AI 视频云 VS 窄带高清,谁是视频时代的宠儿
Posted 又拍云 UPYUN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI 视频云 VS 窄带高清,谁是视频时代的宠儿相关的知识,希望对你有一定的参考价值。
随着网络技术的逐渐改善,各类视频消息成为媒体传播的主要选择手段。但其实支撑着视频传播的并不单单是网络技术,还有视频转码与压缩技术。这类技术下分很多,比如曾经被频繁提到的 H.265,比如时下热门的窄带高清,比如与元宇宙密不可分的 AI 视频云,他们都有些什么差别,在选择时我们该选择什么?
窄带高清
我们通常所说的窄带高清,指的是在视频编码率保持不变的前提下,平均降低视频大小的方法。以又拍云窄带高清为例,其工作大致流程为首先输入一个视频转码的分片,接着进行复杂度分析,然后分场景转码参数,比如运动缓慢还是剧烈,当然这其中还会有码率控制的算法来调整编码器的输出,最终得到编码后的视频。
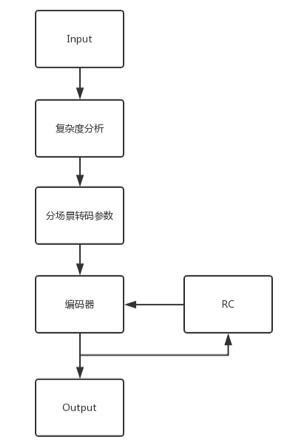
这其中的复杂度,又拍云借鉴了标准 BT1788 里的关于空间感知信息和时间感知信息。空间感知信息是每一帧图像做一个 Sobel 值,然后分析它的纹理的多少作为参考标准;时间感知信息是帧与帧之间的帧差做标准差,作为时间上的变化情况。又拍云最初根据用户的应用场景不同一共分了四类场景:手机自拍、动画、运动缓慢和运动剧烈。不需要用户操作,由系统根据复杂度的分析自动选择上面四个最合适的方法。
而编码器则使用了 H.264 和 H.265 两种。其中 H.265 是在视频编码标准 H.264 基础上,进一步提高压缩效率、提高鲁棒性(Robustness 抗变换性)和错误恢复能力、减少实时的时延、减少信道获取时间和随机接入时延、降低复杂度,以达到最优化设置。

在窄带高清中二者编码框架差不多,都是关于空间域和时间域的冗余压缩。其中 H.264 的框架流程包括了帧间、帧内的预测、变换、量化、反变换反量化、熵编码和去方块滤波。而 H.265 大致上与 H.264 相同,包括了帧间、帧内的预测、熵编码等,只不过 Deblocking 为了去除“块效应",增加了一个新的 SAO 的滤波来消除振铃效应。不过虽然框架相同,H.265 在技术上却进行了相关优化:
-
H.264 块的尺寸是从 16x16 扩展到 H.265 的 64x64,这是一个指数级的块的复杂度的提升;
-
H.265 帧内的预测方向提升到了 35 种。因为 H.265 是针对高清的,包括 1080P、2K、4K,最高到 8K,这种图片的尺寸会比较大,所以它可以分大块,对于那些变化不明显的大块图像区域,可以用更大的块尺寸,可以在预测环节减少分块带来的复杂计算。对运动矢量也做了优化,并且对亮度和色度差值算法变的更复杂;
-
加入了并行计算,因为复杂度提升了很多,而且目前计算机行业的并行技术发展的也很好,所以在视频编码标准制定的时候加入了并行的优化,来节省编码时间。
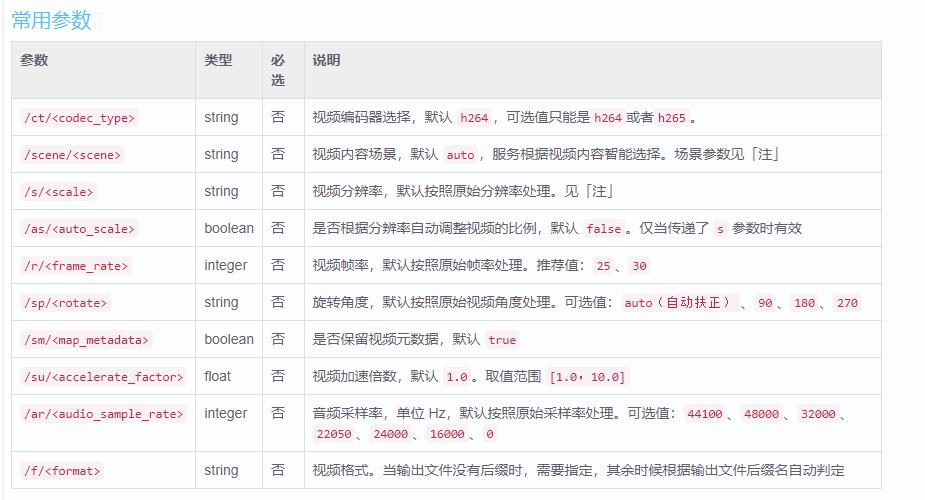
这些优化功能可以通过设置参数来进行调整。
AI视频云
AI 技术的加入,让用户对视频的内容、检索、个性化推荐、等等个性化设置上都有更大的选择和便利。
AI 视频云通过结合新型算力生态、边缘计算和低功耗 AI 视频芯片等前沿技术,由 AI 进行有效信息的快速提取和构筑,进而减少人力、物力、时间的损耗。
其中边缘计算让服务的计算能力更接近于用户,它的基本理念是将数据的处理、应用程序的运行,甚至一些功能服务的实现,由中心服务器下放到网络边缘的节点上,从而有效得减小计算系统的延迟,减少数据传输带宽,缓解云计算中心压力,提高可用性,保护数据安全和隐私。
与上面所提到的窄带高清不同,AI 视频云更致力于打造全生命周期的,云边一体化视频服务。一般会从以下几个方面提供服务:
-
快速产出视频:提供视频录制、编辑、播放为一体的内容生产解决方案。
-
完美兼容不同格式、时间的数据:针对大数据和物联网背景下的数据存储需求,提供非结构化数据云存储 USS、融合云存储等对象存储服务。同时提供快速迁移服务,避免用户被数据所困,帮助用户掌握数据主权。
-
对于海量数据进行智能分析:基于新型算力生态、边缘计算和低功耗 AI 视频芯片等前沿技术,对 AI算法进行持续训练,让 AI 形成对特定场景的视频理解能力和视频结构化分析能力。有效且快速地提取有价值的结构信息,免除大量人力、物力和时间的损耗
-
降低成本,提升效率:针对多媒体数据,能有效降低 40-70% 视频大小,同时提供智能视频还原等多种前沿技术。让用户不再需要自建服务和功能,随需随用,大幅降低开发成本。
-
避免运营商差异,完成快速分发:依托云服务商大量的节点分部,覆盖全部运营商,同时提供智能调度和边缘缓存功能。能针对应用内容快速分发,提高网站响应速度。
那么 AI 视频云和窄带高清又有什么差别呢?

相比窄带高清,AI 视频云的使用更加方便,使用也能更加贴合用户场景。依托于 AI 的智能特性,AI 视频云会不断进行自动调整,不会出现更新换代的问题。
从技术全景到场景实战,透析「窄带高清」的演进突破
随着5G时代的到来,互联网短视频、电影电视剧、电商直播、游戏直播、视频会议等音视频业务呈井喷式发展。
作为通用云端转码平台,阿里云视频云的窄带高清需要处理海量、不同质量的视频。对于中高质量的视频,现有的窄带高清1.0就能提供满意的转码效果,并带来达30%的带宽成本降低;而对于有明显压缩失真和成像噪声的低质量视频,需要使用性能更好的窄带高清2.0进行去压缩失真、去噪和增强处理从而得到更好的观看体验。
在2022稀土开发者大会上,阿里云智能视频云技术专家周明才以《阿里云窄带高清的演进突破与场景实战》为主题,深度分享阿里云视频云在窄带高清上的研发思考与实践。
01 窄带高清的源起
谈及窄带高清之前,先来聊聊普通的云端转码流程。转码本质上是一个先解码再编码的过程。从下图可以看到,普通云端转码是在用户端先形成一个原始视频,经过编码之后以视频流的形式传到服务端,在服务端解码之后做转码,然后再编码通过CDN(内容分发网络)分发出去,此时普通转码主要的功能就是做视频格式的统一,并在一定程度上降低码率。
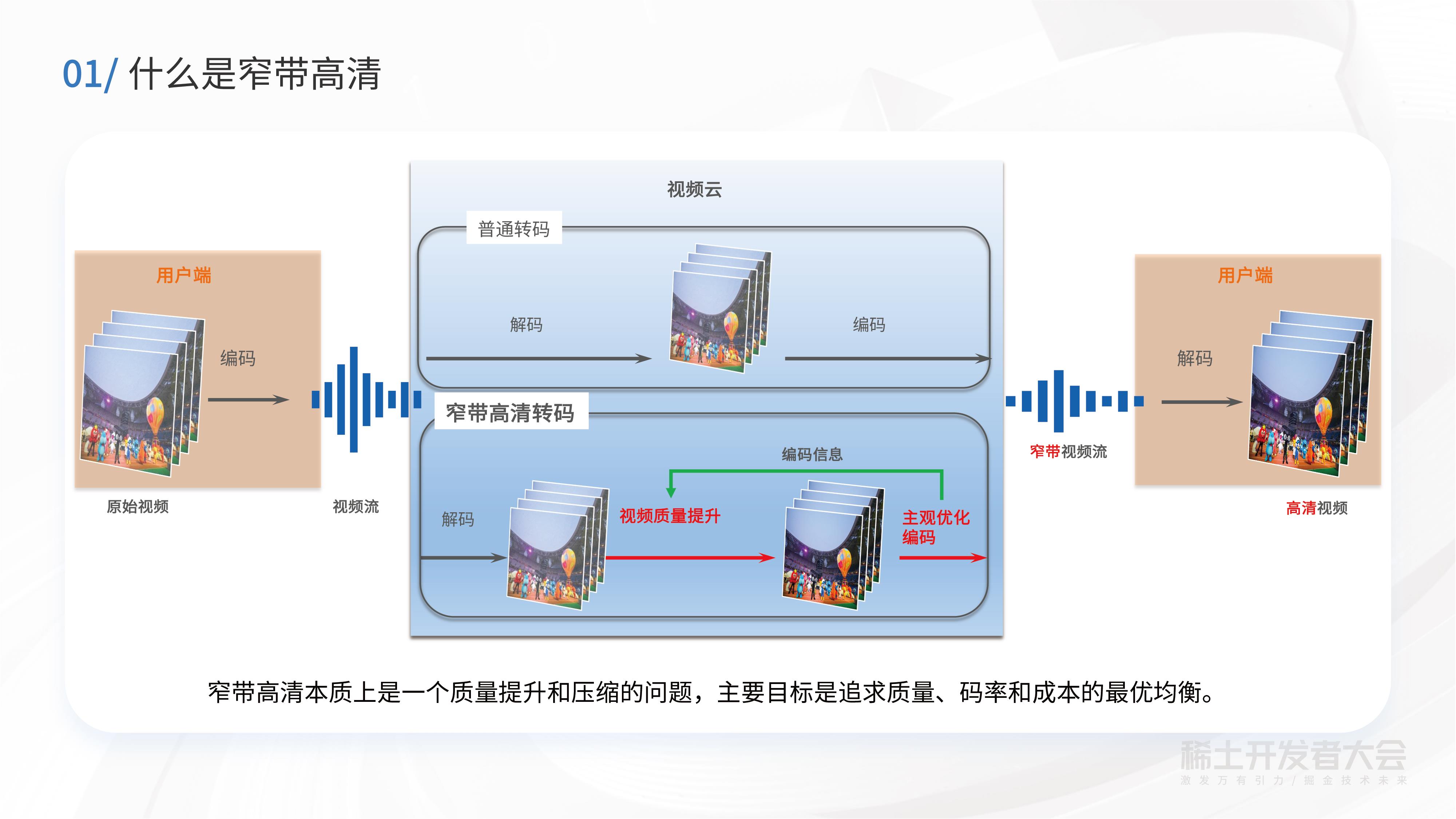
窄带高清是什么?它与普通转码的主要区别是什么?通过窄带高清的字面意思可以理解,“窄带”是指让视频经过窄带高清转码之后,对带宽的需求变得更小。同时,“高清”是指经过转码后的画质仍然能够保持高清、丰富的视觉体验。
上图的下半部分也就是窄带高清的流程,与普通转码流程不同点在于,在云端做了解码之后,窄带高清还会对视频质量做增强处理,以及利用编码信息来辅助提升视频质量。经过质量提升后,再用针对主观质量做过优化的编码器进行编码,最后进行分发。
总结来说,窄带高清本质上解决的是质量提升和压缩的问题,其主要目标是追求质量、码率和成本的最优均衡。
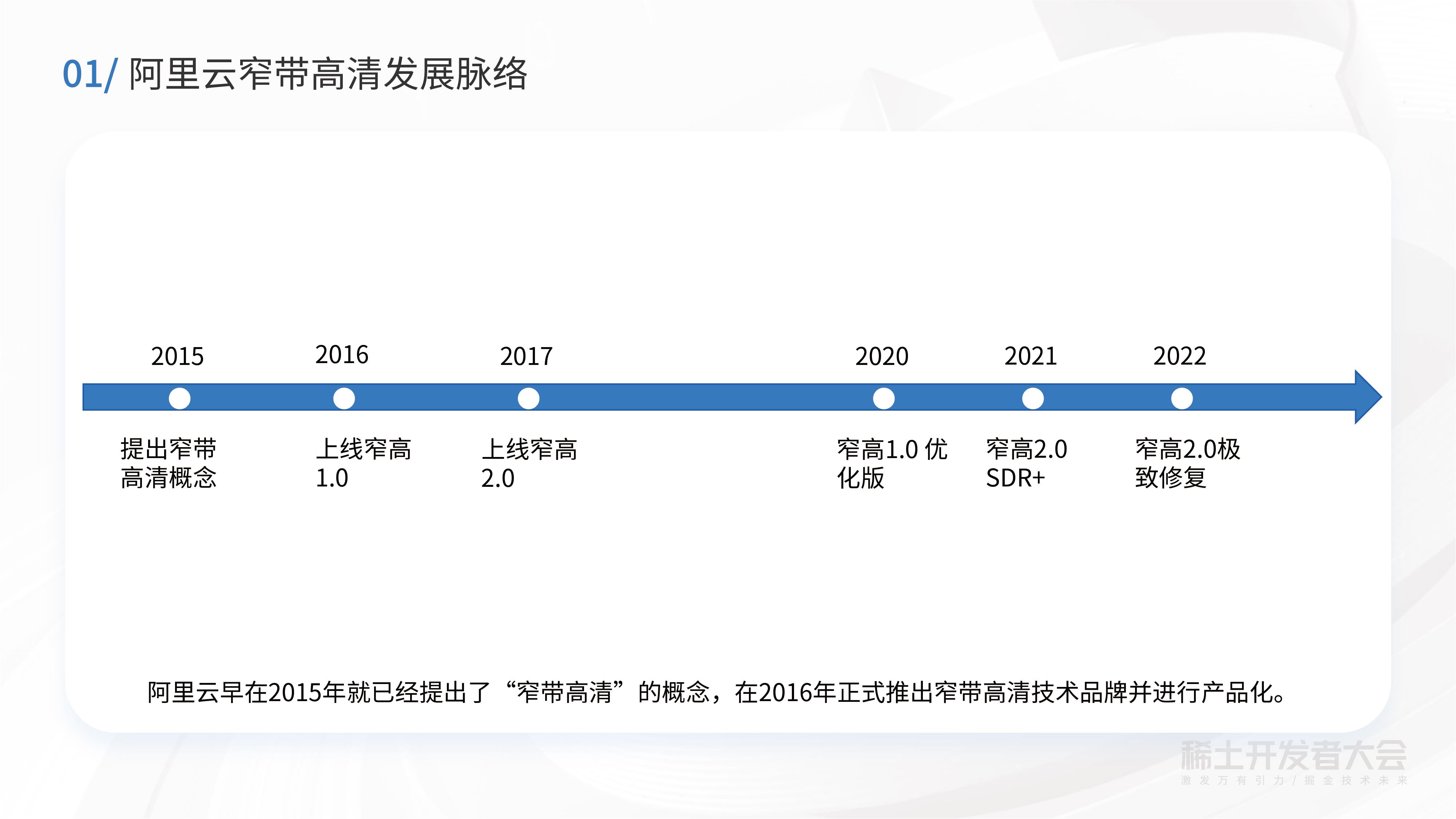
阿里云早在2015年就已经提出了窄带高清这一概念。在2016年正式推出窄带高清这一技术品牌并且进行了产品化。
今年,阿里云推出了窄带高清2.0极致修复生成版本。相较于先前版本,最大特点是能生成细节纹理做到极致修复。
窄带高清全景图
窄带高清在做自适应参数决策时主要考虑三个维度:业务场景、视频热度、视频内容。
由于业务场景的不同,比如电商直播、游戏直播、赛事直播,所需要的视频增强和编码参数不一样;对于一些高热内容,如:在手淘场景中可以用窄带高清2.0启动二次转码来实现质量的进一步提升和码率的节省;在视频内容维度,会针对当前的视频做一些High-level和 Low-level的分析,High-level包含语义的分析,特别是ROI的检测,Low-level包括视频压缩程度、模糊程度、噪声程度的视频质量分析。

根据以上这些维度的分析,可以得到自适应参数的决策结果。根据此结果,窄带高清再去做相应的视频修复和视频增强。具体来说,视频修复包括强压缩失真、降噪等,视频增强包含细节增强、色彩增强、对比度增强等。
02 视频内容分析
ROI
ROI的主要目的是在码率受限或码率一致的情况下,将码率尽可能分配到人眼更关注的区域,比如在电影电视剧中,观众会更多关注主角的脸。
基于ROI的处理和压缩,有以下两个难点:一是如何得到低成本的ROI算法,二是如何基于ROI进行码控决策,例如:保证ROI区域主观质量提升的同时,非ROI区域的主观质量不会明显下降;同时做到时域连续、不闪烁。
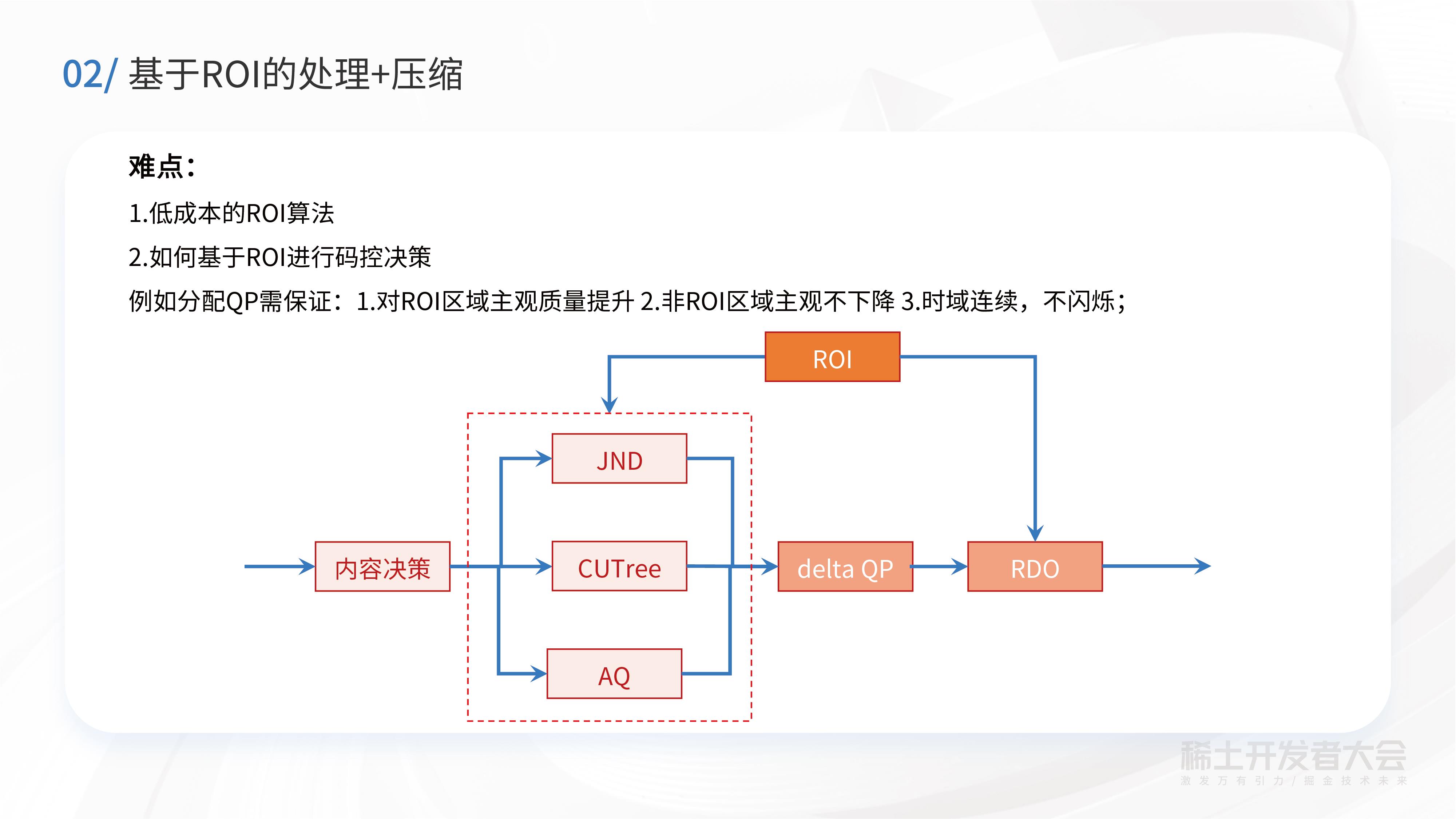
在低成本ROI计算方面,阿里云自研了自适应决策的人脸检测跟踪算法,这是一款低成本、高精度的算法。在极大部分时间只需要做计算量极小的人脸跟踪,只有少部分时间做人脸检测,从而在保证高精度的情况下,实现超低成本和快速ROI获取。
从下图表格里面可以看到,阿里云自研算法相比开源人脸检测算法,精度和召回基本上没有损失,同时复杂度和计算耗时有明显数量级的下降。
在有了ROI算法之后,需要对场景、视频质量的自适应码率分配进行决策。针对此难题,主要考虑与编码器结合,在主观和客观之间取得均衡,同时保证时域的一致。

JND
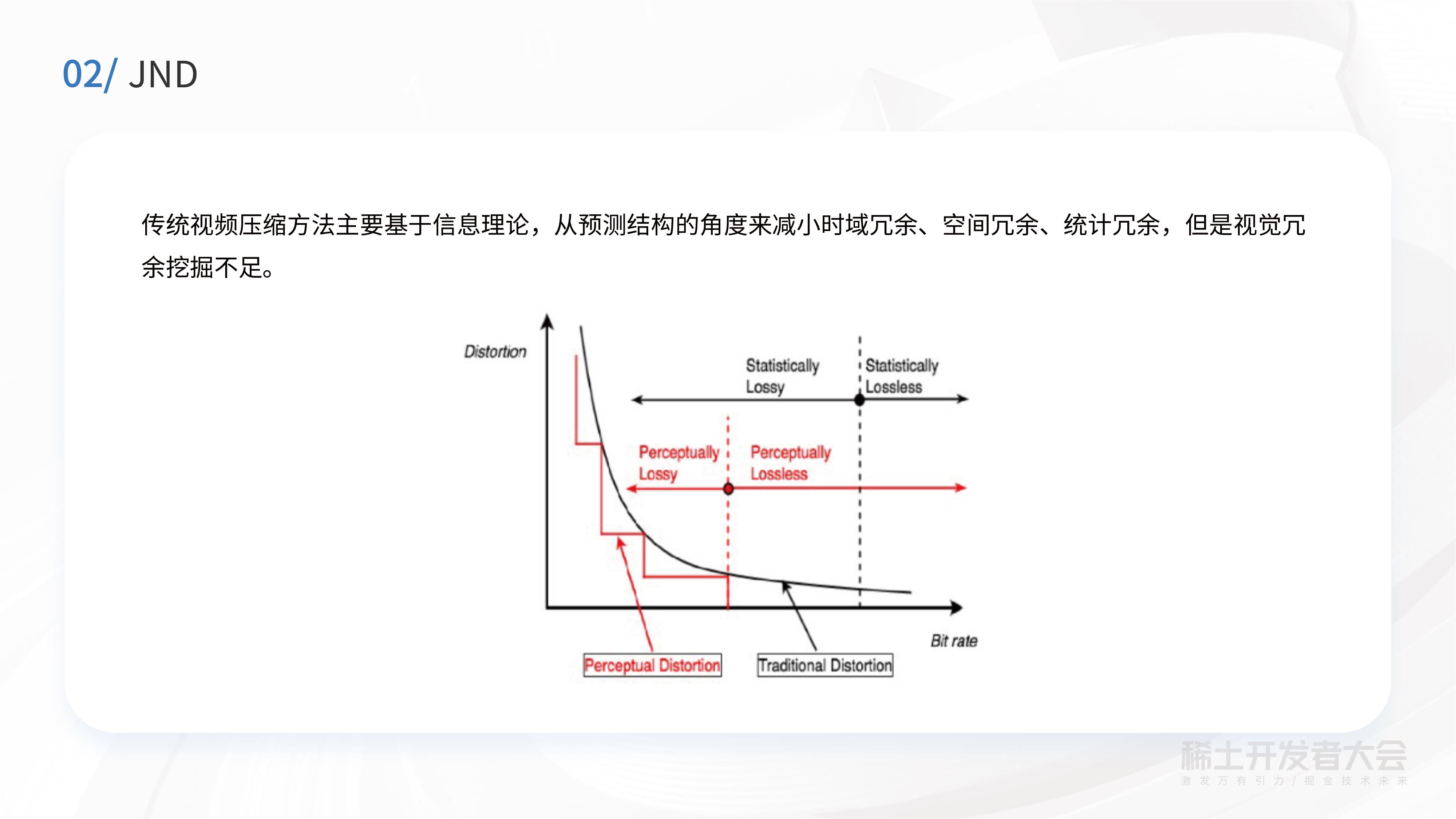
传统视频压缩方法主要基于信息理论,从预测结构的角度减小时域冗余、空间冗余、统计冗余,但这对视觉冗余挖掘是远远不够的。
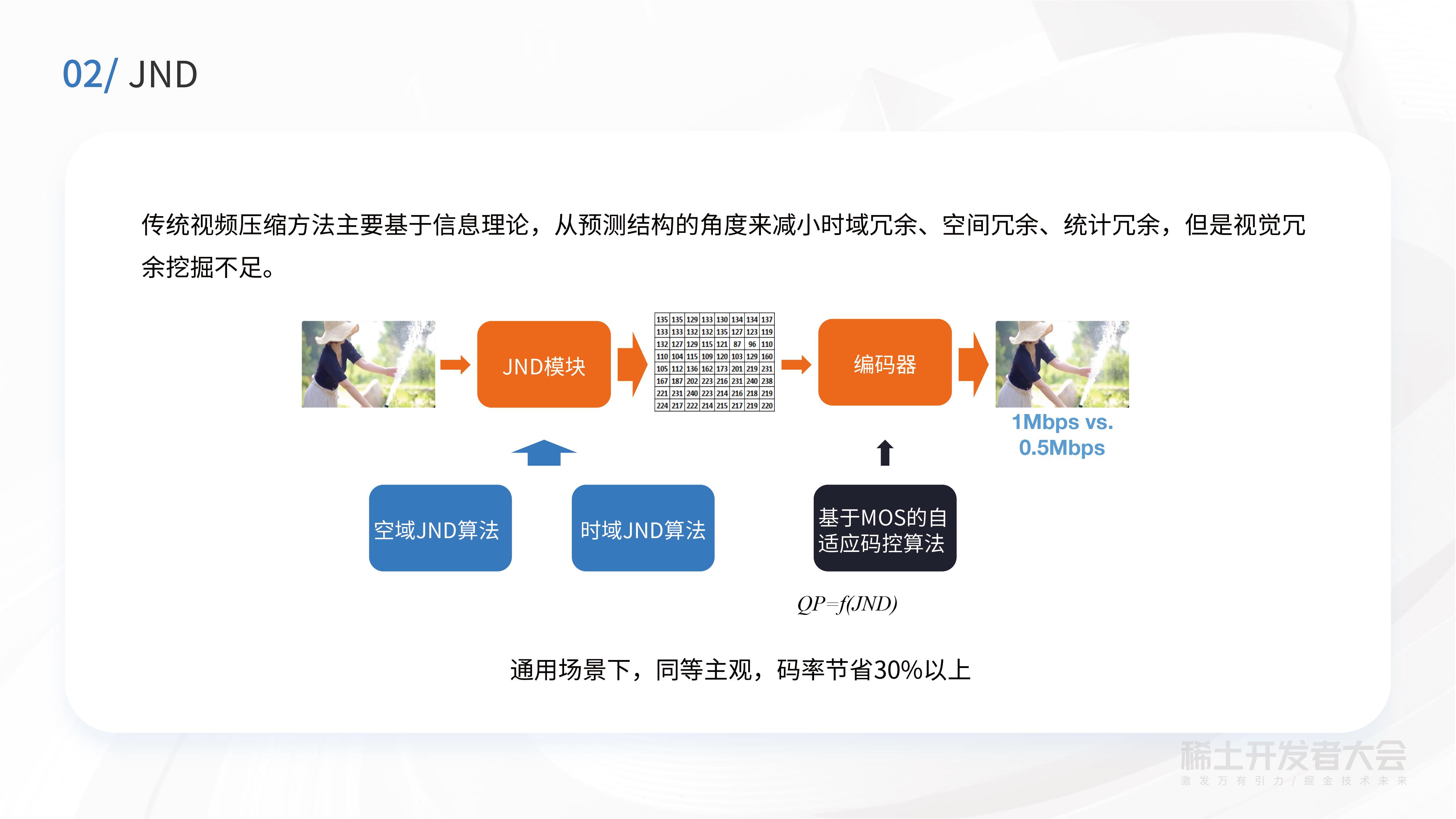
在JND算法里,主要采用了两个算法,一个是空域JND算法,一个是时域JND算法,拿到这些JND算法后,我们再基于MOS的自适应码控算法,对QP做自适应的分配,最终实现在通用场景及主观情况下,码率可以节省30%以上。
03 视频修复增强
细节增强
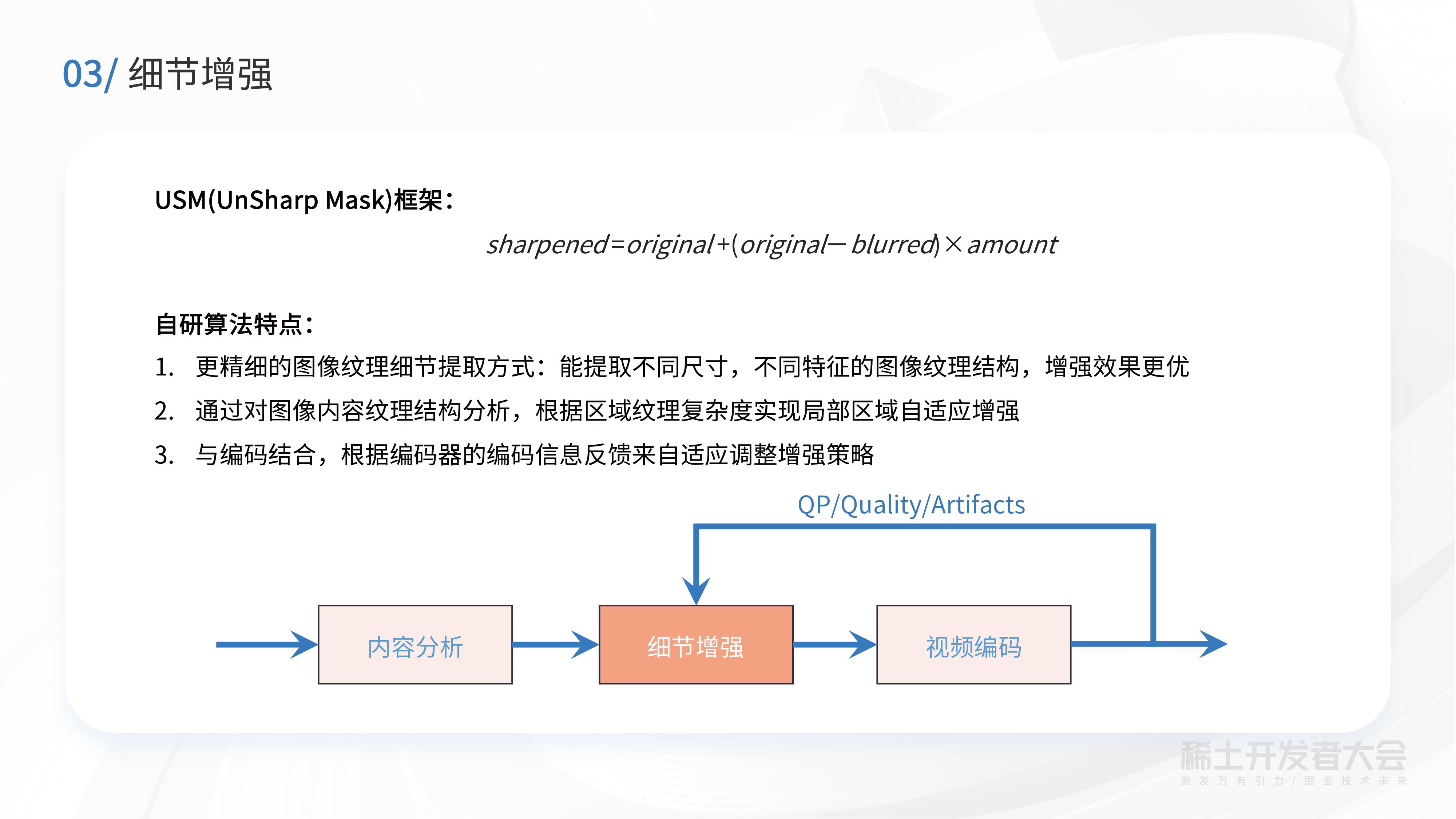
讲到视频修复增强,提及最多的就是细节增强部分,效果确实会比较明显。
通常的细节增强基于UnSharp Mask的框架。阿里云视频云自研的细节增强算法,有以下三个特点:第一是有更精细的图像纹理细节提取方式,能提取不同尺寸,不同特征的图像纹理结构,增强效果更优;第二,算法可以通过对图像内容纹理结构分析,根据区域纹理复杂度实现局部区域自适应增强;第三个特点是算法可以和与编码结合,根据编码器的编码信息反馈来自适应调整增强策略。
色彩增强
通常采集的视频素材,因为采集的设备或者光线亮度的原因,导致素材颜色可能看起来会比较暗淡。特别是在短视频场景,这类视频会失去视觉吸引力,因此需要色彩增强。
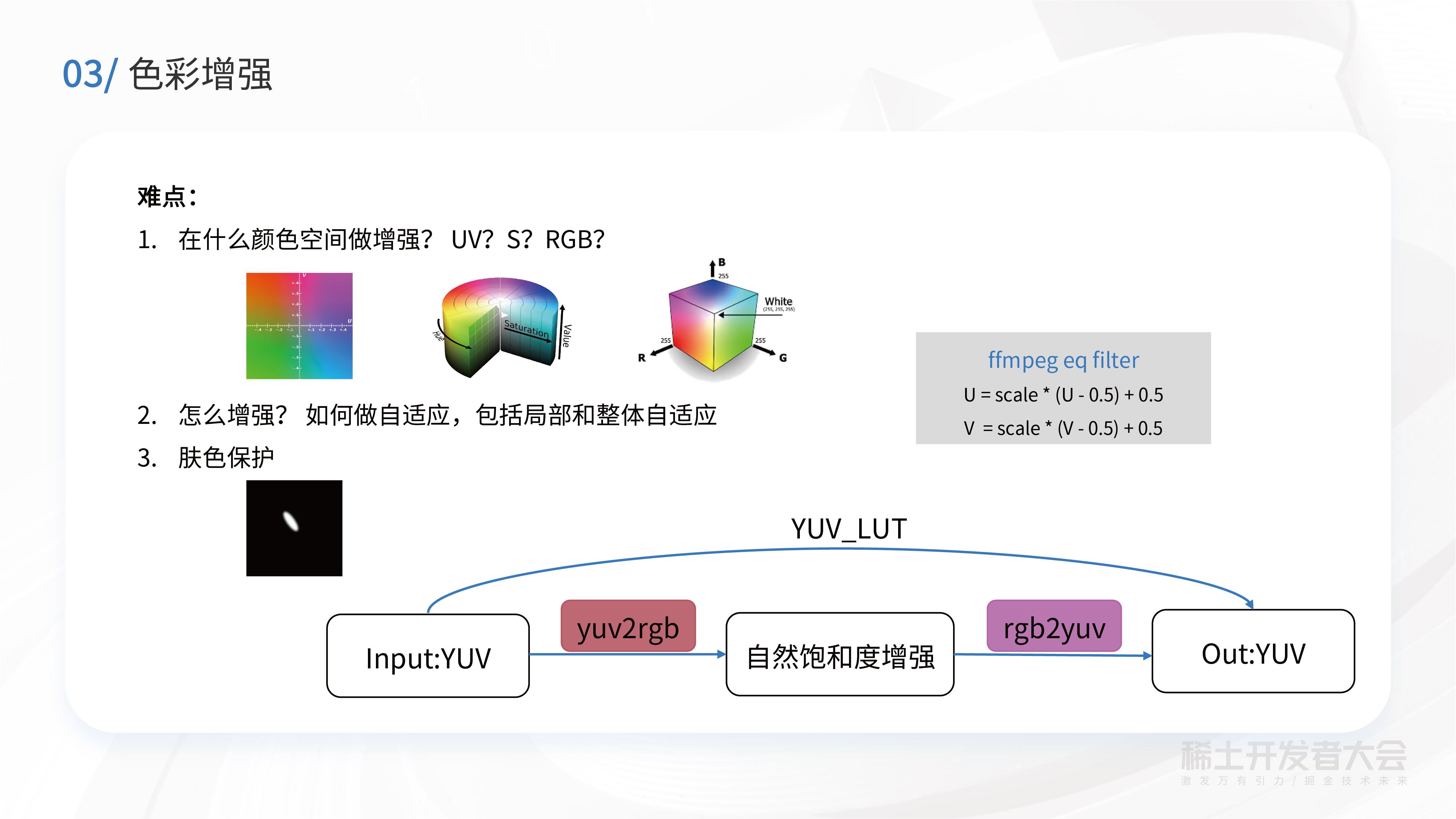
色彩增强存在哪些难点问题?具体如何做色彩增强?
像Ffmpeg里面有EQ filter,EQ filter会用UV通道去做色彩增强。而在我们的自研算法里,实际上是在RGB颜色空间去做增强,即会根据当前颜色点的饱和度,去做一些局部的自适应。同时,也会根据当前画面整体的情况,做一个整体的自适应。
在肤色保护这块,因为传统的色彩增强完之后,人脸区域会泛红,主观视觉上不自然。为了解决这一问题,我们采用了肤色保护的方法,对肤色区域做一个额外的保护。
这是一个色彩增强前跟增强后的效果对比。可以看到增强后的绿色的蔬菜、肉,整个的颜色看着会更饱满,对于美食类视频来讲更能够激发起观众的食欲。

对比度增强
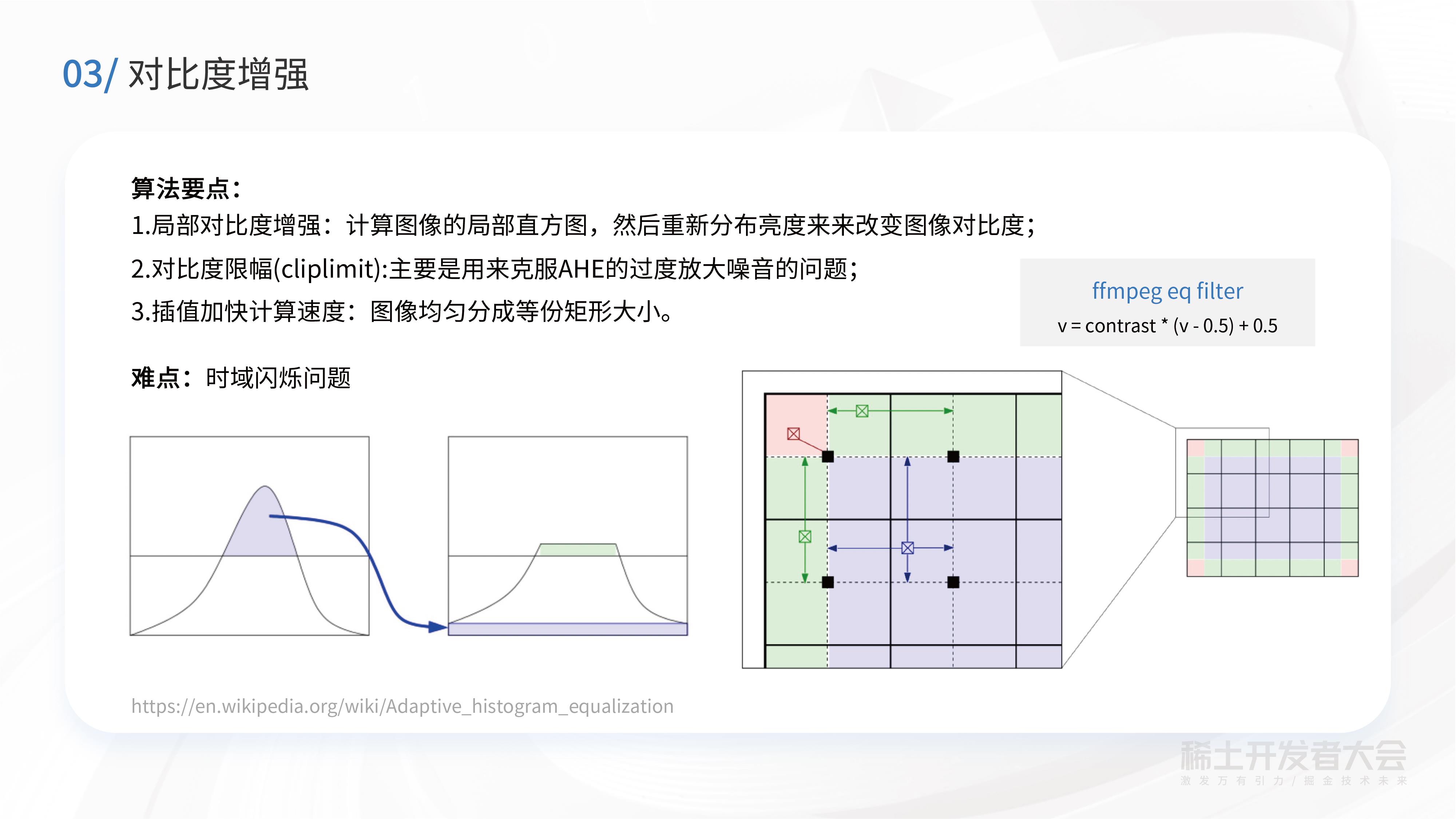
在对比度增强中,使用了经典的CLAHE算法,其思路是对一个视频帧做分块,通常分成8x8个分块,在每一块统计直方图。然后统计直方图的时候,对直方图做一个Clip,就是所谓的对比度受限的直方图均衡,这主要是克服过度放大噪声的问题。基于CLAHE的视频对比度增强其实有一个难点,就是时域闪烁问题。这在学术界也是一个较难的问题,到目前为止,还没有得到非常彻底的解决。
降噪
降噪在ffmpeg里面有很多算法,比如像BM3D、BM4D、 NLM,这些算法的去噪效果好,但是复杂度非常高,会导致速度慢成本高,可能还需要配合噪声估计模块来一起使用。
另外还有一些相对均衡的算法,速度比较快,但是效果不强。如果想要提升它的去噪强度,通常会引入一些伪影或细节丢失的问题。
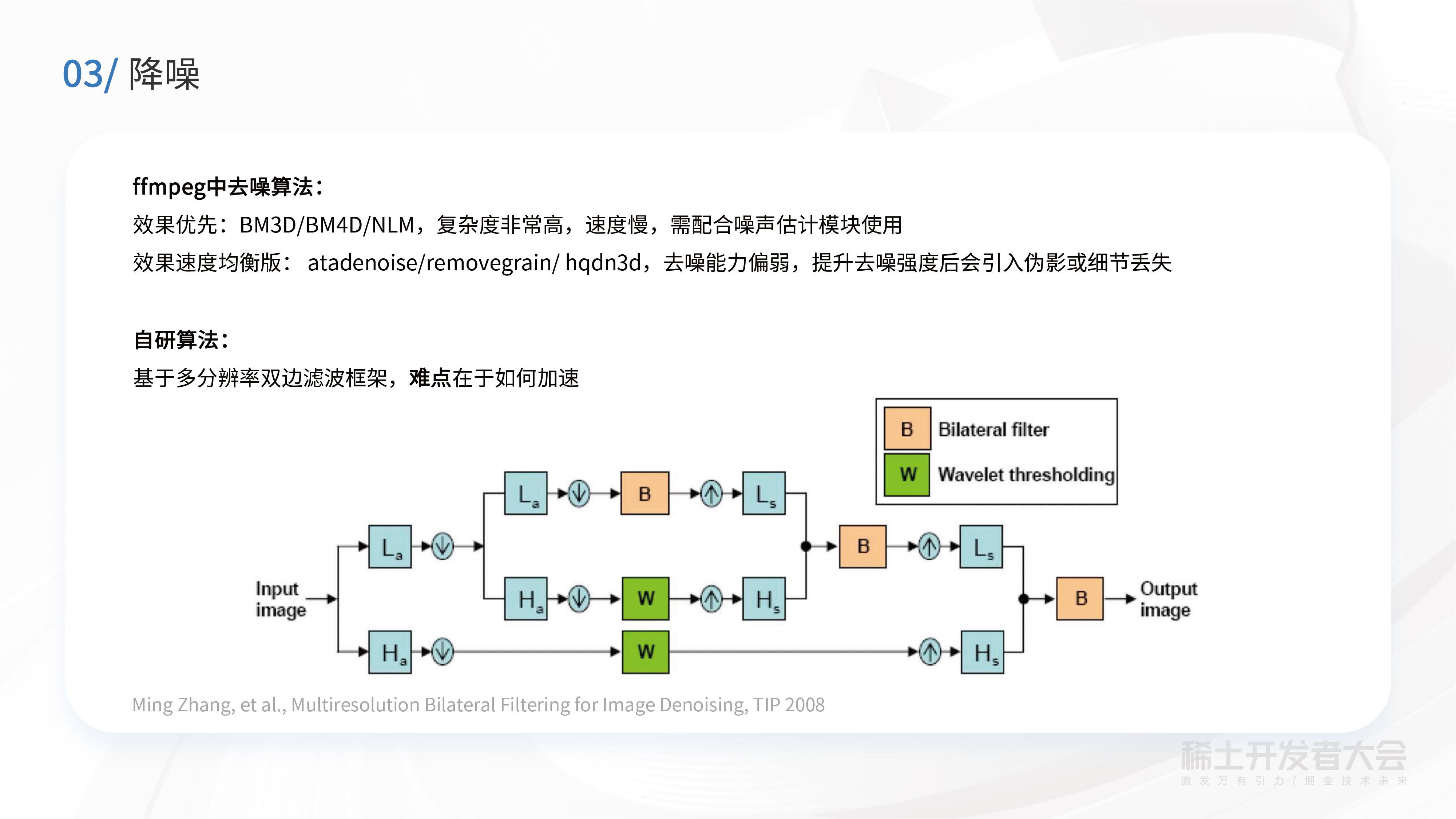
基于这些调研,我们自研的降噪算法采用基于多分辨率分解在上面做滤波框架。首先是对输入图像会做小波分解,得到高频跟低频信息。对于高频做软阈值处理。对于低频采用双边滤波降噪。经过这种滤波或者软阈值之后,再重新合成回去,就可以达到去噪目的。算法的核心难点在于如何去做加速,使得成本和运算速度能够满足转码要求,尤其是实时转码场景,对速度要求是非常高的。
加速
算法团队对于小波变换加速做了包括整形化很多的尝试,总是存在一些累积误差。所以我们最后采用了浮点型加速方式,用avx2浮点加速能够达到大概三倍的提升。
另外是双边滤波这部分的加速,传统的双边滤波基于邻域像素的操作。这种基于邻域的操作其实非常慢的。因此,我们采用了RBF这个快速算法,把二维的滤波分解成一维的,同时采用递归的方式去从左到右,从右到左,从上到下,从下到上,这样的一维操作,就可以实现类似于原始双边滤波效果。通过采用RBF这个快速算法,我们可以获得大概13倍的加速。此外我们还做了这种AVX2汇编的优化,这块能够额外加速十倍左右。

上图是SDR+的整体效果图,在经过SDR+的处理之后,画面整体的对比度、亮度、清晰度会有很大的提升,以上这些是针对视频增强做的一些工作。
CDEF去振铃
首先是CDEF去振铃,CDEF本身是源自于AV 1的一个技术,在CDEF处理之前,强边缘附近会有很多的毛刺和振铃。经过CDEF处理之后,画面中的噪声得到很大的剔除。
CDEF算法的核心步骤,其实是一个平滑滤波的过程,只不过它的平滑滤波的权重、偏差都做了一些特殊的处理。特别是它的滤波权重,跟当前像素点所在的8x8像素区域的主要方向是有关系,也就是图中左下角这里展示的,它会去做一个最优方向的一个搜索。搜索完了之后,根据主方向来确定它的这个滤波器抽头的方向和权重。此外,CDEF有两部分的权重,一个是主方向的WP,另一个是辅助方向WS。然后对于邻域点和当前点的灰度偏差做截断,这可以避免过平滑。

去压缩失真
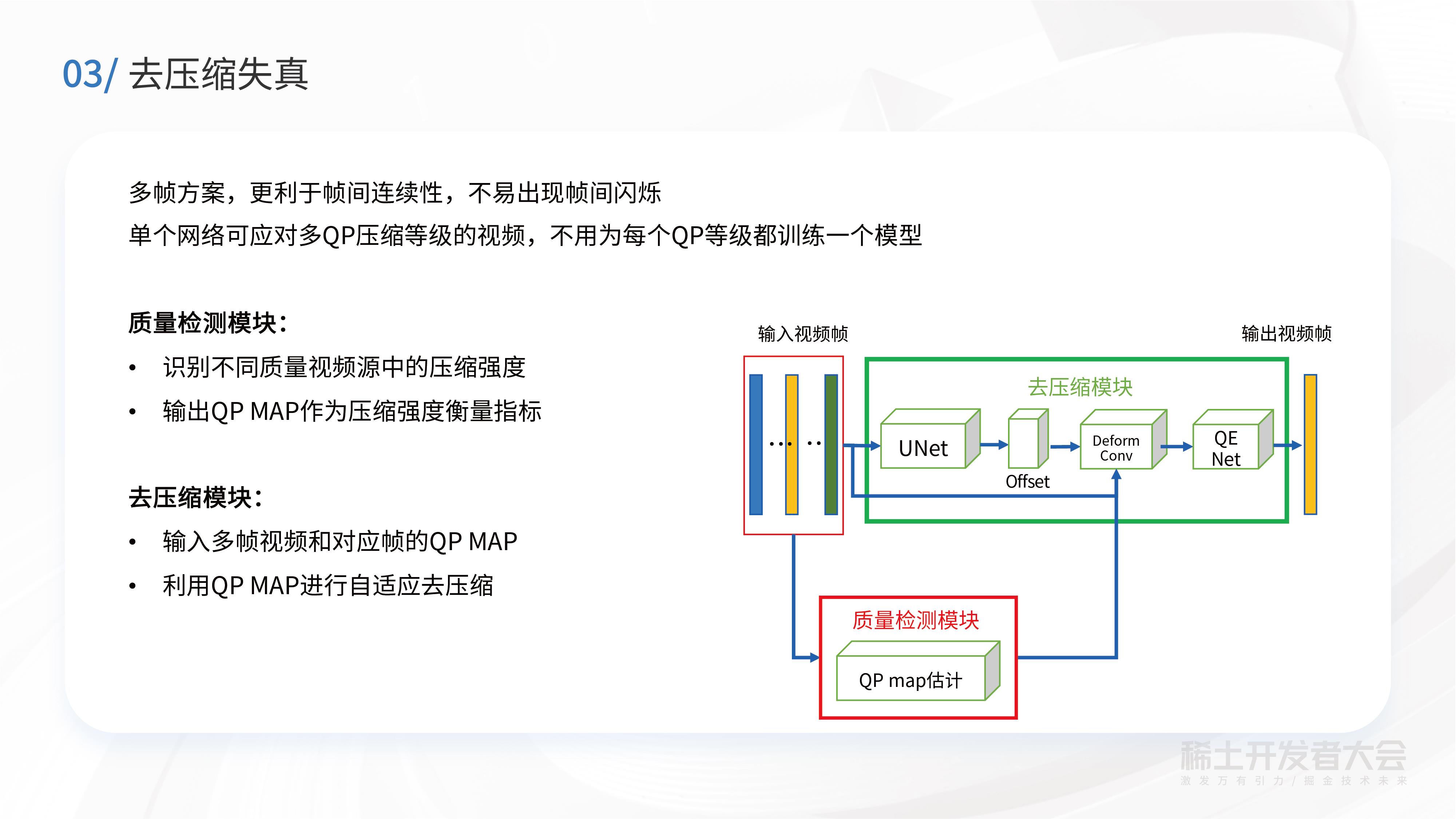
除了用CDEF基于传统的图像处理算法做去振铃之外,还做了基于深度学习的去压缩失真的算法。这个算法是基于多帧的方案,更利于帧间连续性,不易出现帧间闪烁。“窄带高清”算法分成两大块:一个是质量检测模块,一个是去压缩模块。质量检测模块可以识别不同质量视频源的压缩程度,然后输出QP MAP作为压缩强度衡量指标。另一个是去压缩模块,输入多帧视频和对应帧的QP MAP,利用QP MAP进行自适应去压缩。
极致修复生成
极致修复生成主要是针对画质比较差的场景,去除较强的压缩失真的同时,生成一些因压缩而丢失的细节。在极致修复生成研发中,有以下几个要点:一是构建训练数据(在训练数据构建时,参照了Real-ESRGAN的二阶退化思路);二是对比较敏感的人脸区域,保证人脸生成稳定性;三是做模型压缩时,使得模型计算量低的同时保持良好的效果;四是模型部署。

极致修复的场景实战
在六月份NBA决赛直播时,百视TV希望通过使用我们的窄带高清2.0修复生成技术,来提升他们赛事直播的质量。如中间这个截图所示,截图的上半部分是主播直接推过来的视频效果,下半部分是经过极致修复生成之后的效果。

可以看到修复之后,Youtube这几个字母边缘会更清晰、干净,不再毛躁。其他篮球场景相关的,比如球员身后的数字及球员的身体轮廓,也会变得特别清晰。另外也有些生成效果,比如地板上有生成一些纹理,使整体的赛事观感大大提升。
除了自研的算法,阿里云也有一些高校合作项目,字幕修复就是其中一个合作项目的成果。可以看图中右下角实际修复字幕例子。该字幕取自一个老片MV,上面一行是原始MV里的字幕,可以看到“话”字的言字旁几条横笔画会有一些粘连,此外文字边缘还有很多的噪声。下面一行是经过字幕修复之后的效果,能够看到会变得很干净、清晰。
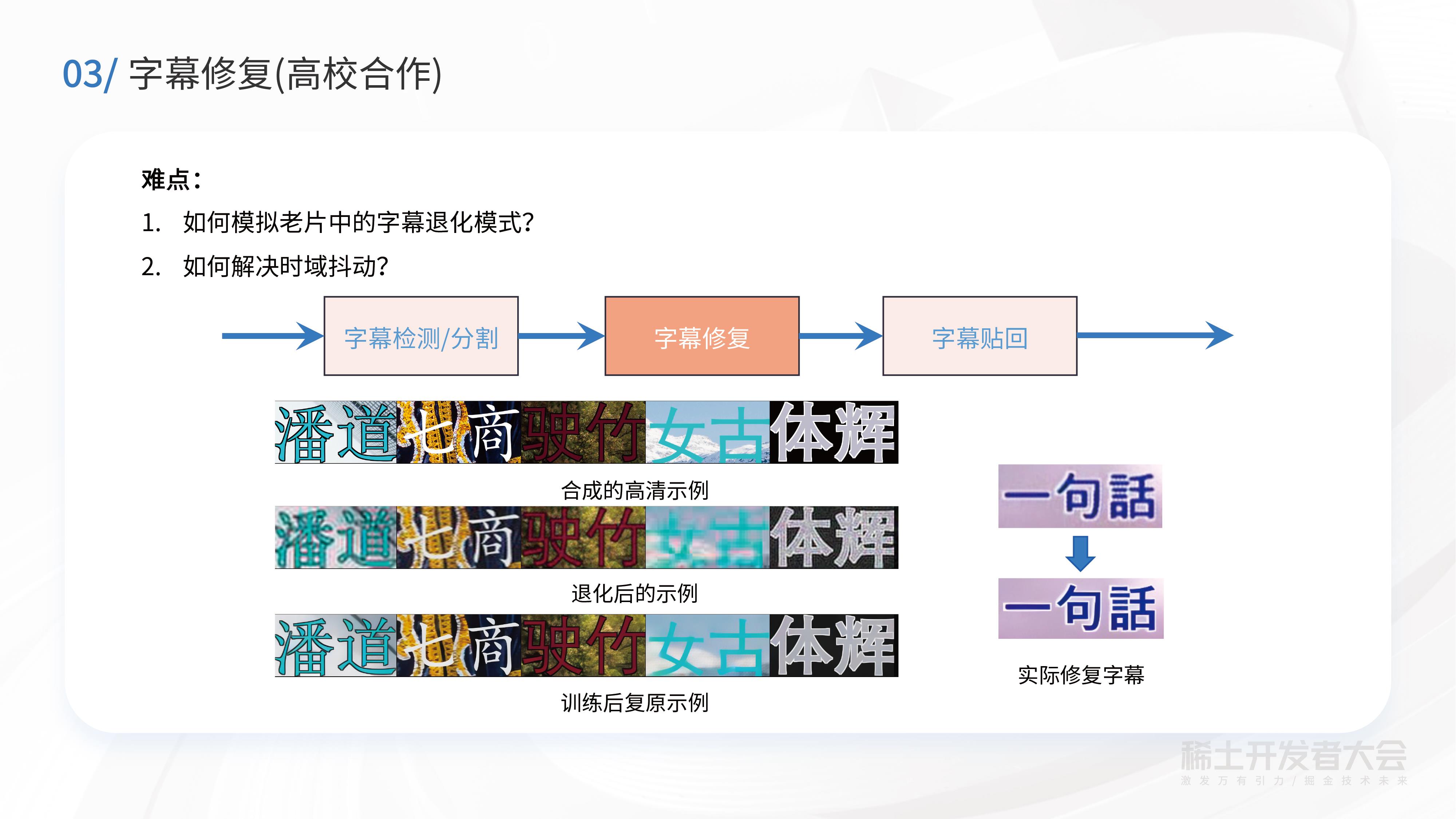
未来,窄带高清技术也将持续升级,通过算法能力进一步提升修复生成效果、降低码率和优化成本,通过打通前后端的处理,以及探索落地更多沉浸式场景,如:针对VR领域的窄带高清。与此同时,该项技术也将应用于更多的顶级赛事活动,在成本优化调和之上,实现视效体验的全新升级。
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。
以上是关于AI 视频云 VS 窄带高清,谁是视频时代的宠儿的主要内容,如果未能解决你的问题,请参考以下文章