如何用Serverless实现视频剪辑批量化自动化与定制化
Posted Woody-Consultant
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Serverless实现视频剪辑批量化自动化与定制化相关的知识,希望对你有一定的参考价值。
前言

开始讲之前先解决大家看到这个标题时心里的3个疑惑:
- 视频剪辑不是用Adobe的软件就可以做了吗?
- 为什么要用Serverless?
- 如何写代码做视频剪辑?
首先说说哪些视频剪辑场景是Adobe等软件无法完成的
大家平常接触到的视频剪辑通常都是使用Premiere,AE等这类专业工具来完成视频剪辑。他们能完成一些复杂的效果,比如做宣传视频,广告视频等。
但有些企业在某些业务场景下是期望能批量且自动化的完成视频剪辑。
比如以下几种场景:
- 假设学校期望能在学生上完网课之后马上呈现所有学生学习过程中的精彩视频,配上学校的logo和宣传语等,让学生一键分享自己的成果。假设有1万个学生,需要为每个学生制作独一无二的视频,所以需要批量且自动化的完成1万个不同的视频剪辑。
- 某次营销活动中,需要为不同的用户生成不同的头像视频来吸引用户参与。每个用户的头像都是独一无二的,生成的视频也是独一无二的,用户可能成千上万,因此自动化完成是必须的条件。
- 网红运营公司期望能给所有主播生成统一的营业视频。可能有100个主播,专门找一个人剪辑100个视频好像勉强能接受,但如果每周都要剪一次不同的视频呢?所以自动化,批量和可定制化的剪辑就成了主要需求。
以上的场景中有三个特点:
- 批量
- 自动化
- 可定制
对于符合以上特点的场景,是传统的视频剪辑工具或者模版化的视频处理软件无法轻松完成的。
再来说说为什么用Serverless
因为视频剪辑这样的业务有几个特点:
- 使用时段集中。
- 计算量大。
单独购买高规格的服务器利用率很低,买便宜的服务器计算能力又跟不上。
因此Serverless按量计费的特点,以及高性能的计算能力,完美匹配了这样的需求场景。
既能达到100%的利用率,又能按量使用它的高性能计算能力。
同时,Serverless拥有多变的可编程环境,可以使用熟悉的编程语言,灵活性很高。
最后说说如何写代码做视频剪辑
本文章提到的所有视频剪辑的功能,都是用FFmpeg这个工具,所以先给大家讲讲什么是FFmpeg。
FFmpeg是一个用来做视频处理的开源工具,它有非常强大的功能,它支持视频剪辑、视频转码、视频编辑、音频处理、添加文字、视频拼接、拉流推流直播等功能。
我们通过不同的FFmpeg命令就可以编程完成不同的视频剪辑功能,组合编排起来,就可以应对各种批量自动化的场景了。
视频剪辑批量化、自动化与定制化实践
常见的视频剪辑场景主要包含以下几种:
- 视频转码
- 视频裁剪
- 视频加文字
- 视频加图片
- 视频拼接
- 视频加音频
- 视频转场
- 视频特效
- 视频加速慢速播放
接下来给大家展示一些具体的FFmpeg命令例子,如果你在本地安装了FFmpeg,也可以在本地执行这些命令。关于怎么安装FFmpeg,可以去看官网的教程。
// 将MOV视频转成mp4视频
ffmpeg -i input.mov output.mp4
// 将原视频的帧率修改为24
ffmpeg -i input.mp4 -r 24 -an output.mp4
// 将mp4视频转为可用于直播的视频流
ffmpeg -i input.mp4 -codec: copy -bsf:v h264_mp4toannexb -start_number 0 -hls_time 10 -hls_list_size 0 -f hls output.m3u8
// 将视频分别变为480x360,并把码率改400
ffmpeg -i input.mp4 -vf scale=480:360,pad=480:360:240:240:black -c:v libx264 -x264-params nal-hrd=cbr:force-cfr=1 -b:v 400000 -bufsize 400000 -minrate 400000 -maxrate 400000 output.mp4
// 给视频添加文字,比如字幕、标题等。
// `fontfile`是要使用的字体的路径,`text`是你要添加的文字,
// `fontcolor`是文字的颜色,`fontsize`是文字大小,`box`是给文字添加底框。
// `box=1`表示enable,`0`表示disable,`boxcolor`是底框的颜色,black@0.5表示黑色透明度是50%,`boxborderw`是底框距文字的宽度
// `x`和`y`是文字的位置,`x`和`y`不只支持数字,还支持各种表达式,具体可以去官网查看
ffmpeg -i input.mp4 -vf "drawtext=fontfile=/path/to/font.ttf:text='你的文字':fontcolor=white:fontsize=24:box=1:boxcolor=black@0.5:boxborderw=5:x=(w-text_w)/2:y=(h-text_h)/2" -codec:a copy output.mp4
// 给视频添加图片,比如添加logo、头像、表情等。filter_complex表示复合的滤镜,overlay表示表示图片的x和y,enable表示图片出现的时间段,从0-20秒
ffmpeg -i input.mp4 -i avatar.JPG -filter_complex "[0:v][1:v] overlay=25:25:enable='between(t,0,20)'" -pix_fmt yuv420p -c:a copy output.mp4
// 视频拼接,list.txt里面按顺序放所有要拼接的视频的文件路径,如下。
// 注意,如果视频的分辨率不一致会导致拼接失败。
ffmpeg -f concat -safe 0 -i list.txt -c copy -movflags +faststart output.mp4
// list.txt的格式如下
file 'xx.mp4'
file 'yy.mp4'
// 视频加音频,stream_loop表示是否循环音频内容,-1表示无限循环,0表示不循环。shortest表示最短的MP3输入流结束时完成编码。
ffmpeg -y -i input.mp4 -stream_loop -1 -i audio.mp3 -map 0:v -map 1:a -c:v copy -shortest output.mp4
FFmpeg能做的事情非常多,这里就不一一讲解了。更多的玩法可以在FFmpeg官网上探索探索。
对于音频的编辑也是同样的道理,FFmpeg也支持单独对音频进行编辑。
如何运行FFmpeg命令
因为Python运行这些命令比较便捷,所以我们可以使用python来运行所有的FFmpeg命令。同时python在serverless云函数上运行性能也比较好,部署也方便。
通过Python来使用FFmpeg的视频剪辑代码在文章最后有开源链接。并且在官网上也有模版可以直接使用,覆盖了常见的音视频剪辑等操作。
这里就展示一个简单的调用代码示例。
child = subprocess.run('./ffmpeg -i input.mov output.mp4',
stdout=subprocess.PIPE,
stderr=subprocess.PIPE, close_fds=True, shell=True)
if child.returncode == 0:
print("success:", child)
else:
print("error:", child)
raise KeyError("处理视频失败, 错误: ", child)
在serverless部署
上面提到的常见的视频剪辑场景我已经实现并开源了,下载代码直接部署到serverless就可以使用了。
https://github.com/woodyyan/ffmpeg-composition
https://github.com/woodyyan/ffmpeg-splice
这里分为了两个函数,一个负责处理单个视频,一个负责把多个视频拼接成一个视频并配上背景音乐。
目前支持以下功能:
- 在视频中添加文字
- 视频分辨率转换
- 在视频中添加图片
- 视频拼接
- 添加背景音乐
源码里展示的只是常见的一些视频剪辑场景,大家可以根据自己的业务需要,编写自己的视频剪辑逻辑。
Serverless部署
方式一:Github Action自动部署
- Fork仓库。
- 在仓库的Settings-Secrets-Actions中添加
TENCENT_SECRET_ID和TENCENT_SECRET_KEY两个密钥。ID和KEY可以在腾讯云的访问控制里面获取。 - 添加之后,在Action中就可以发起部署了。每次修改代码推送后,也会自动触发Action部署。
- 如果需要有一些自定义的配置,请修改serverless.yml。
- 云函数最终会自动部署到
TENCENT_SECRET_ID所在的账号下。
方式二:云函数控制台手动部署
- 下载代码。
- 在根目录把所有文件和文件夹一起打包成一个ZIP文件。
- 去云函数控制台,新建一个函数。
- 选择从头开始:
- 选择python语言。
- 上传ZIP文件。
- 函数内存建议选择较大的内存。
- 开启异步执行。
- 执行超时时间根据视频大小建议设置长一点,比如30秒以上。
- 配置触发器,选择API网关触发器,关闭集成响应。
- 完成部署后,就可以通过API网关的URL开始调用了。
真实案例回顾

一个做网课的学校,需要每次在学生上完网课之后把上网课的录像制作成一段30秒的视频,作为学生的学习成果。
此案例有几个关键的信息点:
- 通常一堂课有200个学生,需要同时制作200个视频。
- 需要把1小时的上课视频剪辑成30秒。
- 由于每个学生的上课屏幕有所不同,因此录制的视频都是不同的。
- 最终的成果视频还需要加上学生的名字和头像。
- 学生结束上课的时间很集中,因此制作视频时会有短时高并发。
- 每次上完课的时候才会需要制作视频,时段比较固定且集中。
综合上述特点,用Serverless来做这样的视频剪辑带来了多个好处:
- 解决了200个并发的问题,不需要自己搭建过多的服务器。
- 解决了只在发生时段使用的问题,其他时段都没有成本产生。
- 解决了需要较强计算能力快速制作视频的问题。
下面是这个案例的参考架构图。

总结
通过编排、组合、复用上面列举的各种音视频剪辑的场景,就能制作出各种各样想要的效果。
然后把视频剪辑中用来控制各种效果的参数,变成调用服务时传入的参数,就能实现各种效果的定制化了。
最后再总结一下通过这种写代码的方式完成视频剪辑的使用场景:
- 解决通过修改个别参数来批量制作视频的场景。
- 解决通过用户触发来自动化制作视频的场景。
- 解决不同场景需要不同定制化的制作视频的场景。
同时,利用serverless来完成视频剪辑,同样也解决了以下几个问题:
- 因为通常视频剪辑不是全天运行,利用serverless按量付费的特性能优化成本。
- 因为视频剪辑通常是重计算场景,利用serverless可选的高规格配置来应对这种重计算。
- 在批量制作视频的场景中通常会存在高并发,利用serverless自动弹性伸缩的特性能轻松应对高并发。
关于Serverless使用上或者视频剪辑大家有什么问题,欢迎给我留言。
如何用Python实现股票量化交易?
全文1.8w字,先带大家认识量化交易和量化回测框架,最后带你手把手实现第一个股票策略。
目录
一、量化交易简介
量化交易(Quantitative trading)
1.1 定义
量化交易(量化投资)是指借助现代统计学和数学(机器学习)的方法,利用计算机技术来进行交易的证券投资方式。
量化交易 从庞大的历史数据中海选能带来超额收益的多种“大概率”事件以制定策略,用数量模型验证及固化这些规律和策略,然后严格执行已固化的策略来指导投资,以求 获得可以持续的、稳定且高于平均收益的超额回报。
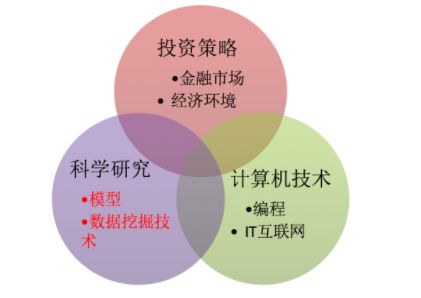
1.2 掌握技能
量化交易分类
1、分类
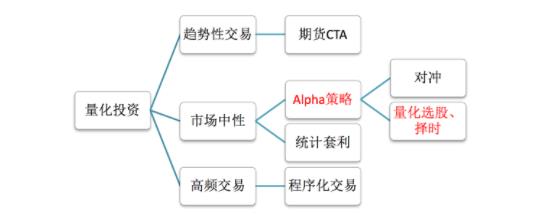
关于这三种分类,不用记忆它们的定义。我们课程主要的量化投资方法是市场中性的策略。
2、 三种分类特点以及要求
- 趋势性交易
- 适合一些主观交易的高手,用技术指标作为辅助工具在市场中如鱼得水的,但如果只用各种技术指标或指标组合作为核心算法构建模型,从未见过能长期盈利的。
- 一般也会做一些量化分析操作,使用编程如python/matlab 。
- 市场中性
- 在任何市场环境下风险更低,收益稳定性更高,资金容量更大。适合一些量化交易者,发现市场中的alpha因子赚取额外收益,例如股票与股指期货的对冲策略等。
- 会做一些量化分析操作,使用编程如python/matlab。
- 高频交易
- 在极短的时间内频繁买进卖出,完成多次大量的交易,此类交易方式对硬件系统以及市场环境的要求极高,所以只有在成熟市场中的专业机构才会得到应用
- 适合一些算法高手,使用C/C++编程语言,去进行算法交易,对软硬件条件要求比较高。
1、金融专业出生,对金融市场环境非深入了解(交易员、基金经理)
2、基本了解金融基础、投资知识,对数据挖掘、机器学习方法擅长,挖掘股票等的价值 (quanter)
3、非常擅长算法,C/C++ ,编写程序化的一些交易方法 (程序化交易员)
3、 金融产品以及衍生品的常用投资技术
- 投资策略
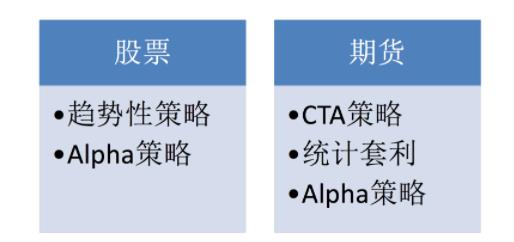
注:比特币不属于衍生品,通常使用的也是趋势策略,少部分使用高频策略
4、 量化交易的优势
- 严格的纪律性
- 完备的系统性
- 完备的系统性具体表现为“三多”。
- 首先表现在多层次,包括在大类资产配置、行业选择、精选个股三个层次上我们都有模型;
- 其次是多角度,量化交易的核心投资思想包括宏观周期、市场结构、估值、成长、盈利质量、分析师盈利预测、市场情绪等多个角度;
- 再者就是多数据,就是海量数据的处理。人脑处理信息的能力是有限的,当一个资本市场只有100只股票,这对定性投资基金经理是有优势的,他可以深刻分析这100家公司。但在一个很大的资本市场,比如有成千上万只股票的时候,强大的定量化交易的信息处理能力能反映它的优势,能捕捉更多的投资机会,拓展更大的投资机会。
- 完备的系统性具体表现为“三多”。
- 靠数学模型取胜
- 股票实际操作过程中,运用概率分析,提高买卖成功的概率
量化交易历史
1、量化交易全球的发展历史
- 量化投资的产生(60年代)
- 1969年,爱德华·索普利用他发明的“科学股票市场系统”(实际上是一种股票权证定价模型),成立了第一个量化投资基金。索普也被称之为量化投资的鼻祖
- 量化投资的兴起(70~80年代)
- 1988年,詹姆斯·西蒙斯成立了大奖章基金,从事高频交易和多策略交易。基金成立20多年来收益率达到了年化70%左右,除去报酬后达到40%以上。西蒙斯也因此被称为"量化对冲之王"。
- 量化交易的繁荣(90年代)
- 1991年,彼得·穆勒发明了alpha系统策略等,开始用计算机+金融数据来设计模型,构建组合
2、 国内量化交易的发展历史
我们通过一张图来对比国内国外的发展历史
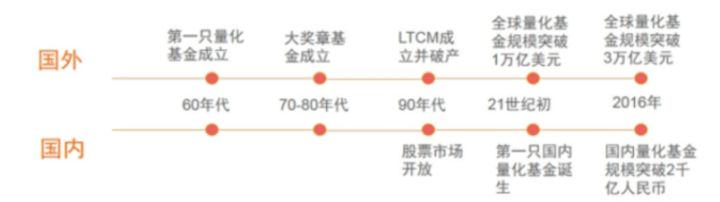
2012年到2016年量化对冲策略管理的资金规模增长了20倍,管理期货策略更是增长了30倍,增长的速度是所有策略中最快的。相比美国量化基金发展历程,中国现在基本处于美国90年代至21世纪之间的阶段。
- 量化投资元年
- 2010年,沪深300股指期货上市,此时的量化基金终于具备了可行的对冲工具,各种量化投资策略如alpha策略、股指期货套利策略才真正有了大展拳脚的空间,可以说2010年是中国量化投资元年。
- 量化投资高速发展、多元化发展
- 2013-2015年股指新政之前可以说是国内量化基金有史以来最风光的一段时期。国内量化投资机构成批涌现,国内量化投资高速发展。
量化交易项目做什么?
1、 量化交易研究流程
量化回测框架提供完整的数据,以及回测机制进行策略评估研究,并能够实时进行模拟交易。为实盘交易提供选择。我们的研究一般在回测平台当中做
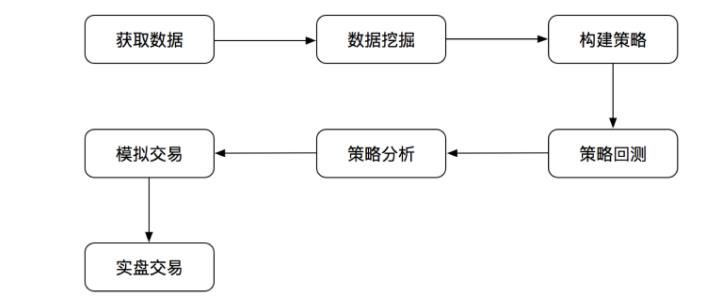
1.1 分析结果
我们最终想要的结果就是在回测当中表现的较好的分析方法和策略。比如:
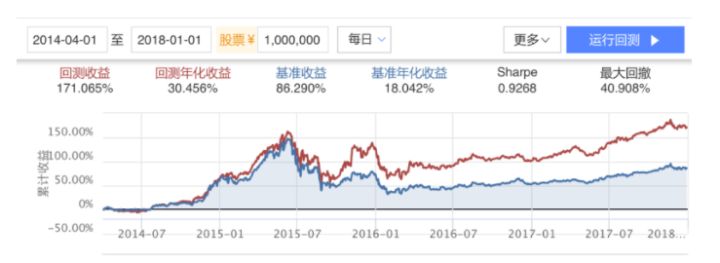
- 演示结果
1.2 什么是策略
量化策略是指使用计算机作为工具,通过一套固定的逻辑来分析、判断和决策。 量化策略既可以自动执行,也可以人工执行。其实策略也可以理解为,分析数据之后,决策买什么以及交易时间。
1.3 流程包含的内容
- 获取数据:
- 公司财务、新闻数据
- 基本行情数据
- 数据分析挖掘:
- 传统分析方法、机器学习,数据挖掘方法
- 数据处理,标准化,去极值,中性化分组回测,行业分布
- 构建策略:
- 获取历史行情,历史持仓信息,调仓记录等
- 止盈止损单,限价单,市价单
- 回测:
- 股票涨跌停、停复牌处理
- 市场冲击,交易滑点,手续费
- 策略分析:
- 订单分析,成交分析,持仓分析
- 模拟交易:
- 接入实时行情,实时获取成交回报
- 实时监控,实时归因分析
- 实盘交易:
- 接入真实券商账户
2、 量化开发和研究岗位要求
- 基于交易市场数据,研究、开发交易策略,进行基础建模
- 负责对交易策略进行回测、跟踪、分析、优化
- 定期对交易策略的运行结果进行总结,给出分析报告,评估市场适用度
- 负责数据挖掘、处理,数据统计分析,从数据中发现规律,为量化分析提供支持,开发量化模型策略
- 与基金经理合作跟踪优化股票市场量化策略在实盘的表现
二、量化回测框架介绍
回测框架介绍
1、 基础回测框架

Zipline本身只支持美国的证券,无法更好的使用数据,本地运行速度慢
2、云端的框架

- 提供部分满足需求的数据(但是平台数据质量不行,指标不完整)
- 策略运行在远端服务器
这些线上平台提供了本地专业版,但是需要收费
3、不去实现一个回测框架的原因
- 1、没有完整的股票行情和基本面数据
- 2、回测平台是载体,重点在于快速验证策略
- 3、证券投资机构各自使用回测框架不同,没有通用的框架
4、RiceQuant回测平台介绍
网址: https://www.ricequant.com/
- 注册账号
策略创建运行流程
1、体验创建策略、运行策略流程
1.1 创建策略

1.2 策略界面
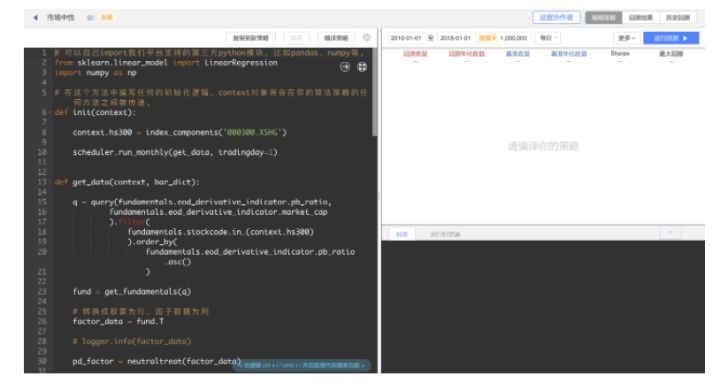
2、 策略界面功能、运行介绍
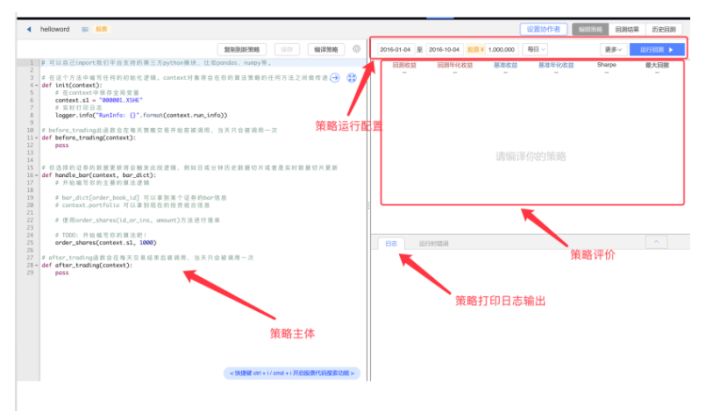
2.1 一个完整的策略需要做的事情
- 选择策略的运行信息:
- 选择运行区间和初始资金
- 选择回测频率
- 选择股票池
- 编写策略的逻辑
- 获取股票行情、基本面数据
- 选择哪些股票、以及交易时间
- 分析结果
- 策略指标分析
2.2 策略初始设置介绍
- 基础设置:指定回测的起止日期、初始资金以及回测频率
- 起止日期:策略运行的时间区间
- 初始资金:用于投资的总资金
- 回测的频率:有两种选择,日回测/分钟回测。做股票量化选择日回测即可
- 高级设置:
关于高级的设置其他部分,在介绍交易函数时介绍
2.3 策略主体运行流程分析
- 在init方法中实现策略初始化逻辑
- 策略的股票池:在那些股票中进行交易判断(例如:HS300)
- 可以选择在before_trading进行一些每日开盘之前的操作,比如获取历史行情做一些数据预处理,获取当前账户资金等。
- 在handle_bar方法中实现策略具体逻辑,包括交易信号的产生、订单的创建。handle_bar内的逻辑会在每次bar数据更新的时候被触发。
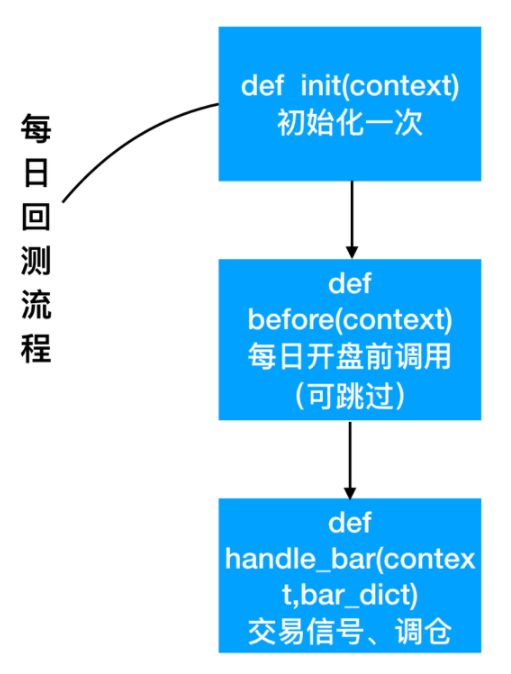
调用的顺序为:
- 1、init
- 2、before_trading
- 3、handle_bar
2.4 策略结果分析
回测完成后,在'回测结果'页面会展示回测的仓位、盈亏、交易、风险等信息
数据获取接口
1、 数据接口种类
- 获取指定行业、板块股票列表
- history_bars - 指定股票合约历史数据
- get_fundamentals - 查询财务数据
2、 获取行业、板块以及概念股票列表
2.1 关于股票代码以及代码补齐
RiceQuant上的股票代码标记
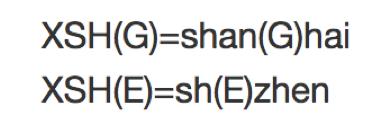
股票自动搜索及补全
- Windows 用户 : 输入ctrl + i
- Mac 用户 :输入command + i
- Linux 用户 :输入ctrl + i
当您输入了这个组合键之后,Ricequant在线IDE就会进入股票代码搜索和自动完成模式,接着您可以输入任何一种进行搜索和自动补全:
- 股票数字代码 - 自动补全为股票数字代码,比如"000024.XSHE":
- 股票中文全称 - 自动补全为股票中文全称,比如"招商地产"
- 股票拼音缩写 - 这里比较特殊,自动补全为股票中文全称,因为股票拼音缩写并不是独一无二的,比如ZSDC补全为"招商地产"
2.2 获取行业
industry - 行业股票列表
industry(code)获得属于某一行业的所有股票列表。
参数
| 参数 | 类型 | 注释 |
|---|---|---|
| code | str OR industry_code item | 行业名称或行业代码。例如,农业可填写industry_code.A01 或 'A01' |
返回
获得属于某一行业的所有股票的order_book_id list。
范例
def init(context):
stock_list = industry('A01')
logger.info("农业股票列表:" + str(stock_list))2.3 获取板块
sector - 板块股票列表
sector(code)获得属于某一板块的所有股票列表。
参数
| 参数 | 类型 | 注释 |
|---|---|---|
| code | str OR sector_code items | 板块名称或板块代码。例如,能源板块可填写'Energy'、'能源'或sector_code.Energy |
返回
属于该板块的股票order_book_id或order_book_id list.
范例
def init(context):
ids1 = sector("consumer discretionary")
ids2 = sector("非必需消费品")
ids3 = sector("ConsumerDiscretionary")
assert ids1 == ids2 and ids1 == ids3
logger.info(ids1)支持的行业获取如下,想要了解全球行业划分标准参考全球行业标准分类:
| 板块代码 | 中文板块名称 | 英文板块名称 |
|---|---|---|
| Energy | 能源 | energy |
| Materials | 原材料 | materials |
| ConsumerDiscretionary | 非必需消费品 | consumer discretionary |
| ConsumerStaples | 必需消费品 | consumer staples |
| HealthCare | 医疗保健 | health care |
| Financials | 金融 | financials |
| InformationTechnology | 信息技术 | information technology |
| TelecommunicationServices | 电信服务 | telecommunication services |
| Utilities | 公共服务 | utilities |
| Industrials | 工业 | industrials |
2.4 获取概念
参考:https://www.ricequant.com/api/python/chn#data-methods-concept
2.5 获取指数成分股
index_components - 指数成分股
index_components(order_book_id, date=None)获取某一指数的股票构成列表,也支持指数的历史构成查询。
| 参数 | 类型 | 说明 |
|---|---|---|
| order_book_id | str | 指数代码,可传入order_book_id |
| date | str, date, datetime, pandas Timestamp | 查询日期,默认为策略当前日期。如指定,则应保证该日期不晚于策略当前日期 |
返回
构成该指数股票的order_book_id list
常见的指数获取代码为
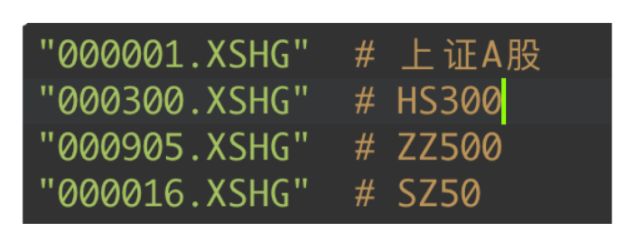
2.6 自定义股票池,提供给handle_bar使用
我们可以通过context的参数,相当于提供一个全局变量来获取
def init(context):
# 在context中保存全局变量
context.s1 = "000001.XSHE"
# context.s2 = "601390.XSHG"
# 获取行业
# context.stock_list = industry("C39")
# 获取指数成分股
context.hs300 = index_components("000300.XSHG")
def before_trading(context):
logger.info(context.hs300)
logger.info("before_trading")3、获取股票合约数据
3.1 history_bars - 某一合约历史数据
history_bars(order_book_id, bar_count, frequency, fields=None, skip_suspended=True, include_now=False)获取指定合约的历史行情,同时支持日以及分钟历史数据。不能在init中调用。
参数
| 参数 | 类型 | 注释 |
|---|---|---|
| order_book_id | str | 合约代码,必填项 |
| bar_count | int | 获取的历史数据数量,必填项 |
| frequency | str | 获取数据什么样的频率进行。'1d'或'1m'分别表示每日和每分钟,必填项。您可以指定不同的分钟频率,例如'5m'代表5分钟线 |
| fields | strOR str list | 返回数据字段。必填项。见下方列表 |
| skip_suspended | bool | 是否跳过停牌,默认True,跳过停牌 |
| include_now | bool | 是否包括不完整的bar数据。默认为False,不包括。举例来说,在09:39的时候获取上一个5分钟线,默认将获取到09:31~09:35合成的5分钟线。如果设置为True,则将获取到09:36~09:39之间合成的"不完整"5分钟线 |
返回
ndarray ,方便直接与talib等计算库对接,效率较history返回的DataFrame更高。
获取的字段内容如下
| fields | 字段名 |
|---|---|
| datetime | 时间戳 |
| open | 开盘价 |
| high | 最高价 |
| low | 最低价 |
| close | 收盘价 |
| volume | 成交量 |
| total_turnover | 成交额 |
| datetime | int类型时间戳 |
| open_interest | 持仓量(期货专用) |
| basis_spread | 期现差(股指期货专用) |
| settlement | 结算价(期货日线专用) |
| prev_settlement | 结算价(期货日线专用) |
3.2 代码以及注意的问题
- 因为撮合逻辑是当前bar收盘或者下一个bar开盘,所以history_bars()可以获取到包含当前bar及之前所有的bar数据
- 获取当天的数据
- 获取前十天的数据
- 获取每天的每分钟分钟的数据?获取每分钟之前的几分钟数据?
# 如果想在今天运行,获取从几天开始前几天一些数据
# 获取前5天的收盘价,开盘价
# 股票代号,间隔,频率,交易指标
data = history_bars(context.s1, 5, '1d', 'close')
# 获取多个指标
data = history_bars(context.s1, 5, '1d', ['close', 'open'])
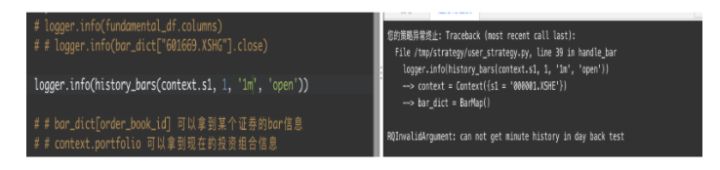
# 如果回测是每日的,不支持获取分钟数据
data = history_bars(context.s1, 5, '1m', ['close', 'open'])问题:这里的频率跟回测的频率区别?
3.3 其它-通过bar_dict获取
获取合约当前价格的bar_dict,
Bar对象
| 属性 | 类型 | 注释 |
|---|---|---|
| order_book_id | str | 合约代码 |
| symbol | str | 合约简称 |
| datetime | datetime.datetime | 时间戳 |
| open | float | 开盘价 |
| close | float | 收盘价 |
| high | float | 最高价 |
| low | float | 最低价 |
| volume | float | 成交量 |
| total_turnover | float | 成交额 |
| prev_close | float | 昨日收盘价 |
| limit_up | float | 涨停价 |
| limit_down | float | 跌停价 |
| isnan | bool | 当前bar数据是否有行情。例如,获取已经到期的合约数据,isnan此时为True |
| suspended | bool | 是否全天停牌 |
| prev_settlement | float | 昨结算(期货日线数据专用) |
| settlement | float | 结算(期货日线数据专用) |
注意,在股票策略中bar对象可以拿到所有股票合约的bar信息
# 只能获取当前的交易信息
logger.info(bar_dict[context.s1].close)注:只能获取当前运行日期的,不能获取之前日期
4、获取财务数据
4.1 get_fundamentals - 查询财务数据
get_fundamentals(query, entry_date=None, interval='1d', report_quarter=False)获取历史财务数据表格。目前支持中国市场超过400个指标,具体请参考 财务数据文档 。目前仅支持中国市场。需要注意,一次查询过多股票的财务数据会导致系统运行缓慢。(entry_date在回测当中不去要提供)
注意这里的数据指标类别虽然有400多种,但是RQ平台的这些指标数据质量不高,很多指标没有经过运算处理成需要的指标,跟我们在讲金融数据处理的时候列出来的那些财务指标差别比较大。
参数
| 参数 | 类型 | 说明 |
|---|---|---|
| query | SQLAlchemyQueryObject | SQLAlchmey的Query对象。其中可在'query'内填写需要查询的指标,'filter'内填写数据过滤条件。具体可参考 sqlalchemy's query documentation 学习使用更多的方便的查询语句。从数据科学家的观点来看,sqlalchemy的使用比sql更加简单和强大 |
| entry_date | str, datetime.date, datetime.datetime, pandasTimestamp | 查询财务数据的基准日期,应早于策略当前日期。默认为策略当前日期前一天。 |
| interval | str | 查询财务数据的间隔,默认为'1d'。例如,填写'5y',则代表从entry_date开始(包括entry_date)回溯5年,返回数据时间以年为间隔。'd' - 天,'m' - 月, 'q' - 季,'y' - 年 |
| report_quarter | bool | 是否显示报告期,默认为False,不显示。'Q1' - 一季报,'Q2' - 半年报,'Q3' - 三季报,'Q4' - 年报 |
返回
pandas DataPanel 如果查询结果为空,返回空pandas DataFrame 如果给定间隔为1d, 1m, 1q, 1y,返回pandas DataFrame
4.2 如何获取指标-query查询

通过fundamentals获取以上的属性
q = query(fundamentals.eod_derivative_indicator.pe_ratio)4.3 过滤指标条件
- query().filter:过滤大小
- query().order_by:排序
- query().limit():限制数量
- fundamentals.stockcode.in_():在指定的股票池当中过滤
# 增加条件过滤掉不符合的股票代码
# 默认直接获取A股是所有的股票这个指标数据
# order_by默认是升序
# limit:选择固定数量的股票,获取20个股票交易
q = query(fundamentals.eod_derivative_indicator.pe_ratio,
fundamentals.eod_derivative_indicator.pcf_ratio).filter(
fundamentals.eod_derivative_indicator.pe_ratio > 20,
fundamentals.eod_derivative_indicator.pcf_ratio > 15,
).order_by(
fundamentals.eod_derivative_indicator.pe_ratio
).limit(20)
# 想要从沪深300指数的一些股票去进行筛选
# 通过fundamentals.stockcode去限定股票池
q = query(fundamentals.eod_derivative_indicator.pe_ratio,
fundamentals.eod_derivative_indicator.pcf_ratio).filter(
fundamentals.eod_derivative_indicator.pe_ratio > 20,
).order_by(
fundamentals.eod_derivative_indicator.pe_ratio
).filter(
fundamentals.stockcode.in_(context.hs300)
).limit(20)
# 获取财务数据,默认获取的是dataframe,entry_date在回测当中不去要提供
fund = get_fundamentals(q)
# 注释:每个表都有一个stockcode在用来方便通过股票代码来过滤掉查询的数据问题:一般选择一些满足财务数据的股票时间并不是每天去获取,而是间隔一周、一个月去获取一次?怎么取获取呢?
4、scheduler定时器定时数据获取
- scheduler.run_daily - 每天运行
- scheduler.run_weekly - 每周运行
- scheduler.run_monthly - 每月运行
4.1 API介绍
4.1.1 scheduler.run_daily - 每天运行
scheduler.run_daily(function)每日运行一次指定的函数,只能在init内使用。
注意,schedule一定在其对应时间点的handle_bar之前执行,如果定时运行函数运行时间较长,则中间的handle_bar事件将会被略过。
参数
| 参数 | 类型 | 注释 |
|---|---|---|
| function | function | 使传入的function每日运行。注意,function函数一定要包含(并且只能包含)context, bar_dict两个输入参数 |
返回
无
4.1.2 scheduler.run_monthly - 每月运行
scheduler.run_monthly(function,tradingday=t)每月运行一次指定的函数,只能在init内使用。
注意:
tradingday的负数表示倒数。tradingday表示交易日,如某月只有三个交易日,则此月的tradingday=3与tradingday=-1表示同一。
参数
| 参数 | 类型 | 注释 |
|---|---|---|
| function | function | 使传入的function每日交易开始前运行。注意,function函数一定要包含(并且只能包含)context, bar_dict两个输入参数 |
| tradingday | int | 范围为[-23,1], [1,23] ,例如,1代表每月第一个交易日,-1代表每月倒数第一个交易日,用户必须指定 |
返回
无
4.2 添加定时器之后的策略运行顺序
比如我们添加了这样一段代码:
def init(context):
# 定义一个每天运行一个定时器
scheduler.run_daily(get_data)
# 每个一个月去获取财务数据,每隔一周去获取财务数据
scheduler.run_monthly(get_data, tradingday=1)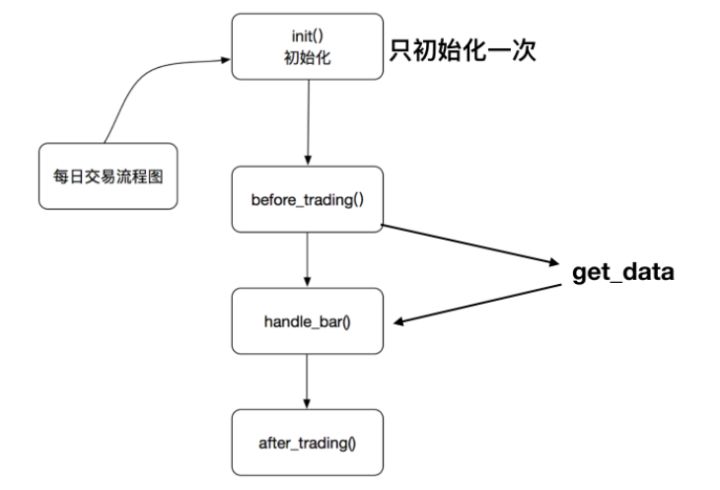
4.3 代码
def get_data(context, bar_dict):
# logger.info("-------")
# 进行每月的第一天去调整要买卖的股票
q = query(fundamentals.eod_derivative_indicator.pe_ratio,
fundamentals.eod_derivative_indicator.pcf_ratio).filter(
fundamentals.eod_derivative_indicator.pe_ratio > 20,
).order_by(
fundamentals.eod_derivative_indicator.pe_ratio
).filter(
fundamentals.stockcode.in_(context.hs300)
).limit(20)
# 获取财务数据
data = get_fundamentals(q)
logger.info("这个月更新的股票池")
logger.info(data.T)回测交易接口
1、用于股票的交易函数
- order_shares - 指定股数交易(股票专用)
- order_lots - 指定手数交易(股票专用)
- order_value - 指定价值交易(股票专用)
- order_percent - 一定比例下单(股票专用)
- order_target_value - 目标价值下单(股票专用)
更多详细内容参考:https://www.ricequant.com/api/python/chn#methods-implement-after-trading
1.1 交易函数API
1.1.1 order_shares - 指定股数交易(股票专用)
order_shares(id_or_ins, amount, style=MarketOrder())落指定股数的买/卖单,最常见的落单方式之一。如有需要落单类型当做一个参量传入,如果忽略掉落单类型,那么默认是市价单(market order)。
参数
| 参数 | 类型 | 注释 |
|---|---|---|
| id_or_ins | str或instrument对象 | order_book_id或symbol或instrument对象,用户必须指定 |
| amount | float-required | 需要落单的股数。正数代表买入,负数代表卖出。将会根据一手xx股来向下调整到一手的倍数,比如中国A股就是调整成100股的倍数。 |
| style | OrderType | 订单类型,默认是市价单。目前支持的订单类型有:style=MarketOrder() and style=LimitOrder(limit_price) |
返回
Order对象
范例
- 购买Buy 2000 股的平安银行股票,并以市价单发送:
order_shares('000001.XSHE', 2000)- 卖出2000股的平安银行股票,并以市价单发送:
order_shares('000001.XSHE', -2000)- 购买1000股的平安银行股票,并以限价单发送,价格为¥10:
order_shares('000001.XSHE', 1000, style=LimitOrder(10))1.1.2 order_target_value - 目标价值下单(股票专用)
order_target_value(id_or_ins, cash_amount, style=OrderType)买入/卖出并且自动调整该证券的仓位到一个目标价值(暂不支持卖空)。如果还没有任何该证券的仓位,那么会买入全部目标价值的证券。如果已经有了该证券的仓位,则会买入/卖出调整该证券的现在仓位和目标仓位的价值差值的数目的证券。需要注意,如果资金不足,该API将不会创建发送订单。
参数
| 参数 | 类型 | 注释 |
|---|---|---|
| id_or_ins | str或instrument对象 | order_book_id或symbol或instrument object,用户必须指定 |
| cash_amount | float-required | 最终的该证券的仓位目标价值 |
| style | OrderType | 订单类型,默认是市价单。目前支持的订单类型有:style=MarketOrder()style=LimitOrder(limit_price) |
返回
Order对象
范例
- 如果现在的投资组合中持有价值¥3000的平安银行股票的仓位并且设置其目标价值为¥10000,以下代码范例会发送价值¥7000的平安银行的买单到市场。(向下调整到最接近每手股数即100的倍数的股数):
order_target_value('000001.XSHE', 10000)1.1.3 order_target_percent - 目标比例下单(股票专用)
order_target_percent(id_or_ins, percent, style=OrderType)买入/卖出证券以自动调整该证券的仓位到占有一个指定的投资组合的目标百分比(暂不支持卖空)。
其实我们需要计算一个position_to_adjust (即应该调整的仓位)
position_to_adjust = target_position - current_position投资组合价值等于所有已有仓位的价值和剩余现金的总和。买/卖单会被下舍入一手股数(A股是100的倍数)的倍数。目标百分比应该是一个小数,并且最大值应该<=1,比如0.5表示50%。
如果position_to_adjust 计算之后是正的,那么会买入该证券,否则会卖出该证券。 需要注意,如果资金不足,该API将不会创建发送订单。
参数
| 参数 | 类型 | 注释 |
|---|---|---|
| id_or_ins | str或instrument对象 | order_book_id或symbol或instrument object,用户必须指定 |
| percent | float-required | 仓位最终所占投资组合总价值的目标百分比。 |
| style | OrderType | 订单类型,默认是市价单。目前支持的订单类型有:style=MarketOrder()style=LimitOrder(limit_price) |
返回
order对象
范例
- 如果投资组合中已经有了平安银行股票的仓位,并且占据目前投资组合的10%的价值,那么以下代码会买入平安银行股票最终使其占据投资组合价值的15%:
order_target_percent('000001.XSHE', 0.15)1.2 交易注意事项
出现以下情况,我们的交易会被回测平台自动拒单
portfolio内可用资金不足
下单数量不足一手(股票为100股)
下单价格超过当日涨跌停板限制
当前可卖(可平)仓位不足
股票当日停牌
合约已经退市(到期)或尚未上市1.3 何为市价单和限价单
撮合机制
我们加入了允许用户自定义撮合机制的功能。您可以在策略编辑页面"更多"选项下选择不同的撮合机制。目前提供的撮合方式有以下两种:
- 1.当前收盘价。即当前bar发单,以当前bar收盘价作为参考价撮合。
- 2.下一开盘价。即当前bar发单,以下一bar开盘价作为参考价撮合
市价单与限价单
1、限价单(LimitOrder)如果买单价格>=参考价,或卖单价格<=参考价,以参考价加入滑点影响成交(买得更高,卖得更低)。市价单(MarketOrder)直接以以参考价加入滑点影响成交。
2、成交数量都不超过当前bar成交量的25%。某一分钟成交量10000股,那么回测的时候我们做限制成交不能超过2500股 。一旦超过,市价单会在部分成交之后被自动撤单;限价单会一直在订单队列中等待下一个bar数据撮合成交,直到当日收盘。当日收盘后,所有未成交限价单都将被系统自动撤单。
拓展: 需要注意,在当前的分钟回测撮合模式下,用户在回测中无法通过在scheduler调用的函数中一次性实现 卖出 -> 资金释放 -> 买入 这种先卖后买的逻辑的。因为在分钟回测中,卖出并不能立刻成交。
- 分钟回测及实盘模拟:在一个
handle_bar内下单,在该handle_bar结束时统一撮合成交(成交价取决于撮合机制以及滑点设置)。 - 日回测:在一个
handelbar内下单,下单时立刻撮合成交(成交价取决于撮合机制以及滑点设置)。 - 举例来说,策略A设置每周一开盘进行调仓操作,先卖后买。那么,以下这种方式在分钟回测中无法实现卖出资金立刻释放的(在开启验资的风控情况下,可能导致后面的买入操作因资金不足而拒单):
#scheduler调用的函数需要包括context, bar_dict两个参数 def rebalance(context, bar_dict): order_shares('000001.XSHE', -100) order_shares('601998.XSHG', 100) def init(context): scheduler.run_weekly(rebalance, weekday=1)
总结
为了更好模拟实际交易中订单对市场的冲击,我们引入滑点的设置。您可以在策略编辑页面"更多"选项下进行滑点设置,允许设置的范围是[0, 1)。该设置将在一定程度上使最后的成交价"恶化",也就是买得更贵,卖得更便宜。我们的滑点方式是按照最后成交价的一定比例进行恶化。例如,设置滑点为0.1,那么如果原本买入交易的成交价为10元,则设置之后成交价将变成11元,即买得更贵。
注:真是交易不需要
1.4 交易的费用
相关介绍参考:https://www.ricequant.com/api/python/chn#backtests-margin
一旦发生了交易,投资组合的资金就会发生变化!那么接下来要介绍的投资组合是什么?
2、投资组合
我们看一张图
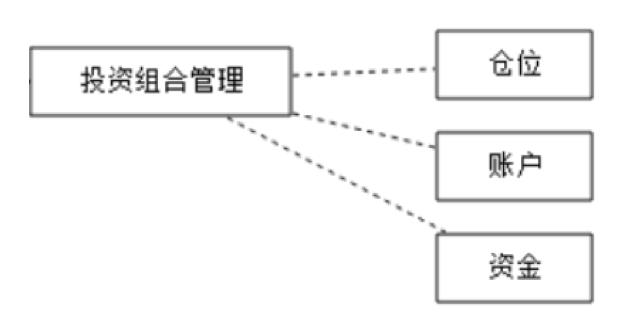
2.1 定义
投资组合是由投资人或金融机构所持有的股票、债券、金融衍生产品等组成的集合,目的是分散风险。
2.2 如何查看投资组合的信息
还记得我们之前提到的一个叫context的参数吗,这个参数当中就包含了投资组合的信息
context属性
- now - 当前时间
context.now使用以上的方式就可以在handle_bar中拿到当前的bar的时间,比如day bar的话就是那天的时间,minute bar的话就是这一分钟的时间点。
返回数据类型为datetime.datetime
- portfolio - 投资组合信息
context.portfolio该投资组合在单一股票或期货策略中分别为股票投资组合和期货投资组合。在股票+期货的混合策略中代表汇总之后的总投资组合。
- stock_account - 股票资金账户信息
context.stock_account获取股票资金账户信息。
portfolio对象
- portfolio对象
| 属性 | 类型 | 注释 |
|---|---|---|
| cash | float | 可用资金,为子账户可用资金的加总 |
| frozen_cash | float | 冻结资金,为子账户冻结资金加总 |
| total_returns | float | 投资组合至今的累积收益率 |
| daily_returns | float | 投资组合每日收益率 |
| daily_pnl | float | 当日盈亏,子账户当日盈亏的加总 |
| market_value | float | 投资组合当前的市场价值,为子账户市场价值的加总 |
| total_value | float | 总权益,为子账户总权益加总 |
| units | float | 份额。在没有出入金的情况下,策略的初始资金 |
| unit_net_value | float | 单位净值 |
| static_unit_net_value | float | 静态单位权益 |
| transaction_cost | float | 当日费用 |
| pnl | float | 当前投资组合的累计盈亏 |
| start_date | datetime.datetime | 策略投资组合的回测/实时模拟交易的开始日期 |
| annualized_returns | float | 投资组合的年化收益率 |
| positions | dict | 一个包含所有仓位的字典,以order_book_id作为键,position对象作为值,关于position的更多的信息可以在下面的部分找到。 |
Position对象
position就代表着当前我们的仓位中有哪些股票正持有,position.keys()可以获取
- 股票position对象
| 属性 | 类型 | 注释 |
|---|---|---|
| order_book_id | str | 合约代码 |
| quantity | int | 当前持仓股数 |
| pnl | float | 持仓累计盈亏 |
| sellable | int | 该仓位可卖出股数。T+1的市场中sellable = 所有持仓-今日买入的仓位 |
| market_value | float | 获得该持仓的实时市场价值 |
| value_percent | float | 获得该持仓的实时市场价值在总投资组合价值中所占比例,取值范围[0, 1] |
| avg_price | float | 平均建仓成本 |
2.3 代码
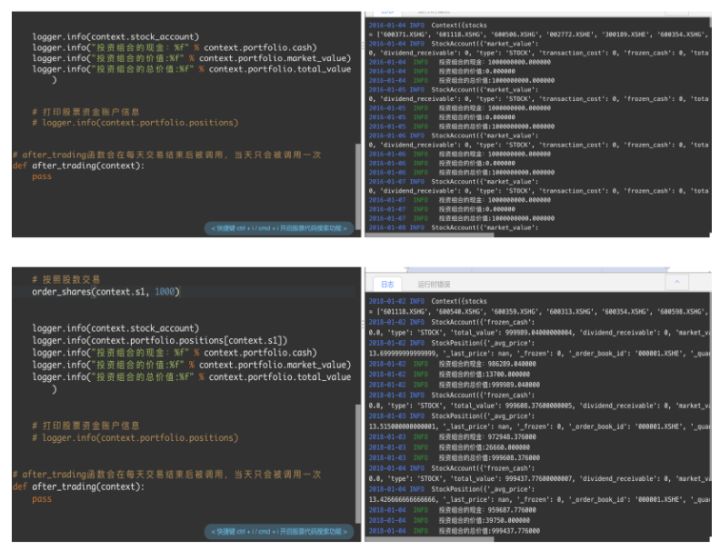
# 查看我们的投资组合信息,仓位、资金
# 查看股票账户信息
logger.info("股票账户信息:")
logger.info(context.stock_account)
# 卖出股票就要从持有的这些股票当中去选择
logger.info(context.portfolio.positions)
# 交易的价格计算
# 当日的:close * 股数
logger.info("投资组合的资金:%f" % context.portfolio.cash)
logger.info("投资组合的市场价值:%f" % context.portfolio.market_value)
logger.info("投资组合的总价值:%f" % context.portfolio.total_value)2.4 查看交易情况界面
策略评价指标
1、策略评价指标
- 收益指标
- 风险指标
2、 收益指标
2.1 回测收益率
策略在期限内的收益率。

2.2 年化收益率
采用了复利累积以及Actual/365 Fixed的年化方式计算得到的年化收益。

我们更加注重年化收益率,对于股票来讲,年化达到15~30%已经算是比较好的策略。年化收益率越高越好
2.3 基准收益率
相同条件下,一个简单的买入并持有基准合约策略的收益率(默认基准合约为沪深300指数,这里假设指数可交易,最小交易单位为1)。

基准收益率拿来对比我们的策略收益率,策略的表现期望超过基准收益率才获得了比较好的收益
3、 风险指标
风险指标指的是在获得收益的时候,承担一些风险值
3.1 最大回撤
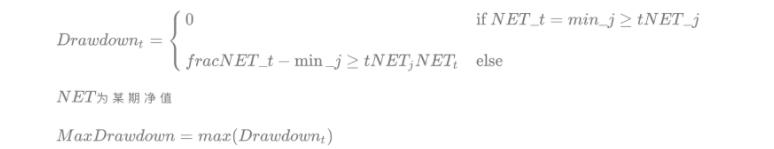
最大回撤越小越好,最大回撤最好保持10~30%之间
4、单位风险收益指标
4.1 夏普比率

举例而言,假如国债的回报是4%,而您的投资组合预期回报是16%,您的投资组合的标准偏差是5%,那么用16%-4%,可以得出12%(代表您超出无风险投资的回报),再用12%÷5%=2.4,代表投资者风险每增长1%,换来的是2.4%的多余收益。夏普比率越大,说明单位风险所获得的风险回报越高。
最终夏普比率越高越好,达到1.5以上已经是很好的结果
实现第一个股票策略
1、 选股简单介绍
不管是技术分析还是基本面分析,我们在进行投资的时候都会选择某些表现较好的股票来作为一个股票池,从中进行交易的判断(技术分析)或者直接购买。
2、 需求
- 选股:获得市盈率大于50且小于65,营业总收入前10的股票
- 调仓:每日调仓,将所有资金平摊到这10个股票的购买策略,卖出一次性卖出所有不符合条件的
3、 代码
# 可以自己import我们平台支持的第三方python模块,比如pandas、numpy等。
# 每日选股:获得市盈率大于50且小于65,营业总收入前10的股票
# 买卖:买入每天选出来的10只,卖出不符合条件
# 调仓按照月调仓,投资对象HS300
# 在这个方法中编写任何的初始化逻辑。context对象将会在你的算法策略的任何方法之间做传递。
def init(context):
# 在context中保存全局变量
# context.s1 = "000001.XSHE"
# 实时打印日志
# logger.info("RunInfo: ".format(context.run_info))
# 定义一个选股的范围
context.hs300 = index_components("000300.XSHG")
scheduler.run_monthly(get_data, tradingday=1)
def get_data(context, bar_dict):
# 删掉两个条件
# .filter(
# fundamentals.eod_derivative_indicator.pe_ratio > 50
# ).filter(
# fundamentals.eod_derivative_indicator.pe_ratio < 65
# )
# 选股
q = query(fundamentals.eod_derivative_indicator.pe_ratio,
fundamentals.income_statement.revenue
).order_by(
fundamentals.income_statement.revenue.desc()
).filter(
fundamentals.stockcode.in_(context.hs300)
).limit(10)
fund = get_fundamentals(q)
# 行列内容以及索引一起进行转置
# print(fund.T)
context.stock_list = fund.T.index
# before_trading此函数会在每天策略交易开始前被调用,当天只会被调用一次
def before_trading(context):
pass
# 你选择的证券的数据更新将会触发此段逻辑,例如日或分钟历史数据切片或者是实时数据切片更新
def handle_bar(context, bar_dict):
# 开始编写你的主要的算法逻辑
# bar_dict[order_book_id] 可以拿到某个证券的bar信息
# context.portfolio 可以拿到现在的投资组合信息
# 使用order_shares(id_or_ins, amount)方法进行落单
# TODO: 开始编写你的算法吧!
# order_shares(context.s1, 1000)
# 在这里才能进行交易
# 先判断仓位是否有股票,如果有,卖出(判断在不在新的股票池当中)
if len(context.portfolio.positions.keys()) != 0:
for stock in context.portfolio.positions.keys():
# 如果旧的持有的股票不在新的股票池当中,卖出
if stock not in context.stock_list:
order_target_percent(stock, 0)
# 买入最新的每日更新的股票池当中的股票
# 等比例资金买入,投资组合总价值的百分比平分10份
weight = 1.0 / len(context.stock_list)
for stock in context.stock_list:
order_target_percent(stock, weight)
# after_trading函数会在每天交易结束后被调用,当天只会被调用一次
def after_trading(context):
pass以上是关于如何用Serverless实现视频剪辑批量化自动化与定制化的主要内容,如果未能解决你的问题,请参考以下文章
换模型更简单如何用 Serverless 一键部署 Stable Diffusion?