机器学习技巧-训练过程中,loss参数出现NAN怎么解决?解决方案汇总?
Posted 键盘即钢琴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习技巧-训练过程中,loss参数出现NAN怎么解决?解决方案汇总?相关的知识,希望对你有一定的参考价值。
一、背景
因为最近在搞毕设,借用交友网站上的yolov5开源代码训练自己的数据集时,第一个epoch就显示各个loss=nan。
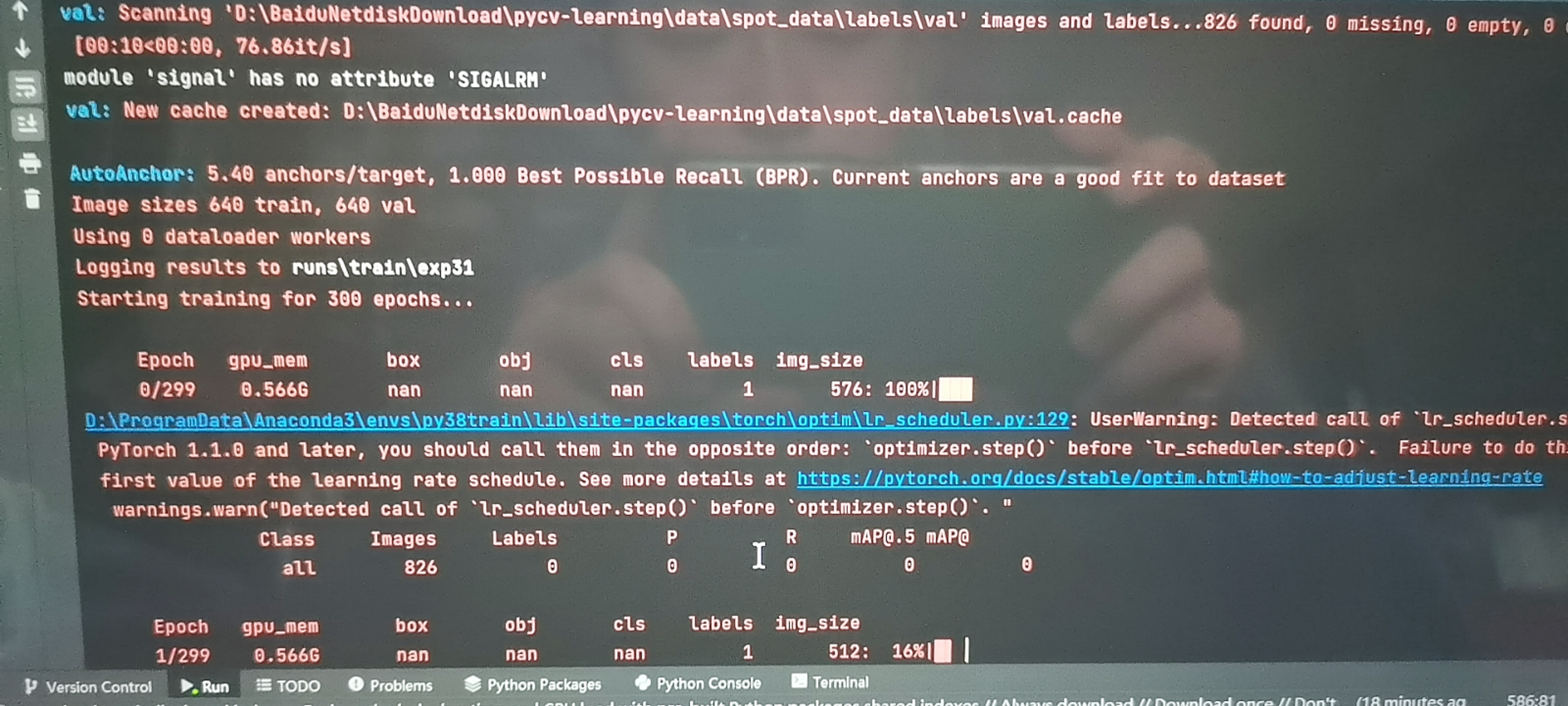
而后,近乎绝望的我找到一个玩计算机视觉玩得不错的UP主,一次调试100元, 我欣然同意了,花钱消灾!
今天上午9点约好,他控制我;在20分钟内,他新建了一个虚拟环境,把pytorch由原先的1.9版本重装成1.8版本(仍是GPU类型),接着把其他依赖库安装完后,叫我run一下代码。
非常顺利!截止到我现在写博客总结,已经训练了13轮了,还没有出现loss为nan的情况。
这位大牛告诉我:可能是因为Pytorch在1.9版本中更新了自己的API(特别是涉及到计算方法的部分),损失函数计算模式有所更改,所以用新环境计算出的结果很可能出现NAN的情况。
虽然下面这些情形,我还没遇到,但还是总结一下吧!免得到时候出现NAN,手忙脚乱不知道怎么办。
二、不同情形下不同解决办法
2.1 在不同机器(环境)下运行得到不同结果
如果你跟我一样是使用开源的代码进行训练的,那么强烈建议你新建一个环境,这个环境根据对方提供的environment.yml文件或者requirement.txt文件进行配置。
特别是base部分的依赖库,尽量保持完全一样。
比如我上面用到的YOLOv5,作者给的requirement.txt文件如下:Base部分,应该是最重要的,特别是numpy、torch、OpenCV这几种涉及到算法、计算方式的第三方库。
# pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
# Logging -------------------------------------
tensorboard>=2.4.1
# wandb
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=4.1 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export
# Extras --------------------------------------
# albumentations>=1.0.3
# Cython # for pycocotools https://github.com/cocodataset/cocoapi/issues/172
# pycocotools>=2.0 # COCO mAP
# roboflow
thop # FLOPs computation2.2 epoch=0时,也即一开始训练loss就等于nan
一般是配置问题,比如我在背景部分分享的环境配置问题,当然还有数据集配置问题(eg:label越界、label缺失)。
这种情况下。
如果是环境配置问题,就要重装环境、在朋友电脑上的环境运行一遍。
如果是数据集配置问题,可以尝试换几个模型对同样的数据集进行测试,结果没出错才说明不是数据集的问题。
2.3 epoch>0时,也即训练着训练着就出事了
这种情况下,先建议做以下几点简易的尝试:
- 增大batch size
- 减小learning rate
三、简易的尝试不管用,只好逐一调试、排查了!
下面的内容,收集于网络。
- 如果在迭代的100轮以内,出现NaN,一般情况下的原因是因为你的学习率过高,需要降低学习率。可以不断降低学习率直至不出现NaN为止,一般来说低于现有学习率1-10倍即可。
- 可能用0作为了除数;可能0或者负数作为自然对数
- 在某些涉及指数计算,可能最后算得值为INF(无穷)(比如不做其他处理的softmax中分子分母需要计算exp(x),值过大,最后可能为INF/INF,得到NaN,此时你要确认你使用的softmax中在计算exp(x)做了相关处理(比如减去最大值等等))
- 开根号里面要大于0,同时要加个Epsilon,因为开根号的导数,变量在分母上,不加Epsilon导数就成了nan
- 训练的时候因为显存不够用半精度的话,会发现如果损失超过半精度最大值就会变成inf,然后面的计算就出现nan
- 每一次batch,打印一次loss,检查是否出现梯度爆炸的情况。若有loss=inf,则可以设定一个阈值,梯度超过这个阈值就等于阈值。
- 梯度爆炸,注意每个batch前梯度要清零,optimizer.zero_grad()
训练网络中出现loss等于Nan的情况几种思路
参考技术A 在使用机器学习训练模型时,发现损失函数竟然是Nan,我们就要从一下几个方面来考虑(由重要到不重要排列):1.如果在迭代的100轮以内,出现Nan,一般情况下的原因是因为你的学习率过高,需要降低学习率。
2.训练数据中有脏数据。(所谓脏数据,就是很离谱的数据,或者完全不正确的数据,会完全带跑模型的走向;或者就是数据中的某个取值是0或者是无穷大,导致网络无法计算)
3.可能用0作为了除数
4.可能0或者负数作为自然对数
以上是关于机器学习技巧-训练过程中,loss参数出现NAN怎么解决?解决方案汇总?的主要内容,如果未能解决你的问题,请参考以下文章