Yolov5--模型文件(yolov5s.yaml)解读和模型修改
Posted 放鹿的散妃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yolov5--模型文件(yolov5s.yaml)解读和模型修改相关的知识,希望对你有一定的参考价值。
1、模型文件解读(yolov5s.yaml)
Yolov5的网络模型结构由位于models文件夹下的yaml文件定义。以yolov5的6.0版本为例,其models文件夹下有多个yaml文件(如下图),它们分别是yolov5n.yaml、yolov5s.yaml、yolov5m.yaml、yolov5l.yaml、yolov5x.yaml,其区别仅为depth_multiple和width_multiple两个参数不同。虽然5个yaml文件中的backbone和head部分完全相同,但通过depth_multiple和width_multiple这两个参数即可实现不同复杂度的模型设计。
以yolov5s.yaml文件为例(如下所示),对模型文件中的参数进行详解。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 4 #80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
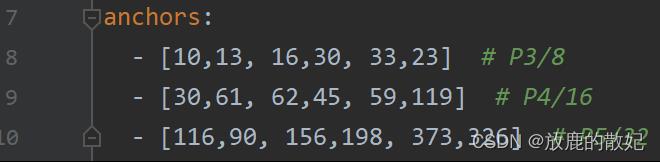
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
(1)nc:num of class类别数
(2)depth_multiple:model depth multiple,模型深度,用来控制子模块数量
(3)width_multiple:layer channel multiple,Conv通道channel的个数,即卷积核的数量
(4)anchors:9(3*3)个锚框的大小,分别在三个Detect层的feature map中使用。
如下所示,尺度越大的freature map分辨率越大,相对于原图的下采样越小,其感受野越小,设置的anchors自然越小,如[10,13, 16,30, 33,23],因此对原始图像中的小物体预测较好;相反,尺度越小的freature map分辨率越小,相对于原图的下采样越大,其感受野越大,设置的anchors自然越大,如[116, 90, 156,198, 373,326], 因此对原始图像中的大物体预测较好。
3组anchors的大小多是根据经验所得,若需要对此进行修改优化,可根据k-means和遗传进化算法找到与自己所使用的数据集最温和放大anchors。
(5)backbone:骨干网络,每一行即对每个模块进行描述,每行均有4个参数,分别为
from:该层数据源从哪里获得,-1表示上一层
number:该层的重复次数,实际中的重复次数=number*depth_multiple
module:该层模型类、
args:参数列表,是该模块所需参数,包括channel、kernel_size、stride、padding和bias等,不同的层参数有所变化。在yolov中没有明显用于下采样的polling层,但是在部分层中的stride为2以上,则说明该层包含有下采样的功能。
(6)head:头部网络,包括Neck颈部网络和预测Prediction部分,同backbone类似,每行为一个模块,且其参数定义与backbone一样。部分from参数为一个list,表面该层的数据来源于多个前面层的输出数据。
2.模型查看
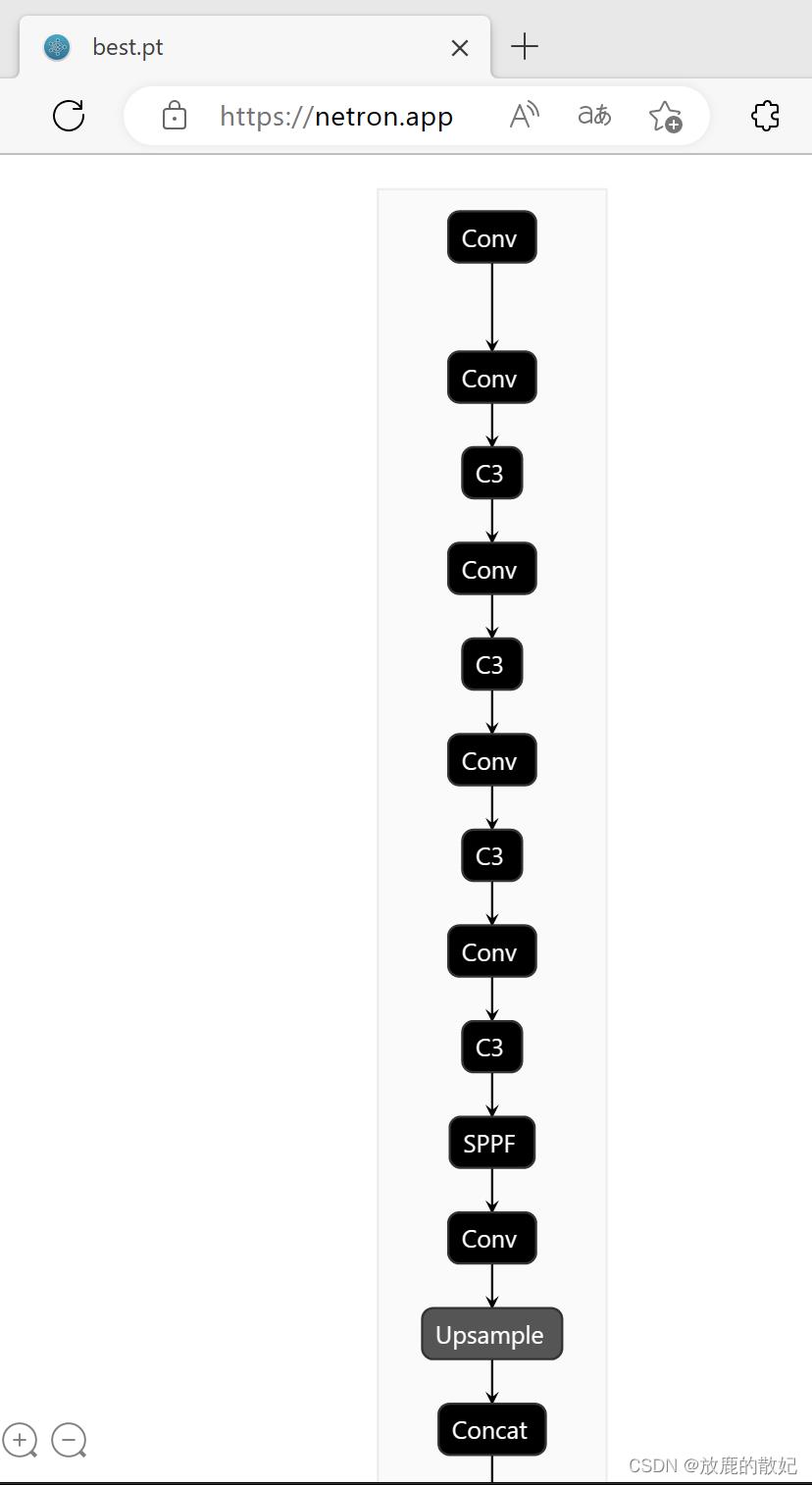
netron是常用的模型查看工具之一,可以下载并安装,也可直接使用网络版,即打开浏览器,输入地址https://netron.app/,将模型文件加载即可。当训练完成后生成了pt文件,但netron对pt文件的细节显示不足,如下图所示为部分内容,其网络结构与yaml文件一致。
但若想查看详细的模型结构,则需要将pt文件转换为onnx文件。可使用yolov5目录下的export.py文件进行转换:
python export.py --include onnx --weight path/to/xxx.pt --img 640 --train --simplify
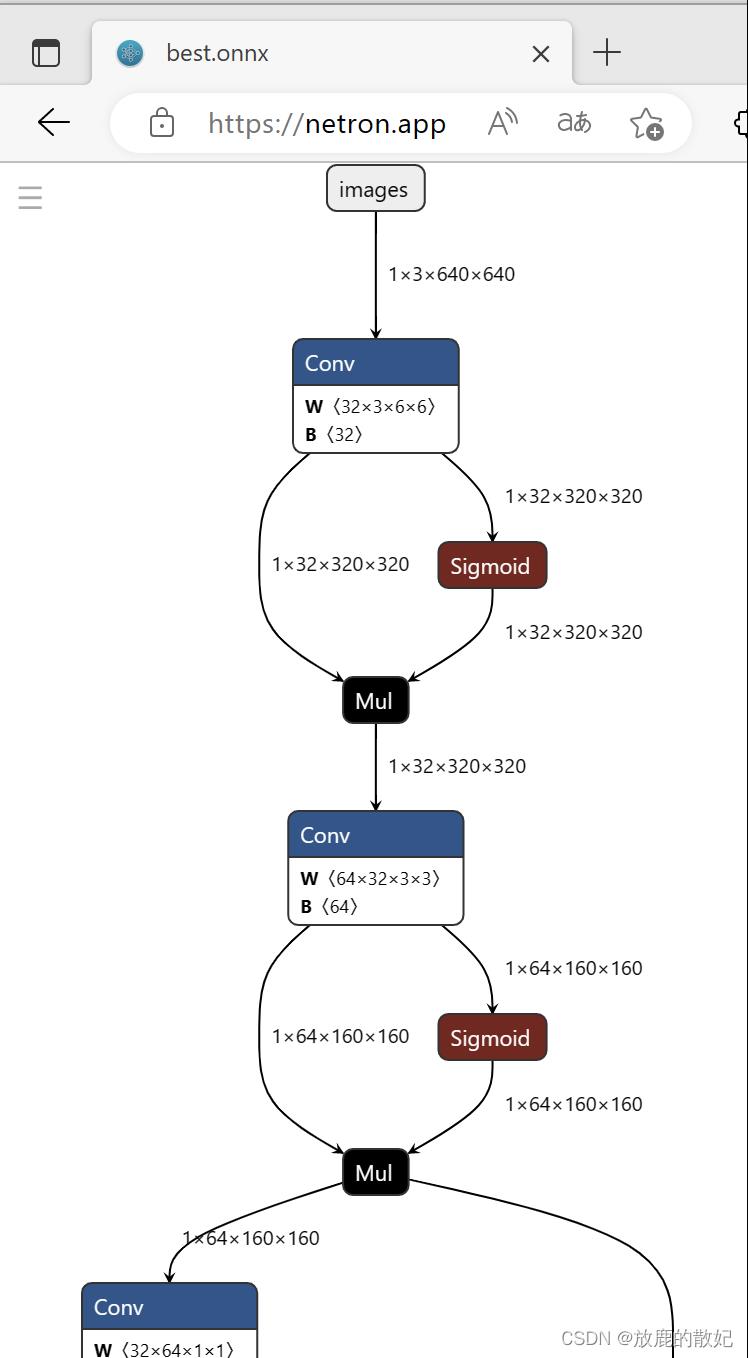
即可在pt文件同一目录下生成onnx文件,如下图所示。

将best.onnx加载到netron.app中,即可查看网络结构,如下所示为其部分内容。
3. 模型修改
在进行train的时候,控制台打印出网络模型,如下图所示。该输出与yaml文件中一致。
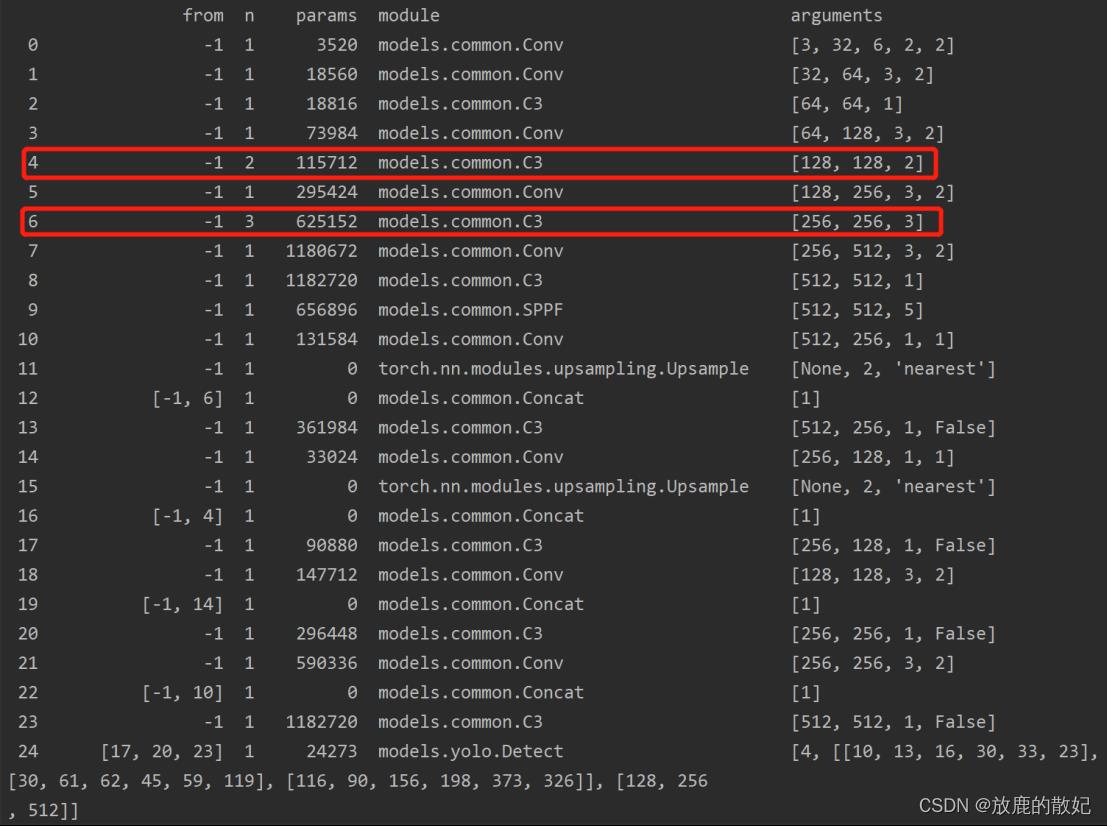
若将第4层的C3*2改为C3*1,第6层的C3*3改为C3*2,则只需要修改模型配置文件,如下所示为修改后的文件yolov5_change.yaml的部分内容,修改部分为图中红框所示。 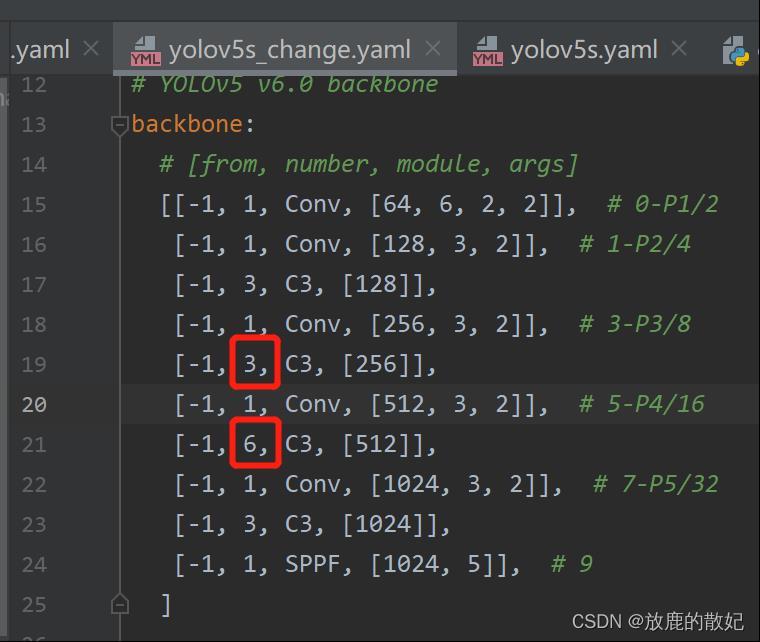
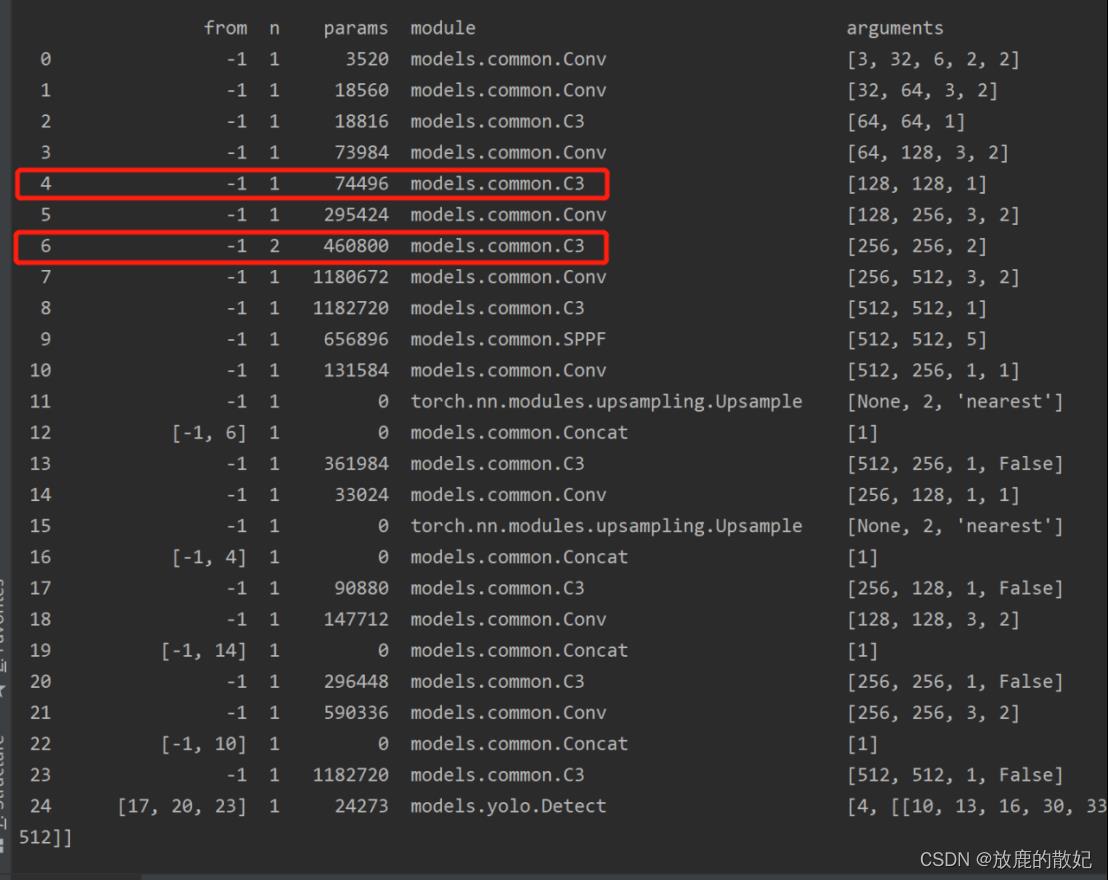
重新进行训练执行train.py时,设置weights为yolov5_change.yaml文件,控制台输出信息如下所示,红框中部分内容说明修改成功。
图像识别之Yolov5训练自己的模型
图像识别之Yolov5训练自己的模型
文章目录
一、前言
上一篇文章讲解了如何使用Yolov5的原有的模型进行识别,本文将会介绍使用Yolov5来进行自己的数据集的训练。
上一篇文章的链接是:
https://blog.csdn.net/m0_54218263/article/details/122601330?spm=1001.2014.3001.5501
二、对图像进行标注
首先我们需要获取数据,这个大家可以根据自己的需要以及数据的要求在不同的数据集中自己选择下载获取,这里不必赘述了,在获取到数据以后需要对数据进行标注,我使用的线上标注平台式:
我是准备使用猫和狗这两种动物的图片进行训练,最终希望可以准确的识别这两种动物。
下面。我们就对数据集进行标注:
导入数据:
进行添加标签:
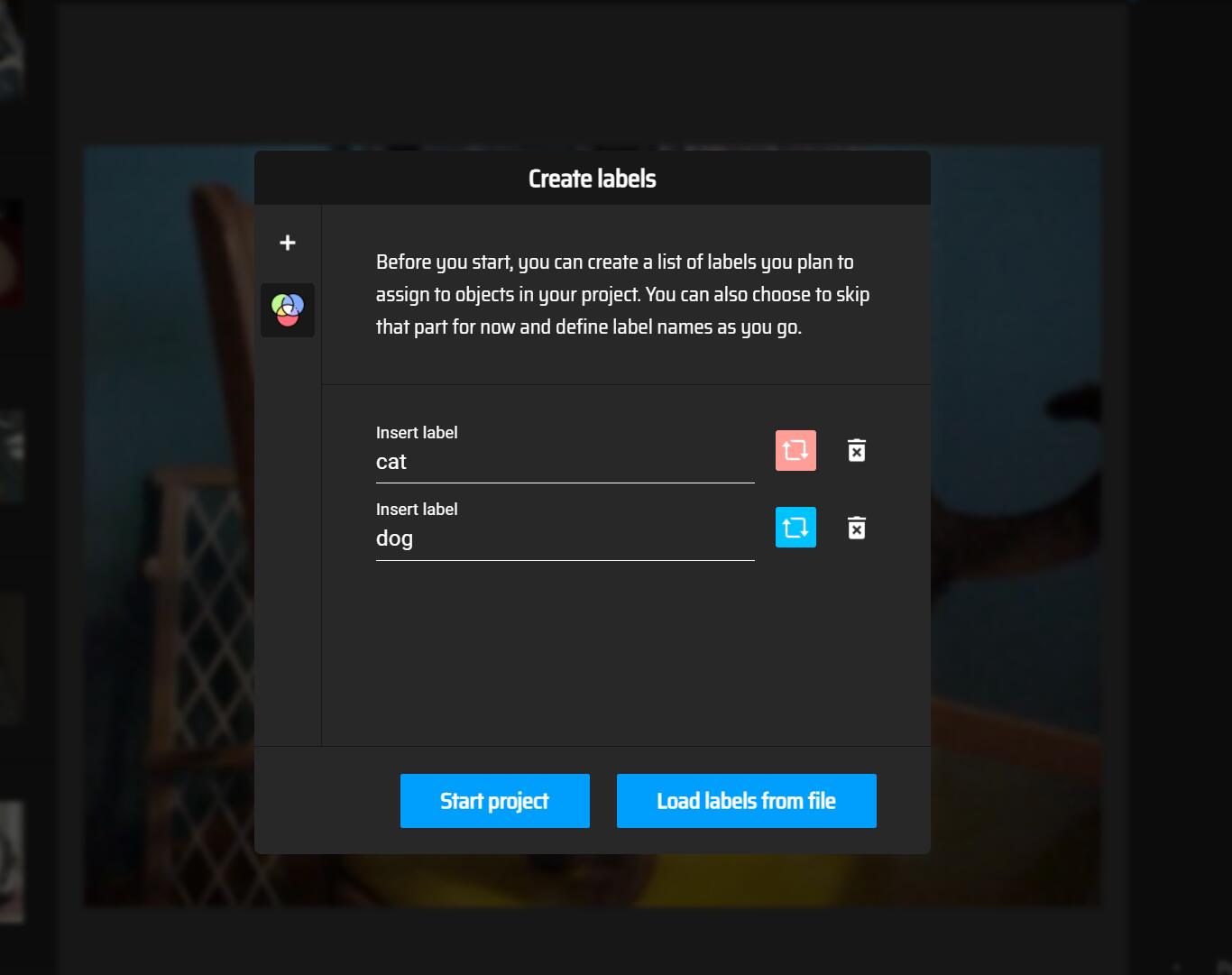
手动圈画空间:
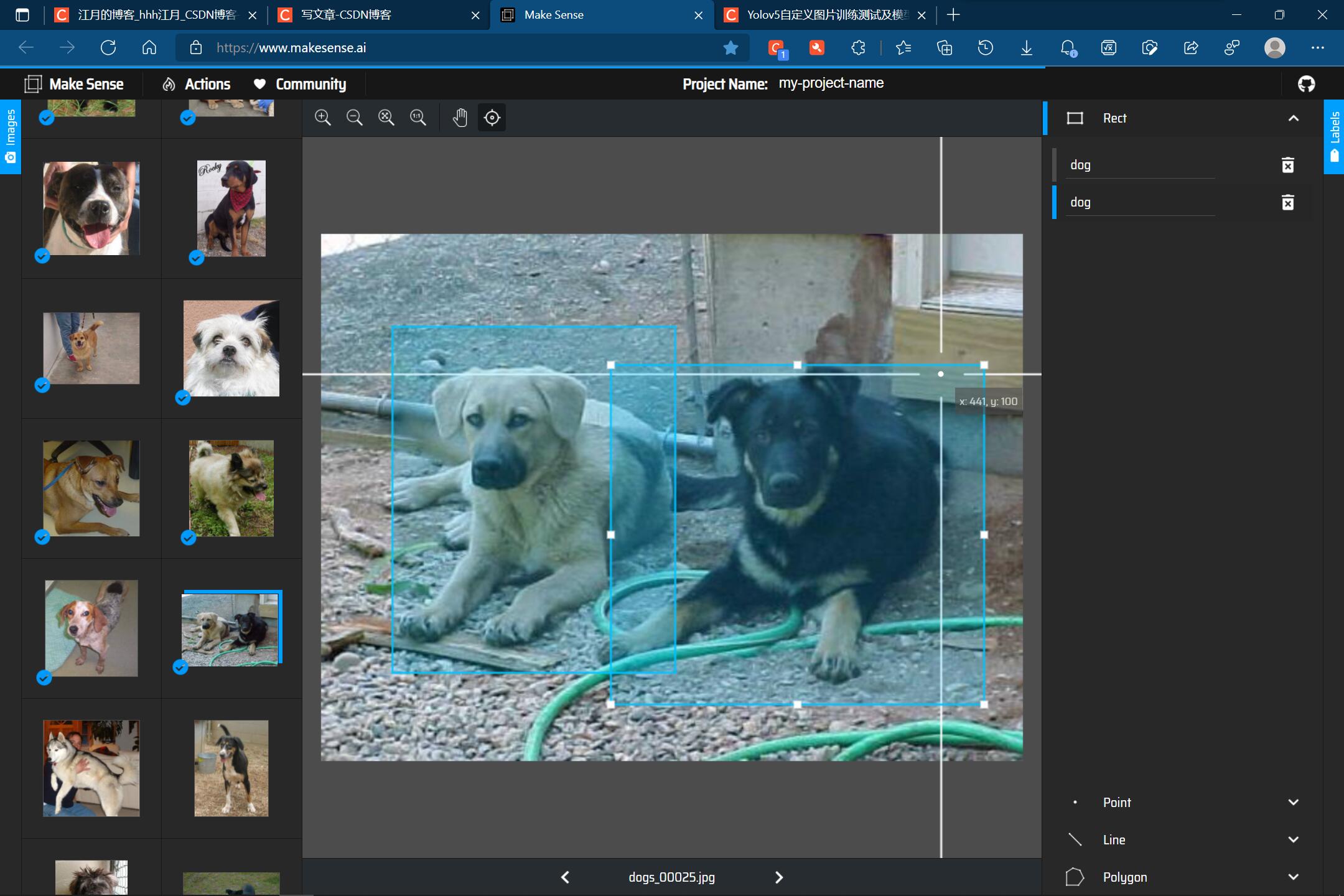
一张图片可以有多条狗:
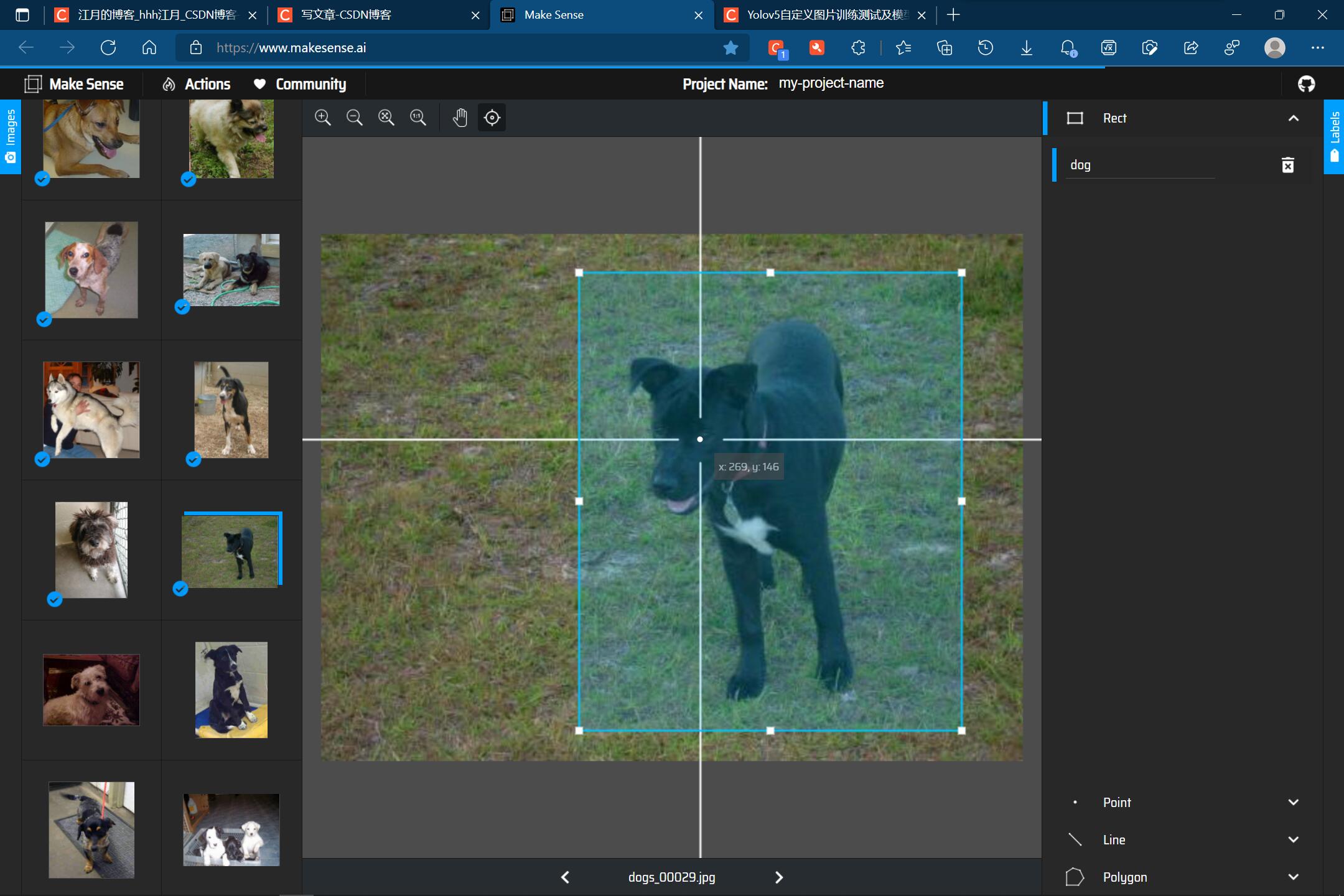
一张图片也可以只有一条狗:
一张图片可以有多只猫:
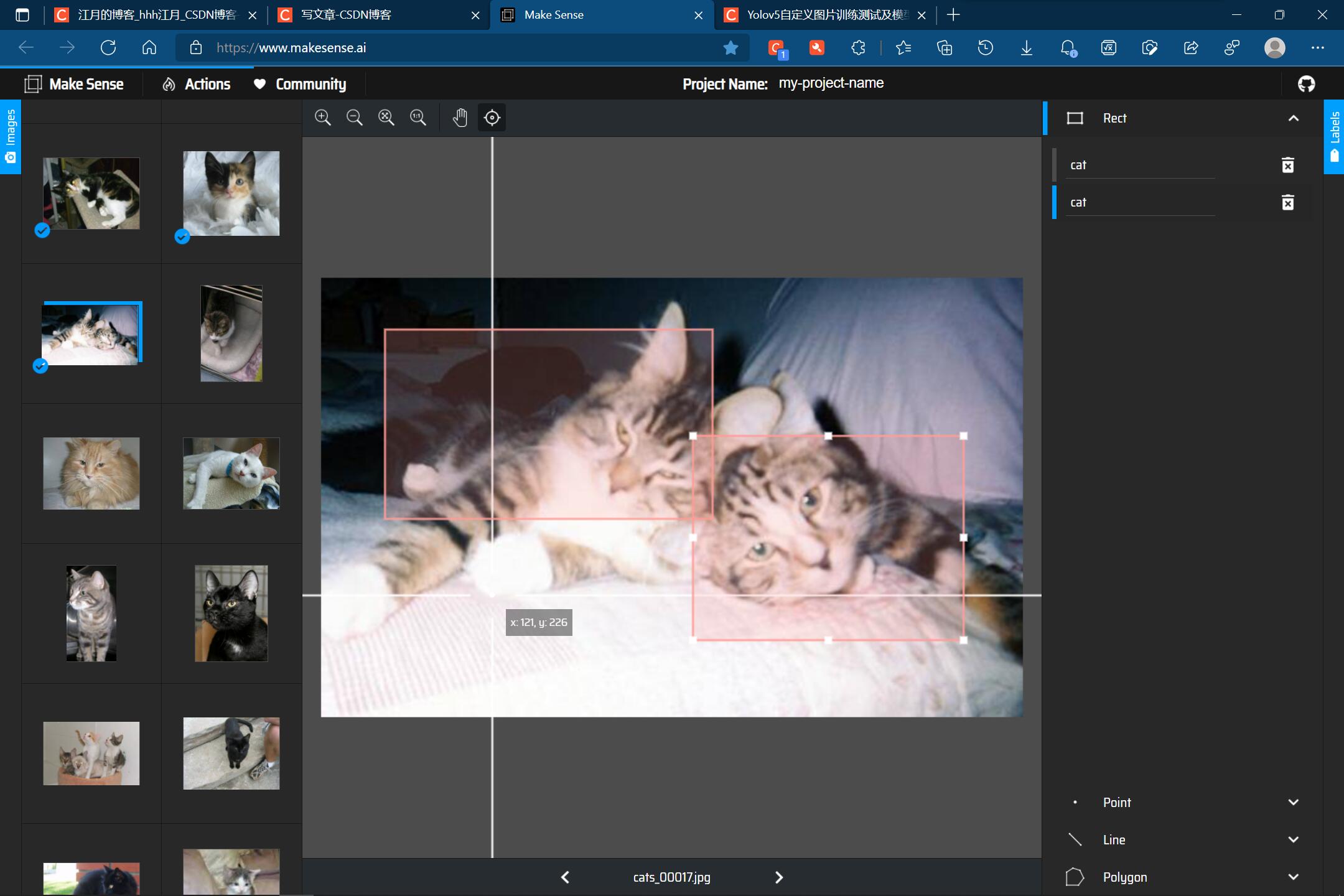
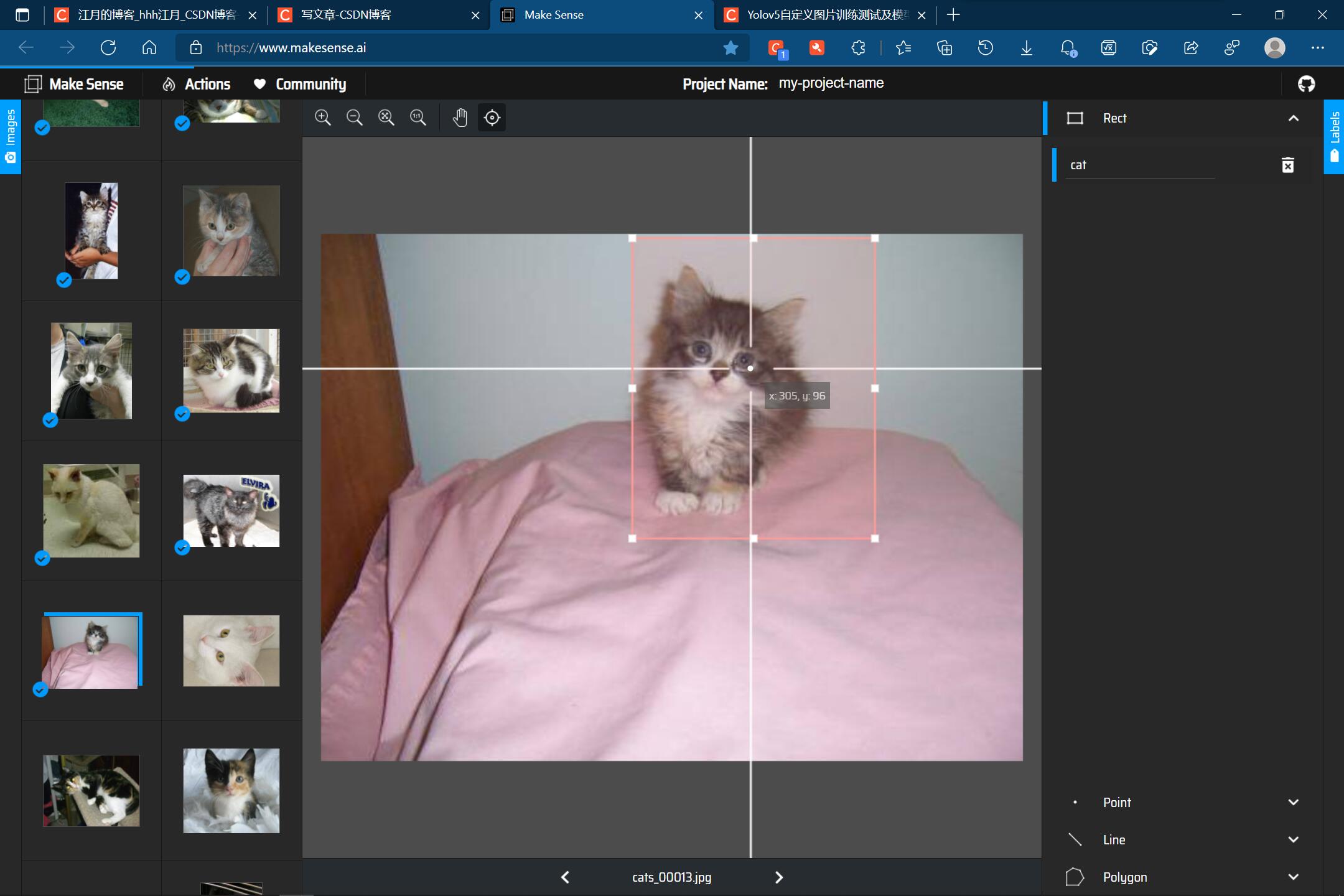
一张图片也可以只有一只猫:
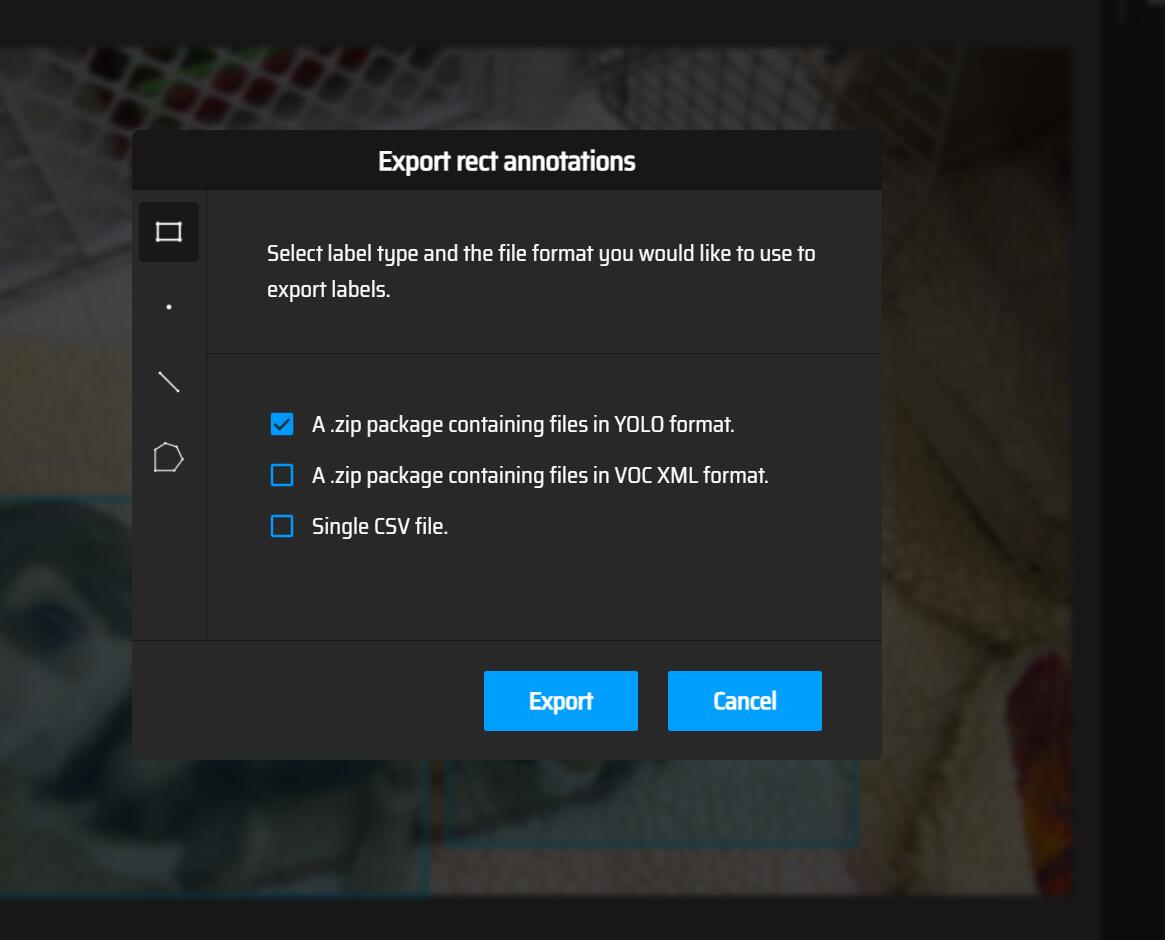
在我们,对所有的图片完成标注以后,需要导出标签:
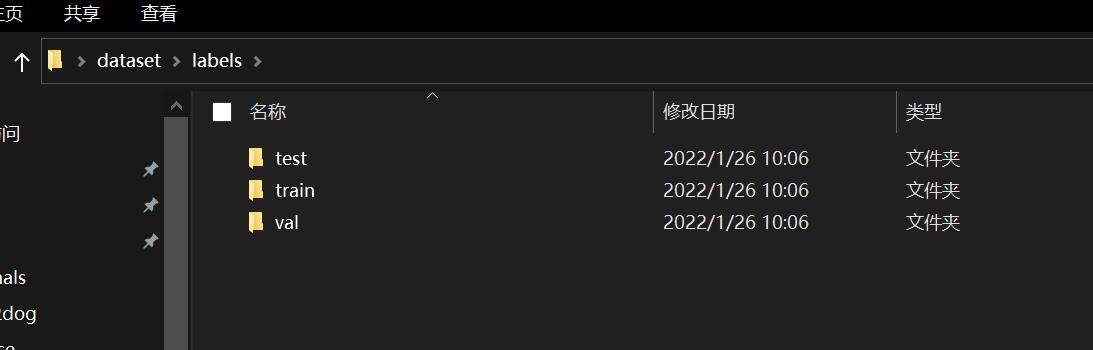
然后,我们需要对数据集进行归类:
三、数据集的划分
将自定义测试的图像数据和标签数据集分别 划分为:训练集、验证集、测试集,,比例根据数据量不同,一般可以为 96%:2%:2%
在上面所示的文件夹里面放入图片以及标签:
这里需要注意的是,标签与图片需要一一对应的。
四、配置训练的文件
我们需要对训练的文件进行配置,这样才可训练我们自己的数据。
我们需要对后缀名为yaml的文件进行修改,从而使得它们满足我们自己的训练的需求:
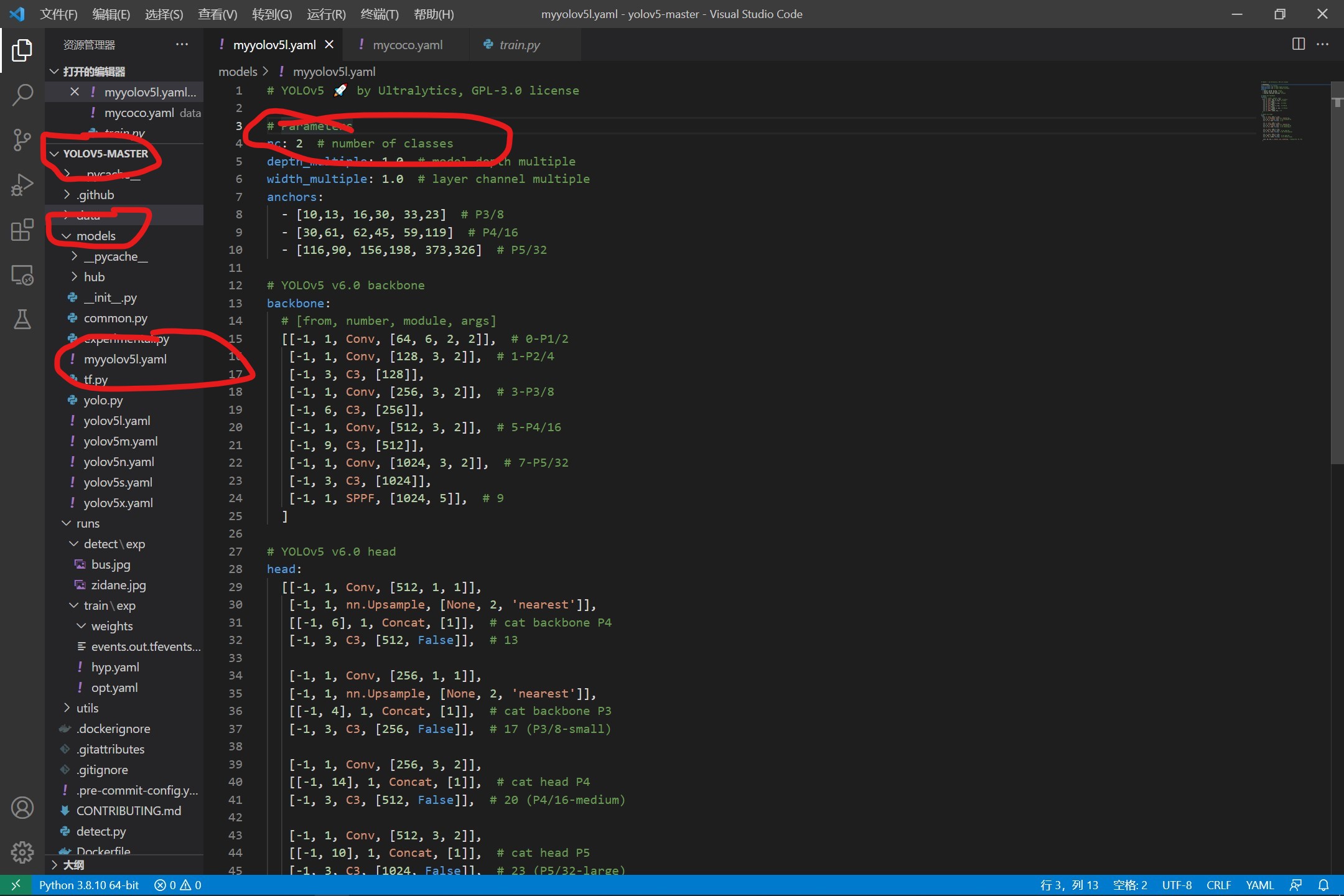
1、修改yolov5l.yaml配置文件
我们在models下面找到yolov5l,因为我是准备使用yolov5l.pt来进行训练,因此使用这个配置文件来进行修改,这里只需要修改一个位置:
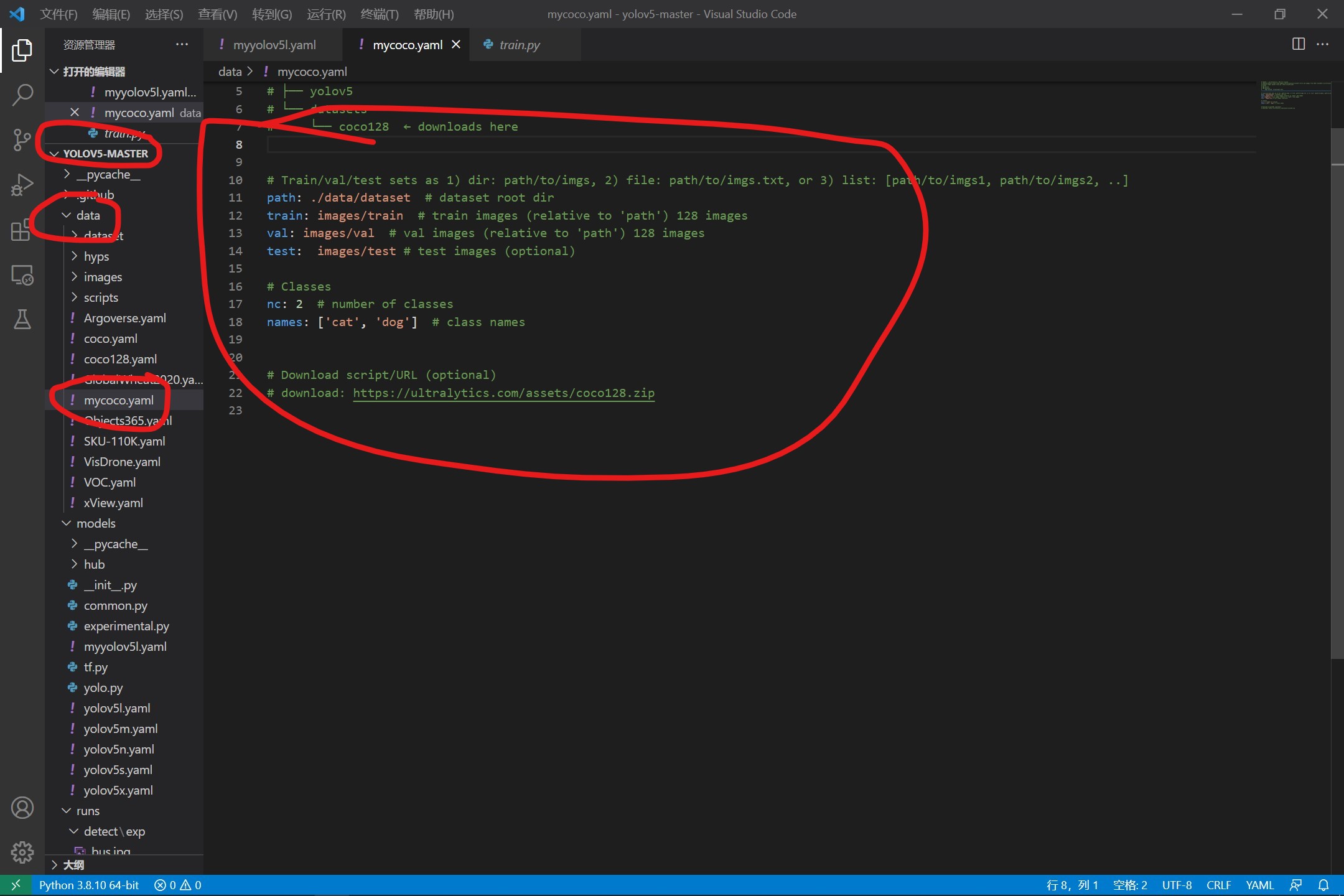
2、修改coco128.yaml配置文件
在这里,我们找到data下面的coco128文件,复制一份,然后将download注释掉,修改数目,修改标签的名称,然后就修改完成了。
五、开始训练
python train.py --cfg models/myyolov5l.yaml --data data/mycoco.yaml --weights yolov5l.pt --epoch 150 --batch-size 32
如果不希望有这么高的训练的精度,可以略微降低:
python train.py --cfg models/myyolov5s.yaml --data data/mycoco.yaml --weights yolov5s.pt --epoch 150 --batch-size 32
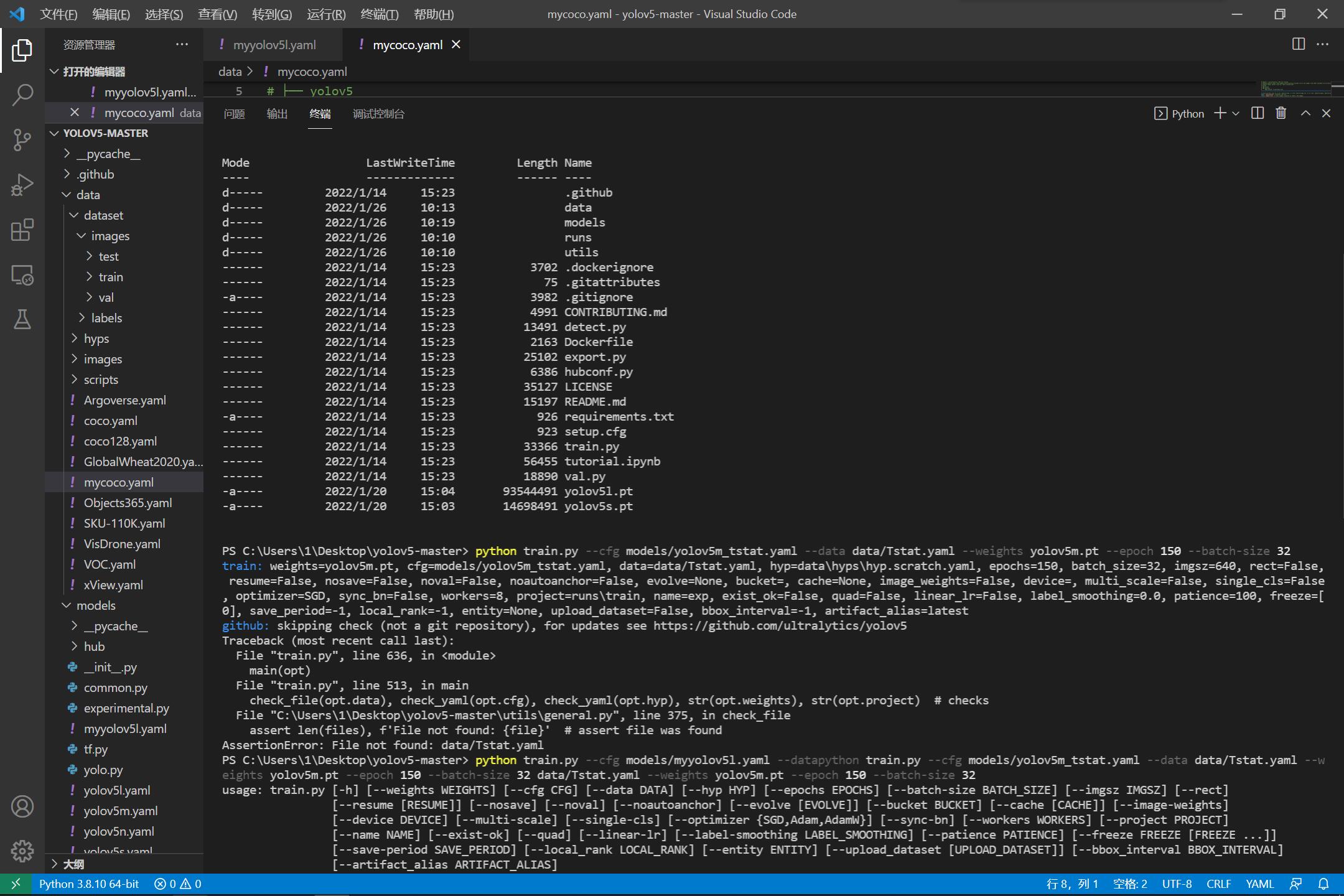
接下来就是漫长的训练过程。
六、训练结果呈现
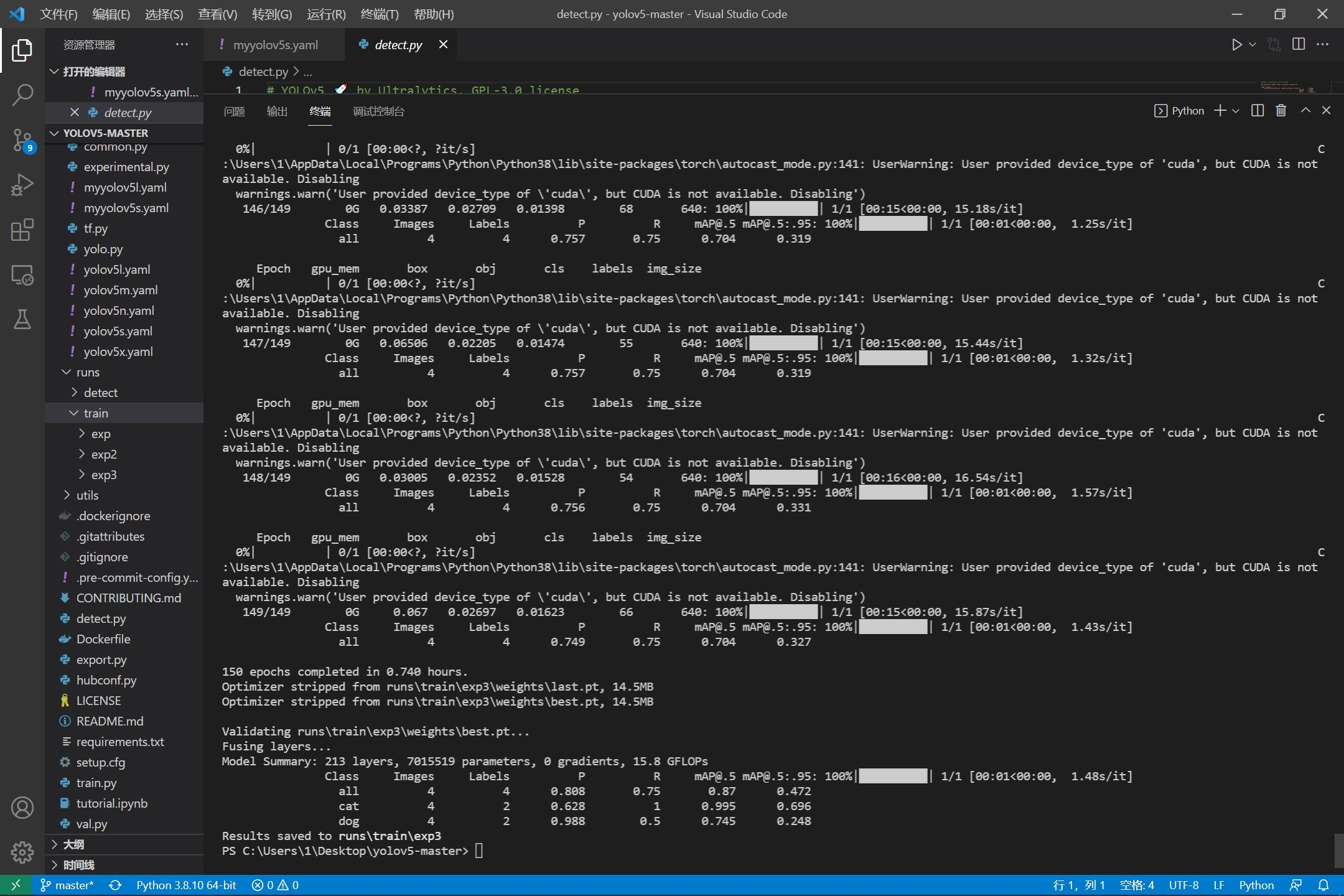
1、训练相关参数
在训练完成之后会有一些训练过程或者结果的记录,这里展示一部分内容:




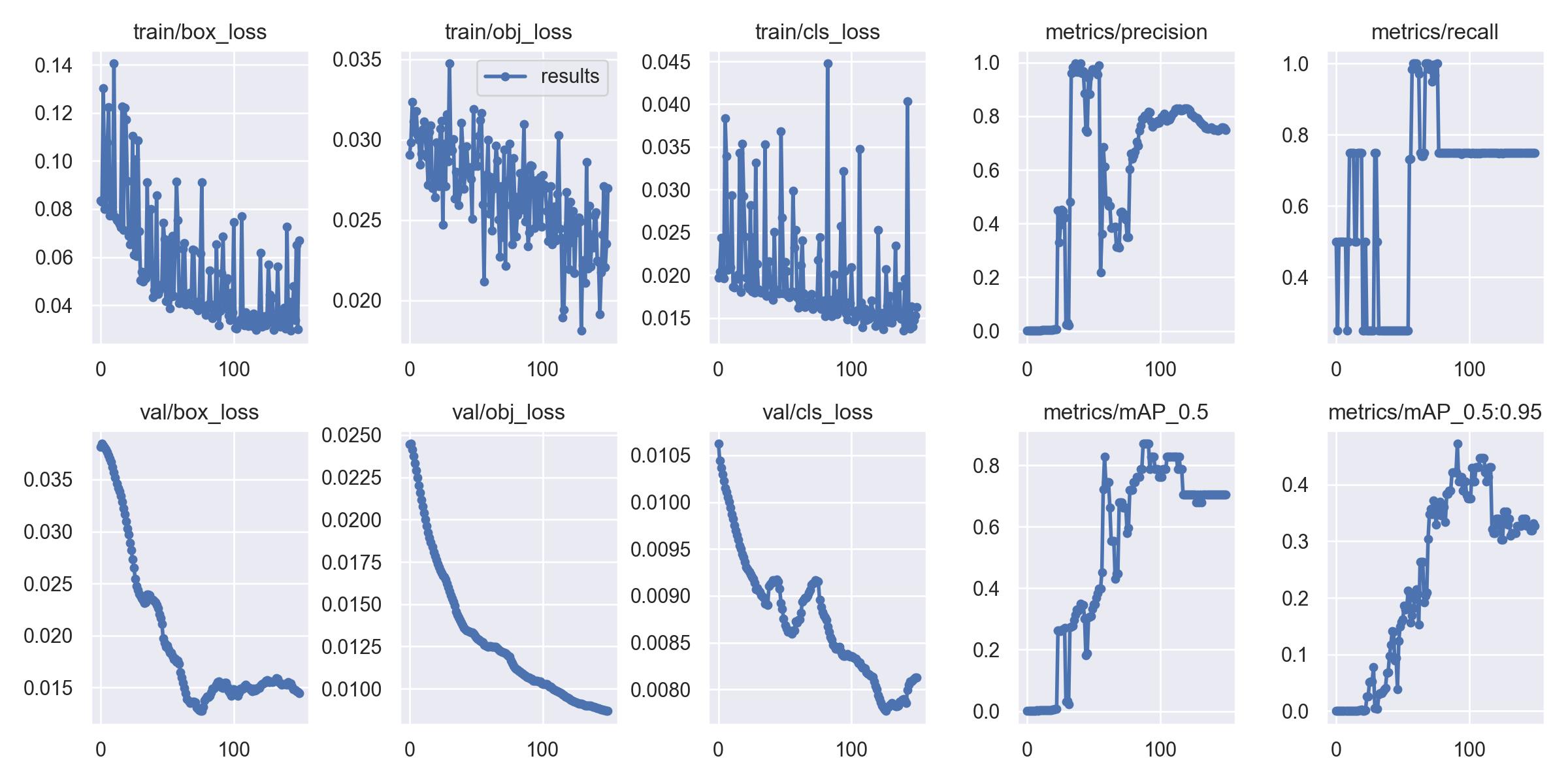
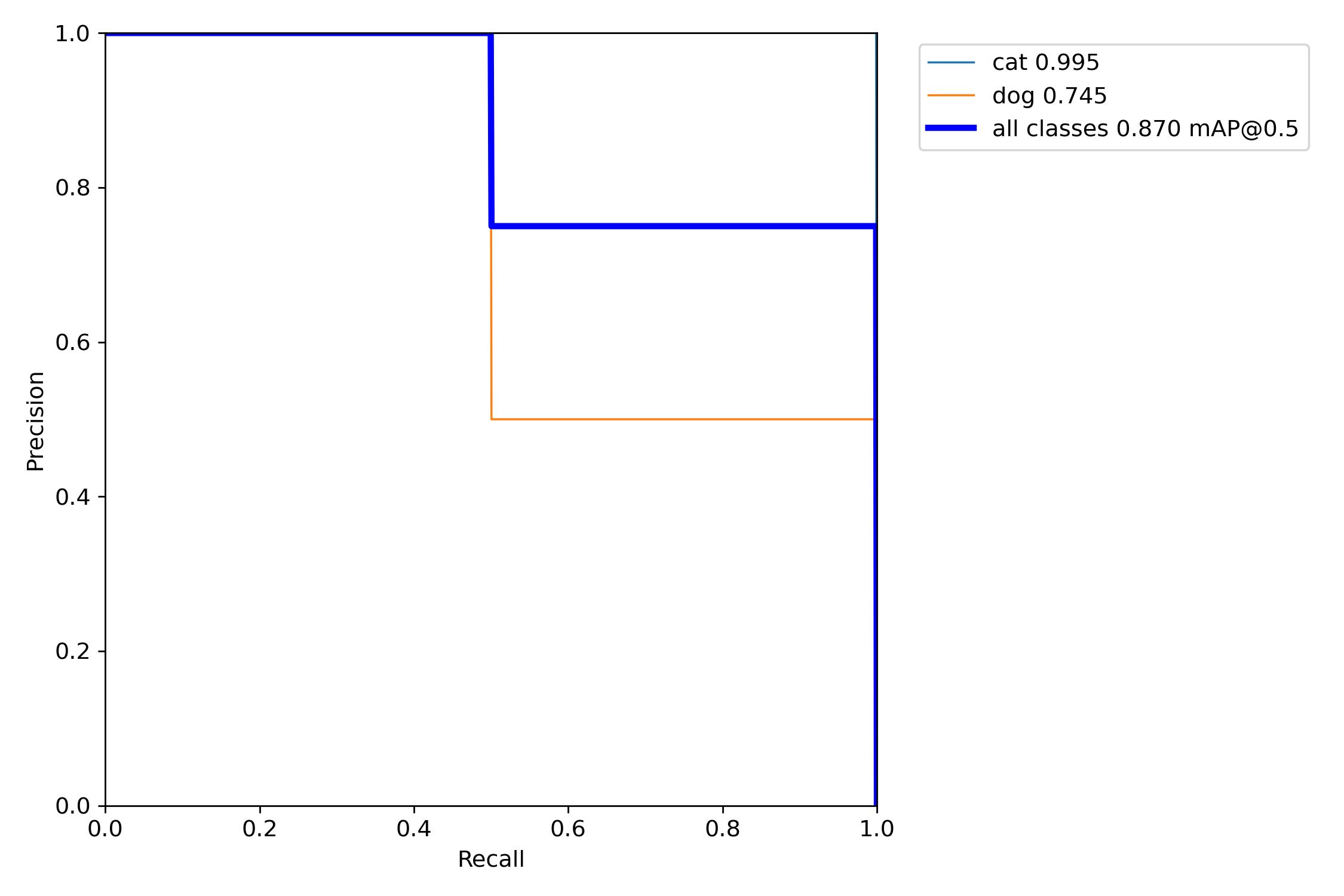
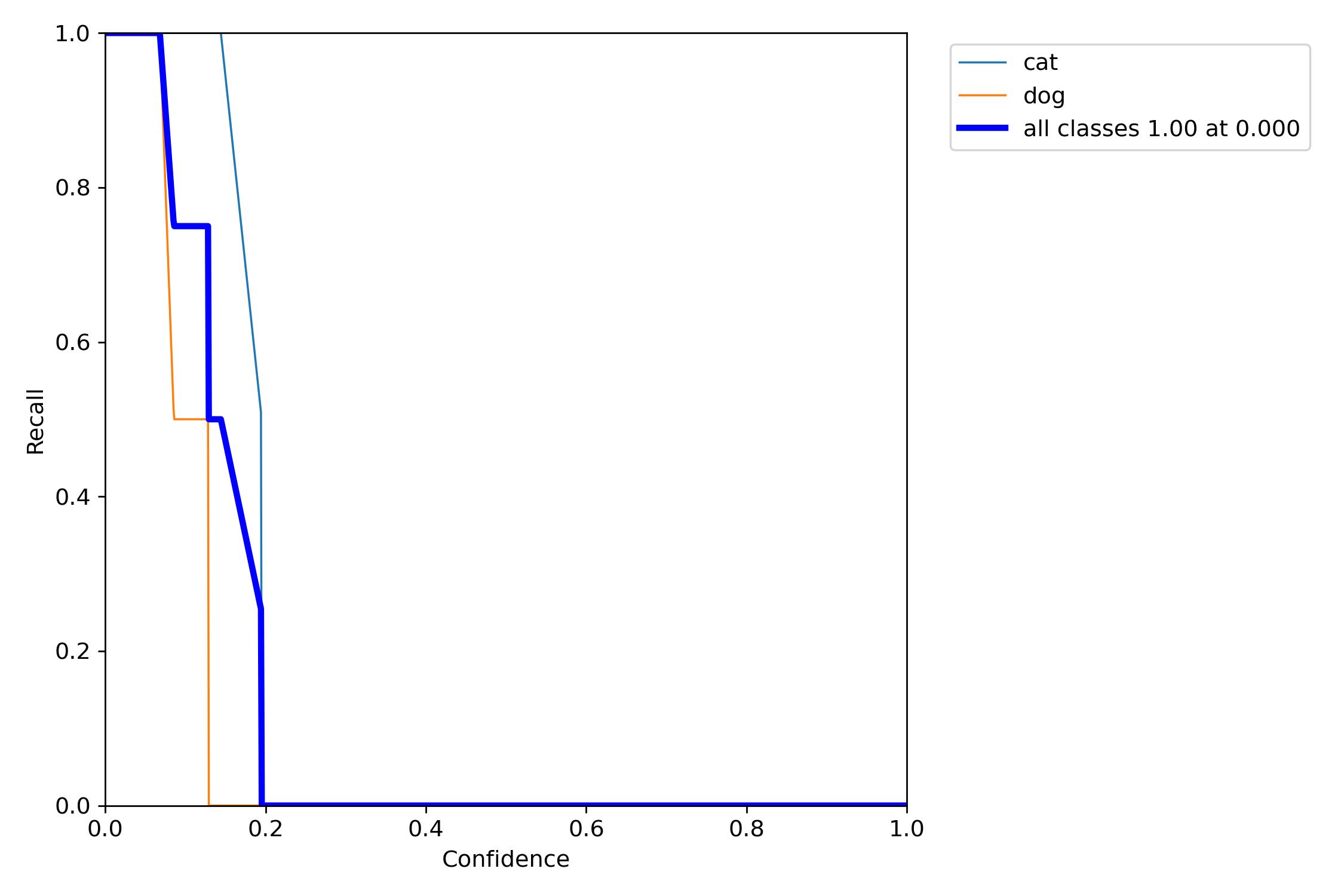
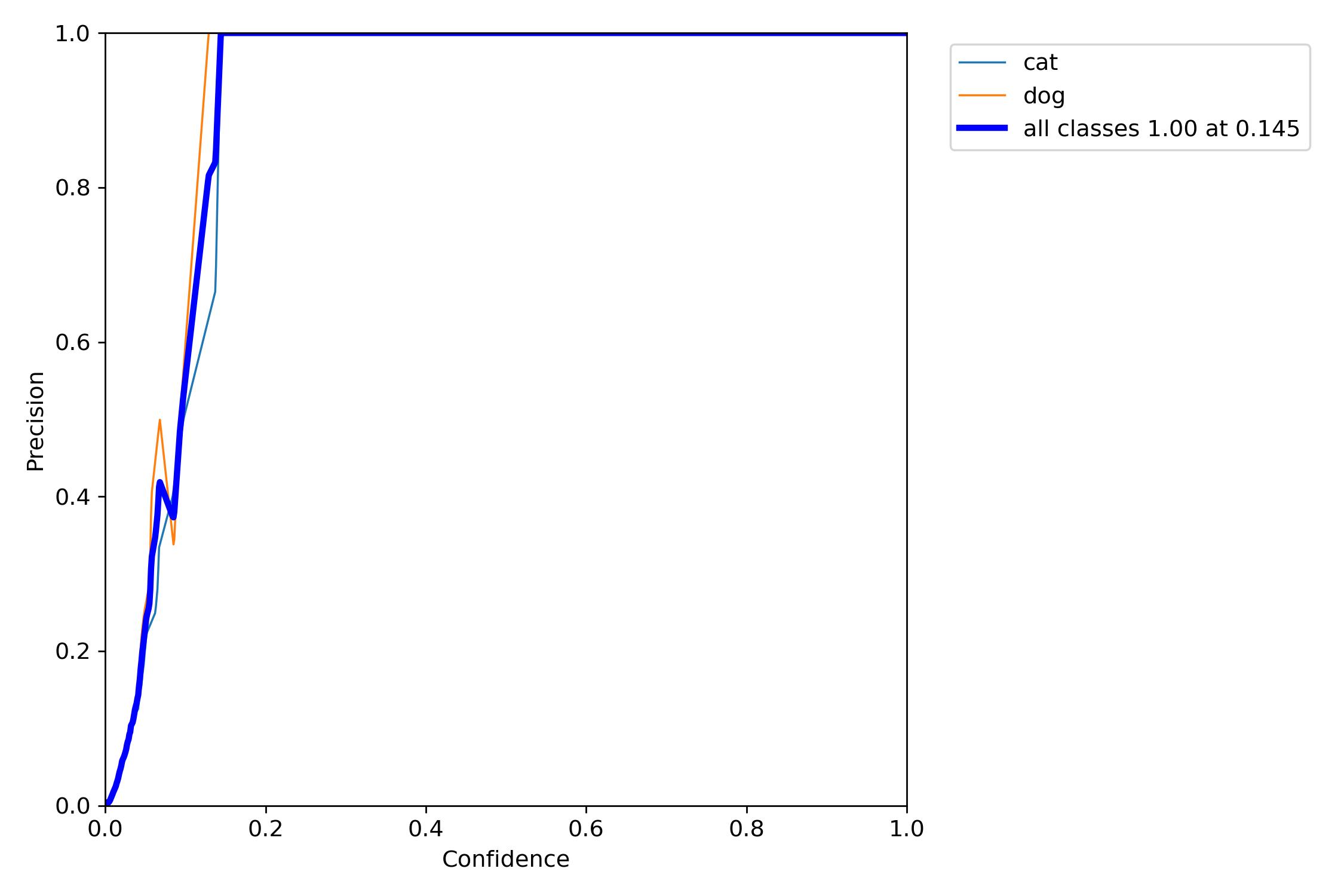
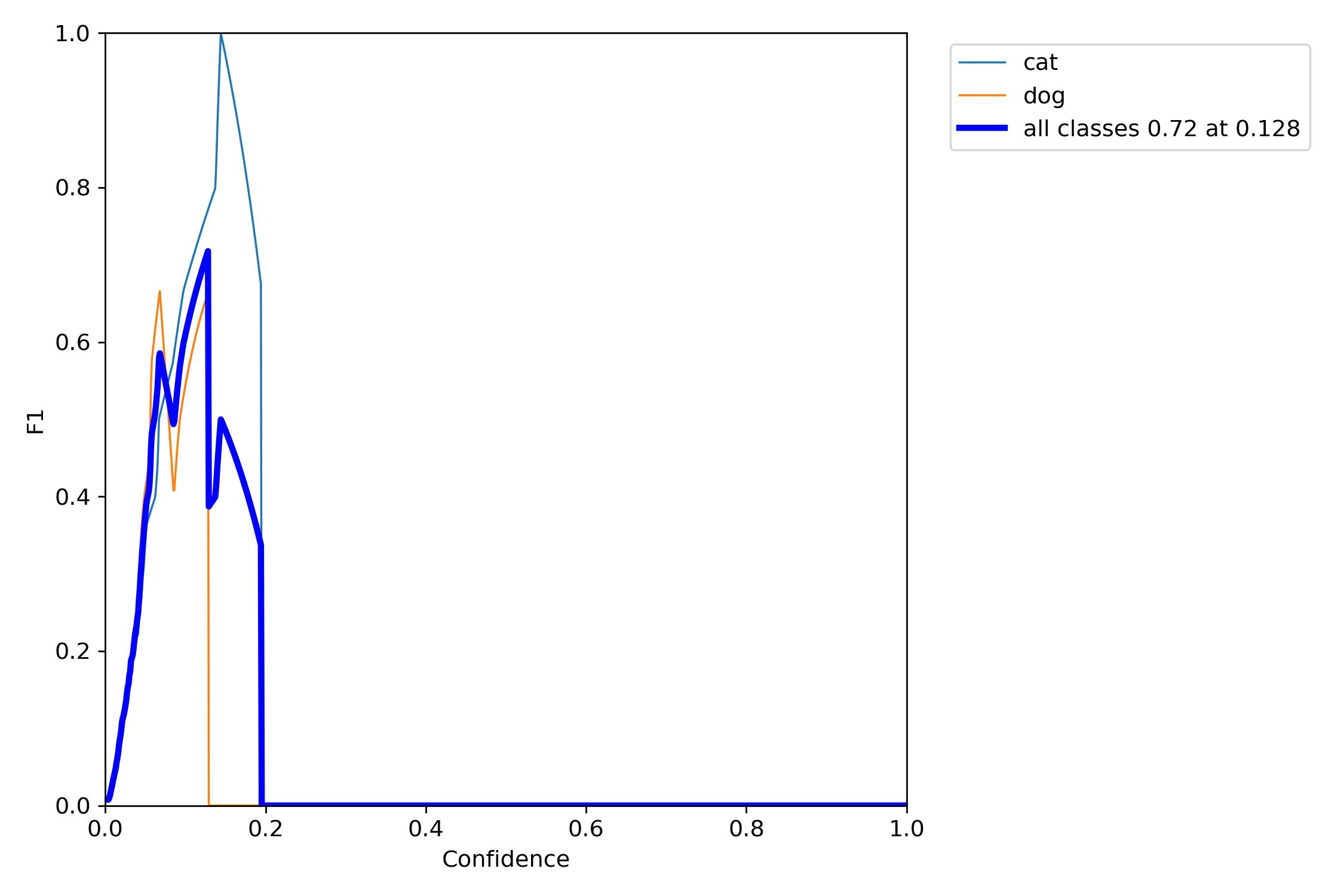
下面,我们来使用图片进行测试,看看训练的效果怎么样。
2、测试
python detect.py --weights runs/train/exp3/weights/best.pt --source data/test/test1.jpg
这是测试的语法:
python detect.py --weights runs/train/exp3/weights/best.pt --source data/test/test1.jpg

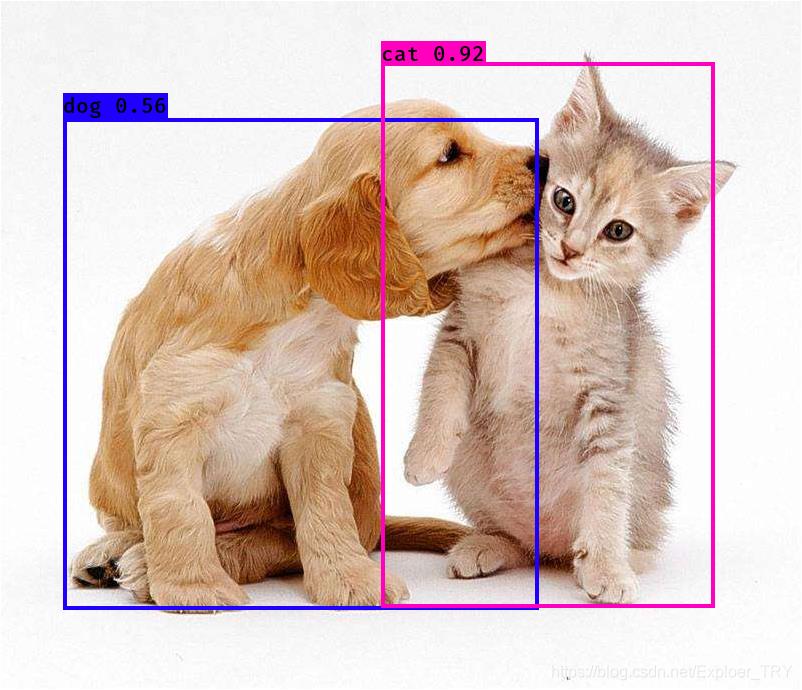
七、总结
以上就是,使用yolov5来训练自己的数据集的一个案例,希望对大家有帮助,最后,谢谢大家的阅读与支持,喜欢的话就点个赞,我一定会再接再厉接着加油的呢。
以上是关于Yolov5--模型文件(yolov5s.yaml)解读和模型修改的主要内容,如果未能解决你的问题,请参考以下文章
YOLOv5源码逐行超详细注释与解读——网络结构yolo.py