数据挖掘(2.4)--数据归约和变换
Posted 码银
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘(2.4)--数据归约和变换相关的知识,希望对你有一定的参考价值。
目录
1.数据归约
在实际应用中,数据仓库可能存有海量数据,在全部数据上进行复杂的数据分析和挖掘工作所消耗的时间和空间成本巨大,这就催生了对数据进行归约的需求。
数据归约可以从几个方面入手:
- 如果对数据的每个维度的物理意义很清楚,就可以舍弃某些无用的维度,并使用平均值、汇总和计数等方式来进行聚合表示,这种方式称为数据立方体聚合;
- 如果数据只有有些维度对数据挖掘有益,就可以去除不重要的维度,保留对挖掘有帮助的维度,这种方式称为维度归约;如果数据具有潜在的相关性,那么数据实际的维度可能并不高,可以用变换的方式,用低维的数据对高维数据进行近似的表示,这种方式称为数据压缩;
- 另外一种处理数据相关性的方式是将数据表示为不同的形式来减小数据量,如聚类、回归等,这种方式称为数据块消减。
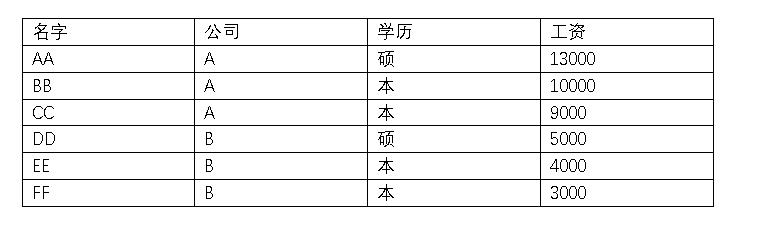
归约后:

1.1数据立方体聚合
数据立方体是一种数据表示和分析的工具,它将数据表示为多维的矩阵,可以对数据进行聚合运算如计数、求和和求平均值等操作。
1.2特征选择
特征选择在数据预处理和迭代调整的学习中都有较多的使用,目的是对于给定数据挖掘任务,选择效果较好的较小特征集合。
在预处理中,特征选择通常希望能使得在选择出的特征集合下的类别的概率分布能够尽量接近于在全部特征下的类别的概率分布,这是为了权衡空间复杂度、时间复杂度和数据挖掘效果的折中。
在原始的特征有N维的情况下,特征子集的可能情况有2^N种情形
通常使用启发式的特征选择方法如:
- 前向特征选择是通过选择新的特征添加到特征集合中,使得扩充后的特征集合具有更好的特性。
- 后向特征消减是通过从特征集合中取出最差的特征,使得新的特征集合具有更好的特性。
- 决策树归纳方法进行特征选择是借助决策树构建来选择较小特征集合的方法。
1.3数据压缩
数据压缩是在尽量保存原有数据中信息的基础上,用尽量少的空间表示原有的数据。数据压缩分为有损压缩和无损压缩,
有损压缩后的数据信息量少于原有的数据,因而无法完全恢复成原有的数据,只能以近似的方式恢复。
无损压缩没有这限制,从压缩后的数据可以完全恢复原有数据。无损压缩一般用于字符串的压缩,被广泛应用在文本文件的压缩中。【霍夫曼提出的具有理论意义的Huffman编码,以及广泛使用于gzip,deflate 等软件中的LZW算法】
在图像和音视频压缩中通常使用有损压缩,在图像压缩中常见的离散小波变换就是一种有损压缩,仅仅保存很少一部分较强的小波分量,可以在图像质量无明显下降的情况下获得相当高的压缩率。
主成分分析(PCA)是一种正交线性变换,它将数据通过正交变换到新的坐标系中,其中第一个分量有最大的方差,第二个分量有第二大的方差,依此类推,数据主要的能量集中在前几个分量中。【通常在处理维数较多的数值型数据中进行应用】
1.4其他数据归约方法
参数式方法和非参数式方法
回归分析
回归分析是一种典型的参数式方法,回归分析的一般表达式如下:
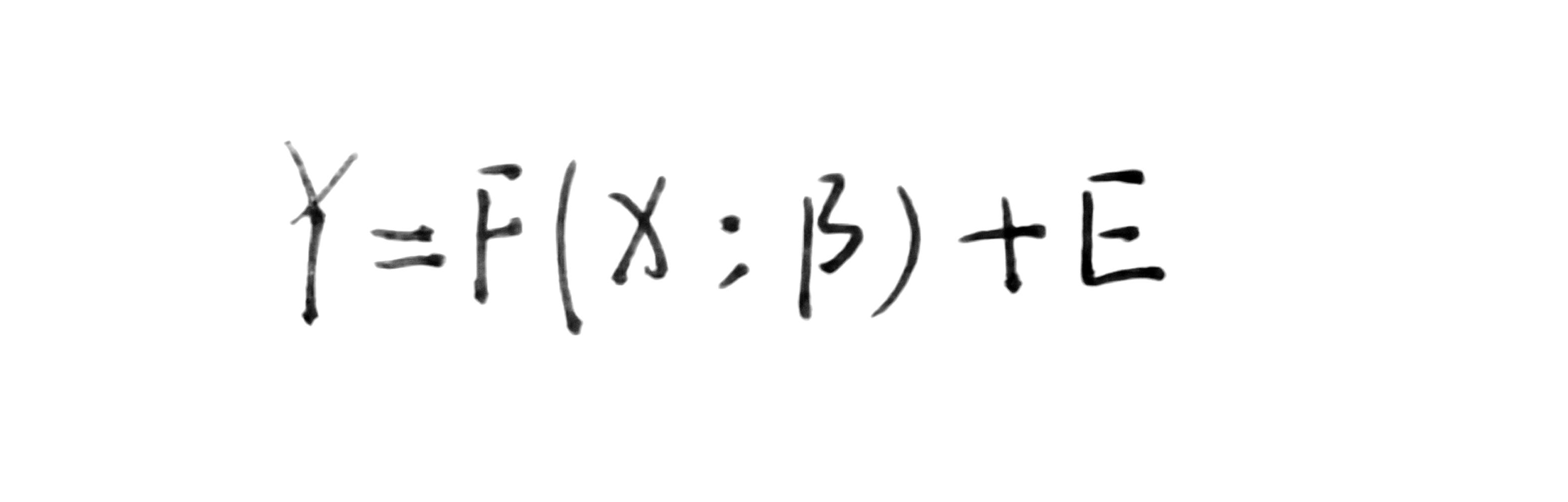
其中,F为模型的表达式,X为自变量,Y为因变量,β为模型的未知参数,E为误差,X、Y、β、E都可以是标量或矢量。回归分析的目的就是在一定条件下估计最好的参数β。根据不同
直方图

聚类
聚类是根据数据相似性将数据聚成簇的方法
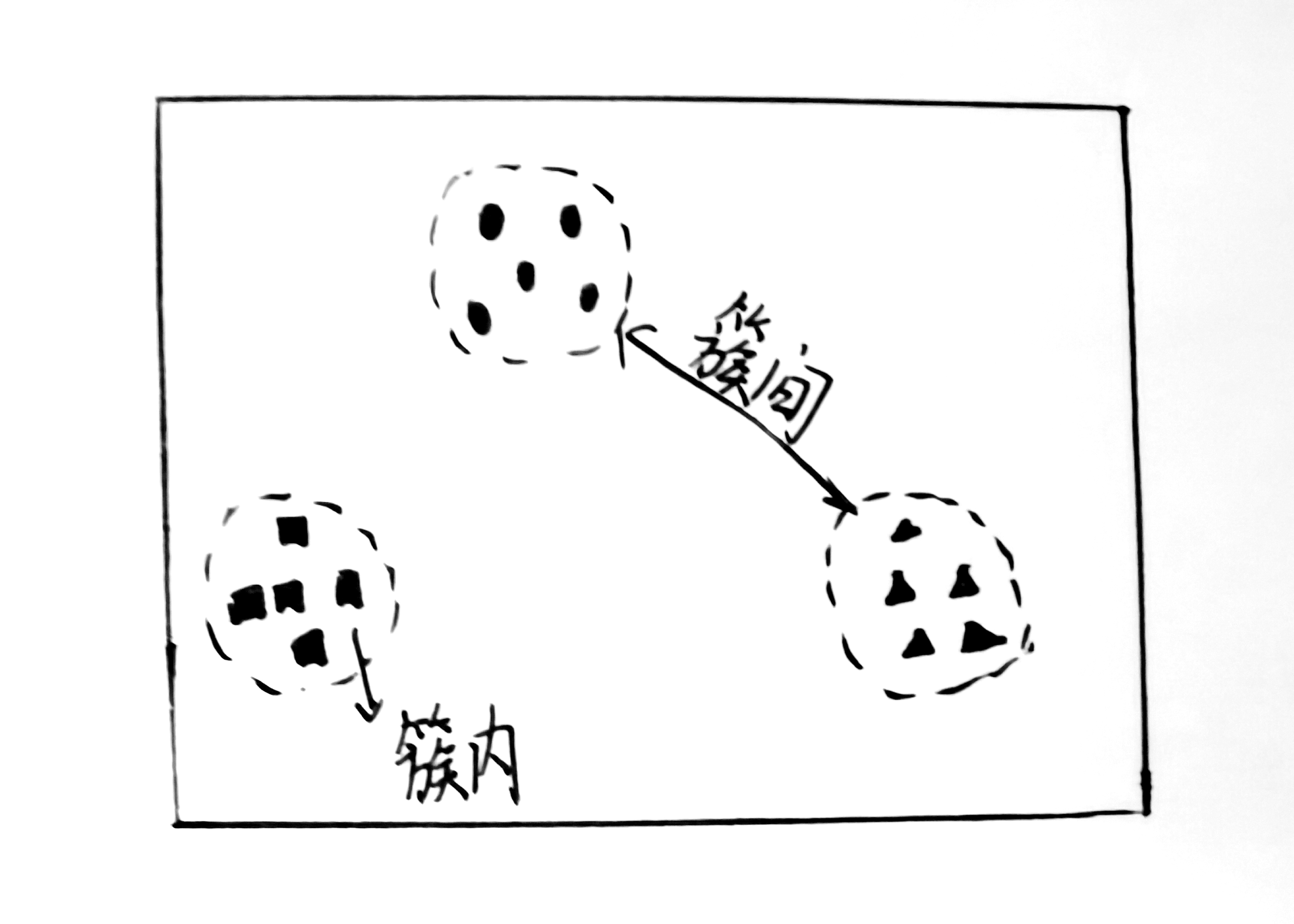
简单随机采样(SAS)
随机地从所有N个数据中抽取M个数据,简单随机采样分为有放回的简单随机采样(SRSWR)和无放回的简单随机采样(SRSWOR),两者的差别在于从总体数据中拿出一个数据后,是否将这个数据放回。
2.数据离散化
计算机存储器无法存储无限精度的值,计算机处理器也不能对无限精度的数进行处理,因此在数据预处理中需要进行数据的离散化。另外,某些数据挖掘方法需要离散值的属性,这也催生了对数据进行离散化的需要。
通常每种方法都假定待离散化的值已经控递增序排序
2.1基于信息增益的离散化
在进行数据离散化的过程中,如果关注点主要在于属性值的离散化能够有助于提高分类的准确性,那么可以使用信息增益来进行数据离散化。这种离散化方法是一种自顶向下的拆分方法。
2.2基于卡方检验的离散化
卡方检验是通过两个变量的联合分布来衡量它们是否独立的一种统计工具。在数据离散化中也可以引入这种思想,对于一个属性的两个相邻的取值区间,“属性值处于哪一个的区间”与“数据属于哪一个类别”这两个变量的独立性可以表明是否应该合并两个区间。如果两个变量独立,那么属性值在哪个区间是不影响分类的,意味着这两个区间可以合并。因此可以提出如下自底向上的区间合并算法来对数据进行离散化:每次寻找相关性最小的两个相邻区间进行合并,循环运行直到停止条件。
2.3基于自然分区的离散化
在实际问题中有时也会采用一些经验性的方法,如自然分区法,即3-4-5规则。这种方法将数值型的数据分成相对规整的自然分区。
规则如下:
- (1)如果一个区间包含的不同值的数量的最高有效位是3,6,7或9,将该区间等宽地分为3个区间;
- (2)如果最高有效位是2,4或8,将该区间等宽地分为4个区间;
- (3)如果最高有效位是1,5或10,将该区间等宽地分为5个区间。
3.概念层次生成
由用户或专家在模式级显式地说明属性的偏序
通过键对元组进行归约和求和
【中文标题】通过键对元组进行归约和求和【英文标题】:Reduce and sum tuples by key 【发布时间】:2019-03-24 16:28:21 【问题描述】:在我的 Spark Scala 应用程序中,我有一个格式如下的 RDD:
(05/05/2020, (name, 1))
(05/05/2020, (name, 1))
(05/05/2020, (name2, 1))
...
(06/05/2020, (name, 1))
我想做的是按日期对这些元素进行分组,并对与键具有相同“名称”的元组求和。
预期输出:
(05/05/2020, List[(name, 2), (name2, 1)]),
(06/05/2020, List[(name, 1)])
...
为了做到这一点,我目前正在使用groupByKey 操作和一些额外的转换,以便按键对元组进行分组并计算共享相同元组的总和。
出于性能原因,我想将这个groupByKey 操作替换为reduceByKey 或aggregateByKey,以减少通过网络传输的数据量。
但是,我不知道该怎么做。这两种转换都将值之间的函数(在我的例子中为元组)作为参数,所以我看不到如何通过键对元组进行分组以计算它们的总和。
可行吗?
【问题讨论】:
【参考方案1】:以下是使用 reduceByKey 合并元组的方法:
/**
File /path/to/file1:
15/04/2010 name
15/04/2010 name
15/04/2010 name2
15/04/2010 name2
15/04/2010 name3
16/04/2010 name
16/04/2010 name
File /path/to/file2:
15/04/2010 name
15/04/2010 name3
**/
import org.apache.spark.rdd.RDD
val filePaths = Array("/path/to/file1", "/path/to/file2").mkString(",")
val rdd: RDD[(String, (String, Int))] = sc.textFile(filePaths).
map line =>
val pair = line.split("\\t", -1)
(pair(0), (pair(1), 1))
rdd.
map case (k, (n, v)) => (k, Map(n -> v)) .
reduceByKey (acc, m) =>
acc ++ m.map case (n, v) => (n -> (acc.getOrElse(n, 0) + v))
.
map(x => (x._1, x._2.toList)).
collect
// res1: Array[(String, List[(String, Int)])] = Array(
// (15/04/2010, List((name,3), (name2,2), (name3,2))), (16/04/2010, List((name,2)))
// )
请注意,需要初始映射,因为我们要将元组合并为 Map 中的元素,而 RDD[K, V] 的 reduceByKey 在转换前后需要相同的数据类型 V:
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
【讨论】:
您的解决方案,虽然最小化似乎不起作用。在您提供的那个特别简单的示例中,它可以工作。但是,我从不同的文件中读取输入数据,奇怪的是,这些计算仅适用于从第一个文件中获取的数据。 我进一步对此进行了测试,似乎当我读取 2 个不同的文件(通过 sc.textfile)时,分区数为 2。看来您的方法仅适用于第一个分区。当我将我的 rdd 重新分区为 1 时,它可以工作,但这不是最佳的。 @matrix,我无法复制上述问题。还测试了将更大的 RDD 显式加载到多个分区中的代码,并按预期跨分区聚合。如您所见,建议的解决方案仅以最简单的形式使用常见的 RDD 方法map 和 reduceByKey。您能否分享导致错误结果的确切代码(以及示例数据,如果可能)的最小版本?
我创建了一个重现该问题的小应用程序。 (在 cmets 你会看到每个文件的数据)你可以在这里找到它:pastebin.com/E7s2zcw4
@matrix,感谢您提供能够证明上述问题的示例代码和数据。在某些情况下,该异常似乎是由reduceByKey 中的函数未在分区之间正确处理引起的。这个问题是如此微妙,以至于它不一定会通过拥有多个分区而浮出水面。当它确实浮出水面时,也不是只处理第一个分区。在这一点上,我倾向于认为它是一个错误。将函数重写为使用Map ++ Map 操作,而不是Map + element,似乎可以解决问题。请看我修改后的答案。【参考方案2】:
是的.aggeregateBykey()可以这样使用:
import scala.collection.mutable.HashMap
def merge(map: HashMap[String, Int], element: (String, Int)) =
if(map.contains(element._1)) map(element._1) += element._2 else map(element._1) = element._2
map
val input = sc.parallelize(List(("05/05/2020",("name",1)),("05/05/2020", ("name", 1)),("05/05/2020", ("name2", 1)),("06/05/2020", ("name", 1))))
val output = input.aggregateByKey(HashMap[String, Int]())(
//combining map & tuple
case (map, element) => merge(map, element)
,
// combining two maps
case (map1, map2) =>
val combined = (map1.keySet ++ map2.keySet).map i=> (i,map1.getOrElse(i,0) + map2.getOrElse(i,0)) .toMap
collection.mutable.HashMap(combined.toSeq: _*)
).mapValues(_.toList)
学分:Best way to merge two maps and sum the values of same key?
【讨论】:
【参考方案3】:您可以将 RDD 转换为 DataFrame,然后将 groupBy 与 sum 一起使用,这是一种方法
import org.apache.spark.sql.types._
val schema = StructType(StructField("date", StringType, false) :: StructField("name", StringType, false) :: StructField("value", IntegerType, false) :: Nil)
val rd = sc.parallelize(Seq(("05/05/2020", ("name", 1)),
("05/05/2020", ("name", 1)),
("05/05/2020", ("name2", 1)),
("06/05/2020", ("name", 1))))
val df = spark.createDataFrame(rd.map case (a, (b,c)) => Row(a,b,c),schema)
df.show
+----------+-----+-----+
| date| name|value|
+----------+-----+-----+
|05/05/2020| name| 1|
|05/05/2020| name| 1|
|05/05/2020|name2| 1|
|06/05/2020| name| 1|
+----------+-----+-----+
val sumdf = df.groupBy("date","name").sum("value")
sumdf.show
+----------+-----+----------+
| date| name|sum(value)|
+----------+-----+----------+
|06/05/2020| name| 1|
|05/05/2020| name| 2|
|05/05/2020|name2| 1|
+----------+-----+----------+
【讨论】:
以上是关于数据挖掘(2.4)--数据归约和变换的主要内容,如果未能解决你的问题,请参考以下文章