高性能服务器架构思路——编码复杂度和通信
Posted 偶素浅小浅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能服务器架构思路——编码复杂度和通信相关的知识,希望对你有一定的参考价值。
版权声明:本文由韩伟原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/166
来源:腾云阁 https://www.qcloud.com/community
分布式编程复杂度
以前我们的代码,从上往下执行,每一行都会占用一定的CPU时间,这些代码的直接顺序,也是和编写的顺序基本一致,任何一行代码,都是唯一时刻的执行任务。当我们在编写分布式程序的时候,我们的代码将不再好像那些单进程、单线程的程序一样简单。我们要把同时运行的不同代码,在同一段代码中编写。就好像我们要把整个交响乐团的每个乐器的乐谱,全部写到一张纸上。为了解决这种编程的复杂度,业界发展出了多种编码形式。
在多进程的编码模型上,fork()函数可以说一个非常典型的代表。在一段代码中,fork()调用之后的部分,可能会被新的进程中执行。要区分当前代码的所在进程,要靠fork()的返回值变量。这种做法,等于把多个进程的代码都合并到一块,然后通过某些变量作为标志来划分。这样的写法,对于不同进程代码大部份相同的“同质进程”来说,还是比较方便的,最怕就是有大量的不同逻辑要用不同的进程来处理,这种情况下,我们就只能自己通过规范fork()附近的代码,来控制混乱的局面。比较典型的是把fork()附近的代码弄成一个类似分发器(dispatcher)的形式,把不同功能的代码放到不同的函数中,以fork之前的标记变量来决定如何调用。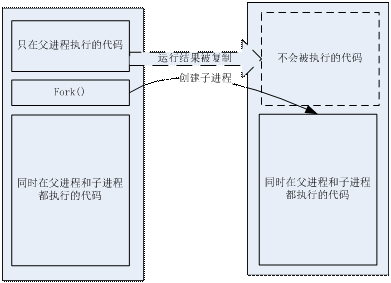
动态多进程的代码模式
在我们使用多线程的API时,情况就会好很多,我们可以用一个函数指针,或者一个带回调方法的对象,作为线程执行的主体,并且以句柄或者对象的形式来控制这些线程。作为开发人员,我们只要掌握了对线程的启动、停止等有限的几个API,就能很好的对并行的多线程进行控制。这对比多进程的fork()来说,从代码上看会更直观,只是我们必须要分清楚调用一个函数,和新建一个线程去调用一个函数,之间的差别:新建线程去调用函数,这个操作会很快的结束,并不会依序去执行那个函数,而是代表着,那个函数中的代码,可能和线程调用之后的代码,交替的执行。
由于多线程把“并行的任务”作为一个明确的编程概念定义了出来,以句柄、对象的形式封装好,那么我们自然会希望对多线程能更多复杂而细致的控制。因此出现了很多多线程相关的工具。比较典型的编程工具有线程池、线程安全容器、锁这三类。线程池提供给我们以“池”的形态,自动管理线程的能力:我们不需要自己去考虑怎么建立线程、回收线程,而是给线程池一个策略,然后输入需要执行的任务函数,线程池就会自动操作,比如它会维持一个同时运行线程数量,或者保持一定的空闲线程以节省创建、销毁线程的消耗。在多线程操作中,不像多进程在内存上完全是区分开的,所以可以访问同一份内存,也就是对堆里面的同一个变量进行读写,这就可能产生程序员所预计不到的情况(因为我们写程序只考虑代码是顺序执行的)。还有一些对象容器,比如哈希表和队列,如果被多个线程同时操作,可能还会因为内部数据对不上,造成严重的错误,所以很多人开发了一些可以被多个线程同时操作的容器,以及所谓“原子”操作的工具,以解决这样的问题。有些语言如Java,在语法层面,就提供了关键字来对某个变量进行“上锁”,以保障只有一个线程能操作它。多线程的编程中,很多并行任务,是有一定的阻塞顺序的,所以有各种各样的锁被发明出来,比如倒数锁、排队锁等等。java.concurrent库就是多线程工具的一个大集合,非常值得学习。然而,多线程的这些五花八门的武器,其实也是证明了多线程本身,是一种不太容易使用的顺手的技术,但是我们一下子还没有更好的替代方案罢了。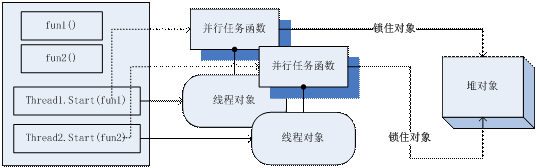
多线程的对象模型
在多线程的代码下,除了启动线程的地方,是和正常的执行顺序不同以外,其他的基本都还是比较近似单线程代码的。但是如果在异步并发的代码下,你会发现,代码一定要装入一个个“回调函数”里。这些回调函数,从代码的组织形态上,几乎完全无法看出来其预期的执行顺序,一般只能在运行的时候通过断点或者日志来分析。这就对代码阅读带来了极大的障碍。因此现在有越来越多的程序员关注“协程”这种技术:可以用类似同步的方法来写异步程序,而无需把代码塞到不同的回调函数里面。协程技术最大的特点,就是加入了一个叫yield的概念,这个关键字所在的代码行,是一个类似return的作用,但是又代表着后续某个时刻,程序会从yield的地方继续往下执行。这样就把那些需要回调的代码,从函数中得以解放出来,放到yield的后面了。在很多客户端游戏引擎中,我们写的代码都是由一个框架,以每秒30帧的速度在反复执行,为了让一些任务,可以分别放在各帧中运行,而不是一直阻塞导致“卡帧”,使用协程就是最自然和方便的了——Unity3D就自带了协程的支持。
在多线程同步程序中,我们的函数调用栈就代表了一系列同属一个线程的处理。但是在单线程的异步回调的编程模式下,我们的一个回调函数是无法简单的知道,是在处理哪一个请求的序列中。所以我们往往需要自己写代码去维持这样的状态,最常见的做法是,每个并发任务启动的时候,就产生一个序列号(seqid),然后在所有的对这个并发任务处理的回调函数中,都传入这个seqid参数,这样每个回调函数,都可以通过这个参数,知道自己在处理哪个任务。如果有些不同的回调函数,希望交换数据,比如A函数的处理结果希望B函数能得到,还可以用seqid作为key把结果存放到一个公共的哈希表容器中,这样B函数根据传入的seqid就能去哈希表中获得A函数存入的结果了,这样的一份数据我们往往叫做“会话”。如果我们使用协程,那么这些会话可能都不需要自己来维持了,因为协程中的栈代表了会话容器,当执行序列切换到某个协程中的时候,栈上的局部变量正是之前的处理过程的内容结果。
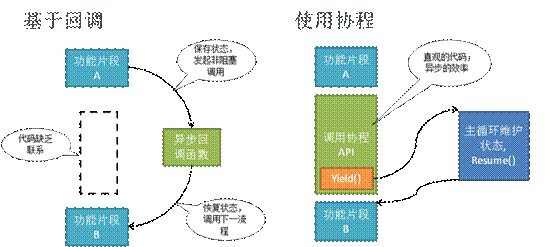
协程的代码特征
为了解决异步编程的回调这种复杂的操作,业界还发明了很多其他的手段,比如lamda表达式、闭包、promise模型等等,这些都是希望我们,能从代码的表面组织上,把在多个不同时间段上运行的代码,以业务逻辑的形式组织到一起。
最后我想说说函数式编程,在多线程的模型下,并行代码带来最大的复杂性,就是对堆内存的同时操作。所以我们才弄出来锁的机制,以及一大批对付死锁的策略。而函数式编程,由于根本不使用堆内存,所以就无需处理什么锁,反而让整个事情变得非常简单。唯一需要改变的,就是我们习惯于把状态放到堆里面的编程思路。函数式编程的语言,比如LISP或者Erlang,其核心数据结果是链表——一种可以表示任何数据结构的结构。我们可以把所有的状态,都放到链表这个数据列车中,然后让一个个函数去处理这串数据,这样同样也可以传递程序的状态。这是一种用栈来代替堆的编程思路,在多线程并发的环境下,非常的有价值。
分布式程序的编写,一直都伴随着大量的复杂性,影响我们对代码的阅读和维护,所以我们才有各种各样的技术和概念,试图简化这种复杂性。也许我们无法找到任何一个通用的解决方案,但是我们可以通过理解各种方案的目标,来选择最适合我们的场景:
-
动态多进程fork——同质的并行任务
-
多线程——能明确划的逻辑复杂的并行任务
-
异步并发回调——对性能要求高,但中间会被阻塞的处理较少的并行任务
-
协程——以同步的写法编写并发的任务,但是不合适发起复杂的动态并行操作。
-
函数式编程——以数据流为模型的并行处理任务
分布式数据通信
分布式的编程中,对于CPU时间片的切分本身不是难点,最困难的地方在于并行的多个代码片段,如何进行通信。因为任何一个代码段,都不可能完全单独的运作,都需要和其他代码产生一定的依赖。在动态多进程中,我们往往只能通过父进程的内存提供共享的初始数据,运行中则只能通过操作系统间的通讯方式了:Socket、信号、共享内存、管道等等。无论那种做法,这些都带来了一堆复杂的编码。这些方式大部分都类似于文件操作:一个进程写入、另外一个进程读出。所以很多人设计了一种叫“消息队列”的模型,提供“放入”消息和“取出”消息的接口,底层则是可以用Socket、共享内存、甚至是文件来实现。这种做法几乎能够处理任何状况下的数据通讯,而且有些还能保存消息。但是缺点是每个通信消息,都必须经过编码、解码、收包、发包这些过程,对处理延迟有一定的消耗。
如果我们在多线程中进行通信,那么我们可以直接对某个堆里面的变量直接进行读写,这样的性能是最高的,使用也非常方便。但是缺点是可能出现几个线程同时使用变量,产生了不可预期的结果,为了对付这个问题,我们设计了对变量的“锁”机制,而如何使用锁又成为另外一个问题,因为可能出现所谓的“死锁”问题。所以我们一般会用一些“线程安全”的容器,用来作为多线程间通讯的方案。为了协调多个线程之间的执行顺序,还可以使用很多种类型的“工具锁”。
在单线程异步并发的情况下,多个会话间的通信,也是可以通过直接对变量进行读写操作,而且不会出现“锁”的问题,因为本质上每个时刻都只有一个段代码会操作这个变量。然而,我们还是需要对这些变量进行一定规划和整理,否则各种指针或全局变量在代码中散布,也是很出现BUG的。所以我们一般会把“会话”的概念变成一个数据容器,每段代码都可以把这个会话容器作为一个“收件箱”,其他的并发任务如果需要在这个任务中通讯,就把数据放入这个“收件箱”即可。在WEB开发领域,和cookie对应的服务器端Session机制,就是这种概念的典型实现。
以上是关于高性能服务器架构思路——编码复杂度和通信的主要内容,如果未能解决你的问题,请参考以下文章