使用FastJson进行驼峰下划线相互转换写法及误区
Posted 氵奄不死的鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用FastJson进行驼峰下划线相互转换写法及误区相关的知识,希望对你有一定的参考价值。
PropertyNamingStrategy
有四种序列化方式。
CamelCase策略,Java对象属性:personId,序列化后属性:persionId – 实际只改了首字母 大写变小写
PascalCase策略,Java对象属性:personId,序列化后属性:PersonId – 实际只改了首字母 小写变大写
SnakeCase策略,Java对象属性:personId,序列化后属性:person_id --大写字母前加下划线
KebabCase策略,Java对象属性:personId,序列化后属性:person-id -大写字母前加减号
public enum PropertyNamingStrategy
CamelCase, //驼峰
PascalCase, //
SnakeCase, //大写字母前加下划线
KebabCase;
public String translate(String propertyName)
switch (this)
case SnakeCase:
StringBuilder buf = new StringBuilder();
for (int i = 0; i < propertyName.length(); ++i)
char ch = propertyName.charAt(i);
if (ch >= 'A' && ch <= 'Z')
char ch_ucase = (char) (ch + 32);
if (i > 0)
buf.append('_');
buf.append(ch_ucase);
else
buf.append(ch);
return buf.toString();
case KebabCase:
StringBuilder buf = new StringBuilder();
for (int i = 0; i < propertyName.length(); ++i)
char ch = propertyName.charAt(i);
if (ch >= 'A' && ch <= 'Z')
char ch_ucase = (char) (ch + 32);
if (i > 0)
buf.append('-');
buf.append(ch_ucase);
else
buf.append(ch);
return buf.toString();
case PascalCase:
char ch = propertyName.charAt(0);
if (ch >= 'a' && ch <= 'z')
char[] chars = propertyName.toCharArray();
chars[0] -= 32;
return new String(chars);
return propertyName;
case CamelCase:
char ch = propertyName.charAt(0);
if (ch >= 'A' && ch <= 'Z')
char[] chars = propertyName.toCharArray();
chars[0] += 32;
return new String(chars);
return propertyName;
default:
return propertyName;
发挥作用的是translate方法
指定序列化格式
了解了PropertyNamingStrategy后,看其是怎么发挥作用的,
阅读源码发现在buildBeanInfo时(注意是将bean转为json时构建json信息时,如果是map,JSONObject不会有这个转换)
if(propertyNamingStrategy != null && !fieldAnnotationAndNameExists)
propertyName = propertyNamingStrategy.translate(propertyName);
这里分别调用PropertyNamingStrategy对应的方法处理
常见误区
那么也就是说通过PropertyNamingStrategy的方式设置输出格式,只对javaBean有效,并且,至于转换结果,需要根据PropertyNamingStrategy#translate方法的内容具体分析
如果javaBean中的字段是用下划线间隔的,那么指定CamelCase进行序列化,也是无法转成驼峰的!
例如
Student student = new Student();
student.setTest_name("test");
SerializeConfig serializeConfig = new SerializeConfig();
serializeConfig.setPropertyNamingStrategy(PropertyNamingStrategy.CamelCase);
System.out.println(JSON.toJSONString(student,serializeConfig));
输出test_name":“test”,因为执行 PropertyNamingStrategy#translate的CamelCase,仅仅只是,判断如果首字母大写转成小写。并不能完成,下划线到驼峰的转换
case CamelCase:
char ch = propertyName.charAt(0);
if (ch >= 'A' && ch <= 'Z')
char[] chars = propertyName.toCharArray();
chars[0] += 32;
return new String(chars);
return propertyName;
指定反序列化格式
智能匹配功能
fastjson反序列化时,是能自动下划线转驼峰的。这点是很方便的。,在反序列化时无论采用那种形式都能匹配成功并设置值
String str = "'user_name':123";
User user = JSON.parseObject(str, User.class);
System.out.println(user);
输出userName=‘123’
fastjson智能匹配处理过程
fastjson在进行反序列化的时候,对每一个json字段的key值解析时,会调用
com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer#parseField
这个方法
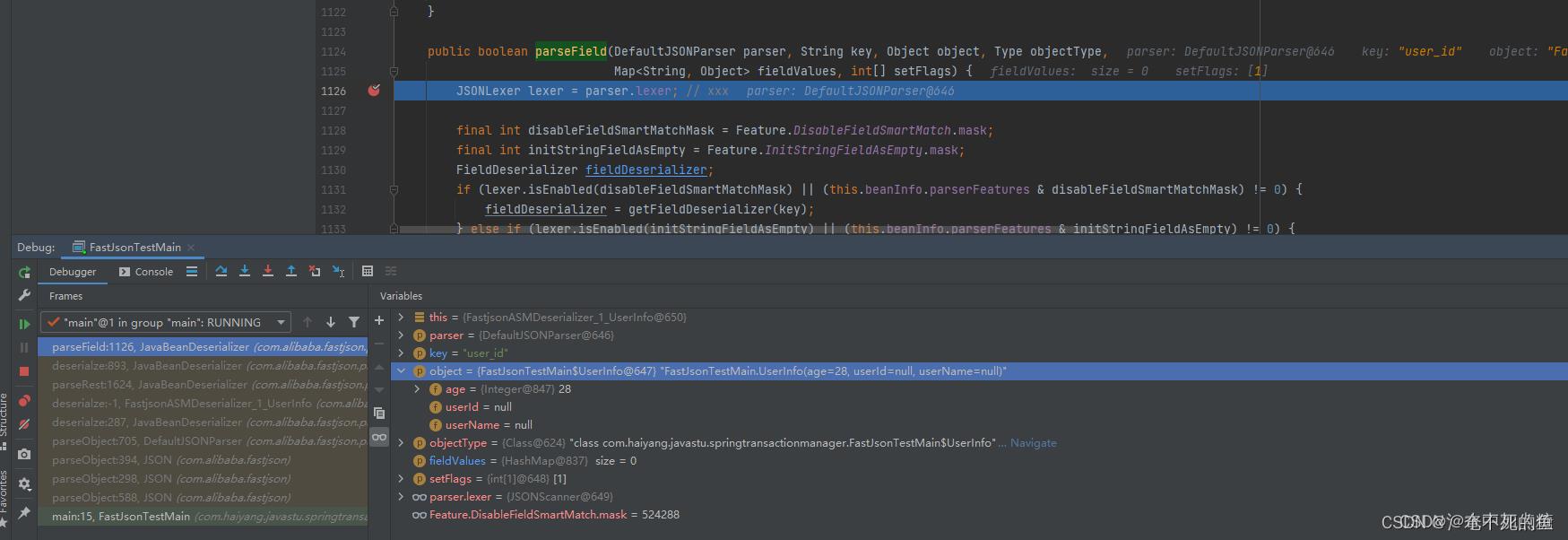
以上面的例子为例,通过debug打个断点看一下解析user_id时的处理逻辑。
此时这个方法中的key为user_id,object为要反序列化的结果对象,这个例子中就是FastJsonTestMain.UserInfo
public boolean parseField(DefaultJSONParser parser, String key, Object object, Type objectType,
Map<String, Object> fieldValues, int[] setFlags)
JSONLexer lexer = parser.lexer; // xxx
//是否禁用智能匹配;
final int disableFieldSmartMatchMask = Feature.DisableFieldSmartMatch.mask;
final int initStringFieldAsEmpty = Feature.InitStringFieldAsEmpty.mask;
FieldDeserializer fieldDeserializer;
if (lexer.isEnabled(disableFieldSmartMatchMask) || (this.beanInfo.parserFeatures & disableFieldSmartMatchMask) != 0)
fieldDeserializer = getFieldDeserializer(key);
else if (lexer.isEnabled(initStringFieldAsEmpty) || (this.beanInfo.parserFeatures & initStringFieldAsEmpty) != 0)
fieldDeserializer = smartMatch(key);
else
//进行智能匹配
fieldDeserializer = smartMatch(key, setFlags);
***此处省略N多行***
再看下核心的代码,智能匹配smartMatch
public FieldDeserializer smartMatch(String key, int[] setFlags)
if (key == null)
return null;
FieldDeserializer fieldDeserializer = getFieldDeserializer(key, setFlags);
if (fieldDeserializer == null)
if (this.smartMatchHashArray == null)
long[] hashArray = new long[sortedFieldDeserializers.length];
for (int i = 0; i < sortedFieldDeserializers.length; i++)
//java字段的nameHashCode,源码见下方
hashArray[i] = sortedFieldDeserializers[i].fieldInfo.nameHashCode;
//获取出反序列化目标对象的字段名称hashcode值,并进行排序
Arrays.sort(hashArray);
this.smartMatchHashArray = hashArray;
// smartMatchHashArrayMapping
long smartKeyHash = TypeUtils.fnv1a_64_lower(key);
//进行二分查找,判断是否找到
int pos = Arrays.binarySearch(smartMatchHashArray, smartKeyHash);
if (pos < 0)
//原始字段没有匹配到,用fnv1a_64_extract处理一下再次匹配
long smartKeyHash1 = TypeUtils.fnv1a_64_extract(key);
pos = Arrays.binarySearch(smartMatchHashArray, smartKeyHash1);
boolean is = false;
if (pos < 0 && (is = key.startsWith("is")))
//上面的操作后仍然没有匹配到,把is去掉后再次进行匹配
smartKeyHash = TypeUtils.fnv1a_64_extract(key.substring(2));
pos = Arrays.binarySearch(smartMatchHashArray, smartKeyHash);
if (pos >= 0)
//通过智能匹配字段匹配成功
if (smartMatchHashArrayMapping == null)
short[] mapping = new short[smartMatchHashArray.length];
Arrays.fill(mapping, (short) -1);
for (int i = 0; i < sortedFieldDeserializers.length; i++)
int p = Arrays.binarySearch(smartMatchHashArray, sortedFieldDeserializers[i].fieldInfo.nameHashCode);
if (p >= 0)
mapping[p] = (short) i;
smartMatchHashArrayMapping = mapping;
int deserIndex = smartMatchHashArrayMapping[pos];
if (deserIndex != -1)
if (!isSetFlag(deserIndex, setFlags))
fieldDeserializer = sortedFieldDeserializers[deserIndex];
if (fieldDeserializer != null)
FieldInfo fieldInfo = fieldDeserializer.fieldInfo;
if ((fieldInfo.parserFeatures & Feature.DisableFieldSmartMatch.mask) != 0)
return null;
Class fieldClass = fieldInfo.fieldClass;
if (is && (fieldClass != boolean.class && fieldClass != Boolean.class))
fieldDeserializer = null;
return fieldDeserializer;
通过上面的smartMatch方法可以看出,fastjson中之所以能做到下划线自动转驼峰,主要还是因为在进行字段对比时,使用了fnv1a_64_lower和fnv1a_64_extract方法进行了处理。
fnv1a_64_extract方法源码:
public static long fnv1a_64_extract(String key)
long hashCode = fnv1a_64_magic_hashcode;
for (int i = 0; i < key.length(); ++i)
char ch = key.charAt(i);
//去掉下划线和减号
if (ch == '_' || ch == '-')
continue;
//大写转小写
if (ch >= 'A' && ch <= 'Z')
ch = (char) (ch + 32);
hashCode ^= ch;
hashCode *= fnv1a_64_magic_prime;
return hashCode;
从源码可以看出,fnv1a_64_extract方法主要做了这个事:
去掉下划线、减号,并大写转小写
总结
fastjson中字段智能匹配的原理是在字段匹配时,使用了TypeUtils.fnv1a_64_lower方法对字段进行全体转小写处理。
之后再用TypeUtils.fnv1a_64_extract方法对json字段进行去掉"_“和”-"符号,再全体转小写处理。
如果上面的操作仍然没有匹配成功,会再进行一次去掉json字段中的is再次进行匹配。
如果上面的操作仍然没有匹配成功,会再进行一次去掉json字段中的is再次进行匹配。
关闭智能匹配的情况
智能匹配时默认开启的,需要手动关闭,看这个例子
String str = "'user_name':123";
ParserConfig parserConfig = new ParserConfig();
parserConfig.propertyNamingStrategy = PropertyNamingStrategy.SnakeCase;
User user = JSON.parseObject(str, User.class, parserConfig,Feature.DisableFieldSmartMatch);
System.out.println(user);
输出userName=‘null’
那么这种情况如何完成下划线到驼峰的转换
那么就需要使用parseConfig了
String str = "'user_name':123";
ParserConfig parserConfig = new ParserConfig();
parserConfig.propertyNamingStrategy = PropertyNamingStrategy.SnakeCase;
User user = JSON.parseObject(str, User.class,parserConfig,Feature.DisableFieldSmartMatch);
System.out.println(user);
那么此时PropertyNamingStrategy.SnakeCase又是如何发挥作用的?
断点PropertyNamingStrategy#translate方法
发现在构建JavaBeanDeserializer时
public JavaBeanDeserializer(ParserConfig config, Class<?> clazz, Type type)
this(config //
, JavaBeanInfo.build(clazz, type, config.propertyNamingStrategy, config.fieldBased, config.compatibleWithJavaBean, config.isJacksonCompatible())
);
if (propertyNamingStrategy != null)
propertyName = propertyNamingStrategy.translate(propertyName);
add(fieldList, new FieldInfo(propertyName, method, field, clazz, type, ordinal, serialzeFeatures, parserFeatures,
annotation, fieldAnnotation, null, genericInfo));
会根据配置对propertyName进行translate。转换成对应格式的属性名称
常见误区:
与序列化误区相同,如果是map,JSONObject不会有这个转换,并且转换结果需要参照translate方方法逻辑来看
值的注意的是,JSONObject的toJavaObject方法,智能匹配会生效。可以放心得进行下划线和驼峰得互相转换
String str = "'user_name':123";
JSONObject object = (JSONObject) JSON.parse(str);
System.out.println(object);
User user = object.toJavaObject(User.class);
System.out.println(user);
递归实现驼峰下划线相互转换,支持多层嵌套对象
/**
* 数据对象key 驼峰下划线相互转化
* @param {Object} data - 原始对象 支持-数组、key-value对象、字符串
* @param {String} type hump-转驼峰 toLine-转下划线
*/
formatHumpLineTransfer (data, type = \'hump\') {
let hump = \'\'
// 转换对象中的每一个键值为驼峰的递归
let formatTransferKey = (data) => {
if (data instanceof Array) {
data.forEach(item => formatTransferKey(item))
} else if (data instanceof Object) {
for (let key in data) {
hump = type === \'hump\' ? this.formatToHump(key) : this.formatToLine(key)
data[hump] = data[key]
if (key !== hump) {
delete data[key]
}
if (data[hump] instanceof Object) {
formatTransferKey(data[hump])
}
}
} else if (typeof data === \'string\') {
data = type === \'hump\' ? this.formatToHump(data) : this.formatToLine(data)
}
}
formatTransferKey(data)
return data
}
/**
* 字符串下划线转驼峰
* @param {String} value 需要转换的值
*/
formatToHump(value) {
return value.replace(/\\_(\\w)/g, (_, letter) => letter.toUpperCase())
}
/**
* 字符串驼峰转下划线
* @param {String} value
*/
formatToLine(value) {
return value.replace(/([A-Z])/g,"_$1").toLowerCase()
}以上是关于使用FastJson进行驼峰下划线相互转换写法及误区的主要内容,如果未能解决你的问题,请参考以下文章