30道python自动化测试面试题
Posted 晚凉日记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了30道python自动化测试面试题相关的知识,希望对你有一定的参考价值。
文章目录
- 1、什么项目适合做自动化测试?
- 2、什么是 PO 模式?
- 3、PO 模式的封装原则有哪些?
- 4、 Python 中 *args 和 **kwargs 的作用?
- 5、Python 中的垃圾回收机制是什么?
- 6、selenium中隐藏元素如何定位?
- 7、关闭浏览器中quit和close的区别
- 8、举例一下你遇到过那些异常
- 9 、如何处理alert弹窗?
- 10、在selenium中如何处理多窗口?
- 11、selenium中如何判断元素是否存在?
- 12、自动化中有哪三类等待?他们有什么特点?
- 13、selenium中如何保证操作元素的成功率?也就是说如何保证点击的元素一定是可以点击的?
- 14、如何提高selenium脚本的执行速度?
- 15、用例在运行过程中经常会出现不稳定的情况,也就是说这次可以通过,下次就没办法通过了,如何去提升用例的稳定性?
- 16、你的自动化用例的执行策略是什么?
- 17、什么是持续集成?
- 18、自动化测试的时候是不是需要连接数据库做数据校验?
- 19、有几种元素常用定位方式,分别是?你最偏爱哪一种,为什么?
- 20、如何去定位页面上动态加载的元素?
- 21、点击链接以后,selenium是否会自动等待该页面加载完毕?
- 22、webdriver client的原理是什么?
- 23、webdriver的协议是什么?
- 24、启动浏览器的时候用到的是哪个webdriver协议?
- 25、怎样去选择一个下拉框中的value=xx的option?
- 26、Python 中常见的可变参数类型和不可变参数类型,都有哪些?
- 27、如何在定位元素后高亮元素(以调试为目的)?
- 28、什么是断言?
- 29/自动化测试过程中,你遇到了哪些问题,是如何解决的?
- 30、如何模拟浏览器的前进、后退、刷新操作
1、什么项目适合做自动化测试?
关键字:不变的、重复的、规范的
1)任务测试明确,需求不会频繁变动
2)项目周期要足够长
3)自动化测试脚本可重复使用,比如:比较频繁的回归测试
4)被测软件系统开发比较规范,能够保证系统的可测试性
5)软件系统界面稳定,变动少
6)项目进度压力不太大
2、什么是 PO 模式?
是指把一个具体的页面转化为编程语言当中的一个对象,页面特性转化成对象属性,页面操作转化为对象方法。
1)通俗来讲把每个页面当成一个对象,页面层写定位元素方法和页面操作方法
2)用例层从页面层调用操作方法,写成用例
3)可以做到定位元素与脚本的分离
4)主要用来实现对页面操作和测试逻辑的一个分离
3、PO 模式的封装原则有哪些?
1)要封装页面中的功能或服务,比如点击页面元素,可以进入到新的页面,则可为这个服务封装方法"进入新页面"
2)封装细节,对外只提供方法名或者接口,尽量不要暴露页面的内部
3)封装的操作细节中不要使用断言,把断言放到单独的模块中,
4)点击一个按钮会开启新的页面,可以用return方法跳转,比如return MainPage()表示跳转到主页
5)整个 PO 你不需要封装整个页面的行为,用到什么逻辑就封装什么
6)一个动作可能产生不同结果,比如点击按钮后,可能成功,也可能失败,为两种结果封装两个方法:click_success和click_error
4、 Python 中 *args 和 **kwargs 的作用?
都是不定长参数,解决参数不固定问题。
args是非关键字参数,用于元组;kwargs是关键字参数 (字典)
也就是说args表示任何多个无名参数,然而kwags表示一个有着对应关系的关键字参数。
在使用的时候需要注意,*args要在**kwags之前,不然会发生语法错误。
5、Python 中的垃圾回收机制是什么?
垃圾回收机制(Garbage Collection),简称GC,是Python解释器自带的机制,专门用来进行垃圾回收。
在定义一个变量时,会申请内存空间,当该变量使用完毕,也应该释放掉该变量所占用的内存空间,Python则由GC机制进行回收。
无论何种垃圾回收机制,一般都分为两个阶段:垃圾检测和垃圾回收。
垃圾检测,就是区分已分配内存中的“可回收”和“不可回收”内存。
垃圾回收,则是使操作系统重新掌握垃圾检测阶段所标识出来的可回收内存块。
所谓垃圾回收,并不是直接把这块内存的数据直接清空了,而是将使用权重新交给了操作系统,不会应用程序霸占了。
什么是垃圾
1)当一个变量调用完毕,且后续不再需要时,便是垃圾。
2)当指向该变量地址的变量名指向另一个地址时,原变量内存地址无法被访问,此时该变量也是垃圾。
6、selenium中隐藏元素如何定位?
首先selenium是无法操作隐藏元素的(但是能正常定位到),本身这个框架就是设计如此,如果非要去操作隐藏元素,那就用js的方法去操作,selenium提供了一个入口可以执行js脚本。
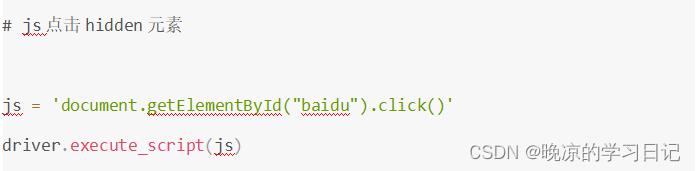
元素的属性隐藏和显示,主要是 type="hidden"和style="display: none;"属性来控制的。
7、关闭浏览器中quit和close的区别
简单来说,两个都可以实现退出浏览器session功能。
close只会关闭浏览器,而quit关闭全部浏览器的同时,也会杀掉驱动进程
8、举例一下你遇到过那些异常
ElementNotSelectableException :元素不能选择异常
ElementNotVisibleException :元素不可见异常
NoSuchAttributeException :没有这样属性异常
NoSuchElementException:没有该元素异常
NoSuchFrameException :没有该frame异常
TimeoutException : 超时异常
Element not visible at this point :在当前点元素不可见
9 、如何处理alert弹窗?
1)先用switch_to_alert()方法切换到alert弹出框上
2)可以用text方法获取弹出的文本 信息
3)通过accept()点击确认按钮
4)通过dismiss()点击取消按钮,取消弹出框
5)通过text()获得弹出窗口的文本
10、在selenium中如何处理多窗口?
句柄:窗口的唯一标识
1)先获取当前窗口的句柄driver.current_window_handle
2)再获取所有的的窗口句柄driver.window_handle
3)循环判断是否是想要操作的窗口,如果是就可以对窗口进行操作;如果不是就使用driver.switch_to_window方法跳转到新的窗口。
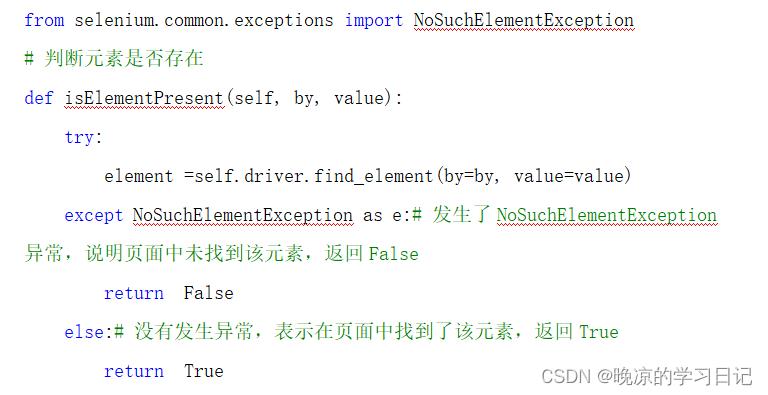
11、selenium中如何判断元素是否存在?
Selenium中没有提供原生的方法判断元素是否存在,一般我们可以通过定位元素+异常捕获的方式判断。
12、自动化中有哪三类等待?他们有什么特点?
1)线程等待(强制等待)如time.sleep(2):线程强制休眠2秒钟,2秒过后,再执行后续的代码。建议少用。
2)imlicitlyWait(隐式等待)会在指定的时间范围内不断的查找元素,直到找到元素或超时,特点是必须等待整个页面加载完成。
3)WebDriverWait(显式等待)通常是我们自定义的一个函数代码,这段代码用来等待某个元素加载完成,再继续执行后续的代码。
13、selenium中如何保证操作元素的成功率?也就是说如何保证点击的元素一定是可以点击的?
1)使用WebDriverWait()显性等待,等待元素加载出来后,再进行元素操作。
2)尽量减少不必要的操作:可以直接访问页面的,不要通过点击操作访问
3)有些页面加载时间过长,可以考虑中断加载
4)开发人员规范开发习惯,如给页面元素加上唯一的name、id等。
14、如何提高selenium脚本的执行速度?
1)使用显性等待,减少强制等待或隐性等待的使用。
2)减少不必要的操作步骤。
3)如果页面加载的内容过多,就设置超时时间,中断页面加载。
15、用例在运行过程中经常会出现不稳定的情况,也就是说这次可以通过,下次就没办法通过了,如何去提升用例的稳定性?
1)在经常检测失败的元素前尽量加上显式等待时间,等要操作的元素出现之后再执行下面的操作。
2)多用 try 捕捉,处理异常
3)尽量使用测试专用环境,避免其他类型的测试同时进行,对数据造成干扰
16、你的自动化用例的执行策略是什么?
自动化测试用例的执行策略是要看自动化测试的目的,通常有如下几种策略:
1)自动化测试用例是用来监控的,在此目的下,可以把自动化测试用例设置成定时执行的,如果每五分钟或一个小时执行一次,在jenkins上创建一个定时任务即可。
2)必须回归的用例。把测试用例设置成触发式执行,在jenkins上将自动化测试任务绑定到开发的build任务上。当开发人员在仿真环境上部代码的时候,自动化测试用例就会被触发执行。
3)不需要经常执行的测试用例。像全量测试用例,没必要一直回归执行,有些非主要业务线也不需要时时回归。这类测试用例采用人工执行,在jenkins创建一个任务,需要执行的时候人工去构建即可。
17、什么是持续集成?
持续集成是一种软件开发实践,即团队开发成员经常将代码集成到主干,也就意味着每天可能会发生多次集成。
它的好处主要有两个:
1)快速发现错误。每完成一点更新,就集成到主干,可以快速发现错误,定位错误也比较容易。
2)防止分支大幅偏离主干。如果不是经常集成,主干又在不断更新,会导致以后集成的难度变大,甚至难以集成。
目的:
持续集成的目的,就是让产品可以快速迭代,同时还能保持高质量。它的核心措施是,代码集成到主干之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。
18、自动化测试的时候是不是需要连接数据库做数据校验?
接口测试需要,UI自动化不需要
19、有几种元素常用定位方式,分别是?你最偏爱哪一种,为什么?
8 种,分别是:id、name、class name、tag name、link text、partial link text、xpath、css
我最常用的是 xpath(或 CssSelector)
因为很多情况下,html 标签的属性不够规范,无法通过单一的属性定位,这个时候就只能使用 xpath 可以去重实现定位唯一element
事实上定位最快的是Id,因为id是唯一的,然而大多数开发并没有设置id。
20、如何去定位页面上动态加载的元素?
属性动态变化是指该 element 没有固定的属性值,所以只能通过相对位置定位比如通过 xpath 的轴,找到该元素的父节点或者子节点等方式
21、点击链接以后,selenium是否会自动等待该页面加载完毕?
不会的。
所以有的时候,当selenium并未加载完一个页面时,去请求页面资源,则会误报不存在此元素。
所以首先我们应该考虑判断,selenium是否加载完此页面。其次再通过函数查找该元素。(使用显示等待,等待页面加载后再去操作元素)
22、webdriver client的原理是什么?
在selenium启动以后,driver充当了服务器的角色,跟client和浏览器通信,client根据webdriver协议发送请求给driver。driver解析请求,并在浏览器上执行相应的操作,并把执行结果返回给client。
23、webdriver的协议是什么?
The WebDriver Wire Protocol
24、启动浏览器的时候用到的是哪个webdriver协议?
http协议
25、怎样去选择一个下拉框中的value=xx的option?
1)select类里面提供的方法:select_by_value(“xxx”)
2)xpath的语法也可以定位到
26、Python 中常见的可变参数类型和不可变参数类型,都有哪些?
不可变的数据类型包括:整数、浮点数、负数、布尔值、字符串、元组
可变参数类型包括:字典、列表、集合
27、如何在定位元素后高亮元素(以调试为目的)?
重置元素属性,给定位的元素加背景、边框
28、什么是断言?
assert,判断测试结果与期望结果是否一致
目的为了表示与验证软件开发者预期的结果——当程序执行到断言的位置时,对应的断言应该为真。若断言不为真时,程序会中止执行,并给出错误信息。
29/自动化测试过程中,你遇到了哪些问题,是如何解决的?
1)频繁地变更页面,经常要修改页面对象类里面的代码
2)自动化测试偶尔出现过误报
3)自动化测试结果出现覆盖的情况:Jenkins根据时间建立文件夹
4)自动化测试代码维护比较麻烦
5)自动化测试进行数据库对比数据
30、如何模拟浏览器的前进、后退、刷新操作
driver. navigate().forward() //前进
driver.navigate().back() //后退
driver.navigate0.efresh() //刷新
11道高级软件测试面试题,你知道多少答案
大家好,我是小洁,这里赠送一套软件测试相关资源:
- 软件测试相关工具
- 软件测试练习集
- 深入自动化测试
- Python学习手册
- Python编码规范
- 大厂面试题和简历模板
关注我公众号:【程序员二黑】即可免费领取!
交流群:642830685
目录
1、列表和元组的区别
答:列表是动态的,长度可变,可以随意地增删改元素。列表的存储空间略大于元组,性能略逊于元组。
元组是静态的,长度大小固定,不可以对元组元素进行增删改操作。元组对于列表更加轻量级,性能稍优。
2、字典的原理
答:python中的字典底层依靠哈希表(hash table)实现, 使用开放寻址法解决冲突。
哈希表是key-value类型的数据结构, 可以理解为一个键值需要按照一定规则存放的数组, 而哈希函数就是这个规则。
字典本质上是一个散列表(总有空白元素的数组, python至少保证1/3的数组是空的), 字典中的每个键都占用一个单元。
一个单元分为两部分, 分别是对键的引用和对值的引用, 使用hash函数获得键的散列值, 散列值对数组长度取余, 取得的值就是存放位置的索引。
哈希冲突(数组的索引相同), 使用开放寻址法解决。
这也是python中要求字典的key必须可hash的原因。
数组中1/3的位置为空, 增加元素可能会导致扩容, 引发新的散列冲突, 导致新的散列表中键的次序发生变化, 这也是字典遍历时不能添加和删除的原因
字典在内存中开销很大, 实际上是以空间换时间。
3、说一下hash算法与哈希冲突
答:哈希算法:根据设定的哈希函数H(key)和处理冲突方法将一组关键字映象到一个有限的地址区间上的算法。也称为散列算法、杂凑算法。
哈希表:数据经过哈希算法之后得到的集合。这样关键字和数据在集合中的位置存在一定的关系,可以根据这种关系快速查询。
非哈希表:与哈希表相对应,集合中的 数据和其存放位置没任何关联关系的集合。
由此可见,哈希算法是一种特殊的算法,能将任意数据散列后映射到有限的空间上,通常计算机软件中用作快速查找或加密使用。
哈希冲突:由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,因此总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突。
4、怎么解决哈希冲突
答:解决哈希冲突的方法一般有:开放定址法、链地址法(拉链法)、再哈希法、建立公共溢出区等方法。
5、说下python的内存管理和垃圾回收机制
答:python的内存管理机制有三种:引用计数、垃圾回收、内存池。
引用计数:引用计数是一种非常高效的内存管理手段,当一个pyhton对象被引用时其引用计数增加1,当其不再被引用时引用计数减1,当引用计数等于0的时候,对象就被删除了
垃圾回收:引用计数、标记清除、分代回收
内存池:Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的 malloc。
另外Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。
也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
6、内存过大时你有什么调优手段
答:1.手动垃圾回收 2.避免循环引用(手动解循环引用和使用弱引用)3.调高垃圾回收阈值
 )
)
7、请简述下python的拷贝
答:1.赋值: 只是复制了新对象的引用,不会开辟新的内存空间。
2.浅拷贝: 创建新对象,其内容是原对象的引用。
浅拷贝有三种形式:切片操作,工厂函数,copy模块中的copy函数。
如:lst = [1,2,3,[4,5]]
切片操作:lst1 = lst[:] 或者 lst1 = [each for each in lst] 要注意:list1=lst 和list1=lst[:]的区别
工厂函数:lst1 = list(lst)
copy函数:lst1 = copy.copy(lst)
浅拷贝之所以称为浅拷贝,是它仅仅只拷贝了一层,在lst中有一个嵌套的list[4,5],如果我们修改了它,情况就不一样了。
3.深拷贝:只有一种形式,copy模块中的deepcopy函数。
和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。
深拷贝出来的对象是一个全新的对象,不再与原来的对象有任何关联。
#说明如下:
#1.外层添加元素时, 浅拷贝c不会随原列表a变化而变化;内层list添加元素时,浅拷贝c才会变化。
#2.无论原列表a如何变化,深拷贝d都保持不变。
#3.赋值对象随着原列表一起变化
8、请讲一下协程的原理
答:运用协程机制最典型的场景就是异步IO。所谓异步,是指一段程序在执行完成前有能力“暂停”,让其他程序段执行。
从语法上来看,协程和生成器类似,都是定义体中包含yield关键字的函数,所以总体上在协程中把yield看做是控制流程的方式。
协程是一个特殊的生成器,yield有返回值>生成器,yield没有>协程(没返回值就是协程)
9、sql的多表联查方式
答:内连接:JOIN / INNER JOIN、不等连接:ON 子句中使用了不等于运算符、自连接:一张表连接自身、左(外)连接:LEFT JOIN / LEFT OUTER JOIN、
右(外)连接:RIGHT JOIN / RIGHT OUTER JOIN、全(外)连接:FULL JOIN / FULL OUTER JOIN、交叉连接:CROSS JOIN (可用","代替)、
UNION 、UNION ALL操作符用于合并两个或多个 SELECT 语句的结果集。
10、数据库的存储过程
答:一组为了完成特定功能的SQL语句集(或者自定义数据库操作命令集), 根据传入的参数(也可以没有),
通过简单的调用, 完成比单个SQL语句更复杂的功能, 存储在数据库服务器端,只需要编译过一次之后再次使用都不需要再进行编译:主要对存储的过程进行控制。
11、数据库的存储过程与事务的异同
答:事务是保证多个SQL语句的原子型的,也就是要么一起完成,要么一起不完成
存储过程是把一批SQL语句预编译后放在服务器上,然后可以远程调用。
最后为方便大家学习测试,特意给大家准备了一份13G的超实用干货学习资源,涉及的内容非常全面。
 )
)
包括,软件学习路线图,50多天的上课视频、16个突击实战项目,80余个软件测试用软件,37份测试文档,70个软件测试相关问题,40篇测试经验级文章,上千份测试真题分享,还有2021软件测试面试宝典,还有软件测试求职的各类精选简历,希望对大家有所帮助……
关注我公众号:【程序员二黑】即可获取这份资料了!
推荐阅读
以上是关于30道python自动化测试面试题的主要内容,如果未能解决你的问题,请参考以下文章