对蚂蚁金服面试中几个题目的浅析
Posted KiteRunner24
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对蚂蚁金服面试中几个题目的浅析相关的知识,希望对你有一定的参考价值。
本文对今天蚂蚁金服面试中的几个问题进行简单阐述分析,望批评指正。
搜索DAG问题
问题描述:给定一个图,寻找出里面所有的有向无环图(DAG)。
问题分析:
有向无环图
在图论中,如果一个有向图无法从某个顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。
解题思路
给定一个图,如下:
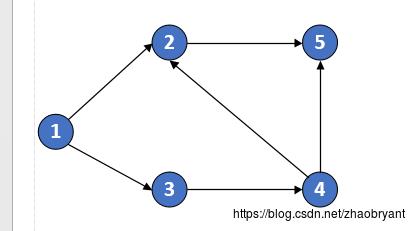
该图包括多个DAG有向无环图。
于是,对于整个算法,我们使用两个阶段来完成:
第一阶段:计算每个节点到其他节点的有向路径。为了防止成环,我们需要在合并时进行成环检测。
代码如下:
public class GraphDAGFinder
private Map<Node, NodeDAGList> nodeDAGListMap = new HashMap<>();
public void findAllDAGinGraph(Set<Node> graphNodes)
for (Node node : graphNodes)
NodeDAGList dagList = this.findAllDAGbyNode(node);
System.out.println("NODE [" + node.getId() + "] DAGS = ");
for (NodeDAGItem item : dagList.getAllDagItems())
item.printDAG();
System.out.println("-------------------------------");
private NodeDAGList findAllDAGbyNode(Node n)
NodeDAGList dagList = this.nodeDAGListMap.get(n);
if (dagList != null)
return dagList;
dagList = new NodeDAGList();
NodeDAGItem item = new NodeDAGItem();
item.addNode(n);
dagList.addNodeDAGItem(item);
if (n.getNextHops().isEmpty())
return dagList;
for (Node nd : n.getNextHops())
NodeDAGList tmplist = this.findAllDAGbyNode(nd);
for (NodeDAGItem tmpit : tmplist.getAllDagItems())
if (tmpit.hasNode(n))
continue;
NodeDAGItem itm = tmpit.copyDAG();
itm.addNode(n);
dagList.addNodeDAGItem(itm);
this.nodeDAGListMap.put(n, dagList);
return dagList;
第二阶段:路径合并成图。有了每个节点到其他节点的路径,我们可以对其所有路径进行合并,合并的规则是节点顺序不能交叉,否则会导致成环。在这里,为了合并路径,需要对不同的路径进行组合,然后再合并。
组合的代码如下,主要是寻找出对应路径集合的ID组合:
private static Set<List<Integer>> computeCombs(List<Integer> idxs)
Set<List<Integer>> combinations = new HashSet<>();
List<Integer> comb = new ArrayList<>();
for (int i = 1; i < idxs.size(); i++)
getNCombs(nodes, 0, i, comb, combinations);
return combinations;
private static void getNCombs(List<Integer> idxs, int index, int len, List<Integer> comb, Set<List<Integer>> combinations)
if (len == 0)
combinations.add(comb);
return;
if (index == idxs.size())
return;
comb.add(idxs.get(index));
getNCombs(idxs, index + 1, len - 1, comb, combinations);
comb.remove(idxs.get(index));
getNCombs(idxs, index + 1, len, comb, combinations);
合并流程如下:
从源节点开始,所有路径向后遍历,直到出现交叉,此时,选择某一分支停止向后遍历。以此类推,直到所有分支全部停止或遍历完成。
这里的合并可能有多个结果,统一存储。
最后的结果如下所示:
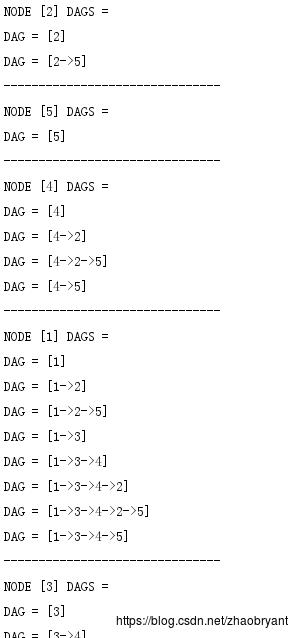
后续工作
对于整个问题,我们这里采用了两阶段的处理过程,能够得到结果,但是对于大规模节点图,仍然存在时间复杂度较高的问题。因此,后续工作可以围绕如何进一步降低搜索空间的方式来进行进一步的优化。比如,换一个维度,从边入手,而不是从节点入手;又如,使用回溯非递归+全局变量存储的方式来代替现有的递归方案,从而进一步减少栈溢出错误;再如,查阅论文文献,参考别人的算法,理解吃透优化。
脑裂问题
摘自CSDN博客:
在高可用HA系统中,当联系两个节点的心跳线断开时,原本为一个整体的动作协调的HA系统,就会分裂成为两个独立的个体。这时,由于两个节点相互失去了联系,都以为是对方出现了故障,两个节点上的HA软件就会像裂脑人一样,争夺共享资源,争相提供应用服务,这个时候就会出现严重后果:
- 共享资源被瓜分,两个节点的服务都起不来;
- 两个节点的服务都起来了,但同时读写共享资源,导致数据损坏。
一般来说,脑裂问题产生的原因主要包括下面几个:
- 高可用服务器之间的心跳线发生故障,导致无法正常通信;
- 高可用服务器开启了iptables防火墙,阻挡了心跳消息传输;
- 高可用服务器上网卡地址等信息配置不正确,导致发送心跳消息失败。
可以认为,在集群或者主备模式下,由于网络原因导致节点之间不可达,此时,每个网络分区就会自主选择出master节点,从而造成原来的集群存在多个master节点。这些master节点会争夺共享资源,从而导致系统出现服务不可用或资源损坏等问题。
解决方案:
- 添加冗余的心跳线,如双心跳线,尽量减少“脑裂”的发生几率。
- 设置仲裁机制,当心跳线完全断开时,两个节点相互ping一下参考IP,不通则表示断点就出在本端,此时可自动重启,从而彻底释放可能还占用的共享资源。
- 增加节点至奇数个,通过raft或paxos协议来进行投票选举主节点。
以上是关于对蚂蚁金服面试中几个题目的浅析的主要内容,如果未能解决你的问题,请参考以下文章