ResNet 基于迁移学习对CIFAR10 数据集的分类
Posted Henry_zhangs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ResNet 基于迁移学习对CIFAR10 数据集的分类相关的知识,希望对你有一定的参考价值。
目录
完整文件下载地址:resnet 基于迁移学习对 CIFAR10 数据集的分类
1. resnet 网络
Resnet 网络的搭建:
import torch
import torch.nn as nn
# residual block
class BasicBlock(nn.Module):
expansion = 1
def __init__(self,in_channel,out_channel,stride=1,downsample=None):
super(BasicBlock,self).__init__()
self.conv1 = nn.Conv2d(in_channel,out_channel,kernel_size=3,stride=stride,padding=1,bias=False) # 第一层的话,可能会缩小size,这时候 stride = 2
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(out_channel,out_channel,kernel_size=3,stride=1,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self,x):
identity = x
if self.downsample is not None: # 有下采样,意味着需要1*1进行降维,同时channel翻倍,residual block虚线部分
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
# bottleneck
class Bottleneck(nn.Module):
expansion = 4 # 卷积核的变化
def __init__(self,in_channel,out_channel,stride=1,downsample=None):
super(Bottleneck,self).__init__()
# 1*1 降维度 --------> padding默认为 0,size不变,channel被降低
self.conv1 = nn.Conv2d(in_channel,out_channel,kernel_size=1,stride=1,bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
# 3*3 卷积
self.conv2 = nn.Conv2d(out_channel,out_channel,kernel_size=3,stride=stride,bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
# 1*1 还原维度 --------> padding默认为 0,size不变,channel被还原
self.conv3 = nn.Conv2d(out_channel,out_channel*self.expansion,kernel_size=1,stride=1,bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
# other
self.relu = nn.ReLU(inplace=True)
self.downsample =downsample
def forward(self,x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
# resnet
class ResNet(nn.Module):
def __init__(self,block,block_num,num_classes=1000,include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64 # max pool 之后的 depth
# 网络最开始的部分,输入是RGB图像,经过卷积,图像size减半,通道变为64
self.conv1 = nn.Conv2d(3,self.in_channel,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1) # size减半,padding = 1
self.layer1 = self.__make_layer(block,64,block_num[0]) # conv2_x
self.layer2 = self.__make_layer(block,128,block_num[1],stride=2) # conv3_x
self.layer3 = self.__make_layer(block,256,block_num[2],stride=2) # conv4_X
self.layer4 = self.__make_layer(block,512,block_num[3],stride=2) # conv5_x
if self.include_top: # 分类部分
self.avgpool = nn.AdaptiveAvgPool2d((1,1)) # out_size = 1*1
self.fc = nn.Linear(512*block.expansion,num_classes)
def __make_layer(self,block,channel,block_num,stride=1):
downsample =None
if stride != 1 or self.in_channel != channel*block.expansion: # shortcut 部分,1*1 进行升维
downsample=nn.Sequential(
nn.Conv2d(self.in_channel,channel*block.expansion,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(channel*block.expansion)
)
layers =[]
layers.append(block(self.in_channel, channel, downsample =downsample, stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1,block_num): # residual 实线的部分
layers.append(block(self.in_channel,channel))
return nn.Sequential(*layers)
def forward(self,x):
# resnet 前面的卷积部分
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# residual 特征提取层
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 分类
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x,start_dim=1)
x = self.fc(x)
return x
# 定义网络
def resnet34(num_classes=1000,include_top=True):
return ResNet(BasicBlock,[3,4,6,3],num_classes=num_classes,include_top=include_top)
def resnet101(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,4,23,3],num_classes=num_classes,include_top=include_top)
这里自定义了resnet34和resnet101网络,区别是更deep的网络,参数会非常多,所以这里对于更深网络的残差块,用1*1卷积进行了降维(bottleneck模块)
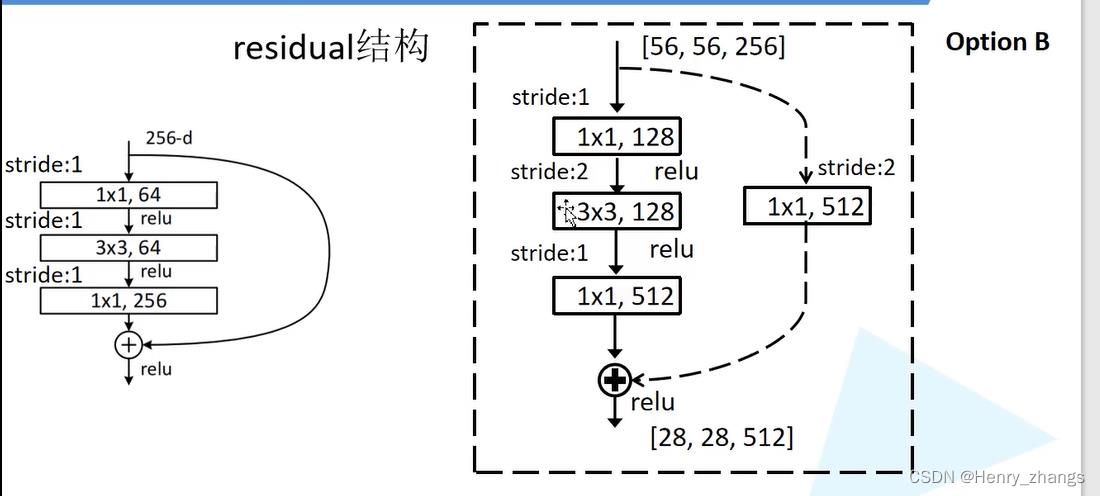
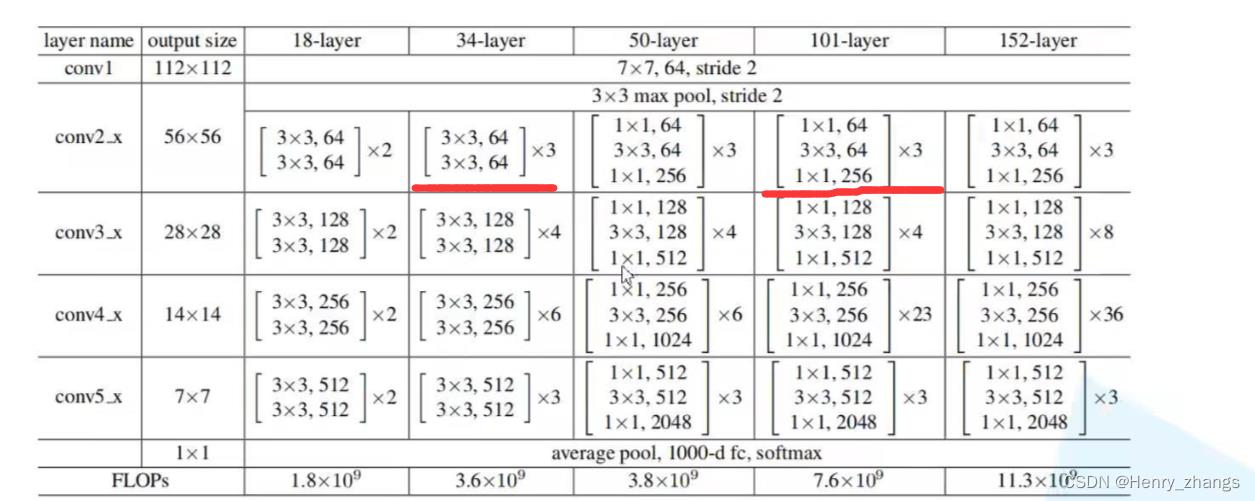
2. 迁移学习-train
这里用了官方提供了预训练权重
2.1 下载预训练权重
首先导入官方定义的模型:
import torchvision.models.resnet然后进入resnet就行了,就可以看到。找不到的话,可以搜索一下 url
这里用的是resnet34 对CIFAR10分类
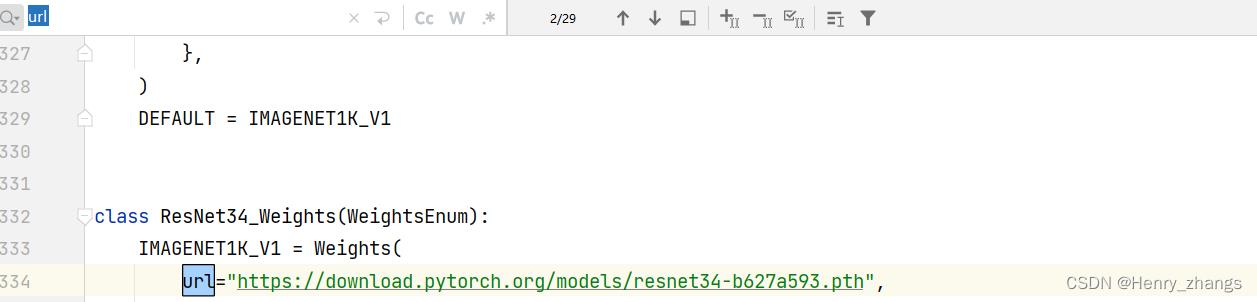
2.2 训练过程
迁移学习的时候,要遵循预处理方式
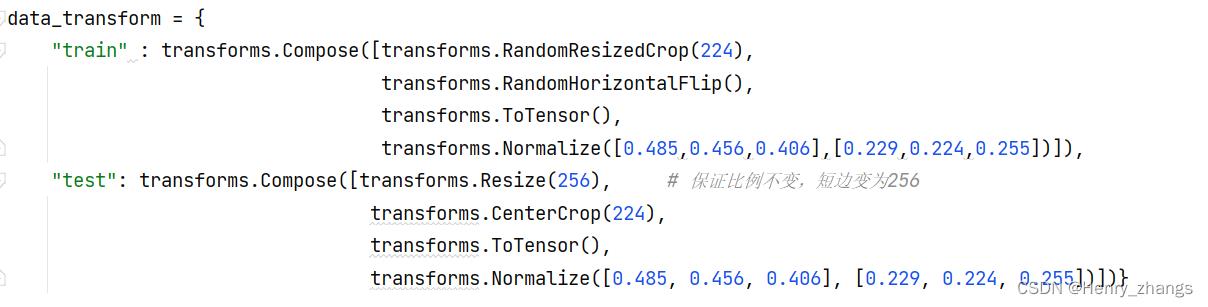
加载预训练权重:
关于迁移学习更为具体的不再本章介绍,后面会单独再写
# 构建网络
net = resnet34() # 不需要设定参数
pre_model = './resnet_pre_model.pth' # 预训练权重
missing_keys,unexpected_keys = net.load_state_dict(torch.load((pre_model)),strict=False)
in_channel = net.fc.in_features # fc
net.fc = nn.Linear(in_channel,10) # 将最后全连接层改变
net.to(DEVICE)这里实例化网络的时候,要按照预训练权重的网络分类1000,加载好权重的时候。找到网络的最后一层,更改为新的全连接层就行
2.3 训练损失+正确率
这里训练的过程较慢,训练了两个epoch就手动停止了

2.4 代码
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from model import resnet34
from torch.utils.data import DataLoader
from tqdm import tqdm
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
data_transform =
"train" : transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.255])]),
"test": transforms.Compose([transforms.Resize(256), # 保证比例不变,短边变为256
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.255])])
# 训练集
trainset = datasets.CIFAR10(root='./data', train=True, download=False, transform=data_transform['train'])
trainloader = DataLoader(trainset, batch_size=16, shuffle=True)
# 测试集
testset = datasets.CIFAR10(root='./data', train=False, download=False, transform=data_transform['test'])
testloader = DataLoader(testset, batch_size=16, shuffle=False)
# 样本的个数
num_trainset = len(trainset) # 50000
num_testset = len(testset) # 10000
# 构建网络
net = resnet34() # 不需要设定参数
pre_model = './resnet_pre_model.pth' # 预训练权重
missing_keys,unexpected_keys = net.load_state_dict(torch.load((pre_model)),strict=False)
in_channel = net.fc.in_features # fc
net.fc = nn.Linear(in_channel,10) # 将最后全连接层改变
net.to(DEVICE)
# 加载损失和优化器
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
best_acc = 0.0
save_path = './resnet.pth'
for epoch in range(5):
net.train() # 训练模式
running_loss = 0.0
for data in tqdm(trainloader):
images, labels = data
images, labels = images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
out = net(images) # 总共有三个输出
loss = loss_function(out,labels)
loss.backward() # 反向传播
optimizer.step()
running_loss += loss.item()
# test
net.eval() # 测试模式
acc = 0.0
with torch.no_grad():
for test_data in tqdm(testloader):
test_images, test_labels = test_data
test_images, test_labels = test_images.to(DEVICE), test_labels.to(DEVICE)
outputs = net(test_images)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == test_labels).sum().item()
accurate = acc / num_testset
train_loss = running_loss / num_trainset
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, train_loss, accurate))
if accurate > best_acc:
best_acc = accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
3. resnet 在 CIFAR10 的预测
展示的结果为: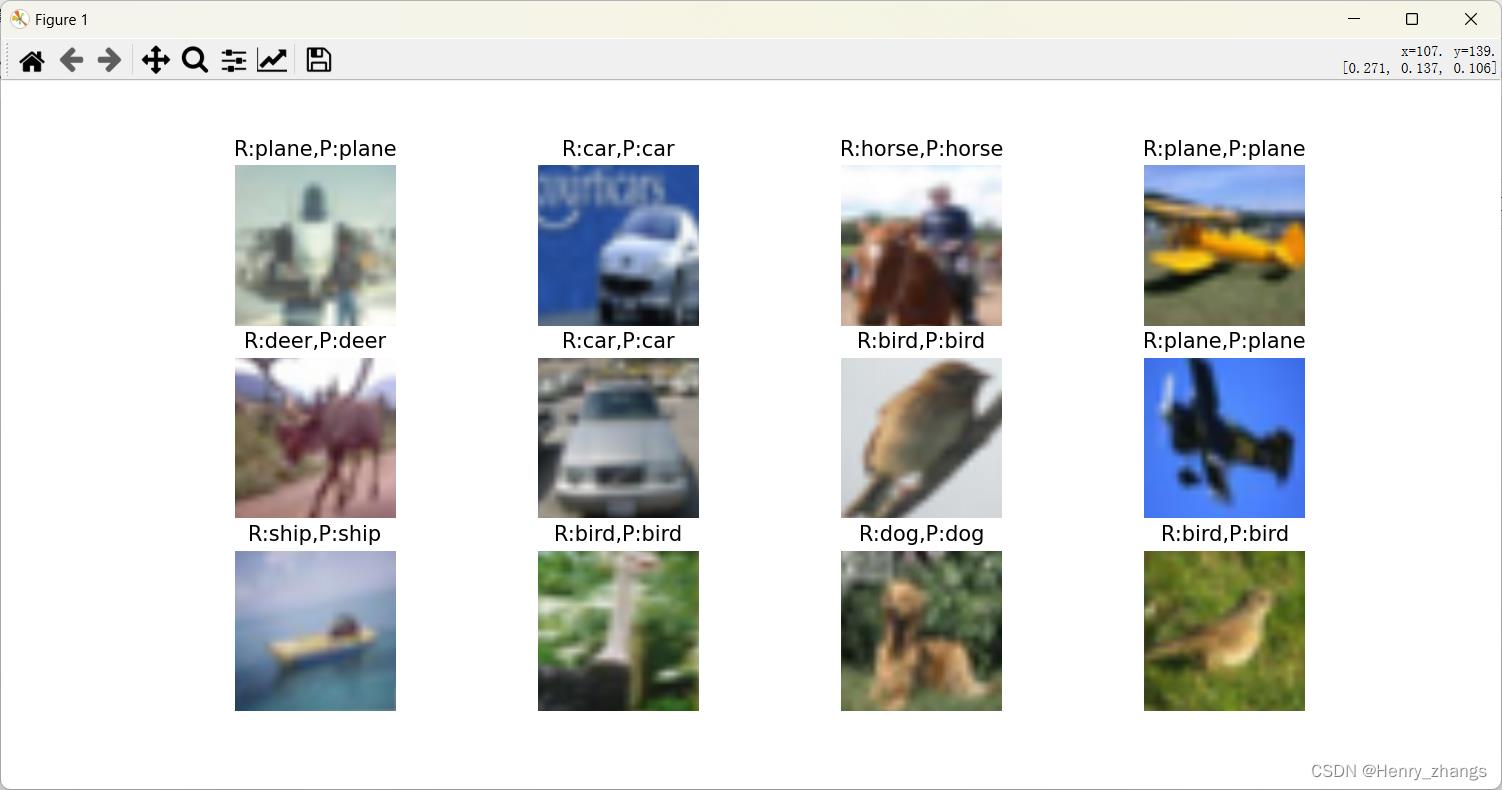
代码:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import torch
import numpy as np
import matplotlib.pyplot as plt
from model import resnet34
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
import torchvision
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 预处理
transformer =transforms.Compose([transforms.Resize(256), # 保证比例不变,短边变为256
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.255])])
# 加载模型
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
model = resnet34(num_classes=10)
model.load_state_dict(torch.load('./resnet.pth'))
model.to(DEVICE)
# 加载数据
testSet = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transformer)
testLoader = DataLoader(testSet, batch_size=12, shuffle=True)
# 获取一批数据
imgs, labels = next(iter(testLoader))
imgs = imgs.to(DEVICE)
# show
with torch.no_grad():
model.eval()
prediction = model(imgs) # 预测
prediction = torch.max(prediction, dim=1)[1]
prediction = prediction.data.cpu().numpy()
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs, labels)):
x = np.transpose(img.data.cpu().numpy(), (1, 2, 0)) # 图像
x[:,:,0] = x[:,:,0] * 0.229 + 0.485 # 去 normalization
x[:,:,1] = x[:,:,1] * 0.224 + 0.456 # 去 normalization
x[:,:,2] = x[:,:,2] * 0.255 + 0.406 # 去 normalization
y = label.numpy().item() # label
plt.subplot(3, 4, i + 1)
plt.axis(False)
plt.imshow(x)
plt.title('R:,P:'.format(classes[y], classes[prediction[i]]))
plt.show()预处理:

加载模型:这里可以之间设置分类是10

展示:这里反归一化的时候,要经过下面的变换

ResNet18迁移学习CIFAR10分类任务(附python代码)
- 实验项目名称:ResNet18迁移学习CIFAR10分类任务
- 实验目的:利用卷积神经网络ResNet18对CIFAR10数据集进行学习与测试,使网络能够完成高准确率的分类任务,最后爬取网页图片进行实际测试。
- 实验原理:
- ResNet网络介绍
-
深度残差网络(Deep residual network, ResNet)由何恺明等人于2015年首次提出,于2016年获得CVPR best paper。
GoogLeNet,VGG等神经网络随着网络深度不断提升,会出现梯度消失,梯度爆炸以及网络退化等问题。ResNet提出残差结构模块并使用Batch Normalization。
Batch Normalization的目的就是使feature map满足均值为0,方差为1的分布规律。批归一化层位于连接层后,非线性激活函数之前,可以有效解决梯度消失与梯度爆炸的问题。
残差结构使用了shortcut连接方式,人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系,其原理图如图3.1.1所示。映射x→H(x)难以学习,通过使H(x)=F(x)+x,F(x)就是输入与输出之间的残差,将学习任务转变为学习映射x→F(x)。
ResNet在上百层都有很好的表现,但是当达到上千层了之后仍然会出现退化现象。
- 损失函数
-
交叉熵损失(cross entropy):用来判定实际的输出与期望的输出的接近程度。其数学计算公式如下,其中概率分布p为期望输出,概率分布q为实际输出。

由于希望输出为one-hot向量,所以计算可简化为:

- 图像预处理
-
CIFAR10数据集共10个类别(飞机,小轿车,鸟,猫,鹿,狗,青蛙,马,船,卡车),图片为3*32*32大小,共50000张训练图片以及10000张测试图片。由于ResNet18网络input为3*224*224的图片,故利用torchvision的transforms模块将3*32*32的原图像resize成3*224*224。
- 实验内容
- 训练集,验证集,测试集
-
将CIFAR10数据集的测试样本进行1:1随机划分出验证集与测试集,从而训练集50000张图片,验证集,测试集各5000张图片,训练集:验证集:测试集=10:1:1。
- 利用50000张训练样本进行首轮训练
-
超参数设计如下表:
超参
值
epoch
12
batch_size
32
learning rate
0.001
优化
随机梯度下降
Momentum
0.9
-

loss变化情况 -
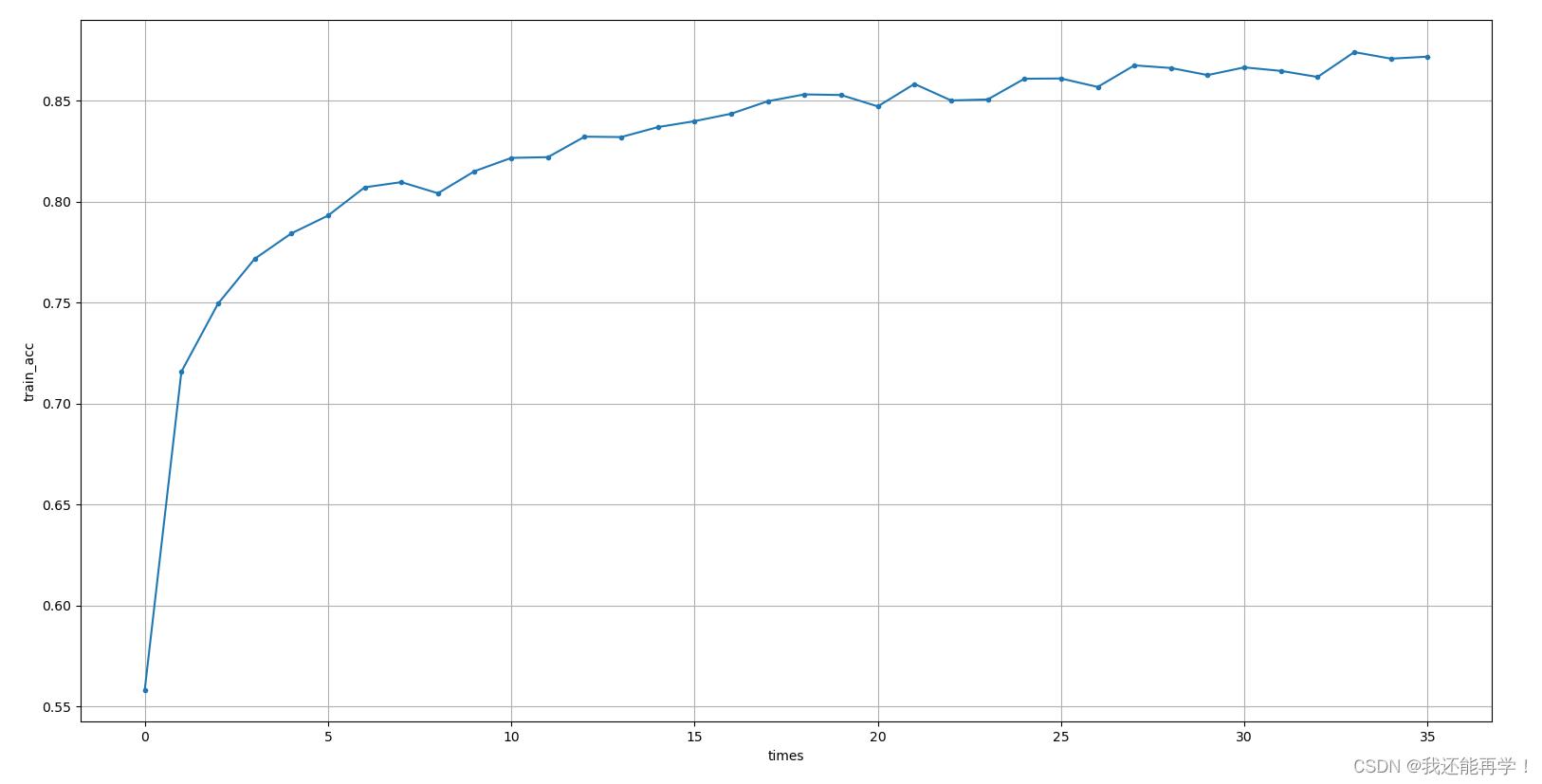
train_acc变化情况 
验证集正确率变化情况 验证集正确率可达94.78%。 笔者后续进行了调参处理进行进一步优化训练,验证集正确率可达95.7%并无过拟合现象,但验证集准确率高并不意味着模型就更优,故在此不多加赘述。
- 实验结果
- 测试集测试模型效果
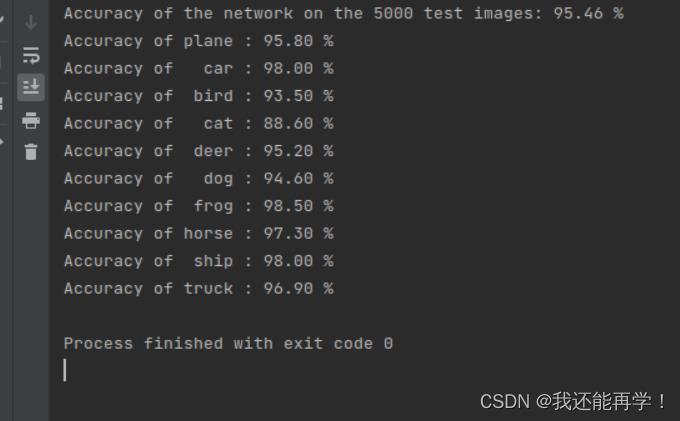
爬取网图进行识别任务
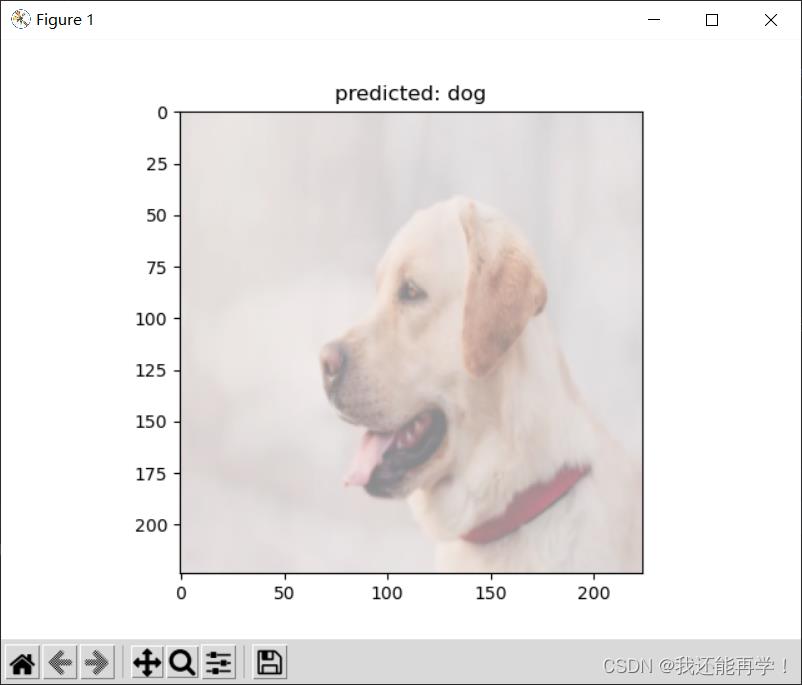
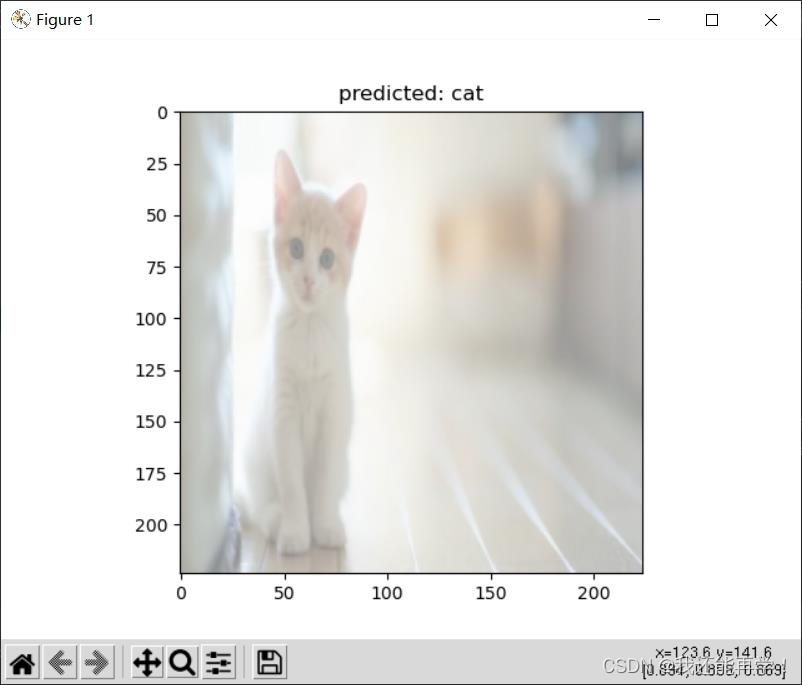

利用requests爬取狗,猫,鸟三类图片,随机选取部分图片进行测试,基本准确分类出图片类别。列举的三张图分别是狗的侧脸照,猫信息较少图片噪声大的照片以及与鸟特征相对差异较大的鹦鹉照片,得出分类结果均正确,故分类器分类效果泛化能力较强。
- Python代码实现
- download dataset.py
import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) trainset = torchvision.datasets.CIFAR10(root='./dataset/train', train=True,download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='./dataset/test', train=False,download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') def imshow(img): img = img / 2 + 0.5 npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() dataiter = iter(trainloader) images, labels = dataiter.next() imshow(torchvision.utils.make_grid(images)) print(' '.join('%5s' % classes[labels[j]] for j in range(4))) - train.py
import torch.optim as optim import torch.nn as nn import torch import torchvision.transforms as transforms import torchvision import os import scipy.io as scio import numpy as np import time from torchvision import models os.environ["CUDA_VISIBLE_DEVICES"] = "0" transform = transforms.Compose( [transforms.RandomResizedCrop(224), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) trainset = torchvision.datasets.CIFAR10(root='./dataset/train', train=True, download=False, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=2) net = models.resnet18(pretrained=True) inchannel = net.fc.in_features net.fc = nn.Linear(inchannel, 10) print(net) net.cuda() resume="./ResNet/model/lr_0.001epoch_11_iters_1499.model" if resume is not None: print('Resuming, initializing using weight from .'.format(resume)) net.load_state_dict(torch.load(resume)) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) lr = 0.001 all_loss = [] all_acc = [] all_train_acc = [] print("start training.....") for epoch in range(12): net.train() running_loss = 0.0 train_acc = 0.0 for i, data in enumerate(trainloader, 0): inputs, labels = data inputs = inputs.cuda() labels = labels.cuda() optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() train_acc += (outputs.argmax(1) == labels).sum().item() if (i + 1) % 500 == 0: print('[%d, %5d] loss: %.5f train_acc: %2f' % (epoch + 1, i + 1, running_loss / 500, train_acc / 500 / 32)) all_loss.append(running_loss / 500) all_train_acc.append(train_acc) running_loss = 0.0 train_acc = 0.0 # save model net.eval() net.cpu() save_model_dir = "./ResNet/model" if os.path.exists(save_model_dir) is False: os.mkdir(save_model_dir) save_model_filename = "lr_" + str(lr) + "epoch_" + str(epoch) + "_iters_" + str(i) + ".model" save_model_path = os.path.join(save_model_dir, save_model_filename) torch.save(net.state_dict(), save_model_path) # save loss all_loss_total = np.array(all_loss) save_loss_dir = "./ResNet/loss" if os.path.exists(save_loss_dir) is False: os.mkdir(save_loss_dir) loss_filename_path = "lr_" + str(lr) + "epoch_" + str(epoch) + "_iters_" + str(i) + ".mat" save_loss_path = os.path.join(save_loss_dir, loss_filename_path) scio.savemat(save_loss_path, 'loss_total': all_loss_total) # save train_acc all_train_acc_total = np.array(all_train_acc) save_train_acc_dir = "./ResNet/train_acc" if os.path.exists(save_train_acc_dir) is False: os.mkdir(save_train_acc_dir) train_acc_filename_path = "lr_" + str(lr) + "epoch_" + str(epoch) + "_iters_" + str(i) + ".mat" save_train_acc_path = os.path.join(save_train_acc_dir, train_acc_filename_path) scio.savemat(save_train_acc_path, 'train_acc_total': all_train_acc_total) net.train() net.cuda() print("time:".format(time.ctime())) net.eval() net.cpu() # save final model save_model_dir = "./ResNet/model" save_model_filename = "lr_" + str(lr) + "epochs_" + str(epoch + 1) + "final.model" save_model_path = os.path.join(save_model_dir, save_model_filename) torch.save(net.state_dict(), save_model_path) print('Finished Training') - val.py
import torch import torchvision import torch.nn as nn import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np from torchvision import models import glob import os import scipy.io as scio def imshow(img): img = img / 2 + 0.5 npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') testset = torchvision.datasets.CIFAR10(root='./dataset/test', train=False,download=False, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2) all_acc = [] num = 0 net = models.resnet18() inchannel = net.fc.in_features net.fc = nn.Linear(inchannel, 10) #net.load_state_dict(torch.load("./ResNet/model/lr_0.001epoch_22_iters_499.model")) path = "./ResNet/model" for model_path in glob.glob(path+'/*.model'): num += 1 net.load_state_dict(torch.load(model_path)) correct = 0 total = 0 with torch.no_grad(): for i, data in enumerate(testloader, 0): if i < 1250: images, labels = data images = images.cuda() labels = labels.cuda() net.eval() net = net.cuda() outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 5000 test images: %d %%' % ( 100 * correct / total)) # save_acc acc = correct / total all_acc.append(acc) all_acc_total = np.array(all_acc) save_acc_dir = "./ResNet/val_acc" if os.path.exists(save_acc_dir) is False: os.mkdir(save_acc_dir) acc_filename_path = "num_" + str(num) + ".mat" save_acc_path = os.path.join(save_acc_dir, acc_filename_path) scio.savemat(save_acc_path, 'val_acc_total': all_acc_total) - visualization.py
import scipy.io as scio import matplotlib.pyplot as plt loss_path = ".\\loss\\lr_0.0001epoch_11_iters_1499.mat" data = scio.loadmat(loss_path) loss_data = data["loss_total"] x = range(len(loss_data[0])) y = loss_data[0] plt.ylabel('loss') plt.xlabel('times') plt.plot(x, y, '.-') plt.grid()
如有错误的地方,还请指正!有疑惑的同学可以在评论区留言,无论能否解决,笔者看到一定回复。
以上是关于ResNet 基于迁移学习对CIFAR10 数据集的分类的主要内容,如果未能解决你的问题,请参考以下文章