k8s容器集群工作负载节点跨越多个云计算厂商
Posted hzwy23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s容器集群工作负载节点跨越多个云计算厂商相关的知识,希望对你有一定的参考价值。
文章目录
1. 背景介绍
随着亚马逊云、阿里云、华为云、腾讯云等云计算服务厂商越来越安全、稳定,以及价格越来越便宜,越来越多的企业或个人开始尝试或正在使用云计算服务厂商提供的IaaS服务替代自建IDC机房中的基础设施资源。面对各个云计算厂商的营销套路,不少企业不知道选哪家云商的服务比较合适,一怕被绑架,上车容易下车难,第一年免费用,第二年没折扣;二怕今年上阿里,明年华为更便宜,后年腾讯更优惠,服务迁移难。如何让业务在不同云商之间随意切换呢?这样就能实现想用哪家的云就选哪家的资源。
下边通过实验的方式尝试一种实现上述诉求的方法,即搭建一套k8s容器集群平台,不同云商上云主机部署工作负载节点,并注册到k8s集群。实现一套容器集群管理多个云商的工作负载节点,于是根据云商的优惠政策,动态的将容器化部署的服务有侧重点的分布到性价比更高的云商上。
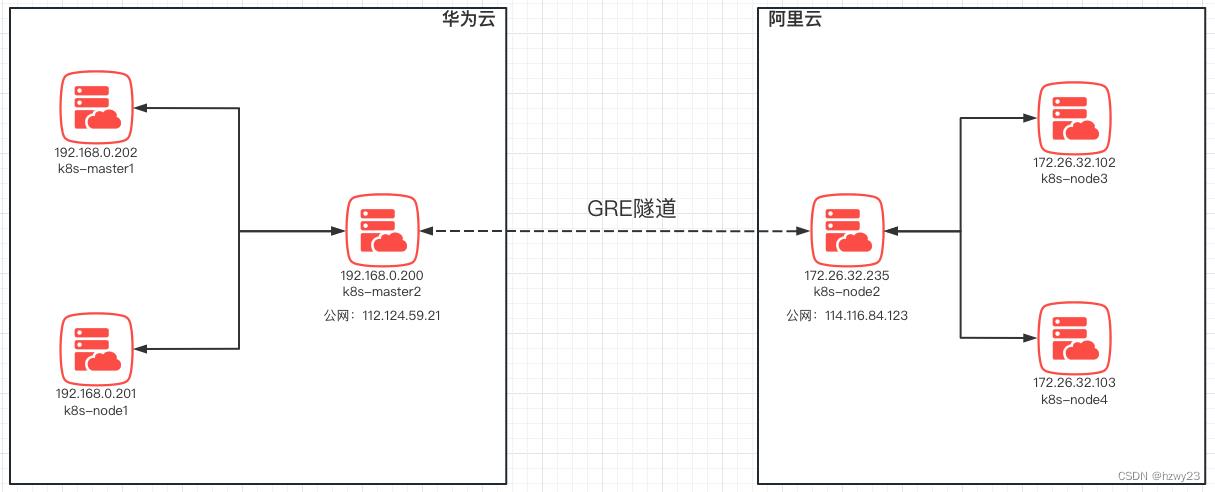
如上图所示,华为云上部署3个节点,阿里云上部署3个节点,其中华为云上 k8s-master1 与 k8s-master2 为 k8s 集群的管理服务,k8s-node1 为 k8s 集群的工作负载节点,阿里云上的 k8s-node2、k8s-node3、k8s-node4 为 k8s 集群的工作负载节点。
2. 跨云商内网打通
通过建立GRE隧道,在华为云 k8s-master2 与阿里云 k8s-node2 节点之间建立 GRE 隧道,打通华为云与阿里云内网通信。同时使用 iptables 设置流量转发规则,例如 k8s-master2 通过设置 iptables 规则将阿里云上的主机对 k8s-master1 与 k8s-node1 的流量进行转发,同理,k8s-node2 通过设置 iptables 规则将华为云上的主机对 k8s-node3 与 k8s-node4 的流量进行转发,从而实现华为云与阿里云上所有主机之间的内网互通。
建立 GRE 隧道的方法请参考 构建GRE隧道打通不同云商的云主机内网 。这篇文章主要介绍了在两个云商之间搭建 GRE 隧道实现两个内网互通的方法。由于使用 route 工具添加的路由并不会持久话的保存(服务器重启将会丢失),所以,本章将会介绍如何搭建 GRE 隧道,并持久话保存。
2.1 阿里云环境安装部署
2.1.1 加载驱动模块
在阿里云 k8s-node2 节点上执行下边命令
cat > /etc/sysctl.d/gre.conf <<EOF
net.ipv4.ip_forward=1
EOF
2.1.2 添加 GRE 隧道开机启动脚本
在阿里云 k8s-node2 节点上执行下边命令
cat > /etc/init.d/gre.sh <<EOF
#!/bin/bash
ip tunnel del tunnel999
ip tunnel add tunnel999 mode gre remote 112.124.59.21 local 172.26.32.235
ip link set tunnel999 up mtu 1476
ip addr add 192.168.100.2 peer 192.168.100.1/32 dev tunnel999
ip route add 192.168.0.0/24 dev tunnel999
EOF
chmod +x /etc/init.d/gre.sh
cat > /usr/lib/systemd/system/gre.service <<EOF
[Unit]
Description=GRE Service
After=network.target
[Service]
Type=oneshot
User=root
ExecStart=/etc/init.d/gre.sh
[Install]
WantedBy=multi-user.target
EOF
systemctl enable gre
systemctl start gre
2.1.3 配置 iptalbes 规则
在阿里云 k8s-node2 节点上执行下边命令
iptables -t nat -A POSTROUTING -o eth0 -s 192.168.100.1 -j MASQUERADE
iptables -A FORWARD -s 192.168.100.1 -o eth0 -j ACCEPT
iptables -t nat -A POSTROUTING -o tunnel999 -s 192.168.0.0/24 -j MASQUERADE
iptables -A FORWARD -s 192.168.0.0/24 -o tunnel999 -j ACCEPT
2.1.4 在其他节点配置路由
在阿里云 k8s-node3 和 k8s-node4 节点上执行下边的命令,添加华为云内网CIDR路由到 k8s-node2 节点内网IP上。
route add -net 192.168.0.0/24 gw 172.26.32.235
添加完成后 k8s-node3 和 k8s-node4 暂时无法访问华为云主机内网IP,等待华为云上安装部署完成后,才可以访问华为云上主机内网IP。
2.2 华为云上安装部署
2.2.1 加载驱动模块
在华为云 k8s-master2 节点上执行下边命令
cat > /etc/sysctl.d/gre.conf <<EOF
net.ipv4.ip_forward=1
EOF
2.2.2 添加 GRE 隧道开机启动脚本
在华为云 k8s-master2 节点上执行下边命令
cat > /etc/init.d/gre.sh <<EOF
#!/bin/bash
ip tunnel del tunnel999
ip tunnel add tunnel999 mode gre remote 114.116.84.123 local 192.168.0.200
ip link set tunnel999 up mtu 1476
ip addr add 192.168.100.1 peer 192.168.100.2/32 dev tunnel999
ip route add 172.26.32.0/24 dev tunnel999
EOF
chmod +x /etc/init.d/gre.sh
cat > /usr/lib/systemd/system/gre.service <<EOF
[Unit]
Description=GRE Service
After=network.target
[Service]
Type=oneshot
User=root
ExecStart=/etc/init.d/gre.sh
[Install]
WantedBy=multi-user.target
EOF
systemctl enable gre
systemctl start gre
2.2.3 配置 iptalbes 规则
在华为云 k8s-master2 节点上执行下边命令
iptables -t nat -A POSTROUTING -o eth0 -s 192.168.100.2 -j MASQUERADE
iptables -A FORWARD -s 192.168.100.2 -o eth0 -j ACCEPT
iptables -t nat -A POSTROUTING -o tunnel999 -s 172.26.32.0/24 -j MASQUERADE
iptables -A FORWARD -s 172.26.32.0/24 -o tunnel999 -j ACCEPT
2.2.4 在其他节点配置路由
在华为云 k8s-master1 和 k8s-node1 节点上执行下边命令,添加阿里云内网CIDR路由到 k8s-master2 节点内网IP上。
route add -net 172.26.32.0/24 gw 192.168.0.200
添加完成后就可以在 k8s-node1 和 k8s-master1 节点上访问阿里云上所有云主机的内网IP,并且阿里云上的所有云主机可以访问华为云上所有云主机的内网IP。
3. 构建K8S集群
首先在华为云上安装部署 kubernetes 集群主节点,具体操作步骤请参考:部署安装kubernetes集群。
4. 容器集群跨云商添加工作负载节点
在阿里云主机上安装 kubernetes worker 节点配置。主要涉及到:Linux 内核升级,Containerd 容器安装,Linux 参数优化,Kubelet与Kube-Proxy 组件部署。下边操作以阿里云 172.26.32.235 主机为例。
4.1 安装Containerd 容器服务
- 在线安装 containerd 服务
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install containerd
- 导出 containerd 默认配置
containerd config default > /etc/containerd/config.toml
- 编辑 /etc/containerd/config.toml 文件
sandbox_image = "registry.k8s.io/pause:3.6"
替换成
sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = false
替换成
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
添加国内镜像仓库,这个非常关键,否则将会导致镜像下载失败,Pod中服务无法启动。
[plugins."io.containerd.grpc.v1.cri".registry]
......
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
在containerd 配置文件中找到上边内容,并在此处添加下边两行, 注意缩进,下边两行内容与上边一行有2个空格的缩进,下边两行内容之间也存在2个空格的缩进。
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn","https://registry.docker-cn.com"]
- 重启 containerd 容器运行时服务
systemctl enable containerd
systemctl restart containerd
4.2 Linux 参数优化
Linux 参数优化请参考 K8S安装过程七:Kubernetes 节点配置调整
4.3 Kubernetes Worker 节点组件安装
4.3.1 获取安装包
从华为云已经安装部署好的节点上获取 kubernetes 的安装包。详细过程请参考:K8S安装过程九:Kubernetes Worker 节点安装
- 获取安装包以及ssl证书。
scp root@192.168.0.200:/opt/kubernetes.tar.gz /opt/
mkdir -p /etc/kubernetes/ssl
scp root@192.168.0.200:/etc/kubernetes/ssl/* /etc/kubernetes/ssl/
cd /opt
tar -xvf kubernetes.tar.gz
mkdir /opt/kubernetes/manifests
4.3.2 kubelet 创建 systemctl 启动服务
cat > /usr/lib/systemd/system/kubelet.service <<EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf
ExecStart=/opt/kubernetes/server/bin/kubelet \\$KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
4.3.3 启动 kubelet
systemctl enable kubelet
systemctl start kubelet
- 查看 kubelet 服务启动状态
systemctl status kubelet

4.3.4 为 kube-proxy 创建 systemctl 启动服务
cat > /usr/lib/systemd/system/kube-proxy.service <<EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.conf
ExecStart=/opt/kubernetes/server/bin/kube-proxy \\$KUBE_PROXY_OPTS
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
4.3.5 启动 kube-proxy 服务
systemctl enable kube-proxy
systemctl start kube-proxy
- 查看 kube-proxy 服务的启动状态
systemctl status kube-proxy

到此,跨越不同云商搭建容器集群完成,此时的容器集群中工作负载节点涵盖了华为云与阿里云。后续添加其他云商的云主机,流程与上述类似。

5. 总结
- 容器集群中工作负载节点跨越多个云商,不同云商之间的服务互相调用实际上走的是公网流量,如果公网带宽资源不足,将会导致跨云服务调用存在性能瓶颈。
- 采用跨云商部署容器集群,建议将不同云商工作负载中运行的业务具备独立性,也即是减少不同云商上服务之间的互相调用。
- 涉及到中间件的使用时,需要考虑跨越云商访问中间件时,保证访问性能。
云计算之路-阿里云上-容器难容:容器服务故障以及自建 docker swarm 集群故障
3月21日,由于使用阿里云服务器自建 docker swarm 集群的不稳定,我们将自建 docker swarm 集群上的所有应用切换阿里云容器服务 swarm 版(非swarm mode)。
3月22日,我们进行移除与重启节点的操作时引发了故障,详见 云计算之路-阿里云上-容器服务:移除节点引发博问站点短暂故障 。
3月24日,我们参考阿里云容器服务帮助文档-指定多节点调度通过给节点添加用户标签的方式成功移除了部分节点。我们是这么操作的,当时所有节点没有添加用户标签,给待移除节点之外的所有节点添加了“group:1”标签,在编排文件的 environment 配置中添加了“constraint:group==1”,对待移除节点上部署的所有应用进行“变更配置”操作(选中“重新调度”)。
3月31日(昨天),16:00 左右,我们再次进行移除节点的操作。由于上次操作时已给所有节点打上了“group:1”标签,这次操作时就需要删除待移除节点的“group:1”标签,然后进行“变更配置”+“重新调度”。但操作后发现不起作用,待移除节点上的所有应用容器纹丝不动。多次操作,一次次仔细检查操作步骤,未发现任何问题,而容器依然与待移除节点在一起,我们似乎听到容器对节点说“You jump, I jump”。被容器与节点在一起的决心所打动,再加上实在找不到其他解决方法,我们决定铤而走险——直接移除这个节点,但这不是盲目的选择,是基于一个前提——这个节点上对应的应用都有2个容器,并且部署在不同的节点上。结果幸运的是冒险成功,节点成功移除,容器与节点比翼双飞,这些应用剩下的部署在其他节点上的容器正常提供服务。
在移除节点后,我们向集群中添加了一个同样配置的新节点。
之后,我们准确对集群中的一个节点进行重启,为了避免重启节点引发故障,我们参考阿里云容器服务帮助文档-容器重新调度在编排文件的 environment 中添加了 “reschedule:on-node-failure”,17: 00 左右重启了节点服务器。
17:20 左右,悲剧开始上演了。。。
一边接到 CPU 报警

一边发现集群上的部分站点 503

一边发现有节点离线

怎么回事?重启节点时,那个被重启节点上的容器被迁移到了配置最低、容器最多的节点上,造成那个节点 CPU 100%,为什么不迁移到新加的节点上?

干脆把这个挂掉的节点移除吧,却发现移除按钮为灰色,不可点,只好重启节点。。。
又发现另外一个低配节点出现同样的问题,但可以移除,先将之移除。。。
在这期间越来越多的站点出现 503 。。。
将开始移除的高配节点加入进来。。。
后来节点逐步恢复了正常,然后一个一个“重新部署”应用,有些应用恢复了。但很多应用不管“重新部署”还是“变更配置”,依然503,虽然阿里云容器服务控制台显示应用正常,其实容器列表中一个容器没有,只能通过容器服务控制台一个一个删除并重新创建应用,重建后容器都起来了,多数应用恢复了正常。但发现有些跑在容器中的内部服务连不上,排查发现集群的服务发现出现了问题,解析出来的 IP 地址与实际运行的容器的 IP 地址不匹配,很可能是解析的是已经删除的容器的 IP 。
被迫无奈,只能赶紧创建 docker swarm 集群,将那些始终无法恢复的应用先迁移过来。
直到 19:30 左右才基本恢复正常。
后来,我们将阿里云容器服务中的所有应用全部迁移回自建 docker swarm 集群。但在 22:35 左右,docker swarm 集群的 2 个 worker 节点宕机造成故障,当时只有 1 manger 节点 2 个 worker 节点,重启 worker 节点后 22:45 左右恢复正常。
然后往集群中加节点,在加第 2 个 manager 节点时,出现下面的错误
The swarm does not have a leader. It\'s possible that too few managers are online. Make sure more than half of the managers are online.
郁闷至极,我们知道 2 个 manager 节点会出现这个问题,但我们是想从 1 个 manager 加到 3 个 manager 节点,必然要经过 2 个 manager ,就那一会就出现了集群群龙无首的问题。
在 23:15 左右再次出现故障,只能重建集群,刚建好集群不久,因为 1 个 manager 节点出现问题又出现故障,最后将这个 manager 节点退出并重新加入集群后,在 23:25 左右恢复正常。
非常抱歉,昨天下午到晚上的故障给您带来了很大的麻烦,请您谅解!
接下来,我们将要采取的应对措施是同时部署多个自建 docker swarm 集群,挂载到同一个负载均衡下,只有所有集群全部宕机才会造成网站访问故障。
以上是关于k8s容器集群工作负载节点跨越多个云计算厂商的主要内容,如果未能解决你的问题,请参考以下文章