风格迁移CycleGAN开源项目代码运行步骤详细教程
Posted 丨你得宠着我丨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了风格迁移CycleGAN开源项目代码运行步骤详细教程相关的知识,希望对你有一定的参考价值。
目录
最近在学习Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks这篇论文,论文下载地址,想要复现一下文中的代码,过程中遇到了很多问题,因此记录下来。遇到其他问题欢迎在评论区留言,相互解答。
前言
如果没有安装Anaconda或者MIniconda的可以先安装,并学一下简单的环境以及包的管理。基本的语法有:
conda remove -n=your_env_name --all
删除虚拟环境
conda create -n=your_env_name python=3.6
创建虚拟环境
conda info --env
显示所有环境的列表
conda activate env_name
切换至env_name环境
一、下载项目,搭配环境
- 下载源码并解压。PyTorch版CycleGAN源码下载地址:CycleGAN源码
项目结构如下,一般的项目都会包含requirements.txt, environment.yml, setup.py三者之中某些或者全部。
- requirements.txt, environment.yml是同一类的东西,它们提供的是当前软件包安装运行所需要的环境或者依赖信息,即这些东西的安装是当前软件包安装和运行的前提条件。这些信息相当于是开发者给使用者提供的用于恢复自己开发时的环境的信息。environment.yml = python + requirements.txt。
- setup.py跟以上两者是完全不一样的,它就是用于安装当前软件包自身的安装脚本。
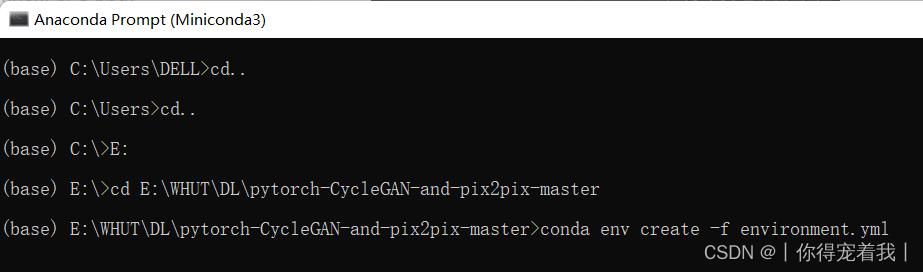
- 打开Anaconda prompt,先切换路径到代码包解压的路径中。然后通过使用作者的环境包来搭建设定好的环境,输入:
conda env create -f environment.yml
再通过pip来安装visdom,输入:
pip install -r requirements.txt
如果使用conda env create -f environment.yml命令时,报错CondaHTTPError,可以参考这篇文章:关于anaconda创建环境时出现CondaHTTPError问题的终极解决办法。如果还是不行,由于environment.yml中的包并不多,可以用pip手动安装。
首先创建一个环境:
conda create -n=MyProject python=3.8
进入环境:
conda activate MyProject
用pip依次安装environment.yml文件中的包(除了torch):
pip install --index-url https://pypi.tuna.tsinghua.edu.cn/simple/ dominate=2.4.0
安装torch:安装教程 , 下载库网址
这里最好下gpu版本的,因为下载gpu版本的,训练时可以选择gpu或者cpu进行训练。但是下载cpu版本,只能选择cpu进行训练。
二、下载数据集
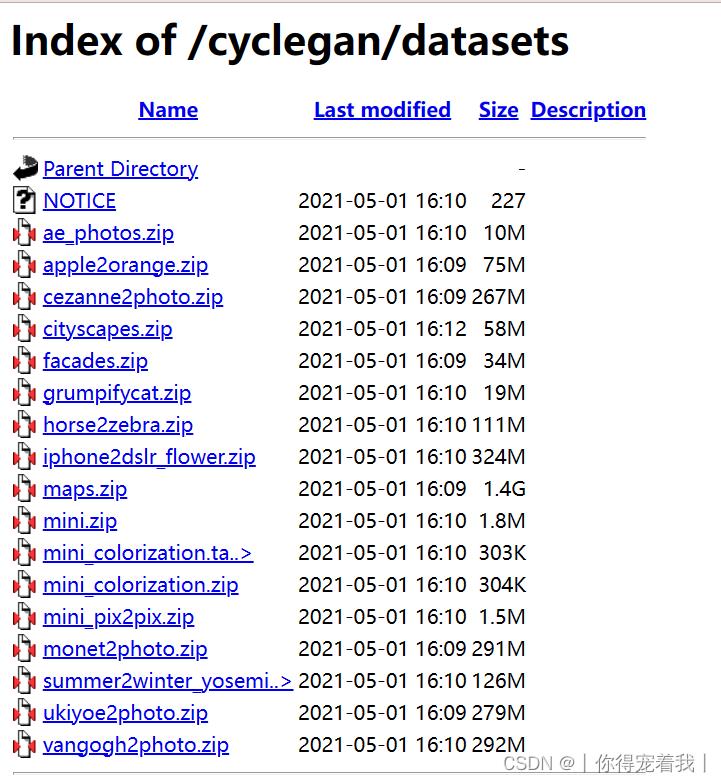
- 找到项目中datasets文件夹下的 download_cyclegan_dataset.sh 文件,使用记事本打开,也可以点击数据集链接http://efrosgans.eecs.berkeley.edu/cyclegan/datasets/
- 下载horse2zebra这个压缩包,也可以下其他的,把这个数据集解压并保存在解压后的代码包的dataset文件中。
如果下载压缩包时提示:“无法下载,网络原因”,可以下载idm,
idm使用教程, idm下载链接
三、训练
3.1调用Visdom可视化库
首先把项目配置在刚才创建的环境中,参考Pycharm中如何配置已有的环境_MrRoose1的博客-CSDN博客。然后在终端输入python -m visdom.server,如果启动成功显示如下:
如果没有反应,或者在Anaconda prompt中输入python -m visdom.server,显示Downloading scripts, this may take a little while,则可以参考博客visdom服务启动时提示Downloading scripts, this may take a little while解决办法亲测有效,可以解决。
3.2 训练
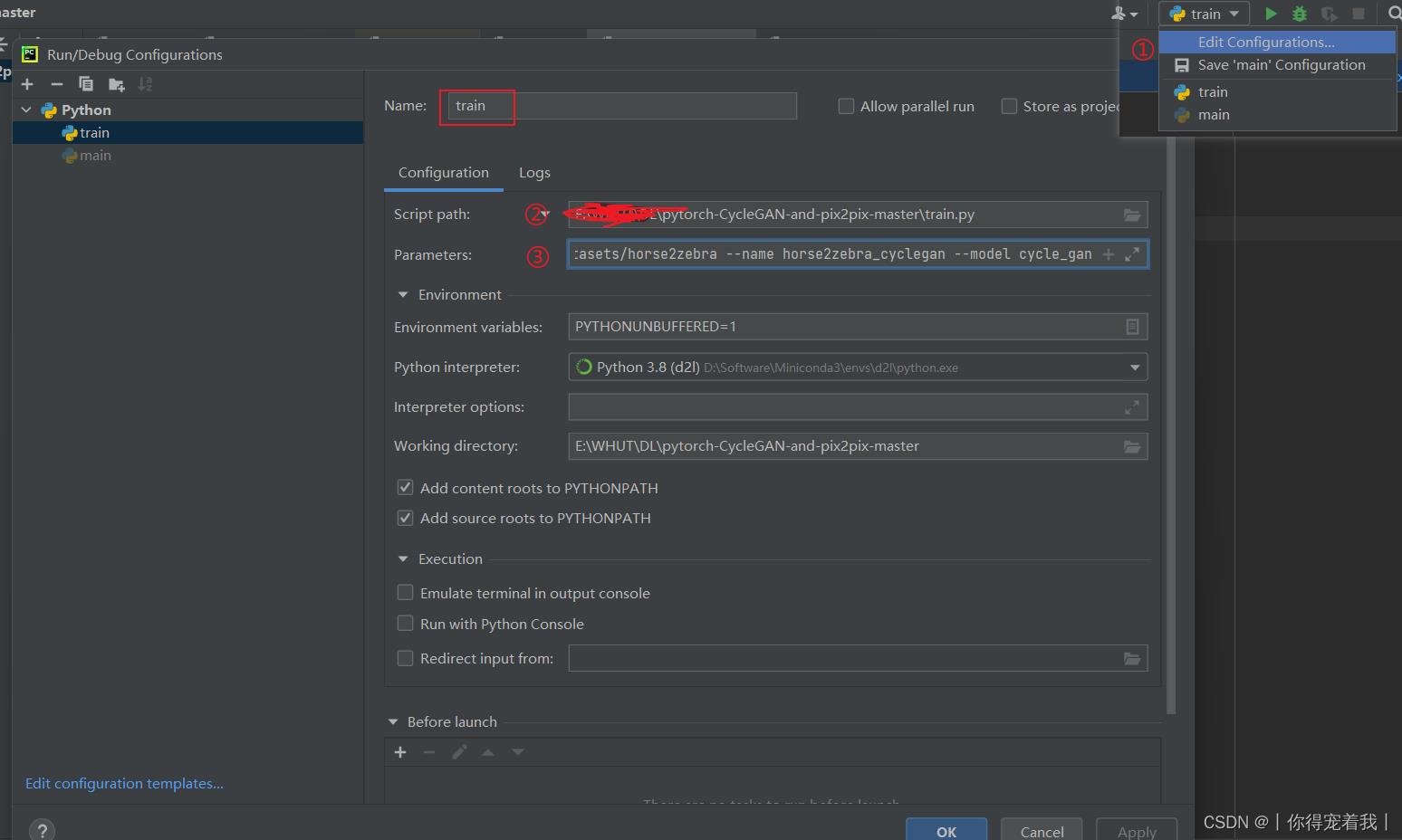
如图添加train文件中的参数,把python train.py后面的部分,也就是--dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan复制到Parameter中,然后运行train.py。
python train.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan
1)datasets 这个最简单,就是数据集的路径
2)name 这里指的是保存训练权重的文件夹的名字
3)model:训练的模型
如果报错module ‘torch._C’ has no attribute ‘_cuda_setDevice’,可能是因为环境里pytorch下载的CPU版本导致的。查看pytorch版本的方法:
import torch
# 若返回为True,则使用的是GPU版本的torch,若为False,则为CPU版本
print(torch.cuda.is_available())
# 返回的GPU型号为你使用的GPU型号
print(torch.cuda.get_device_name(0))
- 如果下载的是cpu版本,要么下载GPU版本,要么在你执行代码时加上将GPU设置成-1。
① 如果时Python文件中调用了GPU,那么设置:
torch.cuda.set_device(-1)
②如果你用命令行执行python文件,那么在最后加上
python train.py --你的GPU的设置对应形参 -1
你的GPU设置对应形参,是你的Python文件中应该会有一个arg是用来设置要使用GPU的编号的,与1同理。
- 如果环境里明明是GPU版本,这里有可能是因为CMD命令行识别环境错了,所以我们换在anaconda里面运行。
报错信息:UserWarning: Detected call of ‘lr_scheduler.step()’ before ‘optimizer.step()’. In PyTorch 1.1.0 and later, you should call them in the opposite order: ‘optimizer.step()’ before ‘lr_scheduler.step()’. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Detected call of ‘lr_scheduler.step()’ before ‘optimizer.step()’. "
把train.py文件中的第43行注释,放到第78行。
model.update_learning_rate() # update learning rates in the beginning of every epoch.
运行成功以后,在Visdom可以看到训练过程。
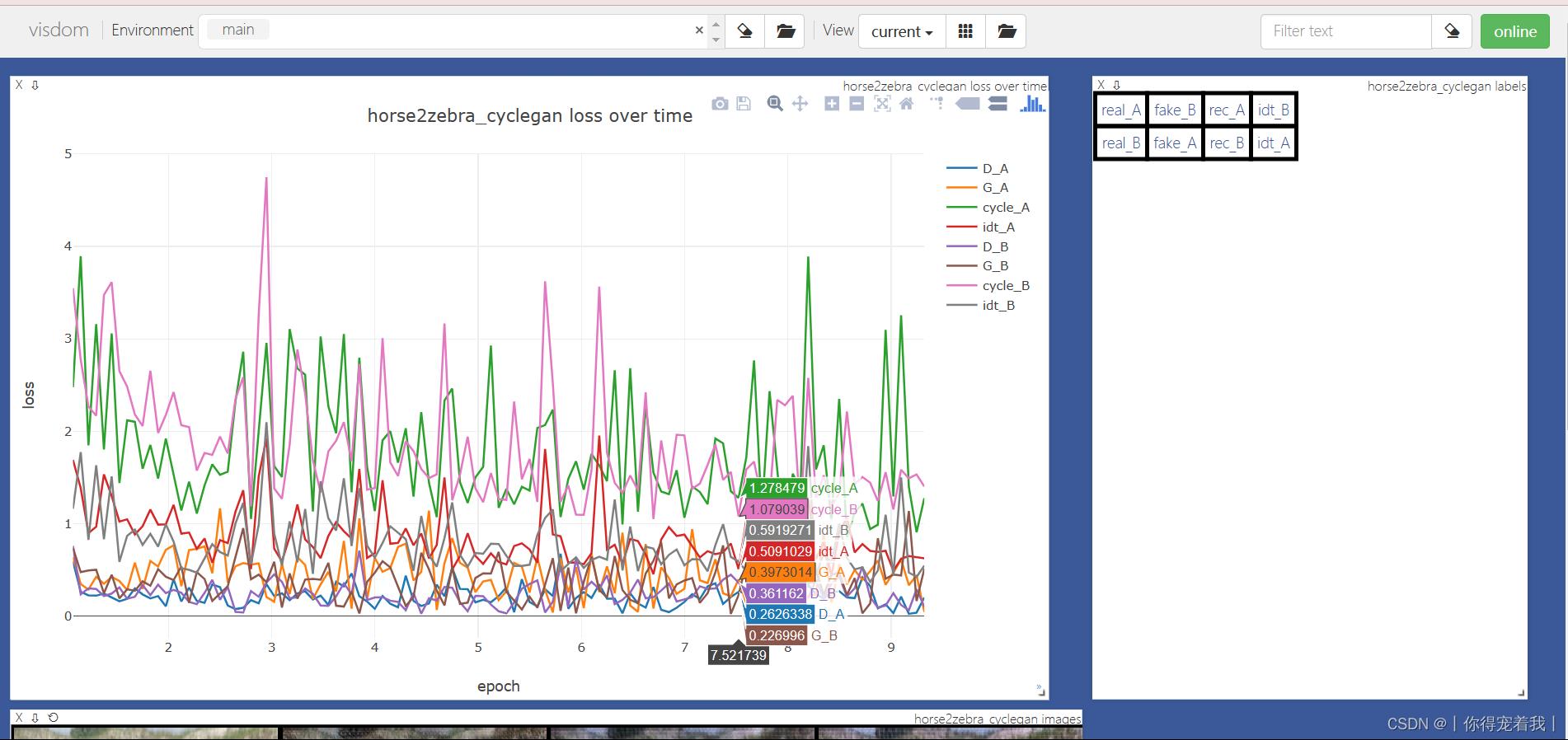
当运行train.py文件时,在文件夹下保存模型里会生成一个web文件,打开里面的html就能看到八种图片:
- real_A:表示输入的真实的A图片
- real_B:表示输入的真实的B图片
- fake_B:表示真实图片A生成的假冒B风格图片
- fake_A:表示真实图片B生成的假冒A风格图片
- rec_A:表示fake_B再生成回A风格图片
- rec_B:表示fake_A再生成回B风格图片
- idt_B:表示真实图片A生成的A风格图片
- idt_A:表示真实图片B生成的B风格图片
其中fake_B一般就是想要生成的图片
- netG_A:生成器A,用于生成B风格的图片
- netG_B:生成器B,用于生成A风格的图片
如果想要继续训练,运行命令如下:
python train.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan --continue_train
四、预测
4.1 用自己训练完的权重文件进行预测
用同样的方法运行test.py文件:
python test.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan
会生成一个results文件夹,打开html可以看到训练的效果。可以看到训练5轮的效果并不好。

4.2 用作者预训练文件进行预测
- 首先要下载预训练文件:预训练文件下载地址
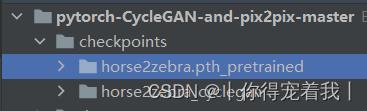
- 在check_points文件夹里新建文件夹:horse2zebra.pth_pretrained
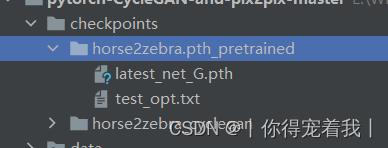
- 将下载的预训练权重文件重新命名为:latest_net_G.pth,并放在horse2zebra.pth_pretrained文件夹下。
- 添加新的参数运行test.py文件,参数为
--dataroot datasets/horse2zebra/testA --name horse2zebra.pth_pretrained --model test --no_dropout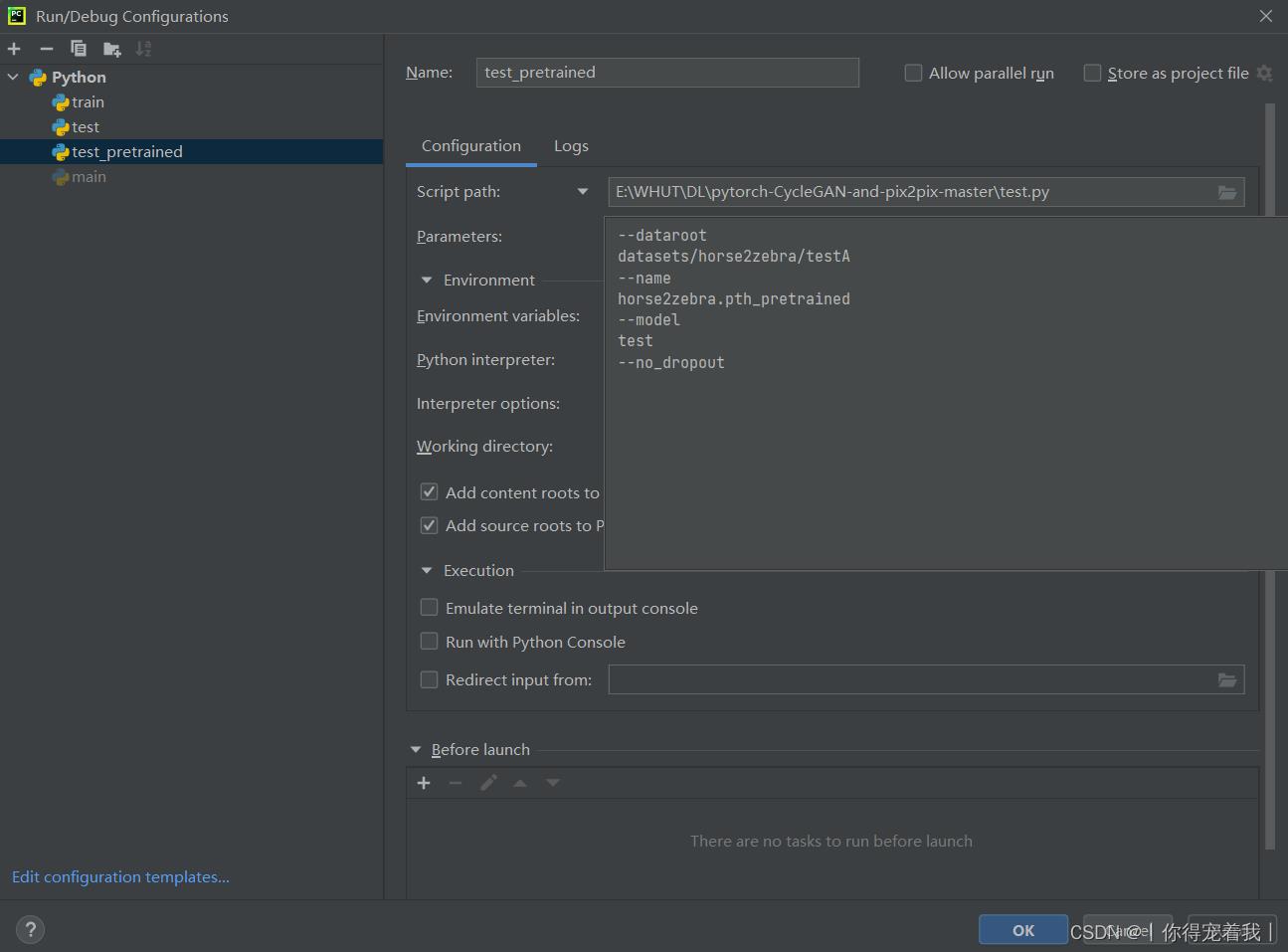
也可以在anconda中激活环境运行:
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra.pth_pretrained --model test --no_dropout
打开results文件夹下horse2zebra.pth_pretrained文件夹中的html,可以看到训练的效果图。

参考:
【毕设】基于CycleGAN的风格迁移【一】环境搭建及运行代码
【深度学习】CycleGAN开源项目学习笔记 | 完整流程 | 报错总结 | pytorch
毕设基于CycleGAN的风格迁移环境搭建及运行代码
源代码地址:CycleGAN源码
因为该篇内容包含Anaconda的环境管理及包的管理,可以选择参考:Anaconda安装+环境管理+包管理+实际演练例子(全网最详细)_MrRoose1的博客-CSDN博客
一、搭配环境
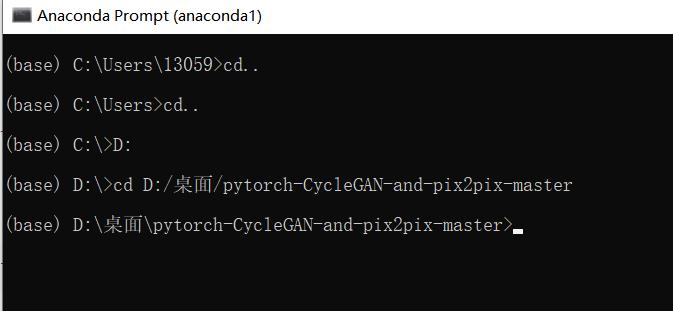
1.首先把代码包下载并解压到本地(我是直接放到桌面)。
2.打开Anaconda prompt,先切换路径到代码包解压的路径中。
3. 然后通过使用作者的环境包来搭建设定好的环境,输入:
conda env create -f environment.yml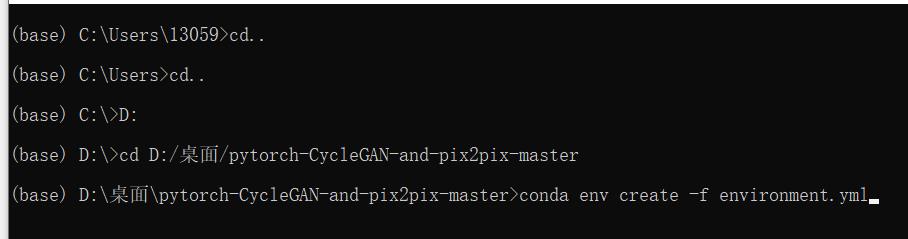
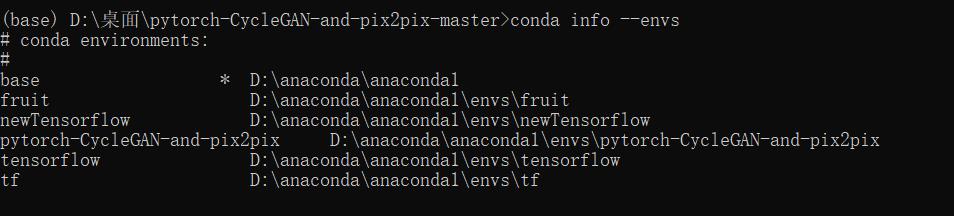
随后产生一个叫pytorch-CycleGAN-and-pix2pix的环境名称。我们可以通过输入:
conda info --envs来查看已有的虚拟环境名称。
4.由于CycleGAN源码中用到了visdom,但此时pytorch-CycleGAN-and-pix2pix环境中却没有visdom这个包,我们需要手动安装。先进入到pytorch-CycleGAN-and-pix2pix虚拟环境中,输入:
activate pytorch-CycleGAN-and-pix2pix
再通过pip来安装visdom,输入:
pip install -r requirements.txt注:期间会有一些提示,显示一些包的版本,那些不用管,因为pip中的requirement.txt与conda中的environment.yml之间有一些包版本不一致,但不耽误我们搭配环境哈,你们按照我的步骤来,保准没问题。
上述就是先把基础环境搭配好了
二、数据集下载
从解压后的代码包中,找到download_cyclegan_dataset.sh文件
(我的地址是:D:\\桌面\\pytorch-CycleGAN-and-pix2pix-master\\datasets\\download_cyclegan_dataset.sh)
通过记事本打开,找到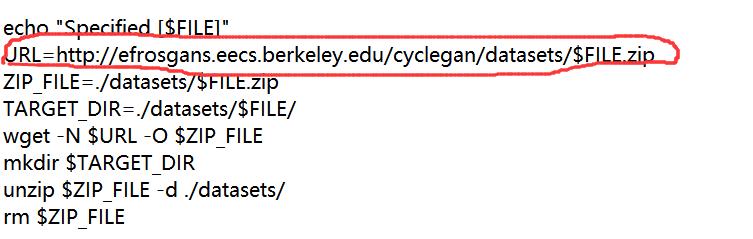
其中复制’$‘前面的地址并打开:(地址:Index of /cyclegan/datasets)
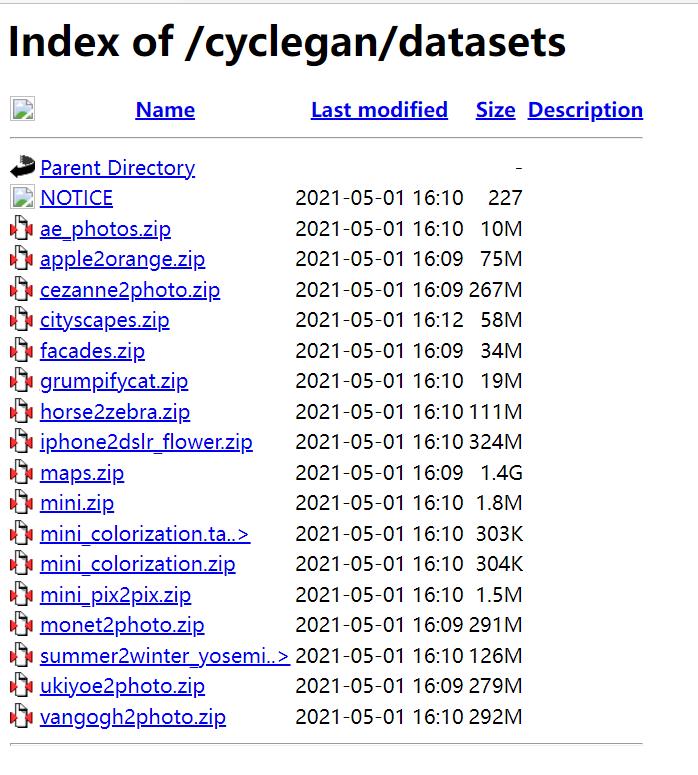 以我为例,下载horse2zebra这个压缩包,把这个数据集解压并保存在解压后的代码包的dataset文件中(我的地址:D:\\桌面\\毕业设计-图像风格迁移\\Neural-Style-GAN\\pytorch-CycleGAN-and-pix2pix-master\\pytorch-CycleGAN-and-pix2pix-master\\datasets)
以我为例,下载horse2zebra这个压缩包,把这个数据集解压并保存在解压后的代码包的dataset文件中(我的地址:D:\\桌面\\毕业设计-图像风格迁移\\Neural-Style-GAN\\pytorch-CycleGAN-and-pix2pix-master\\pytorch-CycleGAN-and-pix2pix-master\\datasets)
此时数据集和环境已经准备好了,我们可以打开pycharm进行最后的参数调试。
三、调用Visdom及运行pycharm前的参数搭建
Train.py
首先需要参考Pycharm中如何配置已有的环境_MrRoose1的博客-CSDN博客把刚刚在anaconda中安装的pytorch-CycleGAN-and-pix2pix虚拟环境配置在pycharm中。
随后由下图可得,如果想保证训练正常运行,得先python -m visdom.server,启动服务器(可以,有tensorboard那味儿了)

那就在terminal开一下,如下图所示
注:我后期把代码包转移位置,放到了桌面一个名叫毕业设计-风格迁移内部的一个叫Neural-Style-GAN文件夹中,此时代码包的路径是 (D:\\桌面\\毕业设计-图像风格迁移\\Neural-Style-GAN\\pytorch-CycleGAN-and-pix2pix-master\\pytorch-CycleGAN-and-pix2pix-master)
从图片中我们可以看到“It's Alive!”代表启动成功,点击terminal中的地址,就可以在train代码的时候看见页面的变化(此时还没有run代码,所以页面内啥也看不到)。
最后看一下这个训练参数设置
python train.py --dataroot ./datasets/horse2zebra --name horse2zebra_cyclegan --model cycle_gan这里说一下以前没说的,类似这种附加参数在pycharm里打开文件后(注意现在活跃的脚本和你想添加参数的脚本要一致,比如我们要添加train文件中的参数,那我们就应该注意红色框内的文件名是否是train) run/Edit Configurations/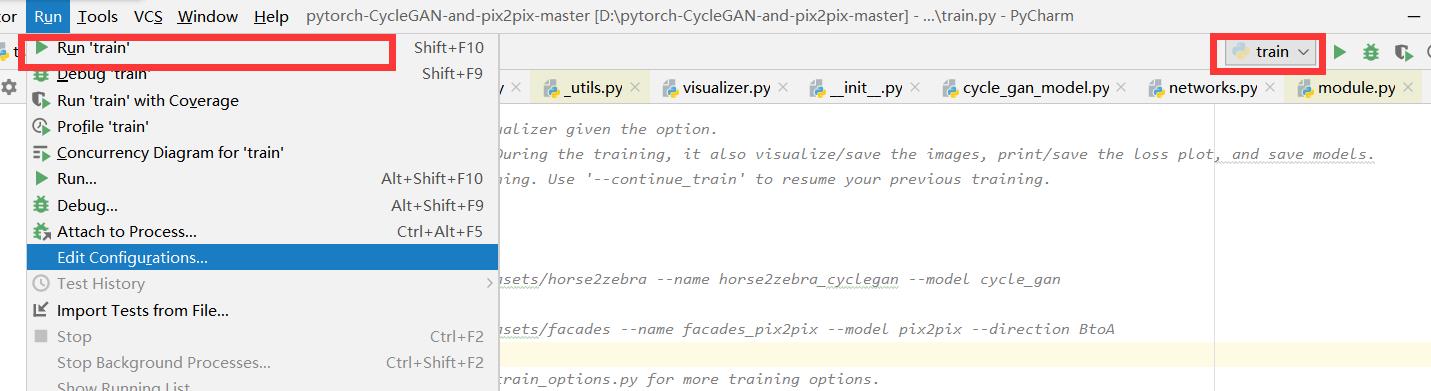

打开然后把后面的参数塞到里面,当然,因为数据集不同,所以需要稍微改改
--dataroot ./datasets/horse2zebra --name horse2zebra_cyclegan --model cycle_gan然后直接训练。
(可能会出现的问题)

第一个
UserWarning: Argument interpolation should be of type InterpolationMode instead of int. Please, use InterpolationMode enum.
“Argument interpolation should be of type InterpolationMode instead of int. “
关于这个问题,在网上找了一圈,在base_dataset添加InterpolationMode,并代替PIL.Image。
你说它没事插什么值啊!
from torchvision.transforms import InterpolationMode定位到dataset的transform里(base_dataset.py),添加引用,然后改一下
def get_transform(opt, params=None, grayscale=False, method=Image.BICUBIC, convert=True):原81行
def get_transform(opt, params=None, grayscale=False, method=InterpolationMode.BICUBIC, convert=True):改81行
第二个
UserWarning: Detected call of lr_scheduler.step() before optimizer.step(). In PyTorch 1.1.0 and later, you should call them in the opposite order: optimizer.step() before lr_scheduler.step(). Failure to do this will result in PyTorch skipping the first value of the learning rate schedule.
这说的就很明白了,就是说pytorch1.1.0之后,优化器的更新要放到学习率更新的前面,定位到就在train里(还好这俩玩意没被放一块)把学习率更新扔后面
# model.update_learning_rate() # update learning rates in the beginning of every epoch.注释掉train43行
model.update_learning_rate() # update learning rates in the ending of every epoch.放到78行运行完一个epoch后
然后就应该没问题可以正常运行了。
Test.py
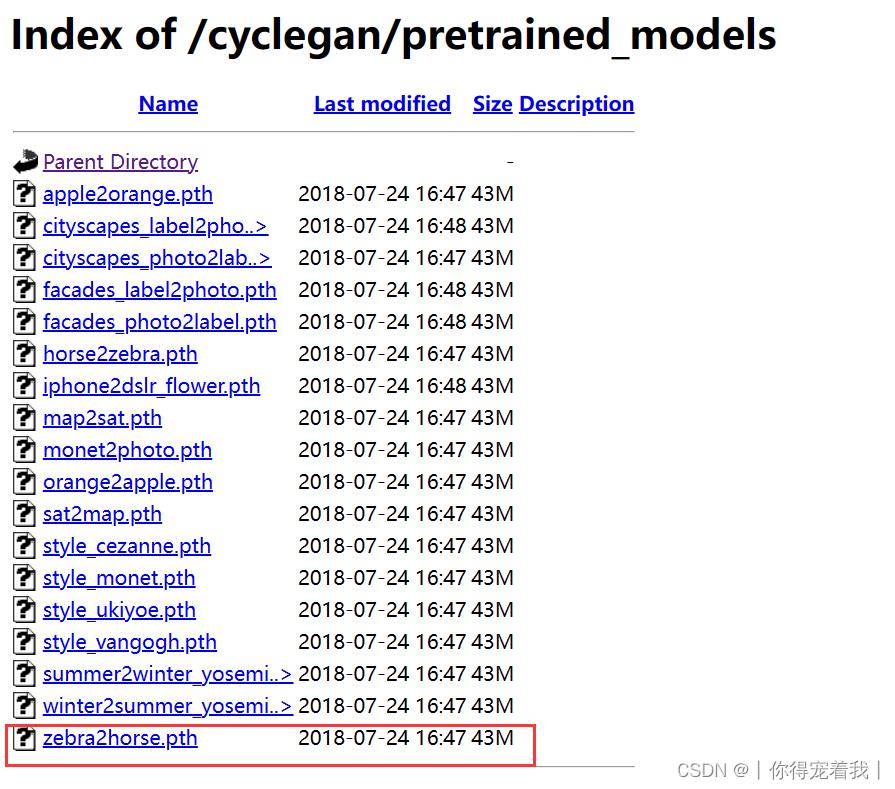
我们可以下载作者已经训练好的模型来直接上手跑。地址:Index of /cyclegan/pretrained_models
这里我下载的是horse2zebra.pth文件。随后在解压后的代码包中找到checkpoints文件夹,在里面新建一个叫name_pretrained的文件夹(其中name此时是horse2zebra),把下载好的文件重命名为latest_net_G.pth,并保存在name_pretrained(horse2zebra_pretrained)中。
 然后与train.py训练一样,添加pycharm参数即可(text.py不需要开启visdom)
然后与train.py训练一样,添加pycharm参数即可(text.py不需要开启visdom)
--dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout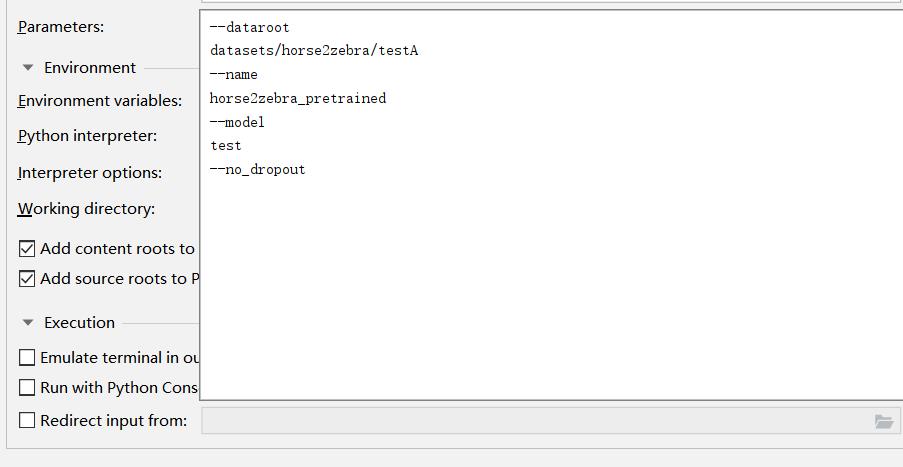
注:这里稍微注意一下dataroot中的路径,最后的是testA,为什么不是testB呢,因为这个模型是马转换成斑马的单向转换模型,textA中全都是马的数据集,而testB中都是斑马的数据集。
test.py运行后的结果(风格迁移后的图片)在D:\\桌面\\毕业设计-图像风格迁移\\Neural-Style-GAN\\pytorch-CycleGAN-and-pix2pix-master\\pytorch-CycleGAN-and-pix2pix-master\\results\\horse2zebra_pretained\\test_latest\\images路径中查询。
以上是关于风格迁移CycleGAN开源项目代码运行步骤详细教程的主要内容,如果未能解决你的问题,请参考以下文章