selenium-webdriver循环点击百度搜索结果以及获取新页面的handler
Posted ZhuQue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium-webdriver循环点击百度搜索结果以及获取新页面的handler相关的知识,希望对你有一定的参考价值。
webdriver还是很有意思的,之前用过Ruby的watir的自动化测试框架,感觉selenium的这套框架更好一些,很容易就可以上手。我虽然不做自动化这块,不过先玩玩再说,多学点东西总之还是好一些的。
1 # coding:utf-8 2 import time 3 from selenium import webdriver 4 import unittest 5 from pythontest.commlib.baselib import * 6 7 8 #引用封装后的日志系统 9 log = TestLog().getlog() 10 class BaiBu(unittest.TestCase): 11 u\'\'\'【百度.类】\'\'\' 12 def setUp(self): 13 self.browser = webdriver.Firefox() 14 self.browser.get("http://www.baidu.com") 15 self.browser.implicitly_wait(10) 16 #self.base = Screen(self.browser) 17 18 def tearDown(self): 19 self.browser.quit() 20 21 def test_search(self): 22 log.info("搜索前title:" + self.browser.title.encode("utf-8") ) #得到的title中文编码格式,非UTF-8格式,需要转码 23 #输入关键字,关键字任意 24 self.browser.find_element_by_class_name("s_ipt").send_keys(u"北京尚拓云测 软件测试外包公司") 25 self.browser.find_element_by_class_name("s_btn").submit() #此处class属性有三个值,中间使用空格隔开,取其中一值 26 #点击搜索结果 27 self.browser.find_element_by_xpath(".//*[@id=\'2\']/h3/a").click() #根据xpath识别元素 28 time.sleep(3) 29 log.info("结果页:" + self.browser.title.encode("utf-8") ) #转码utf-8 30 self.assertIn("软件测试",self.browser.title.encode("utf-8")) #断言,转码 31 time.sleep(5) 32 \'\'\'接下来的工作,是获取新页面的handler,以及循环点击搜索结果\'\'\' 33 34 if __name__ == "__main__": 35 unittest.main()
明天有时间再优化,根据id进行随机数选取。可以参考我之前Ruby的一个自动化测试框架:http://www.cnblogs.com/zhuque/archive/2012/11/30/2796866.html
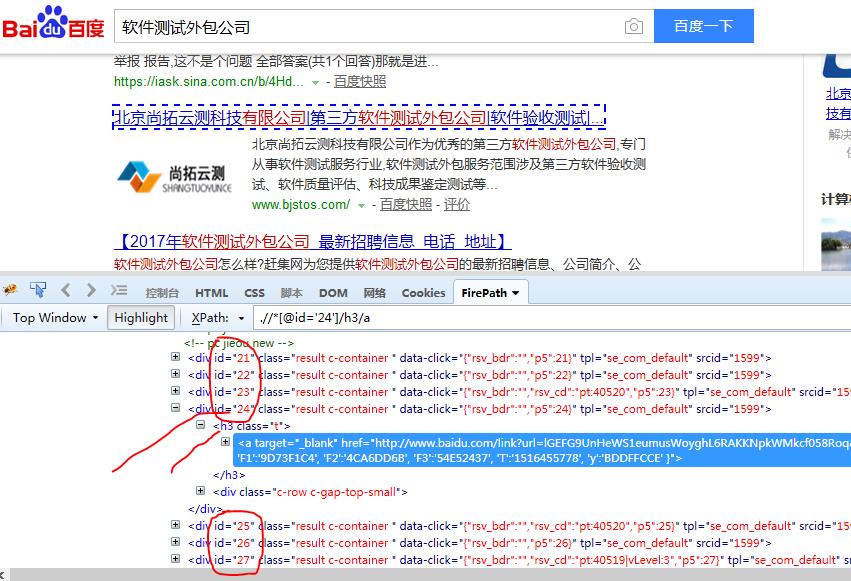
优化: 1、导入random模块,随机打开页面搜索结果;
2、获取新打开页面的页面句柄,并建立新结果页的断言
3、建立while循环,每次打开新页面前,重新获取原来结果页面的句柄
1 # coding:utf-8 2 import time 3 from selenium import webdriver 4 import unittest 5 from pythontest.commlib.baselib import * 6 import random 7 8 9 #引用封装后的日志系统 10 log = TestLog().getlog() 11 class BaiBu(unittest.TestCase): 12 u\'\'\'【百度.类】\'\'\' 13 def setUp(self): 14 self.browser = webdriver.Firefox() 15 self.browser.get("http://www.baidu.com") 16 self.browser.implicitly_wait(10) 17 #self.base = Screen(self.browser) 18 19 def tearDown(self): 20 # self.browser.quit() 21 pass 22 23 def test_search(self): 24 u\'\'\'接下来的工作,是获取新页面的handler,以及循环点击搜索结果\'\'\' 25 log.info("搜索前title:" + self.browser.title.encode("utf-8") ) #得到的title中文编码格式,非UTF-8格式,需要转码 26 #输入关键字,关键字任意 27 self.browser.find_element_by_class_name("s_ipt").send_keys(u"北京尚拓云测 软件测试外包公司") 28 self.browser.find_element_by_class_name("s_btn").submit() #此处class属性有三个值,中间使用空格隔开,取其中一值 29 i = 0 30 while i < 2: #打开两次搜索结果 31 randid = random.randint(1,5) #根据搜索结果页id属性,随机打开搜索结果 32 #点击搜索结果 33 self.browser.switch_to.window(self.browser.window_handles[0]) #获取搜索结果页的页面句柄 34 print( ".//*[@id=\'%s\']/h3/a"%(randid) ) #对print()进行格式化输出,%(randid) 35 self.browser.find_element_by_xpath( ".//*[@id=\'%s\']/h3/a"%(randid) ).click() #根据xpath识别元素 36 time.sleep(3) 37 self.browser.switch_to.window(self.browser.window_handles[-1]) #获取新打开结果页的页面句柄 38 log.info("结果页:" + self.browser.title.encode("utf-8") ) #转码utf-8 39 self.assertIn("尚拓云测",self.browser.title.encode("utf-8")) #断言,转码 40 i = i + 1 41 time.sleep(5) 42 43 if __name__ == "__main__": 44 unittest.main()
测试结果如下:

以上是关于selenium-webdriver循环点击百度搜索结果以及获取新页面的handler的主要内容,如果未能解决你的问题,请参考以下文章