Python读取.xlsx指定行列
Posted L_Jane_H
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python读取.xlsx指定行列相关的知识,希望对你有一定的参考价值。
本文以Python3.9.1读取data.xlsx中包含的西瓜数据集3.0数据为例,数据集如下:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.46 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 0.481 | 0.149 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.666 | 0.091 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0.243 | 0.267 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0.245 | 0.057 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0.343 | 0.099 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.639 | 0.161 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0.657 | 0.198 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.36 | 0.37 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.719 | 0.103 | 否 |
代码段:
一、读取工作表内容(.xlsx转化为DataFrame)
- 导入pandas库,读取工作表数据
import pandas as pd
df = pd.read_excel(r'E:\\Aownplan\\data.xlsx')#默认读取工作簿中第一个工作表,默认第一行为表头
备注:r是为了读取文件路径中\\字符,防止转义。
此处利用pandas库的 read_excel 函数读取文件,获取到的函数返回值类型为DataFrame,后续所有的操作均是基于DataFrame的数据操作方法进行。
二、获取指定行指定列数据(DataFrame转化为numpy.ndarray)
- 获取整个工作表数据
data=df.values#获取整个工作表数据
print("读取整个工作表的数据:\\n0".format(data))
- 获取某一行数据
data=df.iloc[0].values#0表示第一行,不包含表头
print("读取指定行的数据:\\n0".format(data))
- 获取多行数据
data=df.head().values#head()默认读取前5行数据(不包含表头)
print("获取工作表前5行数据:\\n0".format(data))
data=df.iloc[[1,2]].values#读取指定多行,在iloc[]里面嵌套列表指定行数
print("读取指定多行的数据:\\n0".format(data))
data=df.sample(3).values#读取df中随机3行数据(3个样本)
print("获取随机多行数据:\\n0".format(data))
- 获取指定单元格数据
data=df.iloc[1,2]#读取索引为[1, 2]的值,这里不需要嵌套列表
print("读取指定某行某列(单元格)的数据:\\n0".format(data))
- 获取指定列数据
print("输出值\\n",df['含糖率'].values)
- 获取指定多列数据
data=df.loc[:,['敲声','纹理']].values#读所有行的敲声以及纹理列的值,这里需要嵌套列表
print("读取指定列的数据:\\n0".format(data))
- 获取指定多行多列数据
data=df.loc[[1,2],['密度','含糖率']].values#读取第一行第二行的密度以及含糖率列的值,这里需要嵌套列表
print("读取指定多行多列的数据:\\n0".format(data))
- 获取行号和列标题
print("输出行号列表",df.index.values)
print("输出列标题",df.columns.values)
三、数据处理(numpy.ndarray转化为list/set/dict)
(1) 转化为列表list
以上通过.values方法获取到的data值,均为二维值数组(numpy.ndarray)类型,在使用时如果需要转换为列表类型,可使用.tolist()方法,如:
data=df.values.tolist()
此时的输出为:

此时的data为list类型,其中每一行数据均为一个列表,多个列表合并为一个二维列表,此时要获取指定行(m)的数据,使用 data[m],获取指定单元格数据,使用data[m][n]。
(2) 转化为集合set
在分析时,若想获取某一列的数据集合,则可以先提取该列数据,然后使用set()函数将其转化为集合即可,如当前为获取敲声的类型,进行如下操作:
data=df['敲声'].values
print(set(data))
此时的输出:
'清脆', '浊响', '沉闷'
获取除编号,密度,含糖率外所有列的集合:
titles = df.columns.values
for title in titles:
if title != '编号' and title != '密度' and title != '含糖率':
key = df[title].values
values = set(key)
print(title,':',values)
输出:
色泽 : '乌黑', '青绿', '浅白'
根蒂 : '蜷缩', '稍蜷', '硬挺'
敲声 : '清脆', '浊响', '沉闷'
纹理 : '清晰', '稍糊', '模糊'
脐部 : '平坦', '稍凹', '凹陷'
触感 : '硬滑', '软粘'
好瓜 : '是', '否'
(3) 转化为字典dict
如果需要读取某一行的数据为字典,可进行如下操作:
data=df.iloc[0].values#获取某行数据
title=df.columns.values#获取列标题
a=zip(title,data)#将其压缩为一个元组
print(dict(a))#转化为字典
输出:
'编号': 1, '色泽': '青绿', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰', '脐部': '凹陷', '触感': '硬滑', '密度': 0.697, '含糖率': 0.46, '好瓜': '是'
获取除编号,密度,含糖率外所有列的字典:
titles = df.columns.values
adict=dict()
for title in titles:
if title != '编号' and title != '密度' and title != '含糖率':
key = df[title].values
adict[title]=set(key)
print(adict)
输出:
'色泽': '乌黑', '青绿', '浅白', '根蒂': '蜷缩', '稍蜷', '硬挺', '敲声': '清脆', '浊响', '沉闷', '纹理': '清晰', '稍糊', '模糊', '脐部': '平坦', '稍凹', '凹陷', '触感': '硬滑', '软粘', '好瓜': '是', '否'
参考文章:
[1]. Python利用pandas处理Excel数据的应用
利用Python合并指定行列excel文件
效果:
将n多个xlsx文件所有xlsx都取Sheet1表格 抽取指定得行列 并排列到新的Sheet1表格当中
如 表格1内容如下
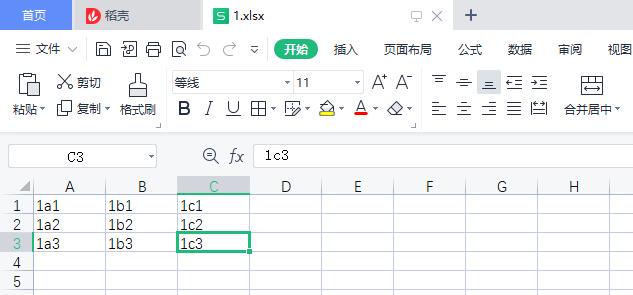
表格2内容如下
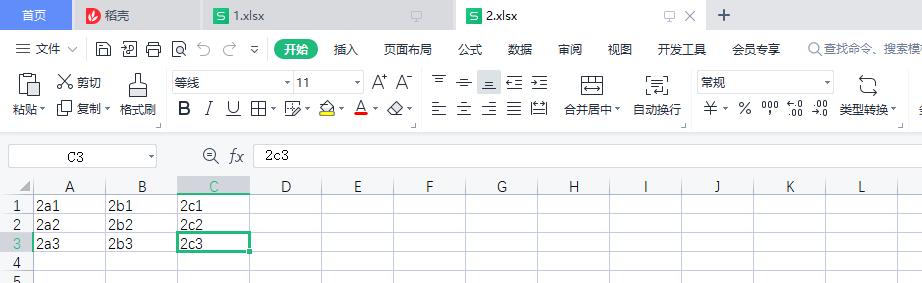
表格数量不限制。都是要取
期望拿到坐标b2-c3的所有数据并放入表格0当中

参数 如果不是从b2 到c3可以自己配置下这个开始坐标和结束坐标坐标概念如下。
# 开始坐标点
start = [1, 1]
# 结束坐标点
end = [2, 2]
# 1,1 1,2 1,3 1,4
# 1,1 1a1 1b1 1c1
# 1,2 1a2 1b2 1c2
# 1,3 1a3 1b3 1c3
直接贴代码
import os
# 读写2007 excel
import openpyxl
def read07Excel(path, outputFiles):
# 选中开始
# 开始坐标点
start = [1, 1]
# 结束坐标点
end = [2, 2]
# 1,1 1,2 1,3 1,4
# 1,1 1a1 1b1 1c1
# 1,2 1a2 1b2 1c2
# 1,3 1a3 1b3 1c3
wb = openpyxl.load_workbook(path)
outWb = openpyxl.load_workbook(outputFiles)
sheet = wb['Sheet1']
outSheet = outWb['Sheet1']
rows = sheet.max_row
columns = sheet.max_column
outSheetMaxRows = outSheet.max_row
if (outSheetMaxRows == 1):
outSheetMaxRows = 0;
for i in range(rows):
if (i < start[0] or i > end[0]):
continue
for j in range(columns):
if (j < start[1] or j > end[1]):
continue
cellvalue = sheet.cell(row=i + 1, column=j + 1).value
outSheet.cell(row=i + 1 - start[0] + outSheetMaxRows, column=j + 1 - start[1], value=cellvalue)
print(cellvalue, "\\t", end="")
print()
outWb.save(outputFiles)
def main():
outputFiles = r"fileslist\\0.xlsx"
for root, dirs, files in os.walk("fileslist"):
for file in files:
fileName = os.path.join(root, file)
if (fileName.endswith(outputFiles)):
continue
print("当前表格:" + fileName)
read07Excel(fileName, outputFiles)
print()
pass
if __name__ == '__main__':
main()
如何使用
1、在main.py同级目录下新建fileslist文件目录

在目录中新建一个空白的xlsx 命名为 0.xlsx 这个是最后要导出的文件夹
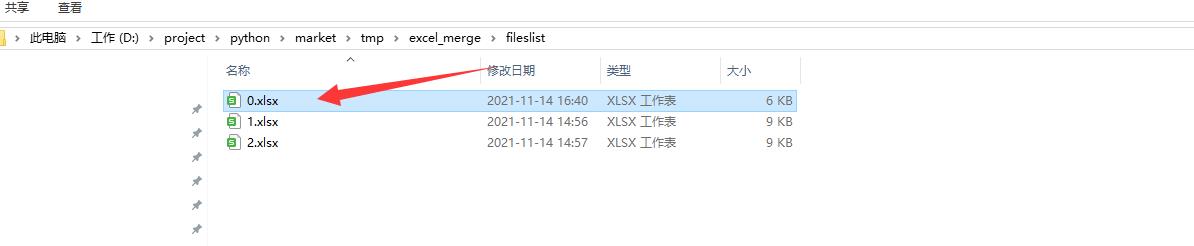
将其他要处理的数据全部复制进来。如1.xlsx,2.xlsx(名字不做限制,这里面所有的文件都会被遍历然后写进0.xlsx)
2、安装 python
下载地址:Python Releases for Windows | Python.org
下载后安装即可
安装成功 将安装目录的路径配置到环境变量当中
在 Windows 设置环境变量
在环境变量中添加Python目录:
在命令提示框中(cmd) : 输入
path=%path%;C:\\Python 按下 Enter。
注意: C:\\Python 是Python的安装目录。
也可以通过以下方式设置:
- 右键点击"计算机",然后点击"属性"
- 然后点击"高级系统设置"
- 选择"系统变量"窗口下面的"Path",双击即可!
- 然后在"Path"行,添加python安装路径即可(我的D:\\Python32),所以在后面,添加该路径即可。 ps:记住,路径直接用分号";"隔开!
- 最后设置成功以后,在cmd命令行,输入命令"python",就可以有相关显示。

3、安装 openpyxl
直接cmd执行
pip install openpyxl4 执行脚本
python main.py以上是关于Python读取.xlsx指定行列的主要内容,如果未能解决你的问题,请参考以下文章