DnCNN-keras版本代码训练教程
Posted 假技术po主
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DnCNN-keras版本代码训练教程相关的知识,希望对你有一定的参考价值。
一、DnCNN-keras版本代码下载
(1)DnCNN-keras下载
https://download.csdn.net/download/qq_41104871/87456626
(2)DnCNN-keras版本代码运行环境配置
https://blog.csdn.net/qq_41104871/article/details/129924049
(3)DnCNN-keras版本代码训练教程
1、按照(2)打开命令框,输入"python main_train.py"运行即可进行训练。第一次运行代码会出现如下问题:
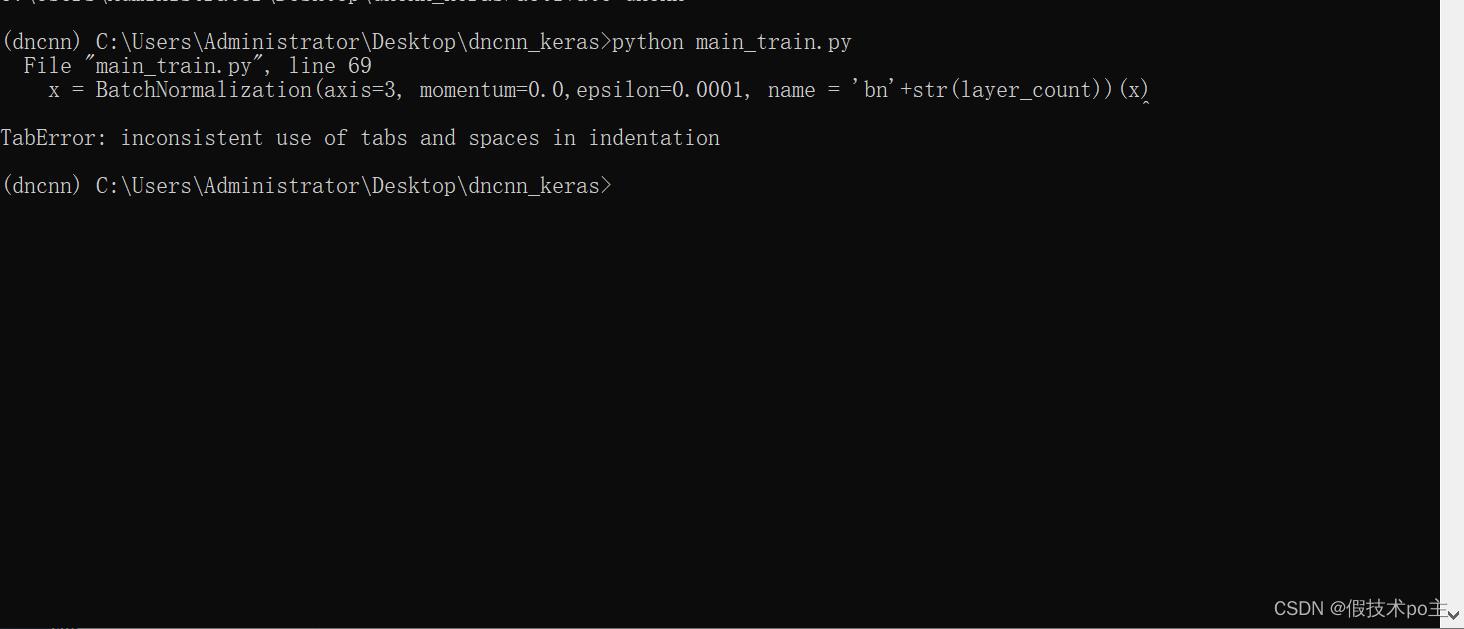
2、解决方案:将main_train.py代码第69行向右缩进先全部删除,再Tab键重新对齐到源代码初始位置即可,如下图所示:

3、继续命令框输入“python main_train.py”回车运行即可,如下图所示,即成功开始训练。
代码补全快餐教程 - 预训练模型的加载和使用
代码补全快餐教程(2) - 预训练模型的加载和使用
上一节我们用30多行代码建立了一个强大的补全模型,让大家对于transformers库有了个感性的认识。
下面我们开始补课,更深入到了解下发生在幕后的故事。
加载预训练好的语言模型
gpt2之所以强大的原因是在于它是在超过40GB的文本上进行训练的大型语言模型。通过这个大型的预训练语言模型,我们可以做一些fine-tuning针对编程语言进行优化,也可以直接通过它进行代码的预测。
因为是个预训练好权型的模型,我们首先通过GPT2LMHeadModel的from_pretrained函数将模型加载进来:
model = GPT2LMHeadModel.from_pretrained('gpt2')
gpt2只是这一系列模型中最小的一个,它的大小是522MB。比它更大的gpt2-medium是1.41GB。gpt2-large是3.02G,gpt2-xl将近6G。
换成更大的模型,我们可以将gpt2参数改成相应的模型即可。
例:
model = GPT2LMHeadModel.from_pretrained('gpt2-medium')
模型的输入输出
创建了预处理模型之后,我们就可以用模型进行推理了:
outputs = model(tokens_tensor)
默认情况下,输出参数有两个,是一个tuple。第一个是prediction_scores,第二个是past。
我们也可以这样写:
# Predict all tokens
with torch.no_grad():
predictions, past = model(tokens_tensor)
推理时主要使用prediction_scores,这个向量显示的是词表中的每个向量可能的概率值。其形状为(batch_size, sequence_length, config.vocab_size),在本例中,词表长度为50257,此时向量形状为([1, 52, 50257])
sequence_length的来源是我们的输入向量。输入向量通过GPT2Tokenizer.from_pretrained(‘gpt2’)来获取分词器,然后通过tokenizer.encode来进行向量的编码:
# Load pre-trained model tokenizer (vocabulary)
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Encode a text inputs
text = "let disposable_begin_buffer = vscode.commands.registerCommand('extension.littleemacs.beginningOfBuffer',\\nmove.beginningOfBuffer);\\nlet disposable_end_buffer = vscode.commands."
indexed_tokens = tokenizer.encode(text)
# Convert indexed tokens in a PyTorch tensor
tokens_tensor = torch.tensor([indexed_tokens])
这个tokens_tensor就是个(1,52)形状的向量。
然后我们取输出的最后一个向量,然后通过argmax取其最大值,就是最可能的值。
topk
如果我们想做beam search,而非贪婪法去进行推理,我们可以将argmax换成topk.
以取3个值为例,代码如下:
top3 = torch.topk(predictions[0,-1,:],3)
for token in top3.indices.cpu().numpy():
print(tokenizer.decode([token]))
输出如下:
register
reg
define
带labels的输入
语言模型支持带labels的输入,此时,输出的第一个参数为loss值。
我们来看一个例子:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
model = model.to('cuda')
inputs = "let disposable_begin_buffer = vscode.commands.registerCommand('extension.littleemacs.beginningOfBuffer',\\nmove.beginningOfBuffer);\\nlet disposable_end_buffer = vscode.commands."
input_ids = torch.tensor(tokenizer.encode(inputs)).unsqueeze(0) # Batch size 1
input_ids = input_ids.to('cuda')
outputs = model(input_ids, labels=input_ids)
loss, logits = outputs[:2]
print(loss)
print(logits)
因为输入时指定了可选参数labels=input_ids,所以输出时的第一个参数就变成了可选参数loss。
以上是关于DnCNN-keras版本代码训练教程的主要内容,如果未能解决你的问题,请参考以下文章