mysql 关联查询是不是很耗性能
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql 关联查询是不是很耗性能相关的知识,希望对你有一定的参考价值。
1、除非迫不得已,不建议使用子查询,因为在几乎所有的sql语言中子查询都是效率很低的,并且mysql中的子查询在某些旧版本下面还有不少缺陷。2、直接连接查询,使用的是笛卡尔积的查询模式。就是把X表中的每一行分别与Y表中的每一行组合一次,10W数据表X与30W数据表Y的笛卡尔积将会产生300W条数据。
3、X,Y直连、join、left join、right join、inner jion都属于直接连接查询,只不过在查询出的结果集中的数据选取方式有区别而已(有的时候也会因为这个区别而产生微量的效率不同)。
4、在你上面的两条语句中,只能用语句1。因为语句1使用了直连,笛卡尔积导致的300W的数据量的主键对等查询的速度上还是说得过去的。而语句2中使用了两个子查询,然后以两个子查询的结果集再做笛卡尔积,然后再在300W数据中做主键对等匹配出结果集,且查询出的结果只能是两个表各自的id,不是你想要的结果,并且你的on语句是错误的,会导致不可预知的结果。 参考技术A 1、除非迫不得已,不建议使用子查询,因为在几乎所有的sql语言中子查询都是效率很低的,并且mysql中的子查询在某些旧版本下面还有不少缺陷。
2、直接连接查询,使用的是笛卡尔积的查询模式。就是把X表中的每一行分别与Y表中的每一行组合一次,10W数据表X与30W数据表Y的笛卡尔积将会产生300W条数据。
3、X,Y直连、join、left join、right join、inner jion都属于直接连接查询,只不过在查询出的结果集中的数据选取方式有区别而已(有的时候也会因为这个区别而产生微量的效率不同)。
请采纳
高性能mysql 第6章 查询性能优化
union的局限性:
mysql无法将limit条件从外层下推到内层。
如:
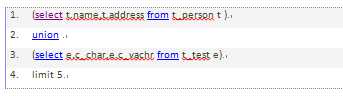
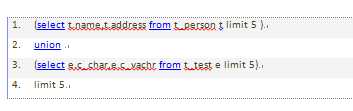
可以优化为:
并行执行:
mysql无法利用多核特性来并行执行查询。
hash关联:
mysql不支持hash关联。
跳跃索引扫描(skip index scan)
不支持。经过测试,在5.6版本支持了。
在同一张表上进行更新的限制:
MySQL不允许对同一张表同时进行查询和更新。这其实并不是优化器的限制,下面的SQL无法运行,这个SQL尝试将两个表中相似行的数量记录到字段cnt中:
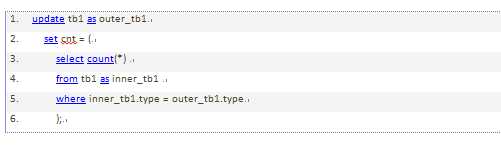
可以通过生成表的形式绕过上面的限制,因为mysql只会把这个表当作一个临时表来处理。实际上,这执行了两个查询:一个是子查询中的select语句,另一个是多表关联update,只是关联的表是一个临时表。子查询会在update语句打开表之前就完成,所以下面的查询会正常执行:

hint提示:
DELAYED:针对insert和replace。执行后立即返回,然后在空闲的时候,数据才会写入到硬盘。比较适合记录日志。
STRAIGHT_JOIN:定义关联顺序。
SQL_SMALL_RESULT,SQL_BIG_RESULT:用于查询,标志结果集的大小,引导排序操作在内存或者硬盘中执行。
SQL_BUFFER_RESULT:将查询结果放入一个临时表,尽快的释放表锁。
SQL_CACHE,SQL_NO_CACHE:是否缓存。
USE INDEX,IGNORE INDEX,FORCE INDEX:强制使用索引,和不适用索引。
优化关联查询:
- 尽量确保on的列上有索引。
- 确保group by和order by只涉及一张表的列。这样才可以用到索引。ps(order by好理解,group by自己思考也会明白,如果group by上没有索引,肯定要全表并排序,或者使用临时表才能做group by)
- mysql内部有可能会自动转换等价的distinct和 group by语法。
用户自定义变量:
这一章节是mysql的独有的功能,不是sql标准,可以在查询里使用自定义变量,来实现行号、统计等功能。这里我没有细看,罗列了两篇文章可以参考:
http://www.cnblogs.com/guaidaodark/p/6037040.html
http://blog.csdn.net/muzizhuben/article/details/49449853
以上是关于mysql 关联查询是不是很耗性能的主要内容,如果未能解决你的问题,请参考以下文章