Linux应用编程-音频应用编程-语音转文字项目
Posted AゞOctopus๊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux应用编程-音频应用编程-语音转文字项目相关的知识,希望对你有一定的参考价值。
文章目录
前言
本篇分享:
Linux应用编程之音频编程,使用户可以录制一段音频并进行识别(语音转文字)
环境介绍:
系统:Ubuntu 22.04
声卡:电脑自带
Linux语音识别
实现目标 :用户可以录制一段音频并进行识别(语音转文字)
知识点 : C语言、文件IO、信号、多线程、alsa-lib 库、libcurl库、API调用
alsa-lib简介:
alsa-lib是一套 Linux 应用层的 C 语言函数库,为音频应用程序开发提供了一套统一、标准的接口,应用程序只需调用这一套 API 即可完成对底层声卡设备的操控,譬如播放与录音。
用户空间的alsa-lib对应用程序提供了统一的API 接口,这样可以隐藏驱动层的实现细节,简化了应用 程序的实现难度、无需应用程序开发人员直接去读写音频设备节点。所以,主要就是学习alsa-lib库函数的使用、如何基于alsa-lib库函数开发音频应用程序。
alsa-lib官方说明文档:https://www.alsa-project.org/alsa-doc/alsa-lib/
安装alsa-lib库:
在ubuntu系统上安装alsa-lib库方法:
sudo apt-get install libasound2-dev
libcurl库简介:
libcurl是一个跨平台的网络协议库,支持http, https, ftp, gopher, telnet, dict, file, 和ldap 协议。libcurl同样支持HTTPS证书授权,HTTP POST, HTTP PUT, FTP 上传, HTTP基本表单上传,代理,cookies,和用户认证。
官网地址:http://curl.haxx.se/
安装libcurl库:
在ubuntu系统上安装alsa-lib库方法:
sudo apt-get install libcurl4-openssl-dev
API调用
该程序使用的是百度语音识别API
注册后领取免费额度及创建中文普通话应用(创建前先领取免费额度(180 天免费额度,可调用约 5 万次左右) )
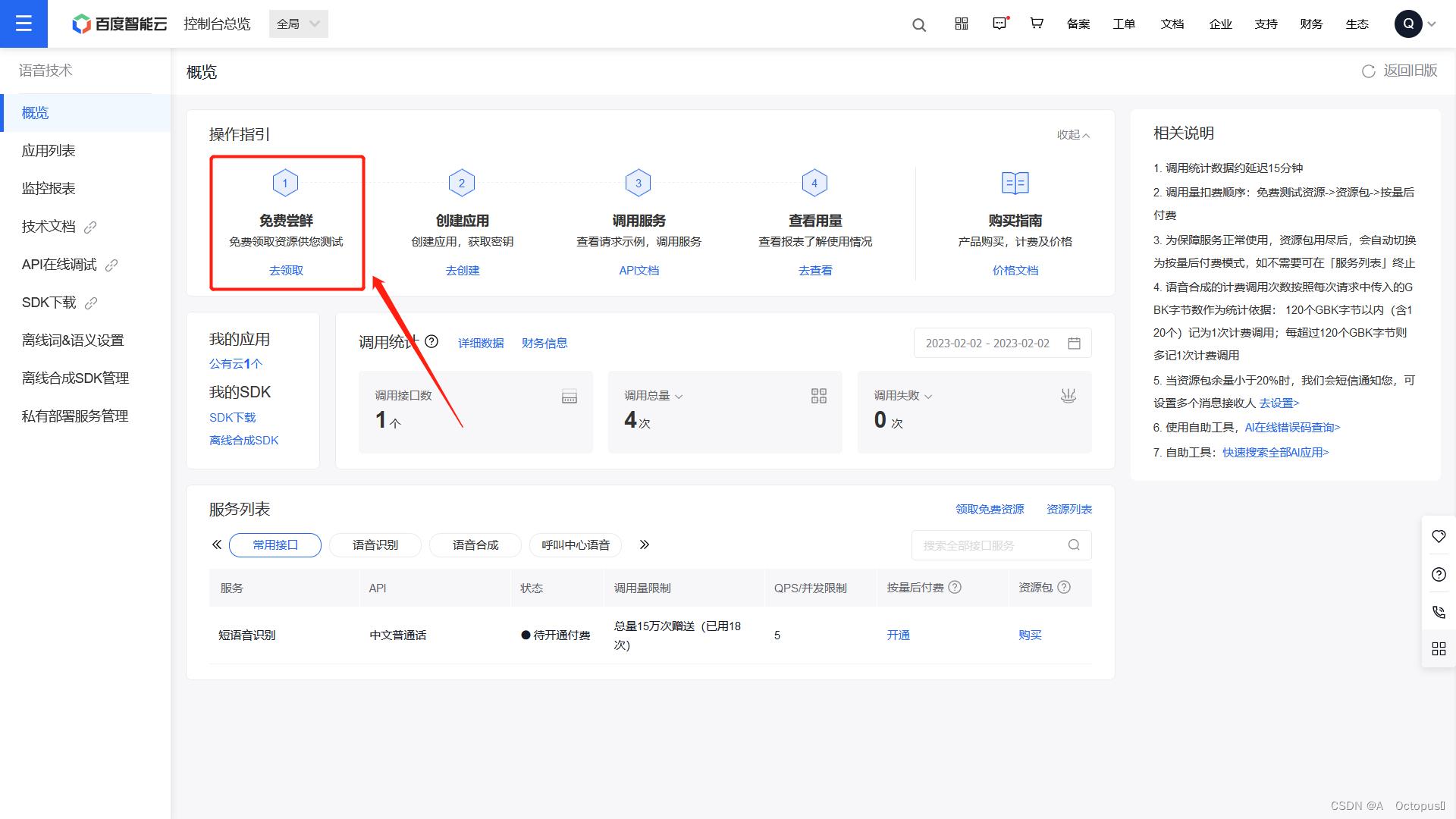
创建好应用后,可以得到API key和Secret Key(填写到程序中的相应位置)
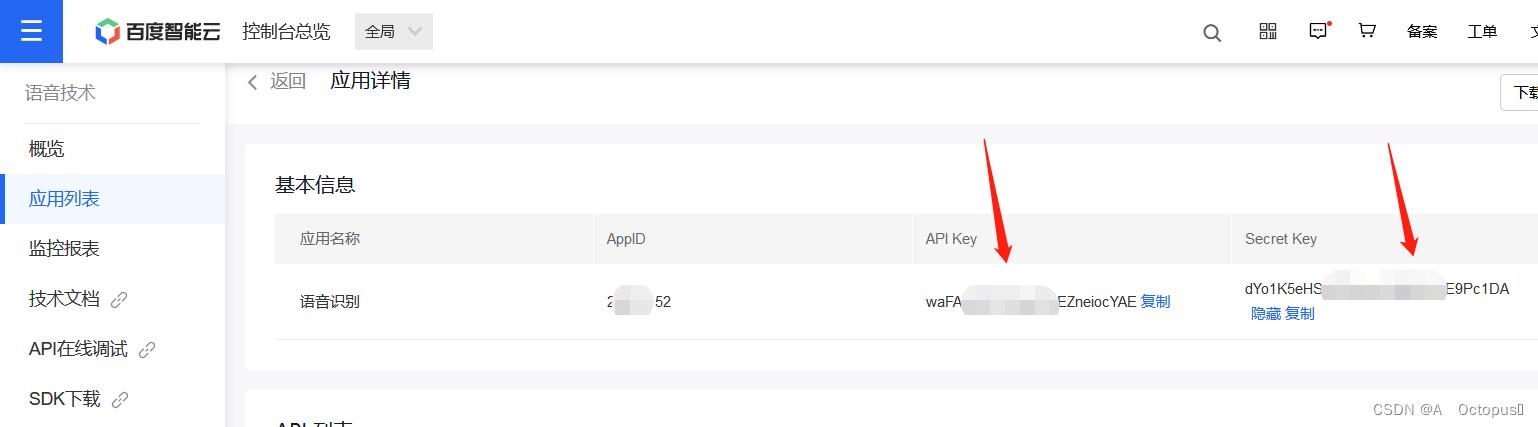
调用API相关说明可在图中所示位置查阅,Demo代码中有多种语言的调用示例可以参考,使用C语言的话也可以直接在本项目程序上面直接更改(项目源代码在最下方):
API相关c文件中 需要修改的有asrmain.c和相应的头文件:
asrmain.c的fill_config函数中(该函数我已修改,原本无file参数,根据实际情况使用),需要修改的有:音频文件格式,API Key以及Secret Key:
RETURN_CODE fill_config(struct asr_config *config,char *file)
// 填写网页上申请的appkey 如 g_api_key="g8eBUMSokVB1BHGmgxxxxxx"
char api_key[] = "填写网页上申请的API key";
// 填写网页上申请的APP SECRET 如 $secretKey="94dc99566550d87f8fa8ece112xxxxx"
char secret_key[] = "填写网页上申请的Secret Key";
// 需要识别的文件
char *filename = NULL;
filename = file;
// 文件后缀仅支持 pcm/wav/amr 格式,极速版额外支持m4a 格式
char format[] = "pcm";
char *url = "http://vop.baidu.com/server_api"; // 可改为https
// 1537 表示识别普通话,使用输入法模型。其它语种参见文档
int dev_pid = 1537;
char *scope = "audio_voice_assistant_get"; // # 有此scope表示有asr能力,没有请在网页里勾选,非常旧的应用可能没有
…………
结合音频录制的程序使用的话,还需要删除示例中的main函数,run函数中的相关初始化以及API调用函数需要根据实际情况重新调整调用位置。本项目总体按照:获取token(在程序开始时获取一次即可,根据官网可知获取的token有效期为30天,重新获取token则之前获取的token失效)->调用API->得到返回结果->解析结果->反馈给用户。
录音
实现音频录制分为以下步骤:打开声卡设备->设置硬件参数->读写数据
相关概念
样本长度(Sample)
- 样本长度,样本是记录音频数据最基本的单元,样本长度就是采样位数,也称为位深度(Bit Depth、Sample Size、 Sample Width)。是指计算机在采集和播放声音文件时,所使用数字声音信号的二进制位数,或者说每个采样样本所包含的位数(计算机对每个通道采样量化时数字比特位数),通常有 8bit、16bit、24bit 等。
声道数(channel)
- 分为
单声道(Mono)和双声道/立体声(Stereo)。1 表示单声道、2 表示立体声。
帧(frame)
- 帧记录了一个声音单元,其长度为样本长度与声道数的乘积,一段音频数据就是由若干帧组成的。把所有声道中的数据加在一起叫做一帧,对于单声道:
一帧 = 样本长度 * 1;双声道:一帧 = 样本长度 * 2。 - 对于本程序中,样本长度为16bit 的单声道来说,一帧的大小等于:16 * 1 / 8 = 2 个字节。
周期(period)
- 周期是音频设备处理(读、写)数据的单位,换句话说,也就是音频设备读写数据的单位是周期,每一次读或写一个周期的数据,一个周期包含若干个帧;譬如周期的大小为 1024 帧,则表示音频设备进行一次读或写操作的数据量大小为 1024 帧。
- 一个周期其实就是两次硬件中断之间的帧数,音频设备每处理(读或写)完一个周期的数据就会产生一个中断,所以两个中断之间相差一个周期,即每一次读或写一个周期的数据。
- 对于本程序中,
一周期的大小 = 一周期帧数 * 一帧大小=一周期帧数 * (样本长度 * 声道数 / 字节长度)= 1024 * (16 * 1 / 8) = 2048个字节。
采样率(Sample rate)
- 也叫采样频率,是指
每秒钟采样次数,该次数是对于帧而言。
打开声卡设备
函数:
函数原型:
int snd_pcm_open(snd_pcm_t **pcmp, const char *name, snd_pcm_stream_t stream, int mode)
参数:
pcmp -- 表示一个 PCM 设备,snd_pcm_open 函数会打开参数 name 所指定的设备,实例化 snd_pcm_t 对象,并将对象的指针通过 pcmp 返回出来。
name -- 参数 name 指定 PCM 设备的名字。alsa-lib 库函数中使用逻辑设备名而不是设备文件名,命名方式为"hw:i,j",i 表示声卡的卡号,j 则表示这块声卡上的设备号
SND_PCM_STREAM_CAPTURE:表示从设备采集音频数据。
stream --SND_PCM_STREAM_PLAYBACK表示播放,SND_PCM_STREAM_CAPTURE则表示采集。
mode -- 最后一个参数 mode 指定了 open 模式,通常情况下将其设置为0,表示默认打开模式,默认情况下使用阻塞方式打开设备;
作用:
打开音频采集卡硬件。
代码:
/*打开音频采集卡硬件,并判断硬件是否打开成功,若打开失败则打印出错误提示*/
// SND_PCM_STREAM_PLAYBACK 输出流
// SND_PCM_STREAM_CAPTURE 输入流
if ((err = snd_pcm_open(&capture_handle, "hw:0", SND_PCM_STREAM_CAPTURE, 0)) < 0)
printf("无法打开音频设备: %s (%s)\\n","hw:0", snd_strerror(err));
exit(1);
printf("音频接口打开成功.\\n");
设置硬件参数
设置硬件参数再细分的话有:初始化硬件参数结构对象,设置访问类型,设置数据编码格式,设置采样频率,设置声道,加载配置好的硬件参数 。
初始化硬件参数结构对象
函数:
函数原型:
int snd_pcm_hw_params_malloc(snd_pcm_hw_params_t **hwparams);
参数:
hwparams -- snd_pcm_hw_params_t 对象。
作用:
实例化snd_pcm_hw_params_t对象。
函数原型:
int snd_pcm_hw_params_any(snd_pcm_t *pcm_handle,snd_pcm_hw_params_t *hwparams);
参数:
pcm_handle -- PCM 设备的句柄。
hwparams -- 传入 snd_pcm_hw_params_t 对象的指针。
作用:
调用该函数会使用 PCM 设备当前的配置参数去初始化 snd_pcm_hw_params_t 对象。
代码:
/*对象声明*/
snd_pcm_hw_params_t *hw_params;
/*分配硬件参数结构对象,并判断是否分配成功*/
if ((err = snd_pcm_hw_params_malloc(&hw_params)) < 0)
printf("无法分配硬件参数结构 (%s)\\n", snd_strerror(err));
exit(1);
printf("硬件参数结构已分配成功.\\n");
/*按照默认设置对硬件对象进行设置,并判断是否设置成功*/
if ((err = snd_pcm_hw_params_any(capture_handle, hw_params)) < 0)
printf("无法初始化硬件参数结构 (%s)\\n", snd_strerror(err));
exit(1);
printf("硬件参数结构初始化成功.\\n");
参数:
hw_params:此结构包含有关硬件的信息,用于指定PCM流的配置
设置访问类型
函数:
函数原型:
int snd_pcm_hw_params_set_access(snd_pcm_t *pcm,
snd_pcm_hw_params_t * params,
snd_pcm_access_t access
)
参数:
access -- 指定设备的访问类型,是一个 snd_pcm_access_t 类型常量,这是一个枚举类型。
作用:
调用 snd_pcm_hw_params_set_access 设置访问类型。
代码:
/*
设置数据为交叉模式,并判断是否设置成功
interleaved/non interleaved:交叉/非交叉模式。
表示在多声道数据传输的过程中是采样交叉的模式还是非交叉的模式。
对多声道数据,如果采样交叉模式,使用一块buffer即可,其中各声道的数据交叉传输;
如果使用非交叉模式,需要为各声道分别分配一个buffer,各声道数据分别传输。
*/
if ((err = snd_pcm_hw_params_set_access(capture_handle, hw_params, SND_PCM_ACCESS_RW_INTERLEAVED)) < 0)
printf("无法设置访问类型(%s)\\n", snd_strerror(err));
exit(1);
if(!start_flag) printf("访问类型设置成功.\\n");
参数:
SND_PCM_ACCESS_RW_INTERLEAVED:访问类型设置为交错访问模式,通过
snd_pcm_readi/snd_pcm_writei 对 PCM 设备进行读/写操作。
设置数据编码格式
函数:
函数原型:
int snd_pcm_hw_params_set_format(snd_pcm_t *pcm,
snd_pcm_hw_params_t *params,
snd_pcm_format_t format
)
参数:
format -- 指定数据格式,该参数是一个 snd_pcm_format_t 类型常量,这是一个枚举类型。
作用:
调用 snd_pcm_hw_params_set_format()函数设置 PCM 设备的数据格式。
代码:
/*设置数据编码格式,并判断是否设置成功*/
if ((err = snd_pcm_hw_params_set_format(capture_handle, hw_params, format)) < 0)
printf("无法设置格式 (%s)\\n", snd_strerror(err));
exit(1);
printf("PCM数据格式设置成功.\\n");
参数:
format:样本长度,样本是记录音频数据最基本的单元,样本长度就是采样位数,也称为位深度。用的最多的格式是SND_PCM_FORMAT_S16_LE,有符号16位、小端模式。
设置采样频率
函数:
函数原型:
int snd_pcm_hw_params_set_rate(snd_pcm_t *pcm,
snd_pcm_hw_params_t *params,
unsigned int val,
int dir
)
参数:
val -- 指定采样率大小,譬如 44100.
dir -- 用于控制方向,若 dir=-1,则实际采样率小于参数 val;dir=0 表示实际采样率等于参数 val;dir=1 表示实际采样率大于参数 val。
作用:
调用 snd_pcm_hw_params_set_rate 设置采样率大小。
代码:
/*设置采样频率,并判断是否设置成功*/
if ((err = snd_pcm_hw_params_set_rate_near(capture_handle, hw_params, &rate, 0)) < 0)
printf("无法设置采样率(%s)\\n", snd_strerror(err));
exit(1);
printf("采样率设置成功\\n");
参数:
rate:采样频率,是指每秒钟采样次数,该次数是针对帧而言,譬如有44100、16000、8000,百度API调用推荐使用16000或8000
设置声道
函数:
函数原型:
int snd_pcm_hw_params_set_channels(snd_pcm_t *pcm,
snd_pcm_hw_params_t *params,
unsigned int val
)
参数:
val -- 指定声道数量,val=1 表示单声道,val=2 表示双声道,也就是立体声。
作用:
调用 snd_pcm_hw_params_set_channels()函数设置 PCM 设备的声道数。
代码:
/*设置声道,并判断是否设置成功*/
if ((err = snd_pcm_hw_params_set_channels(capture_handle, hw_params, AUDIO_CHANNEL_SET)) < 0)
printf("无法设置声道数(%s)\\n", snd_strerror(err));
exit(1);
printf("声道数设置成功.\\n");
参数:
AUDIO_CHANNEL_SET:AUDIO_CHANNEL_SET为单声道,值为1。声道分为单声道(Mono)和双声道/立体声(Stereo)。1 表示单声道、2 表示立体声。
加载硬件参数
函数:
函数原型:
int snd_pcm_hw_params(snd_pcm_t *pcm, snd_pcm_hw_params_t *params)
作用:
参数设置完成之后,最后调用 snd_pcm_hw_params()加载/安装配置、将配置参数写入硬件使其生效。
代码:
/*将配置写入驱动程序中,并判断是否配置成功*/
if ((err = snd_pcm_hw_params(capture_handle, hw_params)) < 0)
printf("无法向驱动程序设置参数(%s)\\n", snd_strerror(err));
exit(1);
printf("参数设置成功.\\n");
使声卡设备处于准备状态
函数:
函数原型:
int snd_pcm_prepare(snd_pcm_t *pcm)
作用:
调用 snd_pcm_prepare()函数会使得 PCM 设备处于 SND_PCM_STATE_PREPARED 状态,也就是处于一种准备好的状态。
代码:
/*使采集卡处于空闲状态*/
snd_pcm_hw_params_free(hw_params);
/*准备音频接口,并判断是否准备好*/
if ((err = snd_pcm_prepare(capture_handle)) < 0)
printf("无法使用音频接口 (%s)\\n", snd_strerror(err));
exit(1);
printf("音频接口已准备好.\\n");
读/写数据
读写数据需要在代码中配置一周期大小的缓冲区:
(读:声卡设备->缓冲区->文件,写:文件->缓冲区->声卡设备)
函数:
函数原型:
snd_pcm_sframes_t snd_pcm_writei(snd_pcm_t *pcm,
const void *buffer,
snd_pcm_uframes_t size
)
参数:
pcm -- PCM 设备的句柄。
buffer -- 应用程序的缓冲区,调用 snd_pcm_writei()将参数 buffer(应用程序的缓冲区)缓冲区中的数据写入到驱动层的播放环形缓冲区 buffer 中。
size -- 指定写入数据的大小,以帧为单位,通常情况下,每次调用 snd_pcm_writei()写入一个周期数据。
作用:
如果是PCM播放,则调用 snd_pcm_writei()函数向播放缓冲区 buffer中写入音频数据。
函数原型:
snd_pcm_sframes_t snd_pcm_readi(snd_pcm_t *pcm,
void *buffer,
snd_pcm_uframes_t size
)
参数:
buffer -- 应用程序的缓冲区,调用 snd_pcm_readi()函数,将从驱动层的录音环形缓冲区 buffer 中读取数据到参数 buffer 指定的缓冲区中(应用程序的缓冲区)。
size -- 指定读取数据的大小,以帧为单位;通常情况下,每次调用snd_pcm_readi()
读取一个周期数据。
作用:
如果是PCM录音,则调用 snd_pcm_readi()函数从录音缓冲区 buffer 中读取数据。
代码:
/*配置一个数据缓冲区用来缓冲数据*/
//snd_pcm_format_width(format) 获取样本格式对应的大小(单位是:bit)
int frame_byte = snd_pcm_format_width(format) * AUDIO_CHANNEL_SET / 8;//一帧大小为2字节
buffer = malloc(buffer_frames * frame_byte); //一周期为2048字节
printf("缓冲区分配成功.\\n");
录音从声卡设备读数据即可,读写操作代码如下:
(调用成功,返回实际读取/写入的帧数; 调用失败将返回一个负数错误码。 即使调用成功,实际读取/写入的帧数不一定等于参数 size所指定的帧数,仅当发生信号或XRUN时,返回的帧数可能会小于参数第三参数buffer_frames。 )
/*从声卡设备读取一周期音频数据:2048字节*/
ret = snd_pcm_readi(capture_handle, buffer, buffer_frames);
if(0 > ret)
printf("从音频接口读取失败(%s)\\n", snd_strerror(ret));
exit(1);
/*向声卡设备写一周期音频数据:2048字节*/
ret = snd_pcm_writei(capture_handle,buffer,buffer_frames);
if(0 > ret)
printf("向音频接口写数据失败(%s)\\n",snd_strerror(ret));
exit(1);
参数:
buffer:程序数据缓冲区;
buffer_frames:1024,读/写数据的大小,以帧为单位,通常情况下,每次读/写一个周期数据。
文件IO
我们需要将录制的音频文件保存到本地,就需要用到文件IO相关知识,打开音频文件以及向音频文件写数据。
打开音频文件
函数:
函数原型:
FILE *fopen(const char *filename, const char *mode)
参数:
filename -- 字符串,表示要打开的文件名称。
mode -- 字符串,表示文件的访问模式。
作用:
以指定的方式打开文件。
代码:
/*创建一个保存PCM数据的文件*/
if ((pcm_data_file = fopen(argv[1], "wb")) == NULL)
printf("无法创建%s音频文件.\\n", argv[1]);
exit(1);
printf("用于录制的音频文件已打开.\\n");
参数:
argv[1]:程序执行时传递的参数,例./voice record.cpm,则该参数为"record.cpm"
"wb":只写打开或新建一个二进制文件,只允许写数据。
向音频文件写数据
函数:
函数原型:
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream)
参数:
ptr -- 这是指向要被写入的元素数组的指针。
size -- 这是要被写入的每个元素的大小,以字节为单位。
nmemb -- 这是元素的个数,每个元素的大小为 size 字节。
stream -- 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输出流。
作用:
向指定文件写入指定大小数据。
代码:
/*从声卡设备读取一周期音频数据:1024帧 2048字节*/
ret = snd_pcm_readi(capture_handle, buffer, buffer_frames);
if(0 > ret)
printf("从音频接口读取失败(%s)\\n", snd_strerror(ret));
exit(1);
/*写数据到文件,写入数据大小:音频的每帧数据大小2个字节*ret(从声卡设备实际读到的帧数)*/
fwrite(buffer, ret, frame_byte, pcm_data_file);
信号
函数:
函数原型:
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact)
参数:
signum -- 要捕获的信号类型。
act -- 传入参数,新的处理方式。
oldact -- 传出参数,旧的处理方式。
作用:
修改信号处理动作(通常在 Linux 用其来注册一个信号的捕捉函数)。
函数原型:
int sigemptyset(sigset_t *set);
参数:
set -- 需要清空的信号集。
作用:
该函数的作用是将信号集初始化为空。
代码:
/*头文件*/
#include <signal.h>
/*注册信号捕获退出接口*/
struct sigaction act;
act.sa_handler = exit_sighandler;//指定信号捕捉后的处理函数名(即注册函数)
act.sa_flags = 0;//通常设置为0,表使用默认属性
sigemptyset(&act.sa_mask);//将屏蔽的信号集合设为空
sigaction(2, &act, NULL); //Ctrl+c→2 SIGINT(终止/中断)
void exit_sighandler(int sig)
/*释放数据缓冲区*/
free(buffer);
/*关闭音频采集卡硬件*/
snd_pcm_close(capture_handle);
/*关闭文件流*/
fclose(pcm_data_file);
/*正常退出程序*/
printf("程序已终止!\\n");
exit(0);
多线程
函数:
函数原型:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg)
thread -- 传出参数,保存系统为我们分配好的线程 ID
attr -- 通常传 NULL,表示使用线程默认属性。若想使用具体属性也可以修改该参数。
start_routine -- 函数指针,指向线程主函数,该函数运行结束,则线程结束。
arg -- 线程主函数执行期间所使用的参数。
作用:
创建一个新线程。
函数原型:
int int truncate(const char *path,off_t length);
参数:
path -- 文件路径名。
length -- 截断长度,若文件大小>length大小,额外的数据丢失。若文件大小<length大小,那么,这个文件将会被扩展,扩展的部分将补以null,也就是‘\\0’。
作用:
截断或扩展文件。
代码:
/*创建子线程读取用户输入*/
pthread_t tid;
ret = pthread_create(&tid, NULL, read_tfn, NULL);
if (ret != 0) perror("pthread_create failed");
void *read_tfn(void *arg)
char buf1.项目前言2.Vosk介绍 3.项目开发
4.效果演示
5.项目总结
系统:Win10
Java:1.8.0_333
IDEA:2020.3.4
Gitee:https://gitee.com/lijinjiang01/SpeechRecognition
1.项目前言
最近在做一个鬼畜视频的时候,需要处理大量语音文件,全部都是 wav 格式的,然后我想把这些语音转成文字,不过这些语音有几千条,这时候我就想能不能用 Java 实现。
不过现在主流的语音识别像百度。讯飞好像都不支持 Java 离线版,在查找一些资料后,我准备使用 Vosk
2.Vosk介绍
Vosk 官网:https://alphacephei.com/vosk/
Vosk 是言语识别工具包,Vosk 最大的优点是:
- 支持二十+种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷兰人,加泰罗尼亚语,阿拉伯, 希腊语, 波斯语, 菲律宾语,乌克兰语, 哈萨克语, 瑞典语, 日语, 世界语, 印地语, 捷克语, 波兰语
- 移动设备上脱机工作-Raspberry Pi,Android,iOS
- 使用简单的 pip3 install vosk 安装
- 每种语言的手提式模型只有是 50Mb, 但还有更大的服务器模型可用
- 提供流媒体 API,以提供最佳用户体验(与流行的语音识别 python 包不同)
- 还有用于不同编程语言的包装器-java / csharp / javascript等
- 可以快速重新配置词汇以实现最佳准确性
- 支持说话人识别
至于选择 Vosk 的原因,我想大概因为他们是 Apache-2.0 开源项目吧,而且他们还提供了中文模型,这省了很多事不是么
3.项目开发
3.1 项目准备
这里的项目准备只做一个 wav 语音识别,能够供自己使用就行了
首先,我们需要新建一个 Maven Java 项目,然后导入相关的依赖
<!-- 获取音频信息 -->
<dependency>
<groupId>org</groupId>
<artifactId>jaudiotagger</artifactId>
<version>2.0.3</version>
</dependency>
<!-- 语音识别 -->
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>5.7.0</version>
</dependency>
<dependency>
<groupId>com.alphacephei</groupId>
<artifactId>vosk</artifactId>
<version>0.3.32</version>
</dependency>
这里除了 vosk 相关依赖,我还导入了 jaudiotagger 这个获取音频信息的依赖,因为等会我们需要自动获取音频的采样率(SampleRate),有兴趣的小伙伴可以看一下我另一篇文章:Java获取Wav文件的采样率SampleRate
那么为什么我需要获取音频的采样率呢?这里我们看下 Vosk 官方给的示例代码:
https://github.com/alphacep/vosk-api/blob/master/java/demo/src/main/java/org/vosk/demo/DecoderDemo.java
package org.vosk.demo;
import java.io.FileInputStream;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import javax.sound.sampled.AudioSystem;
import javax.sound.sampled.UnsupportedAudioFileException;
import org.vosk.LogLevel;
import org.vosk.Recognizer;
import org.vosk.LibVosk;
import org.vosk.Model;
public class DecoderDemo
public static void main(String[] argv) throws IOException, UnsupportedAudioFileException
LibVosk.setLogLevel(LogLevel.DEBUG);
try (Model model = new Model("model");
InputStream ais = AudioSystem.getAudioInputStream(new BufferedInputStream(new FileInputStream("../../python/example/test.wav")));
Recognizer recognizer = new Recognizer(model, 16000))
int nbytes;
byte[] b = new byte[4096];
while ((nbytes = ais.read(b)) >= 0)
if (recognizer.acceptWaveForm(b, nbytes))
System.out.println(recognizer.getResult());
else
System.out.println(recognizer.getPartialResult());
System.out.println(recognizer.getFinalResult());
这个示例代码里有两个重要点:
- model:也就是 new Model(“model”) 这里,这里需要我们指定模型位置
- sampleRate:也就是 new Recognizer(model, 16000) 这里,他这里的示例代码写死了 sampleRate 为 16000 Hz,不过每个音频的采样率不可能都一样,我需要识别的音频采样率基本都是 44100 Hz,所以这里我们需要将他改为自动识别
3.2 model 准备
我们需要实现离线语音识别,那么就得将模型下载到本地电脑。下载地址为官网的 Models 模块:https://alphacephei.com/vosk/models
我们直接找到 Chinese 分类,这里有 2 个模型,上面较小的 40 多M的是轻量级模型,适用于手机等移动设备;下面 1 个多G的适用于服务器的,很明显模型越大识别语音正确率越高

这里我们两个都下载,等会对比下正确率和速率,下载下来是两个压缩包,直接解压到 D 盘,等会选择路径方便(怎么方便怎么来)。

解压之后如下
3.3 测试音频准备
音频下载地址:https://download.csdn.net/download/qq_35132089/86723883
测试音频已经上传到 CSDN 的资源库,设置下载积分为0,有兴趣的小伙伴可以下载测试玩玩
这里一共准备了 8 段音频,共 62 个字
01.wav: 保家卫国
02.wav: 这个世界需要希望
03.wav: 我们的勇气绝对不能动摇
04.wav: 德玛西亚
05.wav: 正义要靠法律要么靠武力
06.wav: 为了那些不能作战的人而战
07.wav: 勇往直前
08.wav: 生命不息战斗不止
3.4 代码实现
捋清楚思路,接下来实现就比较简单了,我这里写一个 Swing 的项目,准备到时候选择 wav 文件直接语音识别,或者选择一个文件夹,解析该目录下所有的 wav 音频文件
关键代码:
import com.lijinjiang.beautyeye.ch3_button.BEButtonUI;
import org.jaudiotagger.audio.AudioFile;
import org.jaudiotagger.audio.wav.WavFileReader;
import org.vosk.Model;
import org.vosk.Recognizer;
import javax.sound.sampled.AudioSystem;
import javax.swing.*;
import javax.swing.filechooser.FileNameExtensionFilter;
import javax.swing.filechooser.FileSystemView;
import java.awt.*;
import java.io.*;
public class MainFrame
private JFrame mainFrame; // 主界面
private final JPanel contentPanel = new JPanel(null); // 内容面板
private String modelPath; // 模型位置
private File chooseFile; // 选择的文件夹或文件
private JTextField pathField; // 模型位置文本框
private JTextField fileField; // 文件路径文本框
private JTextArea displayArea; // 展示区域
private JLabel timeLabel; // 显示耗时标签
public MainFrame()
modelPath = System.getProperty("user.dir") + "/src/main/resources/vosk-model-small-cn-0.22"; // 初始化模型
System.out.println(modelPath);
createFrame();
/**
* 创建主窗口
*/
private void createFrame()
mainFrame = new JFrame();
mainFrame.setTitle("语音识别");
createOperatePanel();
createDisplayPane();
createTimeLabel();
mainFrame.add(contentPanel);
mainFrame.setSize(new Dimension(800, 600));
mainFrame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
mainFrame.setLocationRelativeTo(null);
mainFrame.setVisible(true);
/**
* 创建操作面板
*/
private void createOperatePanel()
JButton pathBtn = new JButton("选择模型");
pathBtn.setLocation(10, 10);
pathBtn.setSize(new Dimension(80, 36));
pathBtn.setFocusable(false); // 不绘制焦点
pathBtn.addActionListener(e -> showChoosePathDialog());
pathField = new JTextField();
pathField.setEditable(false);
pathField.setLocation(100, 10);
pathField.setSize(new Dimension(250, 36));
JButton fileBtn = new JButton("选择文件");
fileBtn.setFocusable(false); // 不绘制焦点
fileBtn.addActionListener(e -> showChooseFileDialog());
fileBtn.setLocation(360, 10);
fileBtn.setSize(new Dimension(80, 36));
fileField = new JTextField();
fileField.setEditable(false);
fileField.setLocation(450, 10);
fileField.setSize(new Dimension(250, 36));
// 开始执行按钮
JButton startBtn = new JButton("执行");
startBtn.addActionListener(e -> execute());
startBtn.setUI(new BEButtonUI().setNormalColor(BEButtonUI.NormalColor.green));
startBtn.setFocusable(false); // 不绘制焦点
startBtn.setLocation(710, 10);
startBtn.setSize(new Dimension(70, 36));
contentPanel.add(pathBtn);
contentPanel.add(pathField);
contentPanel.add(fileBtn);
contentPanel.add(fileField);
contentPanel.add(startBtn);
/**
* 创建展示面板
*/
private void createDisplayPane()
JScrollPane scrollPane = new JScrollPane();
displayArea = new JTextArea();
scrollPane.setViewportView(displayArea);
displayArea.setEditable(false);
displayArea.setBorder(null);
scrollPane.setSize(new Dimension(775, 480));
scrollPane.setLocation(8, 56);
contentPanel.add(scrollPane);
private void createTimeLabel()
timeLabel = new JLabel();
timeLabel.setHorizontalAlignment(SwingConstants.RIGHT); // 文本靠右对齐
timeLabel.setSize(new Dimension(100, 36));
timeLabel.setLocation(680, 530);
contentPanel.add(timeLabel);
/**
* 选择模型位置
*/
private void showChoosePathDialog()
JFileChooser fileChooser = new JFileChooser(); // 初始化一个文件选择器
String pathValue = pathField.getText().trim();
if (pathValue.length() == 0)
FileSystemView fsv = fileChooser.getFileSystemView(); // 获取文件系统网关
fileChooser.setCurrentDirectory(fsv.getHomeDirectory()); // 设置桌面为当前文件路径
else
// 设置上一次选择路径为当前文件路径
File file = new File(pathValue);
File parentFile = file.getParentFile();
if (parentFile == null)
fileChooser.setCurrentDirectory(file);
else
fileChooser.setCurrentDirectory(parentFile);
fileChooser.setFileSelectionMode(JFileChooser.DIRECTORIES_ONLY); // 可选文件夹和文件
fileChooser.setMultiSelectionEnabled(false); // 设置可多选
int result = fileChooser.showOpenDialog(mainFrame);
if (result == JFileChooser.APPROVE_OPTION)
File file = fileChooser.getSelectedFile();
modelPath = file.getAbsolutePath();
pathField.setText(modelPath); // 将选择的文件路径写入到文本框
/**
* 选择需要转换成文字的文件夹或者文件
* 文件夹:表示该目录下一层所有 wav 都需要转成文字
* 文件:表示只需要将该文件转换成文字即可
*/
private void showChooseFileDialog()
JFileChooser fileChooser = new JFileChooser(); // 初始化一个文件选择器
String fileValue = fileField.getText().trim();
if (fileValue.length() == 0)
FileSystemView fsv = fileChooser.getFileSystemView();
fileChooser.setCurrentDirectory(fsv.getHomeDirectory()); // 设置桌面为当前文件路径
else
// 设置上一次选择路径为当前文件路径
File file = new File(fileValue);
File parentFile = file.getParentFile();
if (parentFile == null)
fileChooser.setCurrentDirectory(file);
else
fileChooser.setCurrentDirectory(parentFile);
fileChooser.setFileSelectionMode(JFileChooser.FILES_AND_DIRECTORIES); // 可选文件夹和文件
fileChooser.setMultiSelectionEnabled(false); // 设置可多选
fileChooser.removeChoosableFileFilter(fileChooser.getAcceptAllFileFilter()); // 不显示所有文件的下拉选
fileChooser.addChoosableFileFilter(new FileNameExtensionFilter("wav", "wav"));
int result = fileChooser.showOpenDialog(mainFrame);
if (result == JFileChooser.APPROVE_OPTION)
chooseFile = fileChooser.getSelectedFile();
fileField.setText(chooseFile.getAbsolutePath()); // 将选择的文件路径写入到文本框
/**
* 开始执行操作
*/
private void execute()
displayArea.setText(""); // 执行后清空显示面板
if (modelPath == null || 0 == modelPath.length())
JOptionPane.showMessageDialog(mainFrame, "模型位置不能为空", "错误", JOptionPane.ERROR_MESSAGE);
return;
if (chooseFile == null)
JOptionPane.showMessageDialog(mainFrame, "未选择文件夹或者音频文件", "错误", JOptionPane.ERROR_MESSAGE);
return;
long startTime = System.currentTimeMillis();
// 用于测试进度条的线程
Thread thread = new Thread()
public void run()
if (chooseFile.isDirectory()) // 如果是文件夹,则遍历里面每个文件
File[] files = chooseFile.listFiles(pathname 以上是关于Linux应用编程-音频应用编程-语音转文字项目的主要内容,如果未能解决你的问题,请参考以下文章