
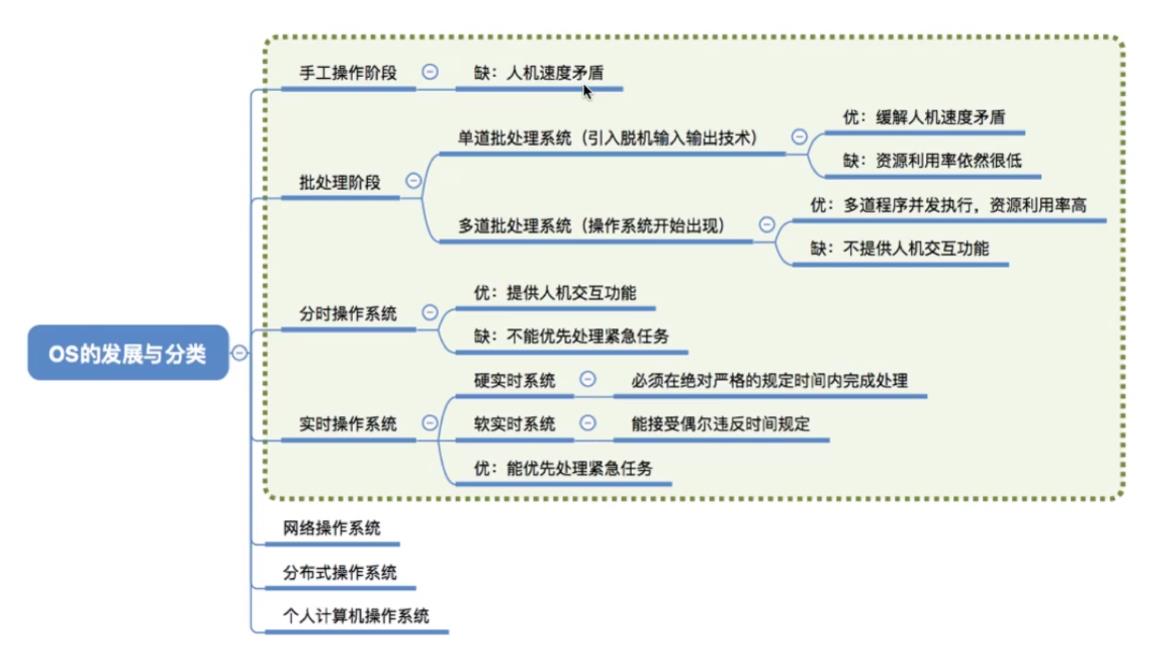
3.1手工操作阶段
- 主要缺点:用户独占全机,人机速度矛盾导致资源利用率极低。
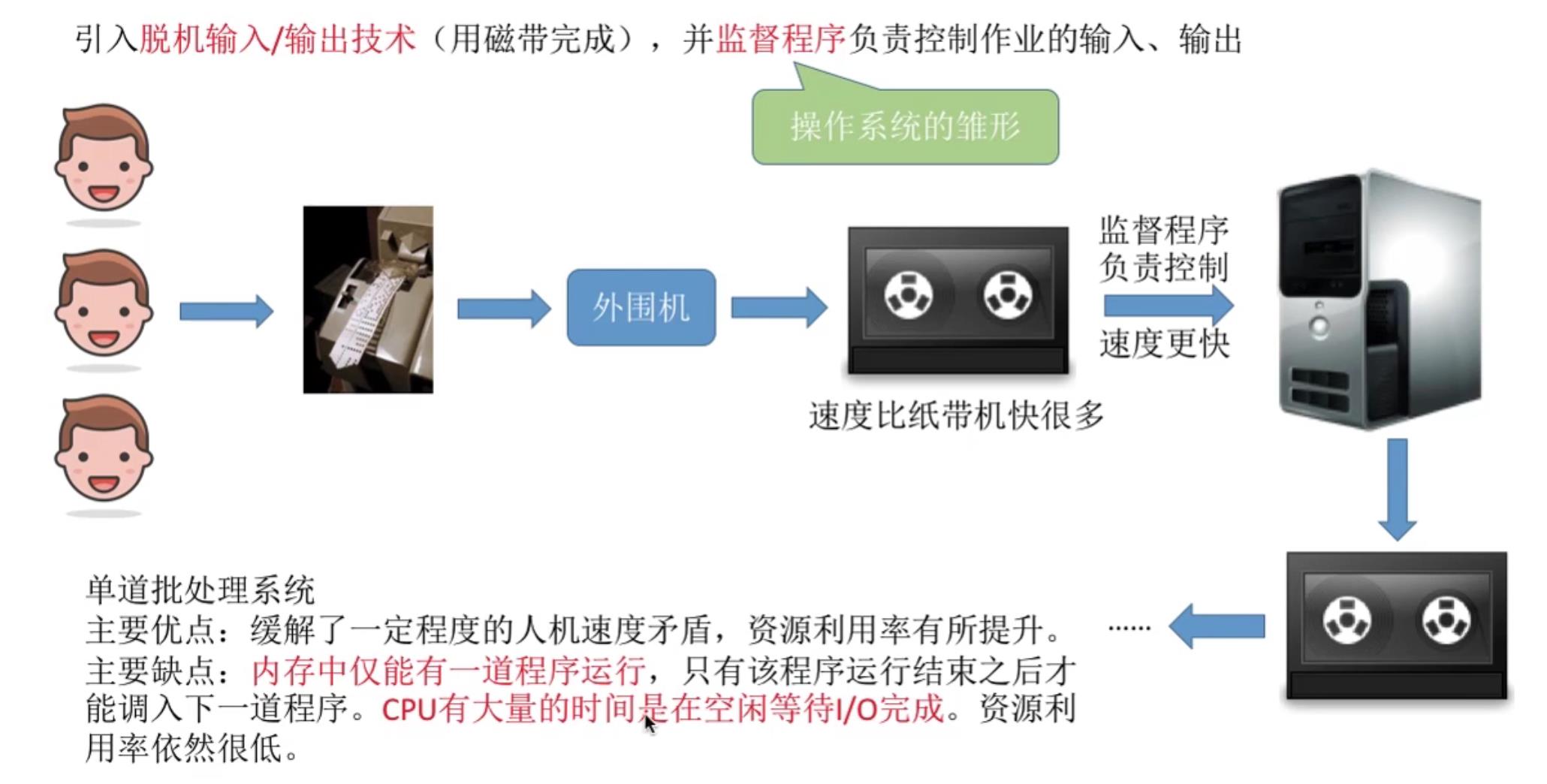
3.2批处理阶段
-
单道批处理系统
- 引入脱机输入/输出技术(用磁带完成),并监督程序负责控制作业的输入,输出。
- 主要优点:缓解了一定程度的人机速度矛盾,资源利用率有所提升。
- 主要缺点:内存中仅能有一道程序运行,只有该程序运行结束之后才能调入下一道程序。CPU有大量的时间是在空闲等待I/O完成。资源利用率依然很低。
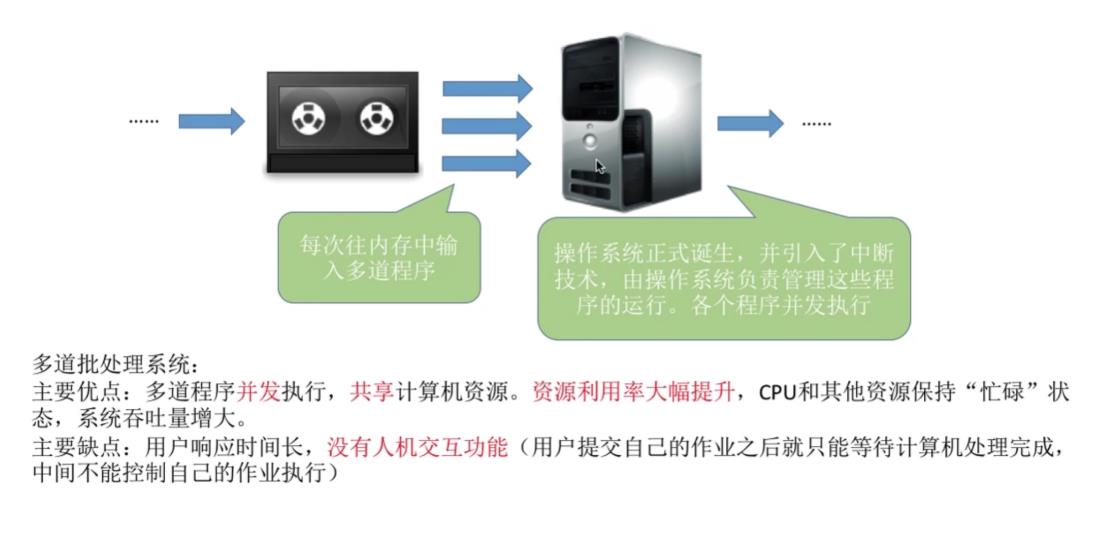
-
多道批处理系统
- 主要优点:多道程序并发执行,共享计算机资源。资源利用率大幅提升,CPU和其他资源保持“忙碌”状态,系统吞吐量增大。
- 主要缺点:用户响应时间长,没有人机交互功能(用户提交自己的作业之后就只能等待计算机处理完成,中间不能控制自己的作业执行)。
3.3分时操作系统
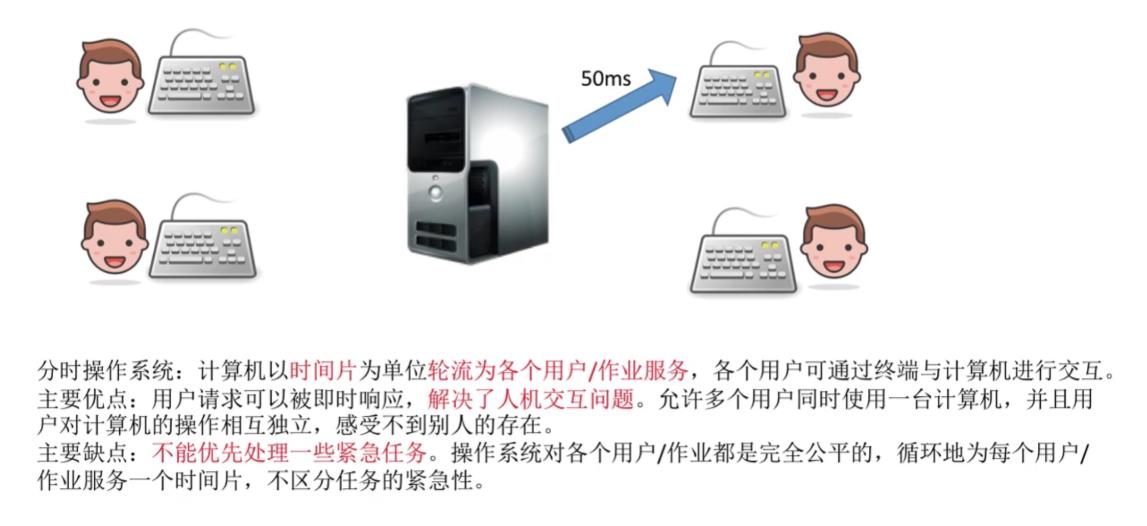
- 分时操作系统:计算机以时间片为单位轮流为各个用户/作业服务,各个用户可通过终端与计算机进行交互。
- 主要优点:用户请求可以被即时响应,解决了人机交互问题。允许多个用户同时使用一台计算机,并且用户对计算机的操作相互独立,感受不到别人的存在。
- 主要缺点:不能优先处理一些紧急任务。操作系统对各个用户/作业都是完全公平的,循环地为每个用户/作业服务一个时间片,不区分任务的紧急性。
3.4实时操作系统
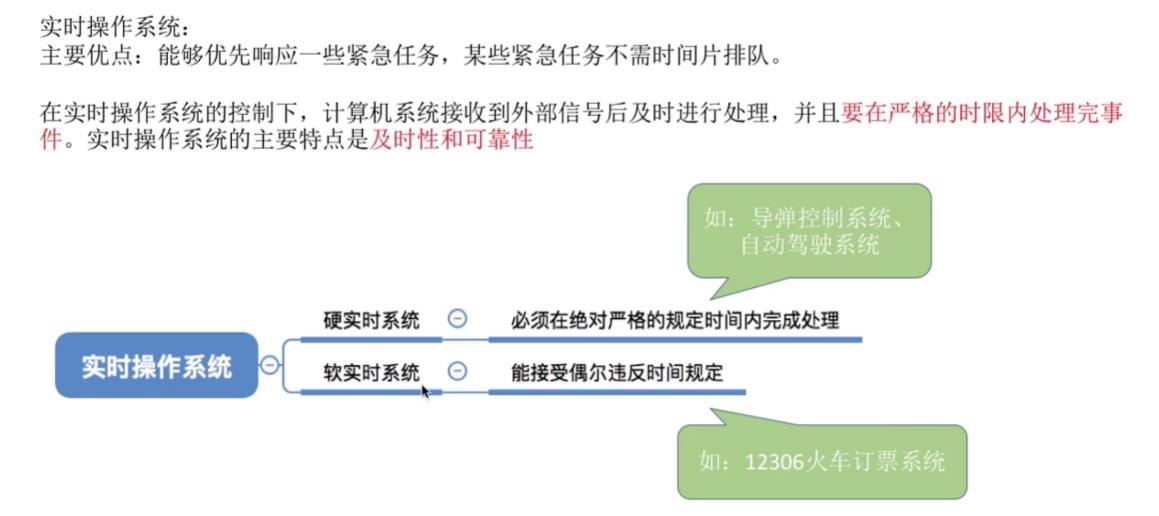
- 主要优点:能够优先响应一些紧急任务,某些紧急任务不需时间片排队。
- 在实时操作系统的控制下,计算机系统接收到外部信号后及时进行处理,并且要在严格的时限内处理完事件。实时操作系统的主要特点是及时性和可靠性。
3.5其他操作系统
- 网络操作系统:是伴随着计算机网络的发展而诞生的,能把网络中各个计算机有机地结合起来,实现数据传送等功能,实现网络中各种资源的共享(如文件共享)和各台计算机之间的通信。(如: Windows NT就是一种典型的网络操作系统,网站服务器就可以使用)
- 分布式操作系统:主要特点是分布性和并行性。系统中的各台计算机地位相同,任何工作都可以分布在这些计算机上,由它们并行、协同完成这个任务。
- 个人计算机操作系统:如 Windows XP、MacOs,方便个人使用。
3.6小结
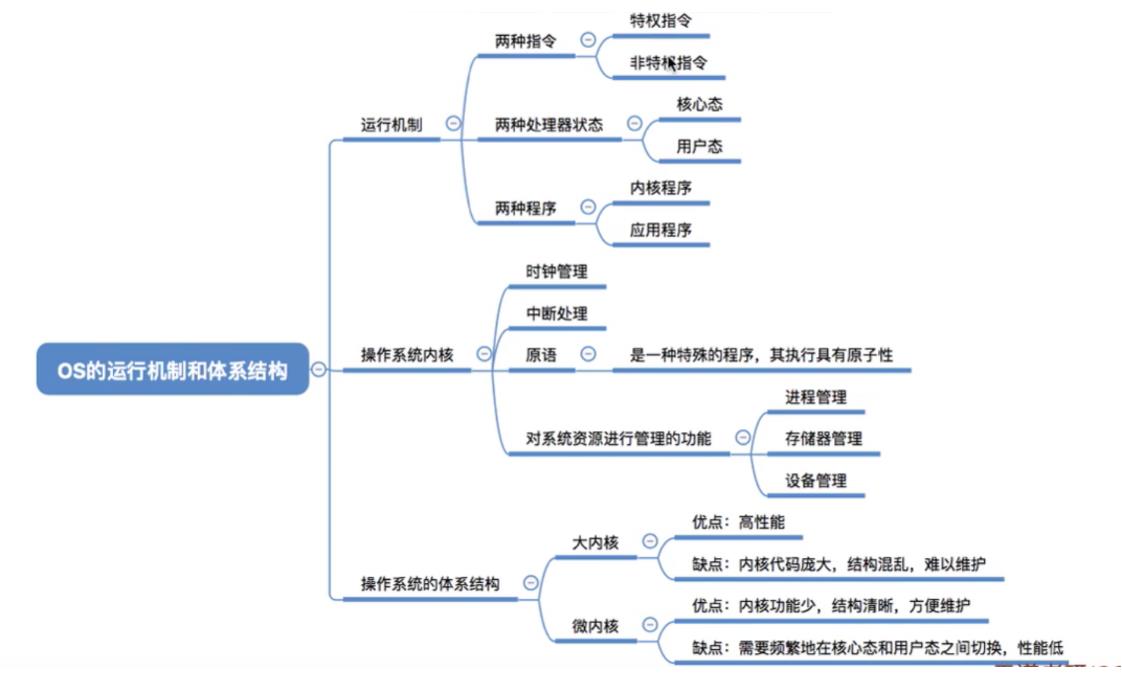
4.操作系统的运行机制与体系结构
4.1两种指令,两种处理状态,两种程序
-
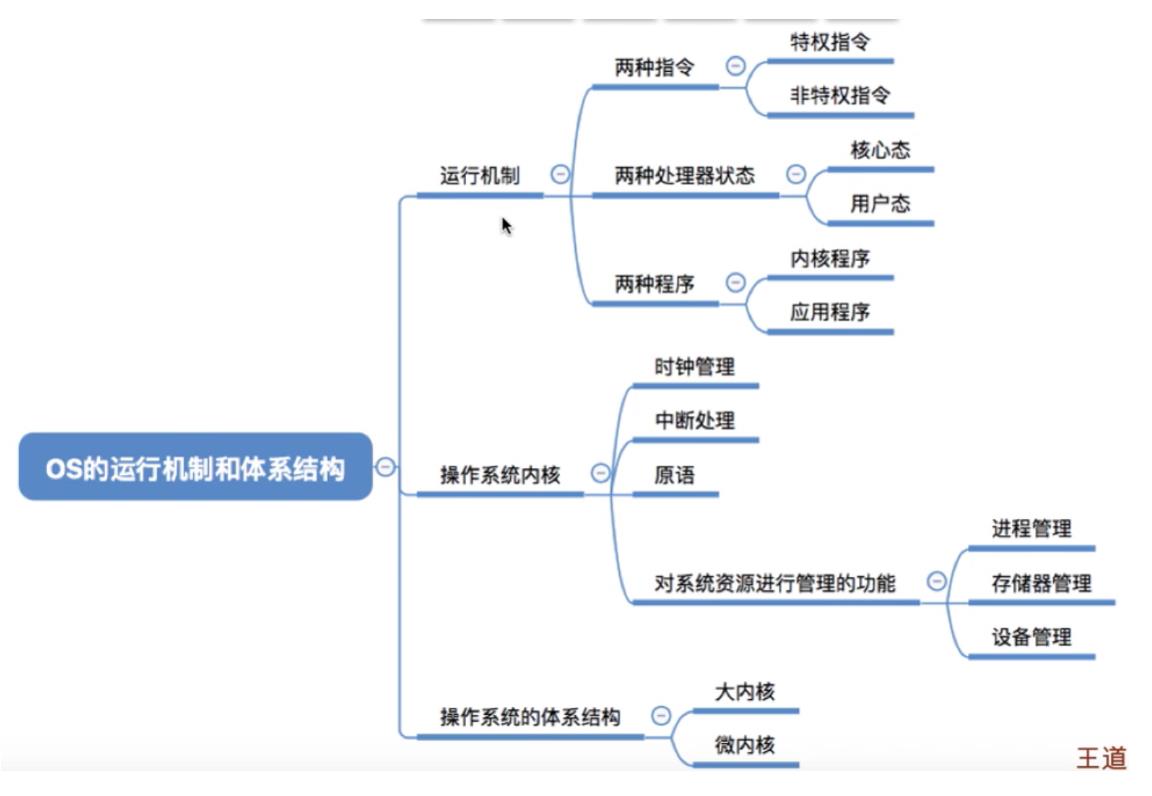
两种指令
- 特权指令:如内存清零指令(不允许用户程序使用)。
- 非特权指令:如普通的运算指令。
-
两种处理状态
用程序状态字寄存器(PSW)中的某标志位来标识当前处理器处于什么状态。
如,0为用户态,1为核心态。
- 用户态(目态):此时CPU只能执行非特权指令。
- 核心态(管态):特权指令,非特权指令都可执行。
-
两种程序
- 内核程序:操作系统的内核程序是系统的管理者,既可以执行特权指令,也可以执行非特
权指令,运行在核心态。 - 应用程序:为了保证系统能安全运行,普通应用程序只能执行非特权指令,运行在用户态。
4.2操作系统的内核
-
内核:是计算机上配置的底层软件,是操作系统的最基本,最核心的部分。实现操作系统内核功能的哪些程序就是内核程序。
-
内核功能:
- 时钟管理
- 中断处理
- 原语
- 对系统资源进行管理的功能
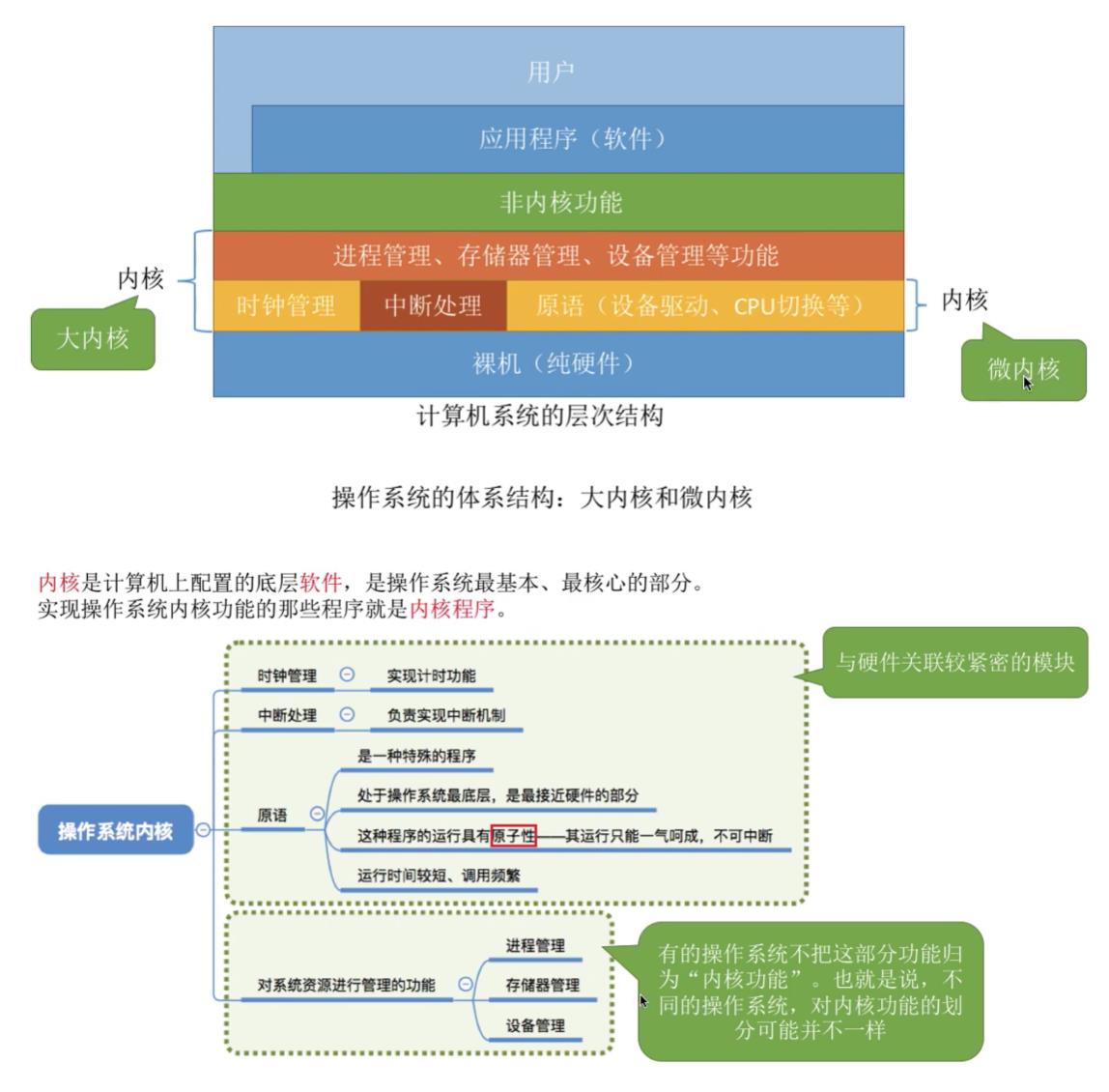
4.3操作系统的体系结构
- 大内核
- 将操作系统的主要功能模块都作为系统内核,运行在核心态。
- 优点:高性能。
- 确点:内核代码庞大,结构混乱,难以维护。
- 微内核
- 只把最基本的功能保留在内核。
- 优点:内核功能少,结构清晰,方便维护。
- 缺点:需要频繁地在核心态和用户态之间切换,性能低。

4.3小结
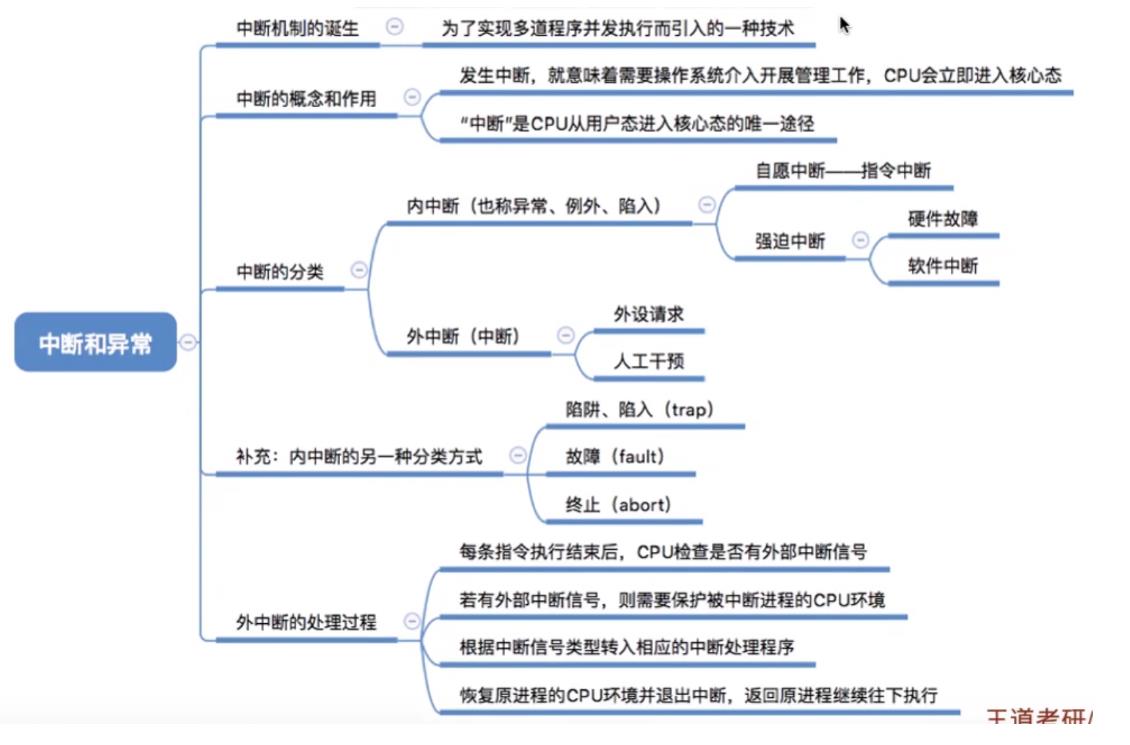
5.中断和异常
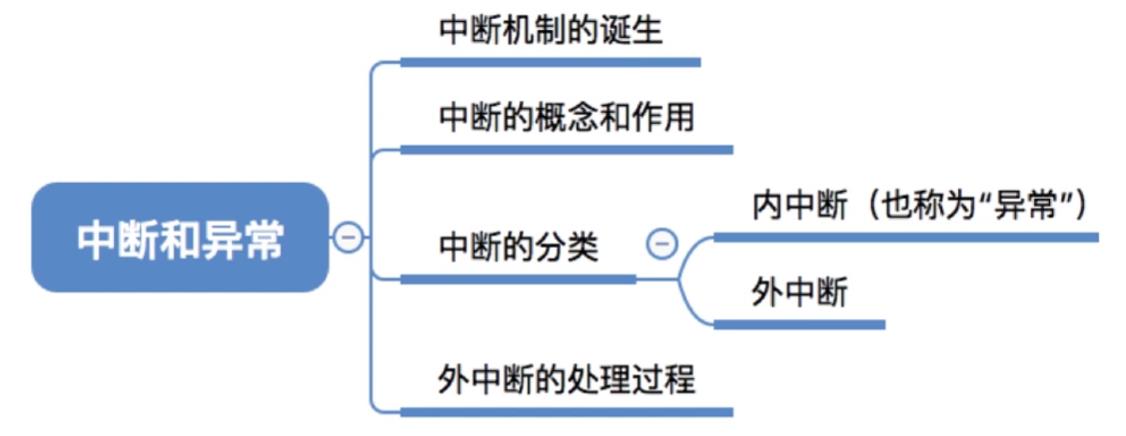
5.1中断机制的诞生

5.2中断的概念和作用

5.3中断的分类
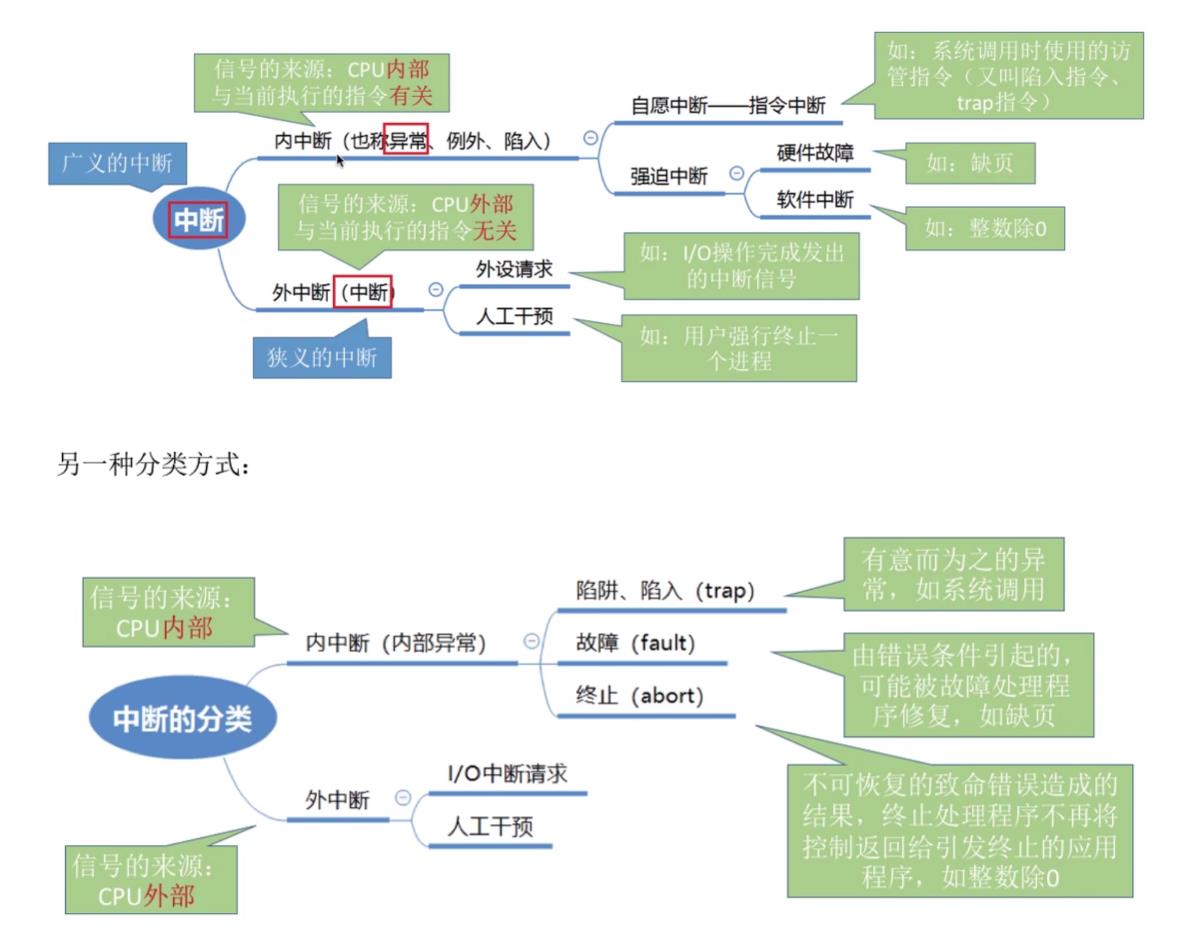
5.4外中断的处理过程
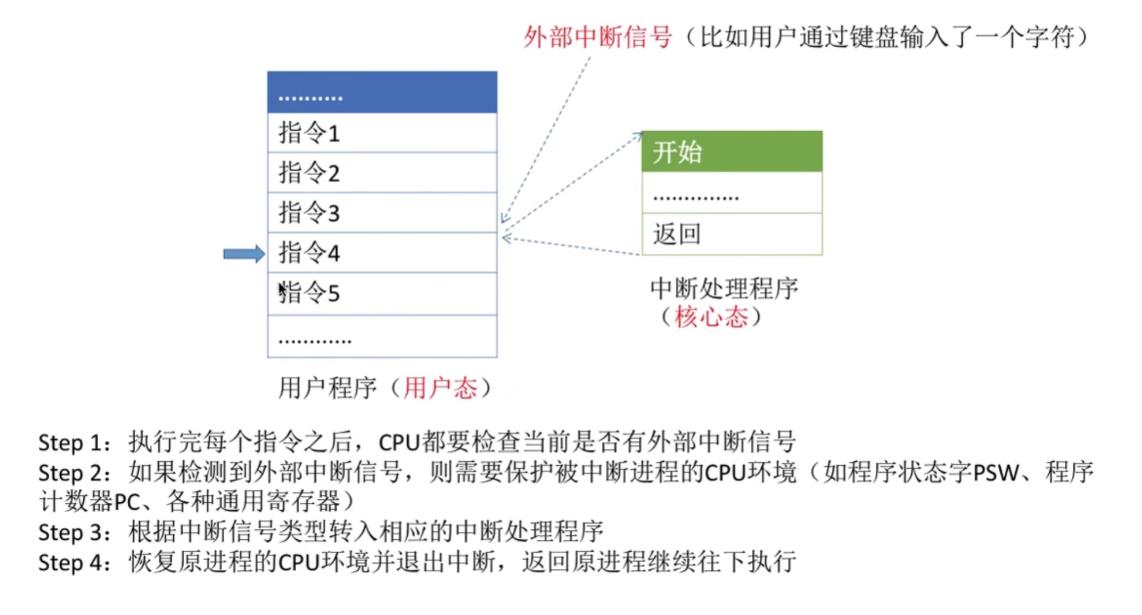
5.5小结
6. 系统调用
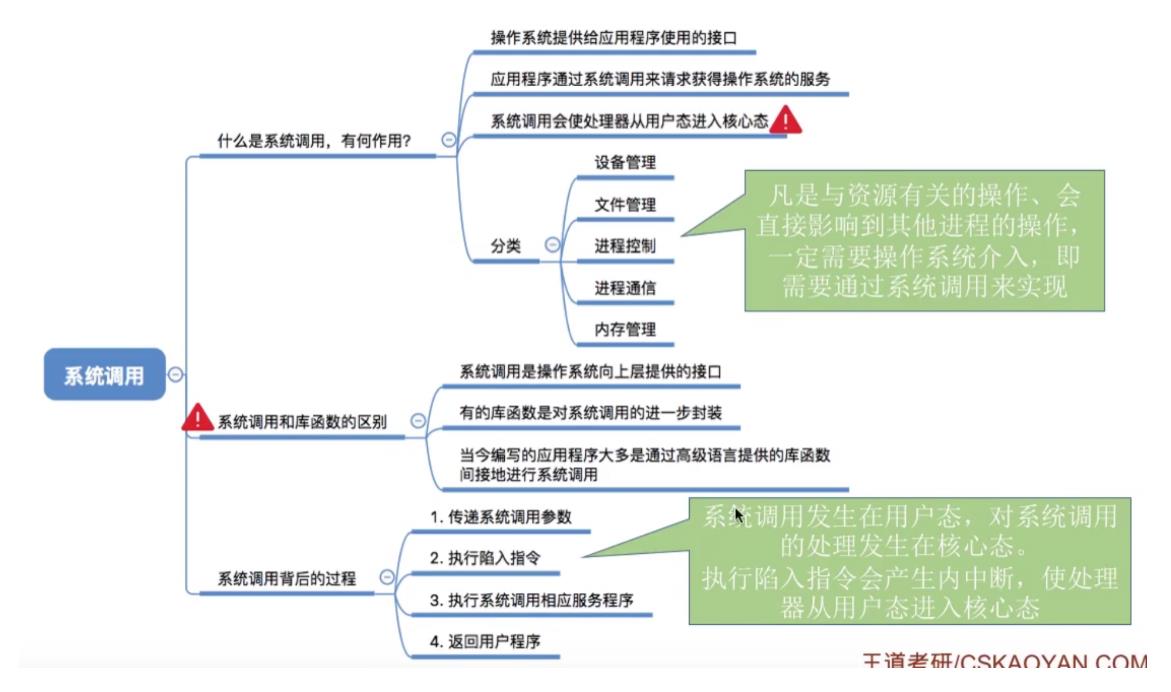
6.1什么是系统调用,有何作用?
-
系统调用:是操作系统提供给应用程序(程序员/编程人员)使用的接口,可以理解为一种可供应用程序调用的特殊函数,应用程序可以发出系统调用请求来获得操作系统的服务。
-
作用:应用程序通过系统调用请求操作系统的服务。系统中的各种共享资源都由操作系统统一掌管,因此在用户程序中,凡是与资源有关的操作〈如存储分配、I/O操作、文件管理等),都必须通过系统调用的方式向操作系统提出服务请求,由操作系统代为完成。这样可以保证系统的稳定性和安全性,防止用户进行非法操作。
-
按功能分类:
- 设备管理:完成设备的请求/释放/启动等功能。
- 文件管理:完成文件的读/写/创建/删除等功能。
- 进程控制:完成进程的创建/撤销/阻塞/唤醒等功能。
- 进程通信:完成进程之间的消息传递/信号传递等功能。
- 内存管理:完成内存的分配/回收等功能。
注意:系统调用相关处理涉及到对系统资源的管理、对进程的控制,这些功能需要执行一些特权指令才能完成,因此系统调用的相关处理需要在核心态下进行
6.2系统调用和库函数区别
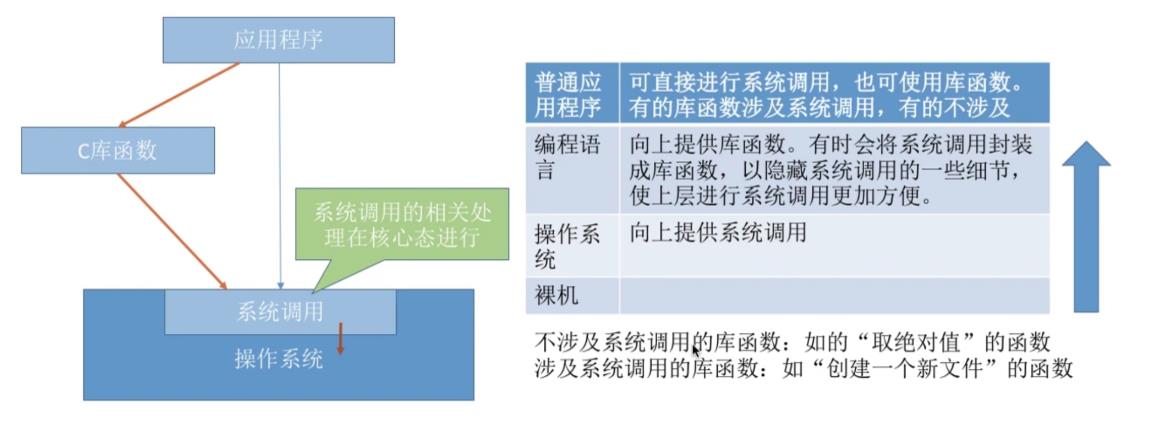
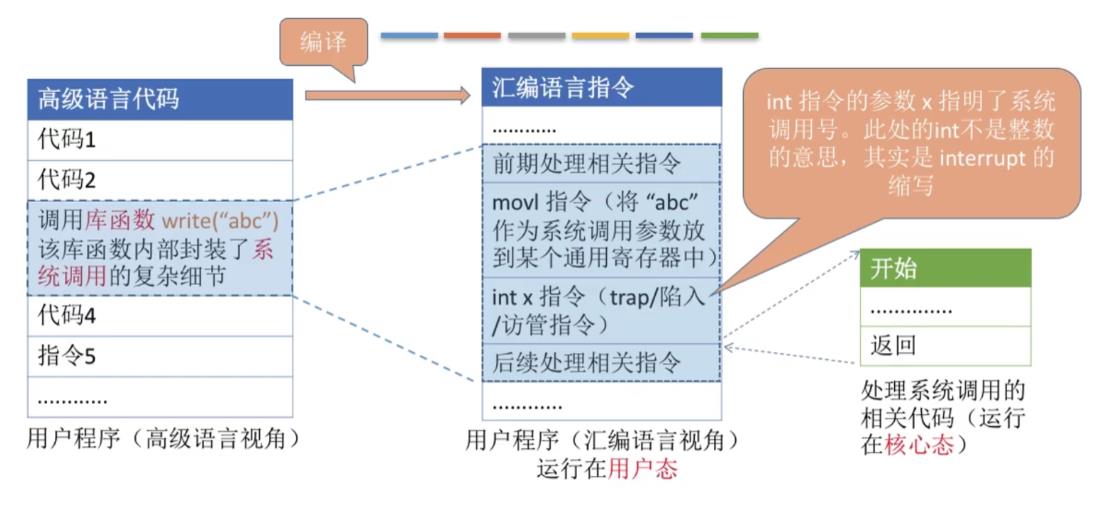
6.3系统调用背后的过程
- 系统调用过程:
- 传递系统调用参数。
- 执行陷入指令(用户态)。
- 执行系统调用相应服务程序(核心态)。
- 返回用户程序。
- 注意:
- 陷入指令是在用户态执行的,执行陷入指令之后立即引发一个内中断,从而CPU进入核心态。
- 发出系统调用请求是在用户态,而对系统调用的相应处理在核心态下进行
- 陷入指令是唯一一个只能在用户态执行,而不可在核心态执行的指令
6.4小结
以上是关于操作系统-AOSOA的主要内容,如果未能解决你的问题,请参考以下文章