各种RL算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了各种RL算法相关的知识,希望对你有一定的参考价值。
参考技术A 在现代RL空间中绘制精确的,无所不包的算法分类法真的很难,因为算法的模块性没有用树结构很好地表示。此外,为了使某些东西适合页面并且在介绍文章中可以合理地消化,我们必须省略相当多的更高级的材料(探索,转移学习,元学习等)。也就是说,我们的目标是:1. 强调深度RL算法中最基本的设计选择,包括学习内容和学习方法,
2. 揭示这些选择中的权衡,
3. 并针对这些选择将一些突出的现代算法放入上下文中。
RL算法中最重要的分支点之一是 agent是否可以获得(或学习)环境模型的问题 。我们提到的环境模型,我们指的是一种预测状态转换和奖励的函数。
拥有模型的主要好处是, 它允许agent 通过提前思考,查看一系列可能的选择会发生什么,以及明确决定其选项 来进行规划 。然后, agent 可以将结果从提前计划中提取到学习策略中。这种方法的一个特别着名的例子是 AlphaZero 。当这种方法有效时,与没有模型的方法相比,它可以显着提高样本效率。
主要缺点是 agent通常无法获得环境的真实模型。 如果 agent 想要在这种情况下使用模型,它必须纯粹从经验中学习模型,这会产生一些挑战。最大的挑战是模型中的偏差可以被 agent 利用,从而导致 agent 在学习模型方面表现良好,但在真实环境中表现得次优(或非常可怕)。模型学习从根本上来说很难,所以即使是非常努力——愿意花费大量时间并对其进行计算——也无法获得回报。
使用模型的算法称为 基于模型 的方法,而不使用模型的算法称为 无模型 。虽然无模型方法放弃了使用模型的样本效率带来的潜在增益,但它们往往更容易实现和调整。截至撰写本简介(2018年9月)时,无模型方法比基于模型的方法更受欢迎,并且得到了更广泛的开发和测试。
RL算法中的另一个关键分支点是 要学习什么 的问题 。 通常可能的名单包括
1. 策略,无论是随机的还是确定的,
2. 动作值函数(Q函数),
3. 值函数,
4. 和/或环境模型。
使用无模型RL表示和训练agent有两种主要方法:
Policy Optimization - 策略优化. 此系列中的方法将策略明确表示为 。它们直接通过性能指标 上的梯度上升来优化参数 ,或者通过最大化 的局部近似来间接地优化参数 。此优化几乎总是以 on-policy 的方式运行,这意味着每个更新仅使用根据最新版本的策略执行时收集的数据。
策略优化通常还涉及学习on-policy值函数 的近似值 ,用于确定如何更新策略。策略优化方法的几个例子是:
1. A2C / A3C ,执行梯度上升以直接最大化性能,
2. 和 PPO ,其更新间接地最大化性能,通过最大化替代 目标函数 ,该函数给出保守估计 将由于更新而改变多少。
Q-Learning. 该系列中的方法学习最优动作值函数 的近似值 。通常,它们使用基于Bellman方程的目标函数。此优化几乎总是以 off-policy 的方式运行,这意味着每次更新都可以使用在训练期间的任何时间点收集的数据,无论agent在获取数据时如何选择探索环境。通过 和 之间的连接获得相应的策略:Q-learning agent所采取的动作由下式给出:
Q-learning方法的例子包括
1. DQN ,一个大规模推出DRL领域的经典之作,
2. 和 C51 ,一种学习回报分布的变体,其期望值为 。
Trade-offs Between Policy Optimization and Q-Learning.
策略优化方法的主要优势在于它们是原则性的,在这种意义上,你可以直接针对你想要的东西进行优化。这往往使它们稳定可靠。
相比之下,Q-learning方法仅通过训练 来满足自洽方程,间接优化agent性能。这种学习有很多失败模式,因此往往不太稳定 [1] 。但是,Q-learning方法的优势在于它们在工作时具有更高的样本效率,因为它们可以比策略优化技术更有效地重用数据。
Interpolating Between Policy Optimization and Q-Learning.
政策优化和Q学习并不矛盾(在某些情况下,事实证明,他们是 等价的 ),并且存在一系列存在于两个极端之间的算法。处在这一范围内的算法能够在任何一方的优势和劣势之间进行谨慎的权衡。 例子包括
1. DDPG 一种同时学习确定性策略和Q函数的算法,通过使用它们当中每一个来改进另一个,
2. 和 SAC ,一种使用随机策略,熵正则化和一些其他技巧来稳定学习并在标准基准上得分高于DDPG的变体。
[1] For more information about how and why Q-learning methods can fail, see 1) this classic paper by Tsitsiklis and van Roy , 2) the (much more recent) review by Szepesvari (in section 4.3.2), and 3) chapter 11 of Sutton and Barto , especially section 11.3 (on “the deadly triad” of function approximation, bootstrapping, and off-policy data, together causing instability in value-learning algorithms).
与无模型RL不同,基于模型的RL不存在少量易于定义的方法集群:使用模型有许多正交方法。我们举几个例子,但这个清单远非详尽无遗。 在每种情况下,可以给出或学习模型。
背景:纯粹的规划. 最基本的方法从未明确地表示策略,而是使用纯 模型 技术(如 模型预测控制 (MPC))来选择操作。在MPC中,每次agent观察环境时,它都会计算一个相对于模型最优的 规划 ,其中 规划 描述了在当前之后的某个固定时间窗口内采取的所有动作。 ( 规划 算法可以通过使用学习值函数来考虑超出视野的未来奖励。)然后,代理执行 规划 的第一个动作,并立即丢弃其余部分。它每次准备与环境交互时计算新 规划 ,以避免使用 规划 范围短于预期的 规划 中的动作。
MBMF 的工作探讨了MPC与深度RL的一些标准基准任务的学习环境模型。
专家迭代. 纯粹 规划 的直接后续涉及使用和学习策略 的明确表示。agent在模型中使用规划算法(如蒙特卡罗树搜索),通过从当前策略中抽样为该规划生成候选动作。规划算法产生的动作优于单独的策略产生的动作,因此它是相对于策略的“专家”。之后更新策略以生成更类似于规划算法输出的动作。
该 ExIt 算法使用这种方法来训练深层神经网络玩Hex。
AlphaZero 是这种方法的另一个例子。
无模型方法的数据增强. 使用无模型RL算法来训练策略或Q函数,但是要么1)在更新agent时增加虚构的实际经验,要么2) 仅 使用虚拟经验来更新agent。
请参阅 MBVE ,了解增加虚构实际体验的示例。
请参阅 世界模型 ,了解使用纯粹的虚拟经验训练agent的例子,他们称之为“在梦中训练”。
将规划循环嵌入到策略中。 另一种方法是将规划程序直接嵌入到作为子程序的策略中——以便完整规划成为策略的辅助信息 ——同时使用任何标准的无模型算法训练策略的输出。关键概念是,在此框架中,策略可以学习如何以及何时使用规划。这使得模型偏差不再成为问题,因为如果模型在某些状态下不适合规划,则策略可以简单地学会忽略它。
有关具有这种想象力的agent的例子,请参阅 I2A 。
[2]. A2C / A3C (Asynchronous Advantage Actor-Critic): Mnih et al, 2016
[3]. PPO (Proximal Policy Optimization): Schulman et al, 2017
[4]. TRPO (Trust Region Policy Optimization): Schulman et al, 2015
[5]. DDPG (Deep Deterministic Policy Gradient): Lillicrap et al, 2015
[6]. TD3 (Twin Delayed DDPG): Fujimoto et al, 2018
[7]. SAC (Soft Actor-Critic): Haarnoja et al, 2018
[8]. DQN (Deep Q-Networks): Mnih et al, 2013
[9]. C51 (Categorical 51-Atom DQN): Bellemare et al, 2017
[10]. QR-DQN (Quantile Regression DQN): Dabney et al, 2017
[11]. HER (Hindsight Experience Replay): Andrychowicz et al, 2017
[12]. World Models : Ha and Schmidhuber, 2018
[13]. I2A (Imagination-Augmented Agents): Weber et al, 2017
[14]. MBMF (Model-Based RL with Model-Free Fine-Tuning): Nagabandi et al, 2017
[15]. MBVE (Model-Based Value Expansion): Feinberg et al, 2018
[16]. AlphaZero : Silver et al, 2017
RL系列SARSA算法的基本结构
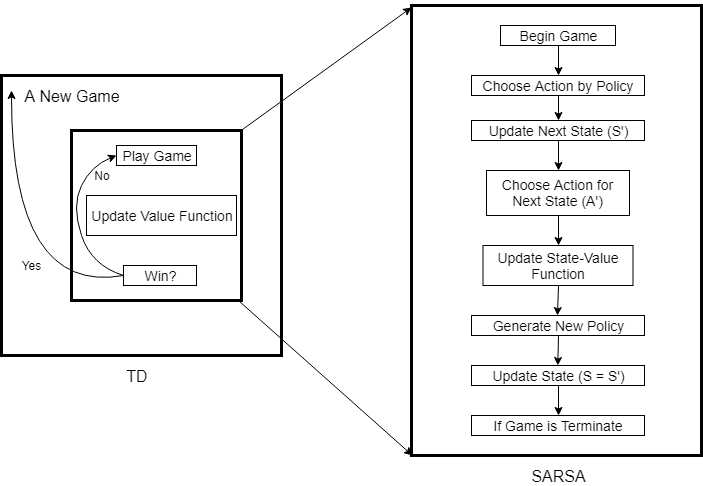
SARSA算法严格上来说,是TD(0)关于状态动作函数估计的on-policy形式,所以其基本架构与TD的$v_{pi}$估计算法(on-policy)并无太大区别,所以这里就不再单独阐述之。本文主要通过两个简单例子来实际应用SARSA算法,并在过程中熟练并总结SARSA算法的流程与基本结构。
强化学习中的统计方法(包括Monte Carlo,TD)在实现episode task时,无不例外存在着两层最基本的循环结构。如果我们将每一个episode task看作是一局游戏,那么这个游戏有开始也有结束,统计方法是就是一局接着一局不停的在玩,然后从中总结出最优策略。Monte Carlo与TD的区别在于,Monte Carlo是玩完一局,总结一次,而TD算法是边玩边总结。所以这两层基本结构的外层是以游戏次数为循环,内层则是以游戏过程为循环。
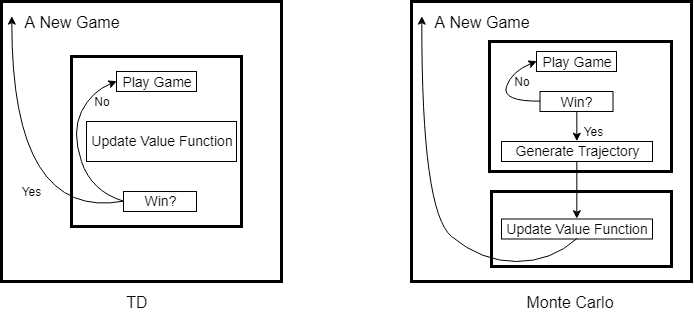
SARSA作为TD算法下的on-policy control算法,只需边进行游戏边更新动作值函数和Policy即可,所以SARSA算法的内层可以由TD算法细化为如下结构:
以上是关于各种RL算法的主要内容,如果未能解决你的问题,请参考以下文章
Java后端各种组建及功能说明,JVM脑图DS算法各种常用排序算法