Spring处理循环依赖只使用二级缓存可以吗?
Posted 老程不秃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring处理循环依赖只使用二级缓存可以吗?相关的知识,希望对你有一定的参考价值。
什么是循环依赖?
先说一下什么是循环依赖,Spring在初始化A的时候需要注入B,而初始化B的时候需要注入A,在Spring启动后这2个Bean都要被初始化完成
Spring的循环依赖有4种场景
- 构造器的循环依赖(singleton,prototype)
- 属性的循环依赖(singleton,prototype)
「spring目前只支持singleton类型的属性循环依赖」
构造器的循环依赖
@Component
public class ConstructorA
private ConstructorB constructorB;
@Autowired
public ConstructorA(ConstructorB constructorB)
this.constructorB = constructorB;
@Component
public class ConstructorB
private ConstructorA constructorA;
@Autowired
public ConstructorB(ConstructorA constructorA)
this.constructorA = constructorA;
@Configuration
@ComponentScan("com.javashitang.dependency.constructor")
public class ConstructorConfig
public class ConstructorMain
public static void main(String[] args)
AnnotationConfigApplicationContext context =
new AnnotationConfigApplicationContext(ConstructorConfig.class);
System.out.println(context.getBean(ConstructorA.class));
System.out.println(context.getBean(ConstructorB.class));
运行ConstructorMain的main方法的时候会在第一行就报异常,说明Spring没办法初始化所有的Bean,即上面这种形式的循环依赖Spring无法解决。
「构造器的循环依赖,可以在构造函数中使用@Lazy注解延迟加载。在注入依赖时,先注入代理对象,当首次使用时再创建对象完成注入」
@Autowired
public ConstructorB(@Lazy ConstructorA constructorA)
this.constructorA = constructorA;
因为我们主要关注属性的循环依赖,构造器的循环依赖就不做过多分析了
属性的循环依赖
先演示一下什么是属性的循环依赖
@Data
@Component
public class A
@Autowired
private B b;
@Data
@Component
public class B
@Autowired
private A a;
@Configuration
@EnableAspectJAutoProxy
@ComponentScan("com.javashitang.dependency")
public class Config
public class Main
public static void main(String[] args)
AnnotationConfigApplicationContext context =
new AnnotationConfigApplicationContext(Config.class);
System.out.println(context.getBean(A.class).getB() == context.getBean(B.class));
System.out.println(context.getBean(B.class).getA() == context.getBean(A.class));
Spring容器正常启动,运行结果为true,想实现类似的功能并不难,我写个demo演示一下
public class DependencyDemoV1
private static final Map<String, Object> singletonObjects =
new HashMap<>(256);
@SneakyThrows
public static <T> T getBean(Class<T> beanClass)
String beanName = beanClass.getSimpleName();
if (singletonObjects.containsKey(beanName))
return (T) singletonObjects.get(beanName);
// 实例化bean
Object object = beanClass.getDeclaredConstructor().newInstance();
singletonObjects.put(beanName, object);
// 开始初始化bean,即填充属性
Field[] fields = object.getClass().getDeclaredFields();
for (Field field : fields)
field.setAccessible(true);
// 获取需要注入字段的class
Class<?> fieldClass = field.getType();
field.set(object, getBean(fieldClass));
return (T) object;
public static void main(String[] args)
// 假装扫描出来的类
Class[] classes = A.class, B.class;
for (Class aClass : classes)
getBean(aClass);
System.out.println(getBean(A.class).getB() == getBean(B.class));
System.out.println(getBean(B.class).getA() == getBean(A.class));
「在开始后面的内容的时候,我们先明确2个概念」
实例化:调用构造函数将对象创建出来 初始化:调用构造函数将对象创建出来后,给对象的属性也被赋值
可以看到只用了一个map就实现了循环依赖的实现,但这种实现有个小缺陷,singletonObjects中的类有可能只是完成了实例化,并没有完成初始化
而在spring中singletonObjects中的类都完成了初始化,因为我们取单例Bean的时候都是从singletonObjects中取的,不可能让我们获取到没有初始化完成的对象。
所以我们来写第二个实现,「用singletonObjects存初始化完成的对象,而用earlySingletonObjects暂存实例化完成的对象,等对象初始化完毕再将对象放入singletonObjects,并从earlySingletonObjects删除」
public class DependencyDemoV2
private static final Map<String, Object> singletonObjects =
new HashMap<>(256);
private static final Map<String, Object> earlySingletonObjects =
new HashMap<>(256);
@SneakyThrows
public static <T> T getBean(Class<T> beanClass)
String beanName = beanClass.getSimpleName();
if (singletonObjects.containsKey(beanName))
return (T) singletonObjects.get(beanName);
if (earlySingletonObjects.containsKey(beanName))
return (T) earlySingletonObjects.get(beanName);
// 实例化bean
Object object = beanClass.getDeclaredConstructor().newInstance();
earlySingletonObjects.put(beanName, object);
// 开始初始化bean,即填充属性
Field[] fields = object.getClass().getDeclaredFields();
for (Field field : fields)
field.setAccessible(true);
// 获取需要注入字段的class
Class<?> fieldClass = field.getType();
field.set(object, getBean(fieldClass));
singletonObjects.put(beanName, object);
earlySingletonObjects.remove(beanName);
return (T) object;
public static void main(String[] args)
// 假装扫描出来的类
Class[] classes = A.class, B.class;
for (Class aClass : classes)
getBean(aClass);
System.out.println(getBean(A.class).getB() == getBean(B.class));
System.out.println(getBean(B.class).getA() == getBean(A.class));
现在的实现和spring保持一致了,并且只用了2级缓存。spring为什么搞第三个缓存呢?「第三个缓存主要和代理对象相关」
我还是把上面的例子改进一下,改成用3级缓存的实现
public interface ObjectFactory<T>
T getObject();
public class DependencyDemoV3
private static final Map<String, Object> singletonObjects =
new HashMap<>(256);
private static final Map<String, Object> earlySingletonObjects =
new HashMap<>(256);
private static final Map<String, ObjectFactory<?>> singletonFactories =
new HashMap<>(256);
@SneakyThrows
public static <T> T getBean(Class<T> beanClass)
String beanName = beanClass.getSimpleName();
if (singletonObjects.containsKey(beanName))
return (T) singletonObjects.get(beanName);
if (earlySingletonObjects.containsKey(beanName))
return (T) earlySingletonObjects.get(beanName);
ObjectFactory<?> singletonFactory = singletonFactories.get(beanName);
if (singletonFactory != null)
return (T) singletonFactory.getObject();
// 实例化bean
Object object = beanClass.getDeclaredConstructor().newInstance();
singletonFactories.put(beanName, () ->
Object proxy = createProxy(object);
singletonFactories.remove(beanName);
earlySingletonObjects.put(beanName, proxy);
return proxy;
);
// 开始初始化bean,即填充属性
Field[] fields = object.getClass().getDeclaredFields();
for (Field field : fields)
field.setAccessible(true);
// 获取需要注入字段的class
Class<?> fieldClass = field.getType();
field.set(object, getBean(fieldClass));
createProxy(object);
singletonObjects.put(beanName, object);
singletonFactories.remove(beanName);
earlySingletonObjects.remove(beanName);
return (T) object;
public static Object createProxy(Object object)
// 因为这个方法有可能被执行2次,所以这里应该有个判断
// 如果之前提前进行过aop操作则直接返回,知道意思就行,不写了哈
// 需要aop的话则返回代理对象,否则返回传入的对象
return object;
public static void main(String[] args)
// 假装扫描出来的类
Class[] classes = A.class, B.class;
for (Class aClass : classes)
getBean(aClass);
System.out.println(getBean(A.class).getB() == getBean(B.class));
System.out.println(getBean(B.class).getA() == getBean(A.class));
「为什么要包装一个ObjectFactory对象?」
如果创建的Bean有对应的aop代理,那其他对象注入时,注入的应该是对应的代理对象;「但是Spring无法提前知道这个对象是不是有循环依赖的情况」,而正常情况下(没有循环依赖情况),Spring都是在对象初始化后才创建对应的代理。这时候Spring有两个选择:
- 不管有没有循环依赖,实例化后就直接创建好代理对象,并将代理对象放入缓存,出现循环依赖时,其他对象直接就可以取到代理对象并注入(只需要2级缓存,singletonObjects和earlySingletonObjects即可)
- 「不提前创建好代理对象,在出现循环依赖被其他对象注入时,才提前生成代理对象(此时只完成了实例化)。这样在没有循环依赖的情况下,Bean还是在初始化完成才生成代理对象」(需要3级缓存)
「所以到现在为止你知道3级缓存的作用了吧,主要是为了正常情况下,代理对象能在初始化完成后生成,而不用提前生成」
缓存说明singletonObjects第一级缓存,存放初始化完成的BeanearlySingletonObjects第二级缓存,存放实例化完成的Bean,有可能被进行了代理singletonFactories延迟生成代理对象
源码解析
获取Bean的时候先尝试从3级缓存中获取,和我们上面的Demo差不多哈
DefaultSingletonBeanRegistry#getSingleton
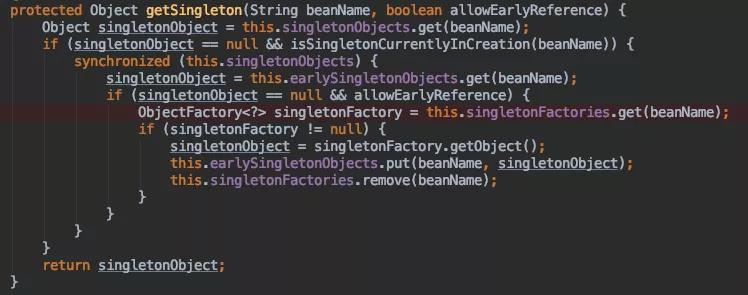
当从缓存中获取不到时,会进行创建 AbstractAutowireCapableBeanFactory#doCreateBean(删除了部分代码哈)
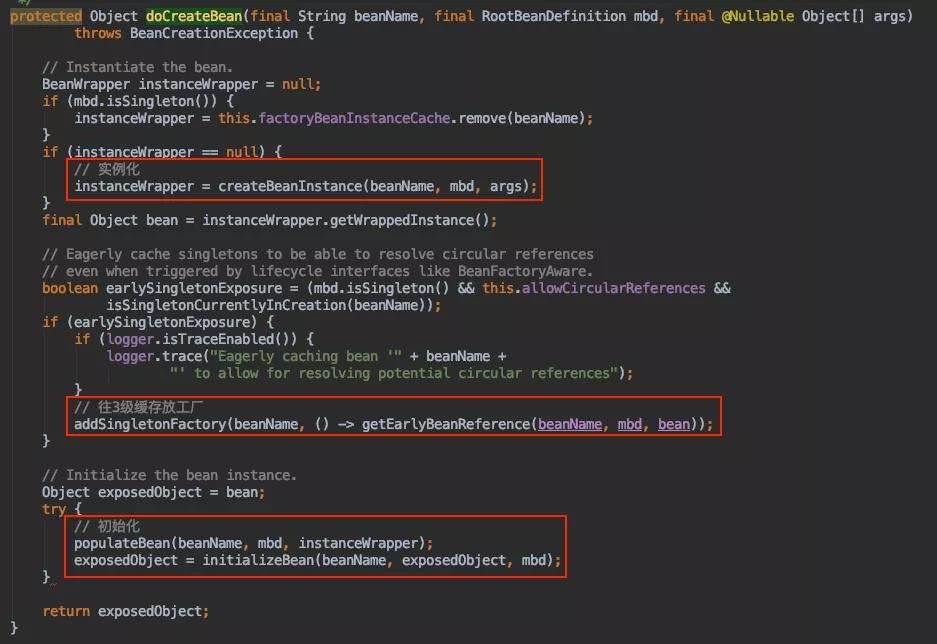
发生循环依赖时,会从工厂里获取代理对象哈
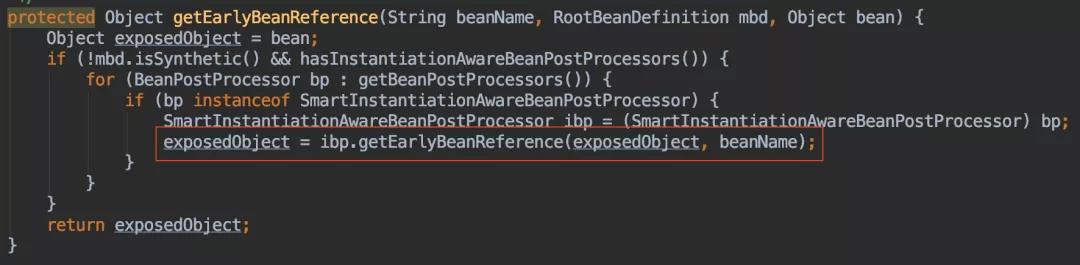
当开启aop代理时,SmartInstantiationAwareBeanPostProcessor的一个实现类有AbstractAutoProxyCreator
AbstractAutoProxyCreator#getEarlyBeanReference

getEarlyBeanReference方法提前进行代理,为了防止后面再次进行代理,需要用earlyProxyReferences记录一下,这个Bean已经被代理过了,不用再代理了
AbstractAutoProxyCreator#postProcessAfterInitialization
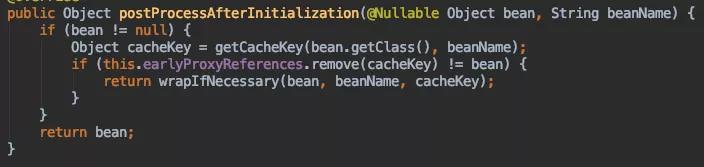
这个方法是进行aop代理的地方,因为有可能提前代理了,所以先根据earlyProxyReferences判断一下,是否提前代理了,提前代理过就不用代理了
当bean初始化完毕,会放入一级缓存,并从二三级缓存删除
DefaultSingletonBeanRegistry#addSingleton
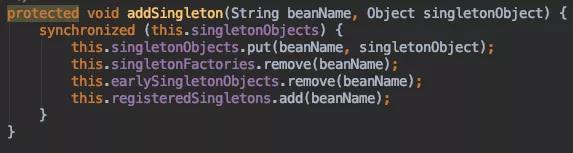
发生循环依赖时,整体的执行流程如下
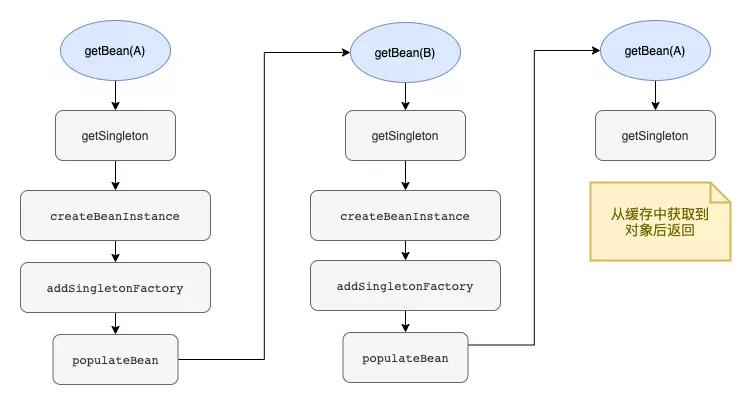
面试题:Spring 为何需要三级缓存解决循环依赖,而不是二级缓存?
-
前言
-
bean生命周期
-
三级缓存解决循环依赖
-
总结

前言
在使用spring框架的日常开发中,bean之间的循环依赖太频繁了,spring已经帮我们去解决循环依赖问题,对我们开发者来说是无感知的,下面具体分析一下spring是如何解决bean之间循环依赖,为什么要使用到三级缓存,而不是二级缓存
bean生命周期
首先大家需要了解一下bean在spring中的生命周期,bean在spring的加载流程,才能够更加清晰知道spring是如何解决循环依赖的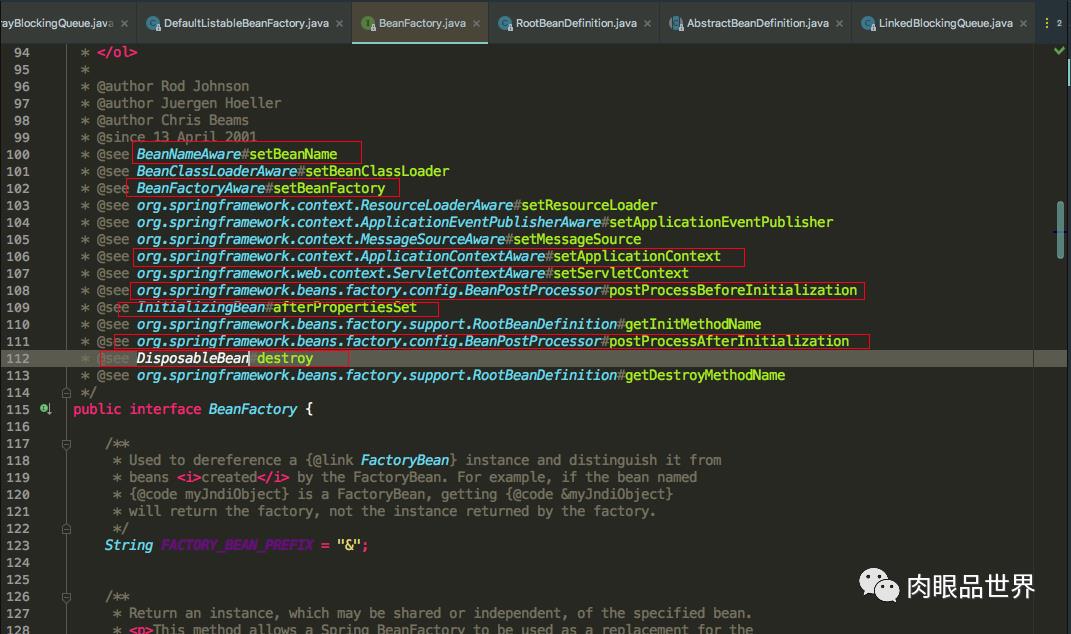 我们在spring的BeanFactory工厂列举了很多接口,代表着bean的生命周期,我们主要记住的是我圈红线圈出来的接口, 再结合spring的源码来看这些接口主要是在哪里调用的
我们在spring的BeanFactory工厂列举了很多接口,代表着bean的生命周期,我们主要记住的是我圈红线圈出来的接口, 再结合spring的源码来看这些接口主要是在哪里调用的

AbstractAutowireCapableBeanFactory类的doCreateBean方法是创建bean的开始,我们可以看到首先需要实例化这个bean,也就是在堆中开辟一块内存空间给这个对象,createBeanInstance方法里面逻辑大概就是采用反射生成实例对象,进行到这里表示对象还并未进行属性的填充,也就是@Autowired注解的属性还未得到注入
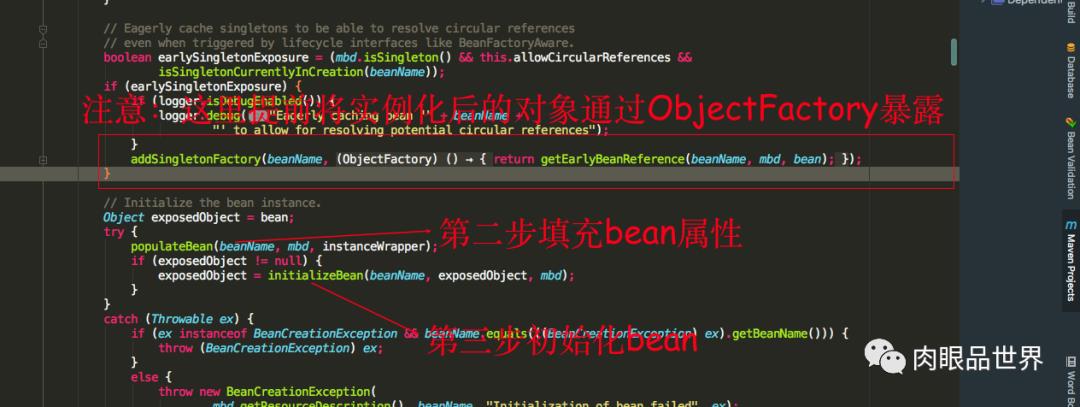
我们可以看到第二步就是填充bean的成员属性,populateBean方法里面的逻辑大致就是对使用到了注入属性的注解就会进行注入,如果在注入的过程发现注入的对象还没生成,则会跑去生产要注入的对象,第三步就是调用initializeBean方法初始化bean,也就是调用我们上述所提到的接口
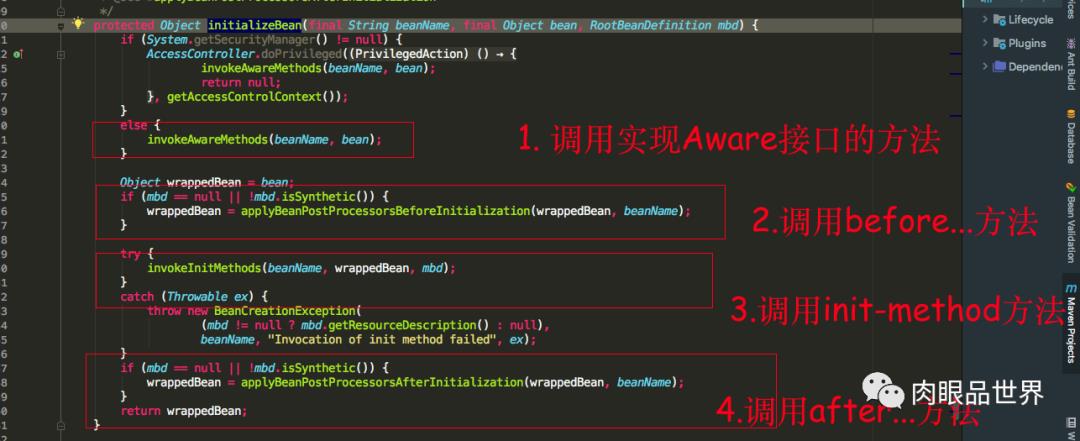
可以看到initializeBean方法中,首先调用的是使用的Aware接口的方法,我们具体看一下invokeAwareMethods方法中会调用Aware接口的那些方法
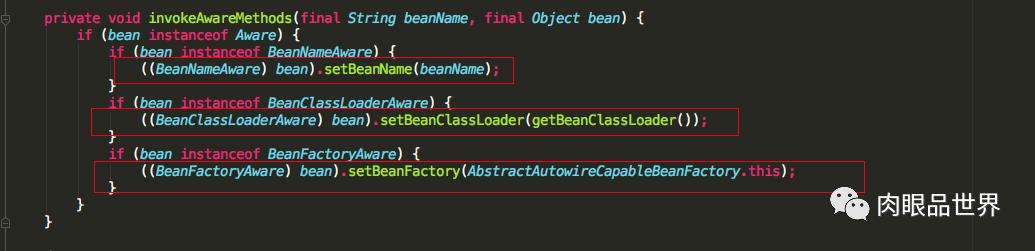
我们可以知道如果我们实现了BeanNameAware,BeanClassLoaderAware,BeanFactoryAware三个Aware接口的话,会依次调用setBeanName(), setBeanClassLoader(), setBeanFactory()方法,再看applyBeanPostProcessorsBeforeInitialization源码

发现会如果有类实现了BeanPostProcessor接口,就会执行postProcessBeforeInitialization方法,这里需要注意的是:如果多个类实现BeanPostProcessor接口,那么多个实现类都会执行postProcessBeforeInitialization方法,可以看到是for循环依次执行的,还有一个注意的点就是如果加载A类到spring容器中,A类也重写了BeanPostProcessor接口的postProcessBeforeInitialization方法,这时要注意A类的postProcessBeforeInitialization方法并不会得到执行,因为A类还未加载完成,还未完全放到spring的singletonObjects一级缓存中。
再看一个注意的点
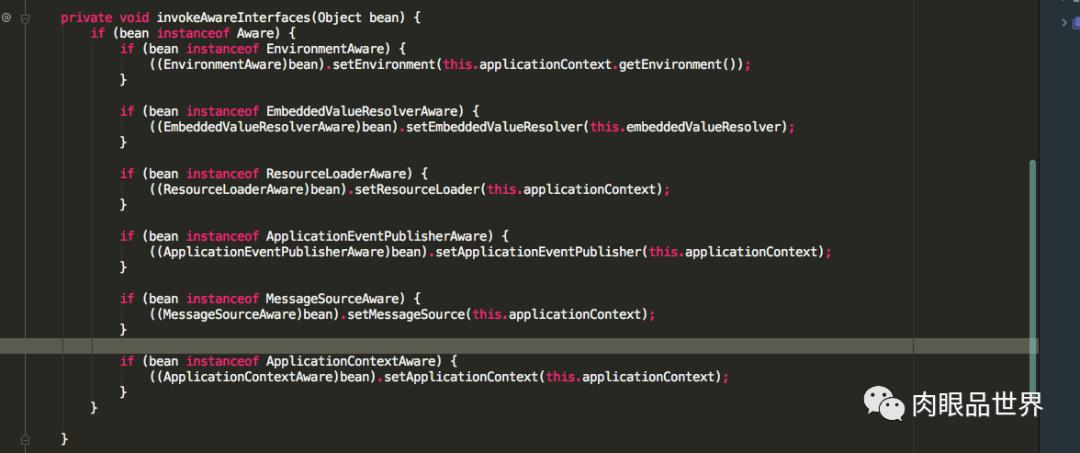
可以看到ApplicationContextAwareProcessor也实现了BeanPostProcessor接口,重写了postProcessBeforeInitialization方法,方法里面并调用了invokeAwareInterfaces方法,而invokeAwareInterfaces方法也写着如果实现了众多的Aware接口,则会依次执行相应的方法,值得注意的是ApplicationContextAware接口的setApplicationContext方法,再看一下invokeInitMethods源码
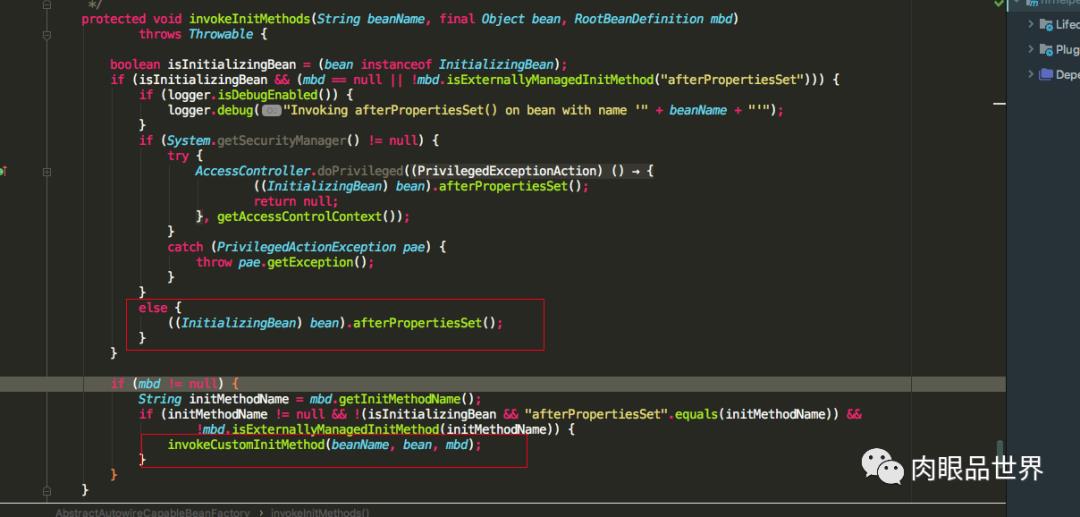
发现如果实现了InitializingBean接口,重写了afterPropertiesSet方法,则会调用afterPropertiesSet方法,最后还会调用是否指定了init-method,可以通过标签,或者@Bean注解的initMethod指定,最后再看一张applyBeanPostProcessorsAfterInitialization源码图

发现跟之前的postProcessBeforeInitialization方法类似,也是循环遍历实现了BeanPostProcessor的接口实现类,执行postProcessAfterInitialization方法。整个bean的生命执行流程就如上面截图所示,哪个接口的方法在哪里被调用,方法的执行流程
最后,对bean的生命流程进行一个流程图的总结

三级缓存解决循环依赖
上一小节对bean的生命周期做了一个整体的流程分析,对spring如何去解决循环依赖的很有帮助。前面我们分析到填充属性时,如果发现属性还未在spring中生成,则会跑去生成属性对象实例
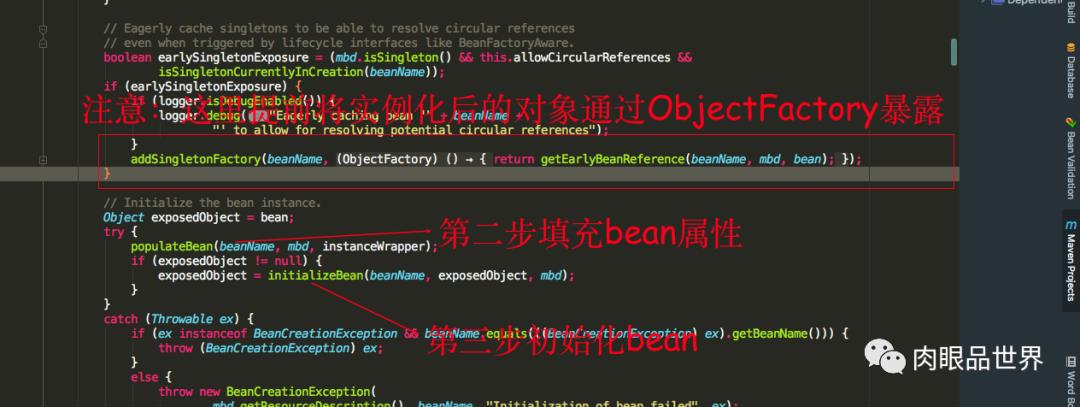
我们可以看到填充属性的时候,spring会提前将已经实例化的bean通过ObjectFactory半成品暴露出去,为什么称为半成品是因为这时候的bean对象实例化,但是未进行属性填充,是一个不完整的bean实例对象

spring利用singletonObjects, earlySingletonObjects, singletonFactories三级缓存去解决的,所说的缓存其实也就是三个Map
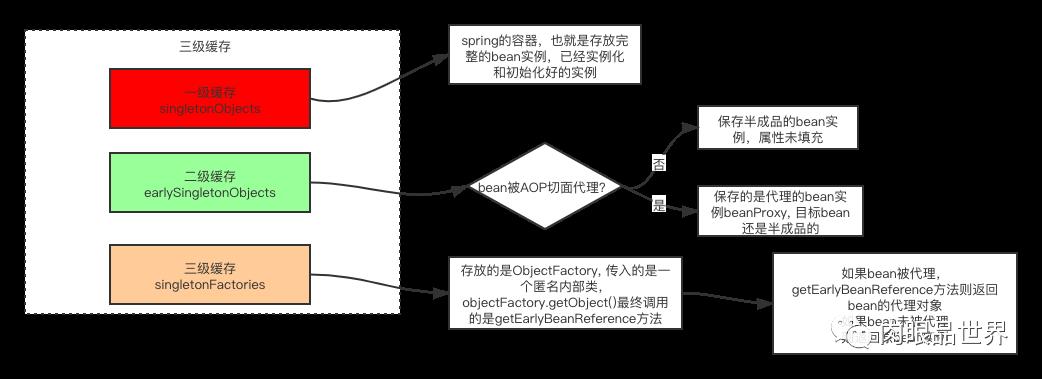
可以看到三级缓存各自保存的对象,这里重点关注二级缓存earlySingletonObjects和三级缓存singletonFactory,一级缓存可以进行忽略。前面我们讲过先实例化的bean会通过ObjectFactory半成品提前暴露在三级缓存中
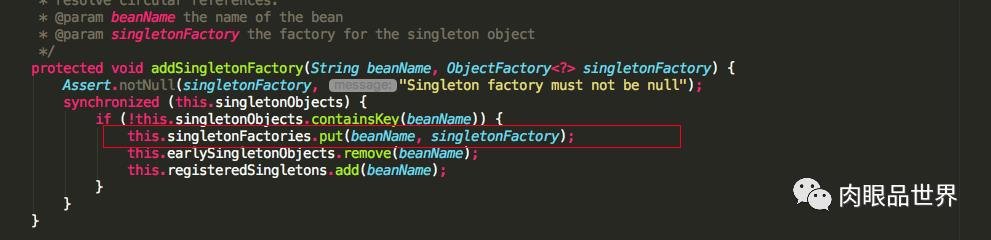
singletonFactory是传入的一个匿名内部类,调用ObjectFactory.getObject()最终会调用getEarlyBeanReference方法。再来看看循环依赖中是怎么拿其它半成品的实例对象的。
我们假设现在有这样的场景AService依赖BService,BService依赖AService
\\1. AService首先实例化,实例化通过ObjectFactory半成品暴露在三级缓存中
\\2. 填充属性BService,发现BService还未进行过加载,就会先去加载BService
\\3. 再加载BService的过程中,实例化,也通过ObjectFactory半成品暴露在三级缓存
\\4. 填充属性AService的时候,这时候能够从三级缓存中拿到半成品的ObjectFactory

拿到ObjectFactory对象后,调用ObjectFactory.getObject()方法最终会调用getEarlyBeanReference()方法,getEarlyBeanReference这个方法主要逻辑大概描述下如果bean被AOP切面代理则返回的是beanProxy对象,如果未被代理则返回的是原bean实例,这时我们会发现能够拿到bean实例(属性未填充),然后从三级缓存移除,放到二级缓存earlySingletonObjects中,而此时B注入的是一个半成品的实例A对象,不过随着B初始化完成后,A会继续进行后续的初始化操作,最终B会注入的是一个完整的A实例,因为在内存中它们是同一个对象。下面是重点,我们发现这个二级缓存好像显得有点多余,好像可以去掉,只需要一级和三级缓存也可以做到解决循环依赖的问题???
只要两个缓存确实可以做到解决循环依赖的问题,但是有一个前提这个bean没被AOP进行切面代理,如果这个bean被AOP进行了切面代理,那么只使用两个缓存是无法解决问题,下面来看一下bean被AOP进行了切面代理的场景
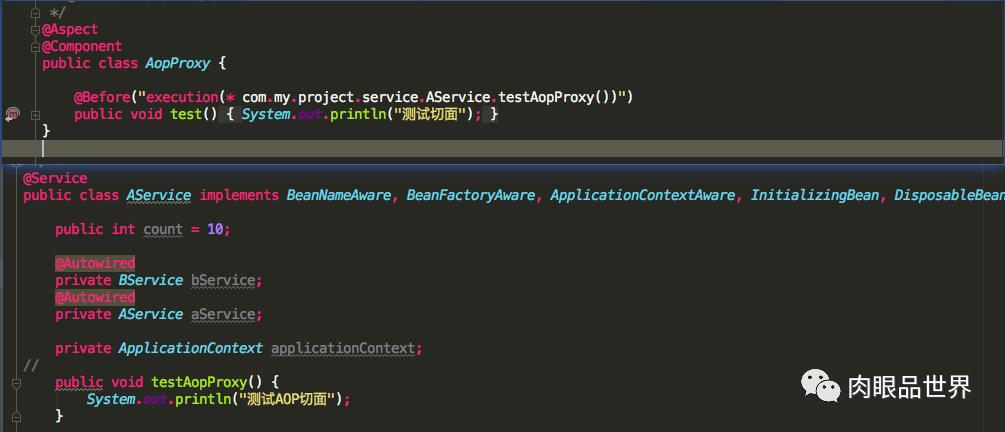
我们发现AService的testAopProxy被AOP代理了,看看传入的匿名内部类的getEarlyBeanReference返回的是什么对象
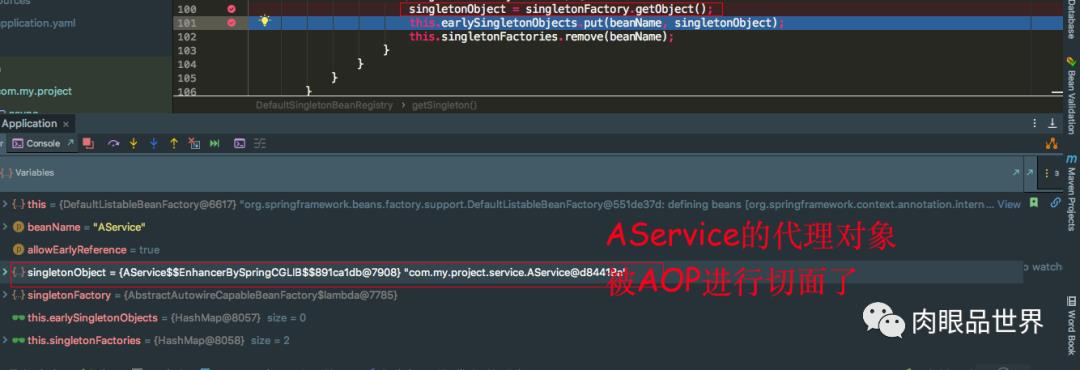
发现singletonFactory.getObject()返回的是一个AService的代理对象,还是被CGLIB代理的。再看一张再执行一遍singletonFactory.getObject()返回的是否是同一个AService的代理对象
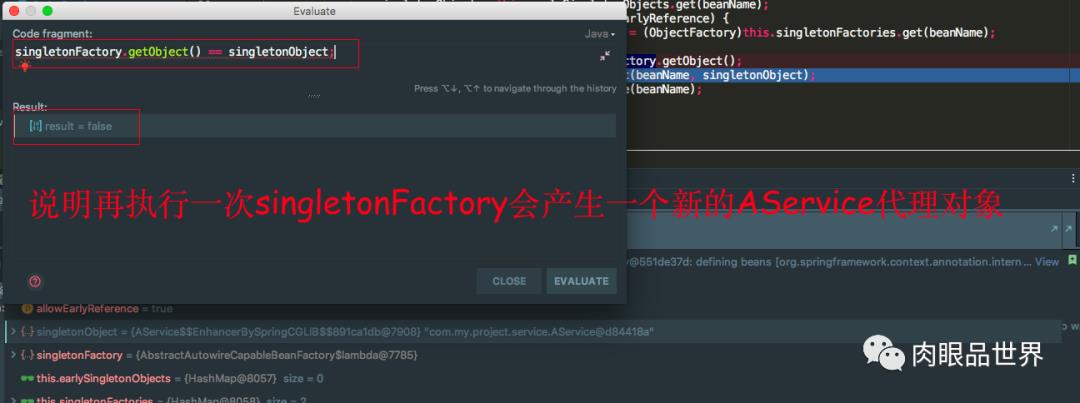
我们会发现再执行一遍singleFactory.getObject()方法又是一个新的代理对象,这就会有问题了,因为AService是单例的,每次执行singleFactory.getObject()方法又会产生新的代理对象,假设这里只有一级和三级缓存的话,我每次从三级缓存中拿到singleFactory对象,执行getObject()方法又会产生新的代理对象,这是不行的,因为AService是单例的,所有这里我们要借助二级缓存来解决这个问题,将执行了singleFactory.getObject()产生的对象放到二级缓存中去,后面去二级缓存中拿,没必要再执行一遍singletonFactory.getObject()方法再产生一个新的代理对象,保证始终只有一个代理对象。还有一个注意的点

既然singleFactory.getObject()返回的是代理对象,那么注入的也应该是代理对象,我们可以看到注入的确实是经过CGLIB代理的AService对象。所以如果没有AOP的话确实可以两级缓存就可以解决循环依赖的问题,如果加上AOP,两级缓存是无法解决的,不可能每次执行singleFactory.getObject()方法都给我产生一个新的代理对象,所以还要借助另外一个缓存来保存产生的代理对象
总结
前面先讲到bean的加载流程,了解了bean加载流程对spring如何解决循环依赖的问题很有帮助,后面再分析到spring为什么需要利用到三级缓存解决循环依赖问题,而不是二级缓存。网上可以试试AOP的情形,实践一下就能明白二级缓存为什么解决不了AOP代理的场景了
在工作中,一直认为编程代码不是最重要的,重要的是在工作中所养成的编程思维。
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)

以上是关于Spring处理循环依赖只使用二级缓存可以吗?的主要内容,如果未能解决你的问题,请参考以下文章