MySQL条件查询 SELECT的执行顺序(DQL语句)
Posted 南有乔木i
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL条件查询 SELECT的执行顺序(DQL语句)相关的知识,希望对你有一定的参考价值。
运算符
比较运算符
| 比较运算符 | 描述 |
|---|---|
| >、<、<=、>=、=、<>、!= | <>在 SQL 中表示不等于,SQL中没有== |
| BETWEEN … AND … | 在一个范围之内,包头又包尾,最小的需要在前面,如:between 100 and 200 |
| IN(…) | 在in之后的列表中的值,多选一,使用逗号分隔 |
| LIKE ‘匹配字符’ | 模糊匹配 ( _ 匹配单个字符,% 匹配任意个字符) |
| IS NULL | 查询某一列为 NULL 的值,注:不能写=NULL |
| IS NOT NULL | 不为空 |
| REGEXP | 正则表达式 |
逻辑运算符
| 逻辑运算符 | 描述 |
|---|---|
and && | 与 |
or 丨丨 | 或 |
not ! | 非 |
| XOR | 异或 |
按位运算符
| 运算符 | 描述 |
|---|---|
| & | 位与关系 |
| 丨 | 位或关系 |
| ~ | 位取反 |
| ^ | 位异或 |
| << | 左移 |
| >> | 右移 |
WHERE语句
执行顺序:FROM → WHERE → SELECT → ORDER BY → LIMIT
select 字段名 from 表名 where 条件:条件查询,取出表中的每条数据,满足条件的记录就返回,不满足条件的不返回select 字段名 from 表名 where 字段 in (数据 1, 数据 2...):in 里面的每个数据都会作为一次条件,只要满足条件的就会显示select 字段名 from 表名 where 字段名 between 值1 and 值2:范围查询 表示从值1到值2范围,包头又包尾select 字段名 from 表名 where 字段名 like '通配符字符串':模糊查询,通配符 %,例如:‘%老王%’
WHERE子句中,条件执行的顺序是从左到右的。所以应该把索引条件,或者筛选掉记录最多的条件写在最左侧。
-- 查询 math 分数大于 80 分的学生
select * from student3 where math > 80;
-- 查询 id 是 1 或 3 或 5 的学生
select * from student3 where id in(1, 3, 5);
-- 查询 id 不是 1 或 3 或 5 的学生
select * from student3 where id not in(1, 3, 5);
-- 查询 english 成绩大于等于 75,且小于等于 90 的学生
select * from student3 where english between 75 and 90;
-- 查询 age 大于 35 且性别为男的学生(两个条件同时满足)
select * from student3 where age > 35 and sex='男';
-- 查询 age 大于 35 或性别为男的学生(两个条件其中一个满足)
select * from student3 where age > 35 or sex = '男';
-- 查询姓马的学生
select * from student3 where name like '马%';
-- 查询姓名中包含'德'字的学生
select * from student3 where name like '%德%';
-- 查询姓马,且姓名有两个字的学生
select * from student3 where name like '马_';
-- 查询t_emp表中,工资和佣金不在2000-3000之间的人
select * from t_emp where not sal + ifnull(comm, 0) in (2000, 3000);
聚合函数
聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。
- 聚合函数会忽略空值 NULL。
- 聚合函数不能出现在where子句中。
select 聚合函数(列名) from 表名:聚合函数的使用
| 聚合函数 | 作用 |
|---|---|
| max(列名) | 求这一列的最大值 |
| min(列名) | 求这一列的最小值 |
| avg(列名) | 求这一列的平均值,非数字类型结果为0 |
| count(*),count(列名) | 统计这一列有多少条记录,第一个用于获得包含空值的记录数,第二个用于获得包含非空值的记录数 |
| sum(列名) | 对这一列求总和,只能用于数字类型,字符类型返回0,日期类型是毫秒数相加 |
-- 查询学生总数
select count(id) as 总人数 from student;
select count(*) as 总人数 from student;
-- 聚合函数对于 NULL 的记录不会统计的,如果统计个数则不要使用有可能为 null 的列。
-- 查询 id 字段,如果为 null,则使用 0 代替
select count(ifnull(id,0)) from student;
-- 查询年龄大于 20 的总数
select count(*) from student where age>20;
-- 查询数学成绩总分
select sum(math) 总分 from student;
-- 查询数学成绩平均分
select avg(math) 平均分 from student;
-- 查询数学成绩最高分
select max(math) 最高分 from student;
-- 查询数学成绩最低分
select min(math) 最低分 from student;
分组
分组查询是指使用GROUP BY语句对查询信息进行分组,相同数据作为一组。
执行顺序:FROM → WHERE → GROUP BY → SELECT → ORDER BY → LIMIT
select 字段 1,字段 2... from 表名 group by 分组字段 [having 条件]:将分组字段结果中相同内容作为一组。select 字段1, 字段2, ... from 表名 group by 1 having 条件:用聚合函数和普通条件数据做判断时使用,平时没用with rollup:对汇总后的数据再次汇总计算having 条件:先在group by子句中分组后再做筛选
GROUP BY 将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用。
查询语句中如果含有group by子句,select子句中可以包括聚合函数或group by子句分组用的列,其余内容不可以出现在select子句中。
-- 按性别进行分组,求男生和女生数学的平均分
select sex, avg(math) from student3 group by sex;
-- 当我们使用某个字段分组,在查询的时候也需要将这个字段查询出来,否则看不到数据属于哪组的。
-- 对分组查询的结果再进行过滤
SELECT sex, COUNT(*) FROM student3 WHERE age > 25 GROUP BY sex having COUNT(*) >2;
-- 多分组字段,先按deptno分组,然后按job分组
select deptno, job, count(*), avg(sal) from t_emp group by deptno, job;
-- 对分组结果集再次做汇总计算
select deptno, avg(sal), sum(sal), max(sal), min(sal) from t_emp group by deptno with rollup;
-- 查询每个部门中,1982年以后入职的员工并且超过2人的部门编号
select deptno from t_emp where hiredate>="1982-01-01" group by deptno having count(deptno) > 2;
对分组结果集再次做汇总计算的结果:
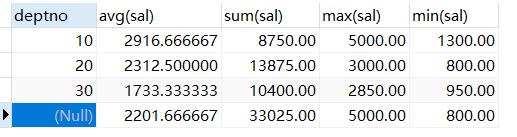
having 与 where 的区别
where 子句
- 对查询结果进行分组前,将不符合 where 条件的行去掉,即在分组之前过滤数据,即先过滤再分组。
- where 后面不可以使用聚合函数
having 子句
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。
- having 后面可以使用聚合函数
MySQL基本查询 SELECT的执行顺序(DQL语句)
select语句屏蔽了物理层的操作,用户不必关心数据的真实存储,交由数据库高效的查找数据。
普通查询
执行顺序:词法分析与优化,读取SQL语句 → FROM,选择数据来源 → SELECT,选择输出内容
select 列名 from 表名 [where 条件表达式]:查询表中的数据select * from 表名:查询表所有行和列的数据*代表所有字段,一般不建议使用
select 字段名 1, 字段名 2, 字段名 3, ... from 表名:查询指定列
-- 查询所有的学生:
select * from student;
-- 查询 student 表中的 name 和 age 列
select name, age from student;
使用别名查询
select 字段名1 as 别名, 字段名2 as 别名... from 表名:对列指定别名select 表别名.字段名1 as 别名, 表别名.字段名2 as 别名... from 表名 as 表别名:对列和表同时指定别名
使用别名的好处:
- 显示的时候使用新的名字,并不修改表的结构。
as可以省略。 - 用于多表查询操作
-- 使用别名
select name as 姓名,age as 年龄 from student;
-- 表使用别名
select st.name as 姓名,age as 年龄 from student as st;
分页查询
LIMIT是限制的意思,所以LIMIT的作用就是限制查询记录的条数。
执行顺序:FROM → SELECT → LIMIT
select 字段名 from 表名 limit 起始位置, 偏移量:分页查询- 起始位置:起始行数,从 0 开始计数,如果省略,默认就是0
- 偏移量:返回的行数
- 公式:开始的索引 = (当前的页码 - 1) * 每页显示的条数
-- 查询学生表中数据,从第 3 条开始显示,显示 6 条。
select * from student3 limit 2, 6;
排序
通过ORDER BY子句,可以将查询出的结果进行排序(排序只是显示方式,不会影响数据库中数据的顺序)。
执行顺序:FROM → SELECT → ORDER BY → LIMIT
select 字段名 from 表名 order by 字段名 [asc|desc]:单列排序,只按某一个字段进行排序,单列排序。select 字段名 from 表名 order by 字段名1 [asc|desc], 字段名2 [asc|desc]:组合排序,同时对多个字段进行排序,如果第 1 个字段相等,则按第 2 个字段排序,依次类推。- ASC:升序,默认值
- DESC:降序
如果排序列是数字类型,数据库就按照数字大小排序,如果是日期类型,就按照日期大小,如果是字符串就按照字符集序号排序。
-- 查询所有数据,使用年龄降序排序
select * from student order by age desc;
-- 查询所有数据,在年龄降序排序的基础上,如果年龄相同再以数学成绩升序排序
select * from student order by age desc, math asc;
清除重复值
select distinct 字段名 from 表名:查询指定列并且结果不出现重复数据
使用
DISTINCT的SELECT子句中只能查询一列数据,如果查询多列,去除重复记录就会失效,一条SELECT语句中,只能使用一次。
-- 查询学生来自于哪些地方
select address from student;
-- 去掉重复的记录
select distinct address from student;
查询结果参与运算
select 列名1+固定值 from 表名:某列数据和固定值运算select 列名1+列名2 from 表名:某列数据和其他列数据参与运算
注意:参与运算的必须是数值类型
-- 某列数据和固定值运算
select age + 1 from student;
-- 某列数据和其他列数据参与运算,英语和数学分数之和
select english + math from student;
以上是关于MySQL条件查询 SELECT的执行顺序(DQL语句)的主要内容,如果未能解决你的问题,请参考以下文章