视频行人重识别系统(UI界面,Python源码,可下载)
Posted 智科帮AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频行人重识别系统(UI界面,Python源码,可下载)相关的知识,希望对你有一定的参考价值。
下载链接:https://mbd.pub/o/bread/mbd-Y5WVmJpt
演示视频链接:https://live.csdn.net/v/236533
目录:
前言
从这篇博文开始,博主将进行一系列的计算机视觉方向软件系统博文的介绍,将详细介绍相关算法模型,UI界面构建,所有展示的系统均附下载链接,感兴趣的朋友可以下载,有问题也可在下方评论或私信交流。
行人检索系统是近几年计算机视觉领域的热门方向,每年CVPR、ICCV等各大顶会文章均维持在20篇以上,工业界也在往视频安防方向积极落地,所涉及的算法主要包括目标检测、行人重识别,考虑到兼顾实时性和准确性,这里采用基于YOLO模型进行目标检测,MGN算法进行行人重识别,都是比较经典的算法,在各个公开数据集上都取得了不错的性能。
网上开源的检测和重识别算法的代码很多,但是几乎没有看到有完整的软件系统。这里博主将检测和重识别算法通过PyQt的界面进行功能展示,用户可以上传一张搜索行人的目标画像,然后打开一个文件夹下所有视频进行目标搜索和匹配,检索到的目标会在界面显示。博文提供了完整的Python程序代码和使用教程,以及环境配置所需要的依赖包,适合新入门的朋友参考,完整的代码资源文件请转至文末的下载链接。
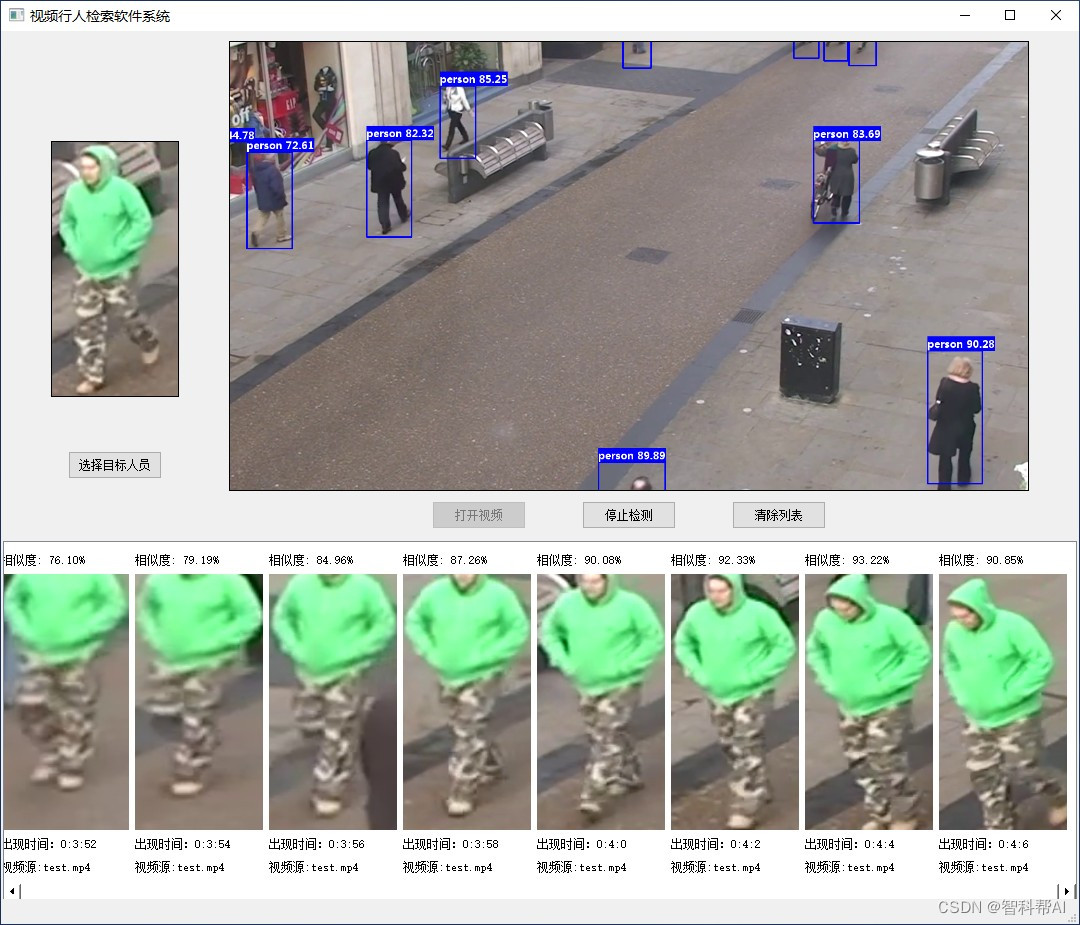
1、功能及操作说明
视频行人重识别系统的主要功能是上传一张目标画像,从几个视频中找出对应的目标。操作步骤如下所示:
- 点击
选择目标人员按钮,选择一张图片进行上传; - 点击
打开视频按钮,选择放置待搜索视频的文件夹;系统将开始自动进行目标检测; - 检索到跟目标画像一致的目标将出现在界面下方;
- 点击
停止检测,系统将停止视频检索,需重新选择文件夹开始检索; 清除列表将清空下方检索到的目标。
2、目标检测
由于整个软件的实现代码复杂,为了使得介绍循序渐进,首先将介绍如何利用YOLO进行视频中目标的检测,这里YOLO所用版本为v5,开源代码路径为https://github.com/ultralytics/yolov5,也可替换为YOLOX、YOLOv6和YOLOv7,对于算法的原理细节会在接下来的博文介绍。
首先是参数设置,这里用的模型是yolov5提供的yolov5x.pt,精度会高一些,如果需要提升速度,可以替换为yolov5s.pt。图像大小reisize为640,置信度阈值设置为0.3,视不同情况可以做调整,如果想要更多的检测到目标,可以设置低一点,当然会带来一些误检。iou阈值设置0.5,用于进行非极大值抑制的,这个基本可以不用动。类别这里我们因为是针对于行人,所以设置classes为0进行类别筛选,yolov5x.pt的模型是在coco数据集进行训练的,一共有80类,person是第一类。
self.yolo_weights = "./yolov5/weights/yolov5x.pt"
imgsz = 640
self.conf_thres = 0.3
self.iou_thres = 0.5
self.classes = 0
然后加载模型,通过以下方式进行载入,
from yolov5.models.experimental import attempt_load
self.half = self.device.type != 'cpu' # half precision only supported on CUDA
self.model = attempt_load(self.yolo_weights, map_location=self.device) # load FP32 model
if self.half:
self.model.half() # to FP16
接下来遍历视频存放的文件夹,读取每个视频的每一帧,通过以下代码实现
# 针对打开的文件夹,得到所有的视频,作为检索库
filelist = os.listdir(self.directory)
# 遍历视频
for i in range(len(filelist)):
filename = os.path.join(self.directory, filelist[i])
cap = cv2.VideoCapture(filename)
frameRate = math.ceil(cap.get(cv2.CAP_PROP_FPS))
currframenum = 1
while cap.isOpened():
# 读取第i个图片
success, frame = cap.read()
if success:
if currframenum % (2*frameRate) != 0:
currframenum += 1
continue
currframenum += 1
# 通过yolo进行目标检测
frame = self.YOLO(frame,currframenum,filelist[i],frameRate)
对于视频的每一帧,进行数据处理,然后放入模型进行推断
def YOLO(self,frame,currframenum,filename,frameRate):
img = letterbox(frame, self.img_size, stride=self.stride)[0]
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half() if self.half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = self.model(img, augment=False)[0]
最后,对得到的检测结果进行非极大值抑制和数据后处理,将检测框映射为原图片大小。
# Apply NMS
imghw = [img.shape[2], img.shape[3]]
detections = non_max_suppression(
pred, self.conf_thres, self.iou_thres, classes=self.classes, agnostic=False)
t2 = time_synchronized()
detections = detections[0].cpu().numpy()
# yolov5前向推断得到检测结果
person_boxs, person_class_names = self.preprocess(detections,frame.shape[0],frame.shape[1], imghw)
3、行人重识别
通过上一节的介绍我们了解了如何使用YOLO对视频中的每一帧进行目标检测,那么检测到的行人是否是我们要找的目标呢,我们将通过行人重识别算法进行目标的特征提取和相似度度量,最后设置阈值将目标找到。对于行人重识别模型,博主采用MGN算法,在多个公开数据集上精度都很高,该算法来源于论文Learning Discriminative Features with Multiple Granularitiesfor Person Re-Identification ,开源代码路径为https://github.com/seathiefwang/MGN-pytorch,对于算法的原理细节会在接下来的博文介绍。
首先,参数设置模块,主要参数包括cpu设置,模型路径
import argparse
# 所有参数
parser = argparse.ArgumentParser(description='MGN')
parser.add_argument('--nThread', type=int, default=2, help='number of threads for data loading')
parser.add_argument('--cpu', action='store_true', help='use cpu only')
parser.add_argument('--nGPU', type=int, default=1, help='number of GPUs')
parser.add_argument("--datadir", type=str, default="Market-1501-v15.09.15", help='dataset directory')
parser.add_argument('--data_train', type=str, default='Market1501', help='train dataset name')
parser.add_argument('--data_test', type=str, default='Market1501', help='test dataset name')
parser.add_argument('--reset', action='store_true', help='reset the training')
parser.add_argument("--epochs", type=int, default=80, help='number of epochs to train')
parser.add_argument('--test_every', type=int, default=20, help='do test per every N epochs')
parser.add_argument("--batchid", type=int, default=16, help='the batch for id') # 多少个id(人)
parser.add_argument("--batchimage", type=int, default=4, help='the batch of per id') # 每个id(人)多少图像
parser.add_argument("--batchtest", type=int, default=32, help='input batch size for test')
parser.add_argument('--test_only', action='store_true', help='set this option to test the model')
parser.add_argument('--model', default='MGN', help='model name')
parser.add_argument('--loss', type=str, default='1*CrossEntropy+1*Triplet', help='loss function configuration')
parser.add_argument('--act', type=str, default='relu', help='activation function')
parser.add_argument('--pool', type=str, default='max', help='pool function')
parser.add_argument('--feats', type=int, default=256, help='number of feature maps')
parser.add_argument('--height', type=int, default=384, help='height of the input image')
parser.add_argument('--width', type=int, default=128, help='width of the input image')
parser.add_argument('--num_classes', type=int, default=751, help='训练集人数751|702')
parser.add_argument("--lr", type=float, default=2e-4, help='learning rate')
parser.add_argument('--optimizer', default='ADAM', choices=('SGD', 'ADAM', 'NADAM', 'RMSprop'),
help='optimizer to use (SGD | ADAM | NADAM | RMSprop)')
parser.add_argument('--momentum', type=float, default=0.9, help='SGD momentum')
parser.add_argument('--dampening', type=float, default=0, help='SGD dampening')
parser.add_argument('--nesterov', action='store_true', help='SGD nesterov')
parser.add_argument('--beta1', type=float, default=0.9, help='ADAM beta1')
parser.add_argument('--beta2', type=float, default=0.999, help='ADAM beta2')
parser.add_argument('--amsgrad', action='store_true', help='ADAM amsgrad')
parser.add_argument('--epsilon', type=float, default=1e-8, help='ADAM epsilon for numerical stability')
parser.add_argument('--gamma', type=float, default=0.1, help='learning rate decay factor for step decay')
parser.add_argument('--weight_decay', type=float, default=5e-4, help='weight decay')
parser.add_argument('--decay_type', type=str, default='step', help='learning rate decay type')
parser.add_argument('--lr_decay', type=int, default=60, help='learning rate decay per N epochs')
parser.add_argument("--margin", type=float, default=1.2, help='')
parser.add_argument("--re_rank", action='store_true', help='')
parser.add_argument("--random_erasing", action='store_true', help='')
parser.add_argument("--probability", type=float, default=0.5, help='')
parser.add_argument("--savedir", type=str, default='saved_models', help='directory name to save')
parser.add_argument("--outdir", type=str, default='out', help='')
parser.add_argument("--resume", type=int, default=-1, help='resume from specific checkpoint')
parser.add_argument('--save', type=str, default='adam_1', help='file name to save')
parser.add_argument('--load', type=str, default='', help='file name to load')
parser.add_argument('--save_models', action='store_true', help='save all intermediate models')
parser.add_argument('--pre_train', type=str, default='', help='pre-trained model directory')
args = parser.parse_args()
然后加载模型文件
from MGN.model import Model as reidModel
from MGN.option import args
import MGN.utils.utility as utility
#加载REID模型
ckpt = utility.checkpoint(args)
self.model_ReID = reidModel(args,ckpt)
接下来对目标画像提取特征
def Extract(self, image):
# 提取MGN特征
self.model_ReID.eval()
with torch.no_grad():
image = self.img_to_tensor(image, self.img_transform)
image = image.to(self.device)
outputs = self.model_ReID(image)
feature = outputs[0].data.cpu()
# print(feature.shape)
return feature
# 打开一张图,opencv读取,提取特征q_feature
img=cv2.imread(self.queryimg_path)
person_img = Image.fromarray(img)
self.q_feature = self.Extract(person_img)
对每个视频的每一帧检测到的包围框进行遍历,提取特征
# 遍历每一个检测结果
for box in person_boxs:
x1 = int(box[0])
x2 = int(box[0] + box[2])
y1 = int(box[1])
y2 = int(box[1] + box[3])
if x1 < 0:
x1 = 0
if x2 > frame.shape[1]:
x2 = frame.shape[1]
if y1 < 0:
y1 = 0
if y2 > frame.shape[0]:
y2 = frame.shape[0]
# 把行人在图片中的区域扣取出来
person = frame[y1:y2, x1:x2]
person_img = Image.fromarray(person)
# 提取扣取出来的区域的特征t_feature
t_feature = self.Extract(person_img)
然后进行特征的余弦相似度度量
# 计算特征的余弦相似度进行匹配
def Align(self, q_feature, t_feature):
q_feature = F.normalize(q_feature)
t_feature = F.normalize(t_feature)
# distance = F.pairwise_distance(q_feature, t_feature, p=2)
distance = F.cosine_similarity(q_feature, t_feature, dim=1)
# print(distance)
return distance
# 计算扣取出来的区域的特征t_feature和要查询的人的图片的特征q_feature之间的距离
distance = self.Align(self.q_feature,t_feature)
最后基于阈值,进行判断检测框是否为要检索的目标
# 设定阈值,>0.7则为同一个人
if distance>0.7:
similaritylabel = QLabel()
similaritylabel.setText("相似度: %.2f%%"%((distance)*100))
similaritylabel.move(100 * self.count + 2, 510)
targetlabel = QLabel()
targetlabel.setFixedSize(128, 256)
person = cv2.resize(person, (128, 256))
person = cv2.cvtColor(person, cv2.COLOR_RGB2BGR)
4、环境配置
所需依赖包:
base
matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.2 Pillow PyYAML>=5.3.1 scipy>=1.4.1
torch>=1.7.0 torchvision>=0.8.1 tqdm>=4.41.0logging
tensorboard>=2.4.1
plotting
seaborn>=0.11.0 pandas
UI
PyQt5==1.4.1
下载链接
https://mbd.pub/o/bread/mbd-Y5WVmJpt
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
实时车辆行人多目标检测与跟踪系统-上篇(UI界面清新版,Python代码)
 摘要:本文详细介绍如何利用深度学习中的YOLO及SORT算法实现车辆、行人等多目标的实时检测和跟踪,并利用PyQt5设计了清新简约的系统UI界面,在界面中既可选择自己的视频、图片文件进行检测跟踪,也可以通过电脑自带的摄像头进行实时处理,可选择训练好的YOLO v3/v4等模型参数。该系统界面优美、检测精度高,功能强大,设计有多目标实时检测、跟踪、计数功能,可自由选择感兴趣的跟踪目标。博文提供了完整的Python程序代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
摘要:本文详细介绍如何利用深度学习中的YOLO及SORT算法实现车辆、行人等多目标的实时检测和跟踪,并利用PyQt5设计了清新简约的系统UI界面,在界面中既可选择自己的视频、图片文件进行检测跟踪,也可以通过电脑自带的摄像头进行实时处理,可选择训练好的YOLO v3/v4等模型参数。该系统界面优美、检测精度高,功能强大,设计有多目标实时检测、跟踪、计数功能,可自由选择感兴趣的跟踪目标。博文提供了完整的Python程序代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
以上是关于视频行人重识别系统(UI界面,Python源码,可下载)的主要内容,如果未能解决你的问题,请参考以下文章